- The paper introduces COMPACT-VA, a conditional VQ-VAE framework that jointly optimizes token compression with planning, achieving a +6.3% improvement in intersection handling.
- The paper utilizes a hierarchical Q-former and latent skill inference to compress multi-modal sensor data, reducing GPU usage by 2.7× and speeding up inference by 3.3×.
- The paper demonstrates significant performance gains in high-signal driving scenarios with improved Go/Stop success rates and a 22% reduction in roll-through incidents.
Planning-Aligned Token Compression for Long-Context Autonomous Driving
Motivation and Problem Statement
Unified vision-action (VA) policies for autonomous driving, which directly map temporal and multimodal sensory streams to action outputs via transformer architectures, have shown promise in handling complex long-tail driving scenarios. However, their reliance on tokenizing and encoding high-frequency, multi-camera historic observations leads to rapid context window growth, making real-time inference computationally prohibitive. Existing compression techniques (such as temporal decay) are heuristically engineered and decoupled from the downstream planning objectives, resulting in the frequent loss of decision-critical long-term cues necessary for nuanced behavior, particularly in intersection handling and scenarios with occlusion.
COMPACT-VA: Planning-Aligned Compression
The proposed COMPACT-VA framework introduces a conditional VQ-VAE-based working memory module that learns to compress and retain the most decision-relevant historical features by jointly optimizing compression and planning. The memory system is hierarchically organized such that recent observations are densely represented while more distant history is aggressively compressed, still capturing temporally extended cues required for behavior correctness in critical intersection scenarios.
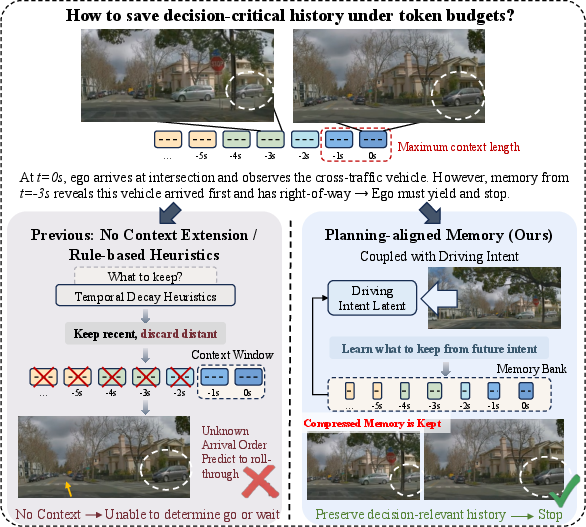
Figure 1: Standard token compression (e.g., temporal decay) removes temporally distant yet crucial cues, whereas planning-aligned compression via a conditional VAE enables retention of context necessary for correct right-of-way negotiation (+6.3% success rate improvement).
The architecture consists of:
- Q-former-based token aggregation: Raw observation tokens from multi-view cameras across a long context are hierarchically compressed using learnable queries, forming a multi-level FIFO buffer.
- Conditional latent skill inference: During training, a posterior encoder ("Q-net") computes latent driving intent from future trajectory targets ('teacher forcing'), while a prior encoder ("P-net") predicts intent from compressed observations alone.
- End-to-end optimization: The compressed history tokens and the predicted latent are jointly fed as input to the final transformer policy, with the VAE objective's KL-divergence directly regularizing compression to preserve planning-critical attributes.
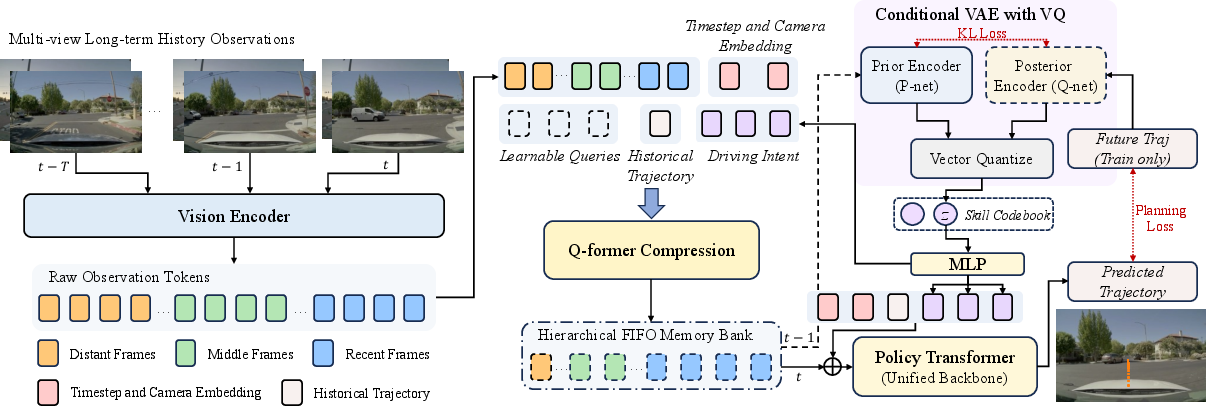
Figure 2: Model overview—hierarchical Q-former compresses observation history, conditioned on both historical trajectory and learned driving intent, which are fused for final policy prediction. The skill latent is distilled from future waypoints during training (posterior) and inferred from compressed observations at test time (prior).
Evaluation: High-Signal Memory-Critical Driving
COMPACT-VA is evaluated on curated subsets of autonomous driving data focusing on "high-signal" scenarios—stop-controlled intersections, dynamic occlusions at yield signs, and unprotected turns—where discrete behavioral correctness (stopping, yielding, prompt departure) depends on memory of distant cues such as agent arrival order or occluded traffic presence.
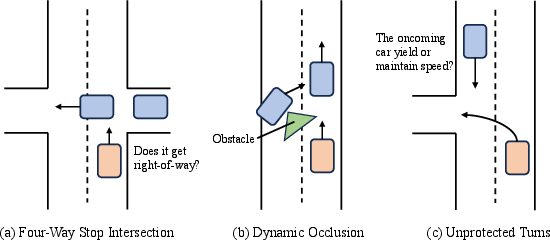
Figure 3: Illustration of challenging high-signal driving cases where long temporal memory is essential (arrival order at four-way stops, occluded cross-traffic, unprotected gaps).
A suite of behavioral metrics is defined, including Go/Stop Success Rate (SR), roll-through rates (illegal behavior), and stop error statistics, to specifically measure decision-level, not just trajectory fidelity, improvements.
Quantitative Analysis and Ablation
COMPACT-VA consistently outperforms both standard, sparse, and dense context baselines, as well as naïve hierarchical compression without planning alignment, across all behavioral metrics under equivalent or much lower token and computational budgets.
On the most challenging settings (40 frames over 5s at 4Hz, 1424 compressed tokens), the following is observed:
- Go SR: COMPACT-VA: 68.3%; baseline compression w/o planning: 65.6%; standard Alpamayo: 63.8%; uncompressed long-context: 61.9%
- Stop SR: Up to 89.2%
- Roll-through reduction: −22% relative improvement
- Speed and memory: 3.3× speedup, 2.7× lower GPU usage vs. uncompressed
Closed-loop simulator evaluation confirms that the improved long-context policy incurs no regression in standard lane-following or safety metrics, preserving general driving proficiency.
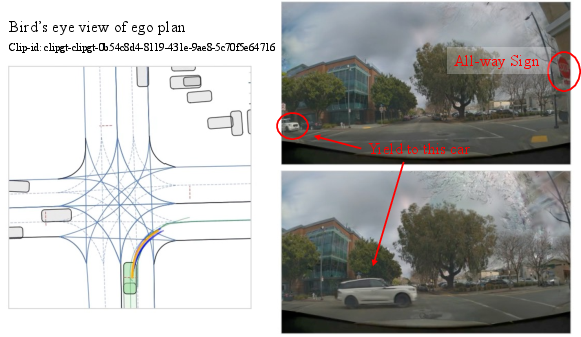
Figure 4: Policy output in an all-way sign intersection—by retaining decision-relevant arrival order, the ego vehicle yields correctly and only proceeds when safe, as reflected in both trajectory and camera views.
Ablation studies highlight the necessity of all architectural choices: hierarchical compression, trajectory-conditional Q-former, and, crucially, the planning-aligned VAE skill latent. Codebook utilization analysis shows high diversity of learned latent skills (80%+ VQ entries used), indicating robust intent discretization without mode collapse.
Theoretical and Practical Implications
This work demonstrates that tying compression to downstream planning outcomes is essential for monolithic VA policy efficiency and safety, especially as context windows grow and traditional quadratic attention becomes intractable. The conditional VQ-VAE formulation ensures that the model selects and retains precisely those cues which optimize behavioral metrics, driving more reliable intersection handling and response to occlusions.
Practically, this mechanism provides a route to scalable, token-budgeted long-horizon memory in physical AI, reducing both compute and latency, and is suitable for deployment on resource-limited real-world autonomous systems. The architecture is fully compatible with standard transformer-based policies and can serve as a plug-in memory/buffering module, or as a template for generalization to other embodied domains such as manipulation or navigation.
Future Directions
Future research may explore extending planning-aligned compression with adaptive recurrent mechanisms, application to severe occlusion/multi-agent congestion scenarios, or integrating with efficient sequence models like SSMs. There is also scope to transfer the skill discretization concept to hierarchical temporal abstraction in broader decision-making settings.
Conclusion
COMPACT-VA introduces a memory system for autonomous driving that leverages planning-aligned token compression to substantially improve behavioral decision-making in contexts where long-term historical information is critical. The approach bridges the gap between token-efficient transformer architectures and the need for task-aware, compact, and persistent working memory, thus contributing a robust foundation for future scalable, safe, and efficient embodied AI planning (2606.07464).