- The paper presents on-policy distillation using GKD to reduce LLM size while maintaining near-teacher performance in autonomous motion planning.
- It compares the GKD approach with a dense-feedback RL baseline on the nuScenes benchmark, focusing on metrics like L2 error and collision rate.
- The work demonstrates that full token-level distribution matching mitigates cascading errors, enabling safe, resource-efficient deployment in real-world vehicles.
On-Policy Knowledge Distillation of LLMs for Autonomous Vehicle Motion Planning
Introduction
This work systematically investigates the compression of LLM-based planners for autonomous vehicles via on-policy distillation methods. It builds on the GPT-Driver framework, which recasts motion planning as conditional language modeling wherein driving scenarios are encoded as natural language prompts and waypoint predictions are generated as sequences of tokens, augmented with chain-of-thought reasoning. The main objective is to transfer motion planning competencies from a large, resource-intensive teacher LLM to a smaller student model suitable for real-time deployment, without sacrificing planning accuracy or safety.
Two main student training paradigms are evaluated: (1) On-policy Generalized Knowledge Distillation (GKD), which aligns the student to the teacher's token-level distributions during student-driven rollouts, and (2) a dense-feedback RL baseline that provides per-token reward signals derived from teacher log-probabilities. The evaluation leverages the nuScenes benchmark, focusing on L2 trajectory accuracy, collision rate, and output formatting reliability. The controlled experiments isolate the effect of the student learning algorithm while keeping all architectural and data factors constant.
Methodology
A supervised-finetuned Qwen3-8B LLM serves as the teacher, trained to produce both chain-of-thought explanations and 6-step future trajectories given nuScenes-derived driving scenarios. The Qwen3-1.7B serves as the student in all comparative evaluations.
On-Policy Generalized Knowledge Distillation
GKD mitigates the inherent train-inference distribution mismatch seen in classic distillation approaches. The student generates complete output sequences, which are then used as input context to the teacher. The training objective minimizes the divergence (default: Jensen-Shannon divergence with β=0.5) between the teacher's and student's next-token distributions along the student's own rollouts, thus matching the full token-level output distributions on inputs likely to be encountered at deployment. This approach retains soft-label supervision, conveying richer structure than scalar reward feedback, especially on critical sub-sequences such as coordinate generation where output space is highly structured.
Dense-Feedback RL Baseline
For comparison, a dense-feedback RL objective is considered, where the student receives per-token scalar advantage rewards, computed as the difference between teacher and student log-probabilities for the sampled token, with gradients propagated only through the sampling policy. This setup mirrors recent RL-driven distillation protocols and allows for isolation of the value of full-distribution supervision versus sampled-token reward shaping.
Evaluation
Performance is comprehensively assessed on 5,119 nuScenes validation scenarios. Metrics are computed for L2 displacement errors at 1, 2, and 3-second horizons using both STP-3 and UniAD averaging conventions, as well as per-horizon and average collision rates. Format error, tracking output parseability and thus the operational reliability of the planner, is also measured.
The GKD student demonstrated strong retention of teacher-level performance: average L2 error (STP-3) was 0.373 m for the GKD student versus 0.355 m for the teacher, and average trajectory error (UniAD convention) was 0.772 m for GKD versus 0.730 m for the teacher. The significant performance drop of the RL baseline, which obtained a 0.579 m STP-3 L2 and 1.092 m UniAD L2, corroborates the hypothesis that full token-level distribution matching is critical for high-fidelity trajectory generation.
Collision rate analyses support these findings: GKD achieved 0.138% STP-3 collision versus the teacher's 0.101%, significantly outperforming the RL baseline (0.363%). Both student training protocols maintained perfect format reliability, with zero unparseable outputs across all test scenarios.
Qualitative results in complex maneuvers, such as turning scenarios, illustrate the superiority of GKD over RL for sequence-level coherence. Even when missing the ground truth maneuver, the GKD student remains closer to feasible driving behavior, with less severe error accumulation over prediction horizons.
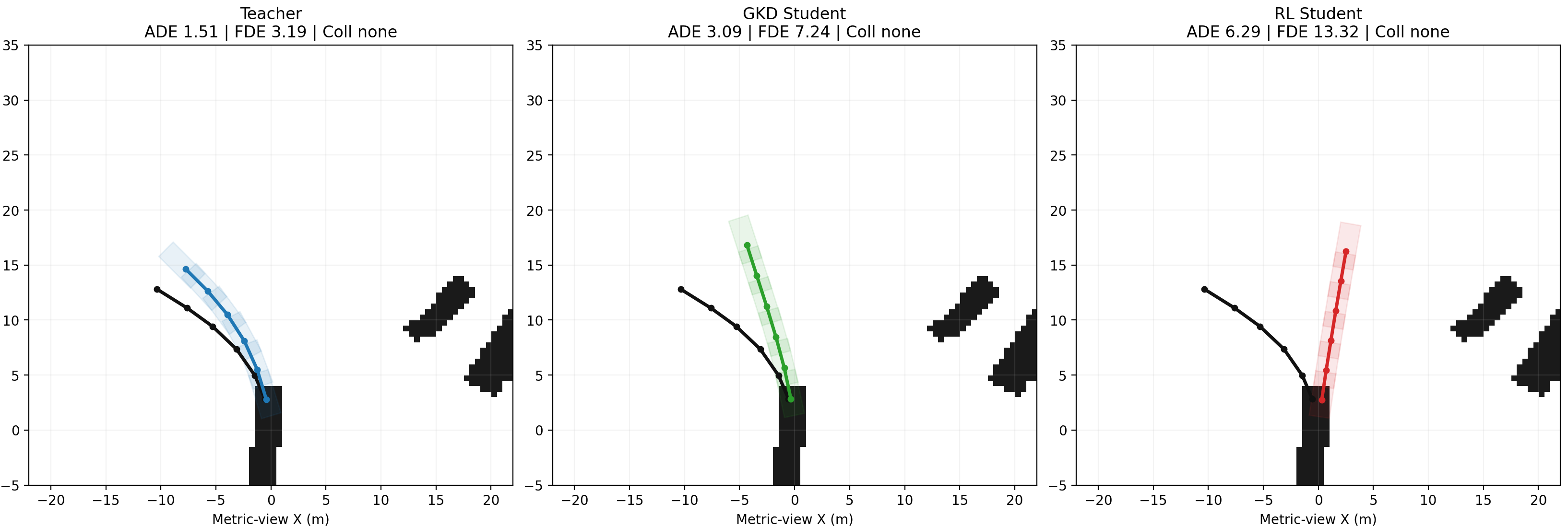
Figure 1: Qualitative trajectory comparison in a left turn scenario; the GKD distillation student (green) tracks the ground truth more faithfully than the RL student (red), with the teacher (blue) providing the closest match.
Analysis and Implications
The comprehensive suppression of train-inference gap by GKD underpins the safety-critical requirements of autonomous planning, where single-token errors in early waypoints can have cascading, hazardous downstream effects. By training on student-generated distributions, GKD enables compressed models to generalize to their own error modes, a property missing from both classical distillation and sampled-token RL imitation.
The empirical results reinforce that dense, full-distribution teacher supervision is required for maintaining sequence consistency in output domains characterized by high structure and long horizons.
The demonstrated 5× reduction in model size with minimal degradation in planning metrics underscores the viability of deploying LLM-based planners on embedded platforms, provided GKD is employed for compression. Additionally, the observed training stability advantages (e.g., RL student overfitting after minimal epochs) further motivate the adoption of distribution-matching approaches in practical, safety-critical distillation pipelines.
Future Directions
Extensions of this research may include sim-to-real and closed-loop testing, data augmentations with vectorized scene representations, scaling studies on teacher–student ratios, and hybrid objectives imposing explicit safety regularization. Further, the integration of on-policy distillation with map-based reasoning and multimodal fusion remains open for investigation, especially as open-weight LLMs and training frameworks further mature.
Conclusion
This work demonstrates that on-policy GKD provides an effective, principled path to compressing LLM-based motion planners for autonomous vehicles, enabling near-teacher performance in trajectory accuracy and collision avoidance with significant resource savings. By explicitly matching the teacher’s token-level output distributions on the student’s own inference trajectories, GKD substantially reduces cascading error accumulation and bridges the resource/performance gap between foundation model research prototypes and real-world deployed planners.
The findings inform both the theoretical development of sequence model distillation algorithms and practical strategies for deploying high-fidelity, interpretable autonomous vehicle planning in hardware-constrained environments.