- The paper introduces Tempo, a unified query-aware compression architecture that leverages small vision-language models for efficient long video understanding.
- It employs a two-stage design where the local compressor segments the video, dynamically allocating tokens via Adaptive Token Allocation to focus on query-relevant evidence.
- The study demonstrates that integrating end-to-end training with temporal anchoring preserves causality and achieves state-of-the-art results on multiple long video benchmarks.
Efficient Long-Video Understanding via Query-Aware Compression: An Analysis of Tempo
Motivation and Context
Long video understanding is fundamentally constrained by the sheer volume of visual data and the fixed context windows of LLMs. As video durations increase, tokenized visual inputs rapidly surpass feasible model capacities, hampering evidence retrieval and inducing severe attention dilution, especially for queries focused on sparse, transient moments. Existing approaches predominantly either sample frames sparsely, thereby risking the loss of salient events, or apply query-agnostic compression—leading to the retention of background redundancy and blurring of fine-grained evidence. Previous attempts at query-aware routing often employ auxiliary modules, decoupling the routing from end-to-end training and limiting optimal allocation.

Figure 1: Tempo achieves SOTA long video understanding via query-aware Adaptive Token Allocation (ATA), dynamically compressing redundant contexts and allocating high bandwidth to query-relevant segments.
The Tempo Framework: Query-Aware Compression Architecture
The paper introduces Tempo, a two-stage, end-to-end architecture for efficient long video understanding. It unifies a Small Vision-LLM (SVLM) as a local compressor with a global LLM as a decoder, bridging visual and text modalities via compression aligned with the query and optimized across both modules.
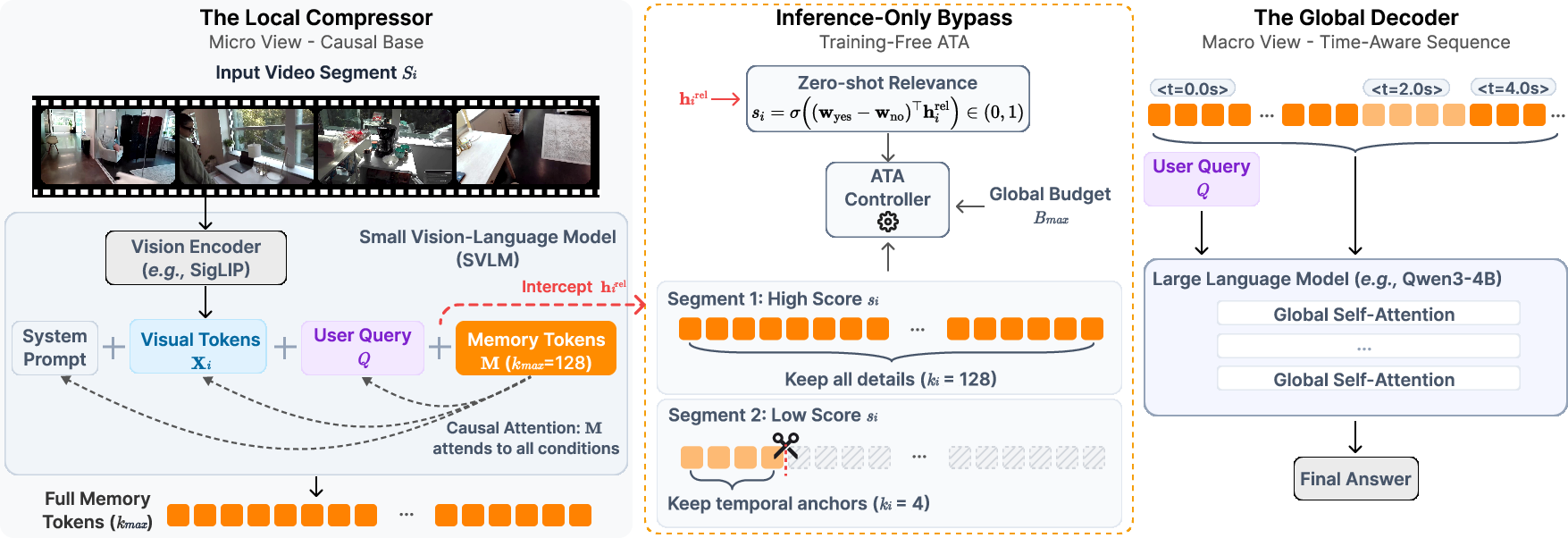
Figure 2: Overview of Tempo’s query-aware, segment-wise compression pipeline and global decoding pipeline.
Key Architectural Elements
- Local Compression: Each video is split into temporal segments, which are processed by an SVLM that encodes visual tokens and the textual query into a fixed-capacity memory bank via causal attention. Memory tokens are appended after the visual and query tokens, concentrating query-aligned evidence into these summary slots.
- Temporal Grounding: To retain the causality and enable temporal attributions, explicit timestamps are prepended when assembling the compressed global context for the LLM.
- End-to-End Training: The entire system is optimized with standard auto-regressive objectives without auxiliary compression losses, thus incentivizing the compressor to distill predictive, query-relevant semantics.
- Compression at Inference: During inference, an Adaptive Token Allocation (ATA) module operates in a training-free regime, leveraging the SVLM’s zero-shot ability to assess segment-query relevance and allocate dynamic per-segment tokens, enforcing a strict global visual budget.
Adaptive Token Allocation: Query-Guided Bandwidth Routing
A central innovation is ATA, an O(1) inference-time policy that dynamically assigns tokens per segment based on segment relevance:
- Relevance Estimation: SVLM is augmented to yield a logit-based binary signal ("Yes/No") regarding query-segment relevance, extracted via additional prompt engineering and logit difference computation before compression within a single forward pass.
- Dynamic Token Mapping: Segment scores are min-max normalized and mapped linearly to token allocations between kmin (temporal anchor) and kmax. The total sum is bounded below the global context budget, with excess budget distributed proportionally.
- Preserving Causality: Minimal temporal anchors are guaranteed for every segment, facilitating global narrative continuity even for discarded portions.
- Efficient High-Fidelity Selection: Exploiting the empirically observed "semantic front-loading"—where key evidence appears in the earliest tokens—token selection is implemented via head truncation, i.e., slicing the first ki memory tokens.
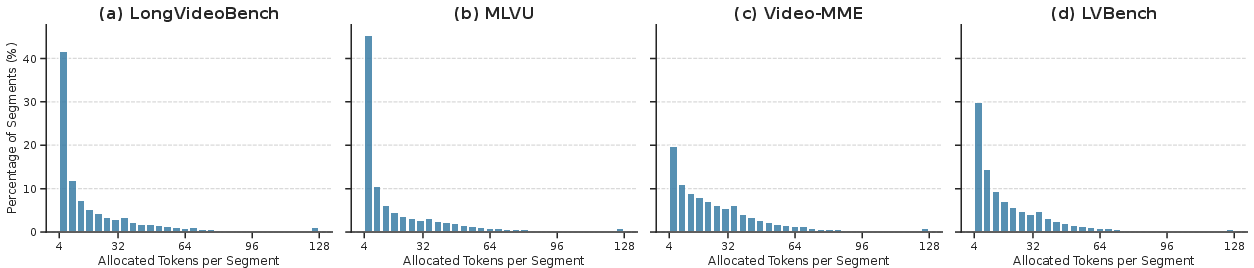
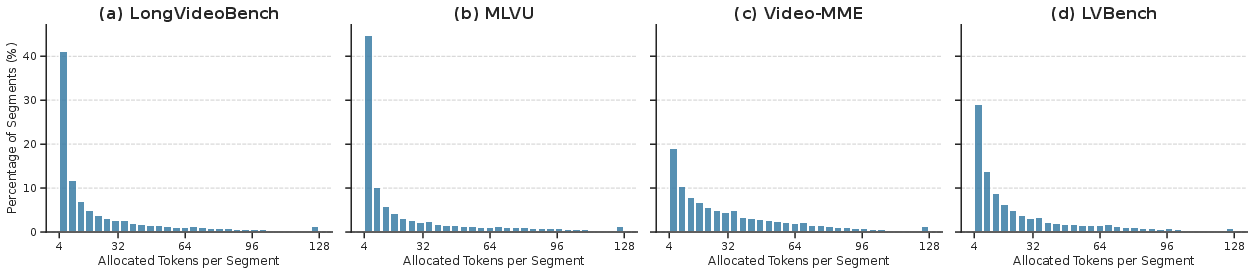
Figure 3: ATA-induced allocation is strongly right-skewed, allocating most segments minimal tokens while selectively amplifying bandwidth for critical segments.
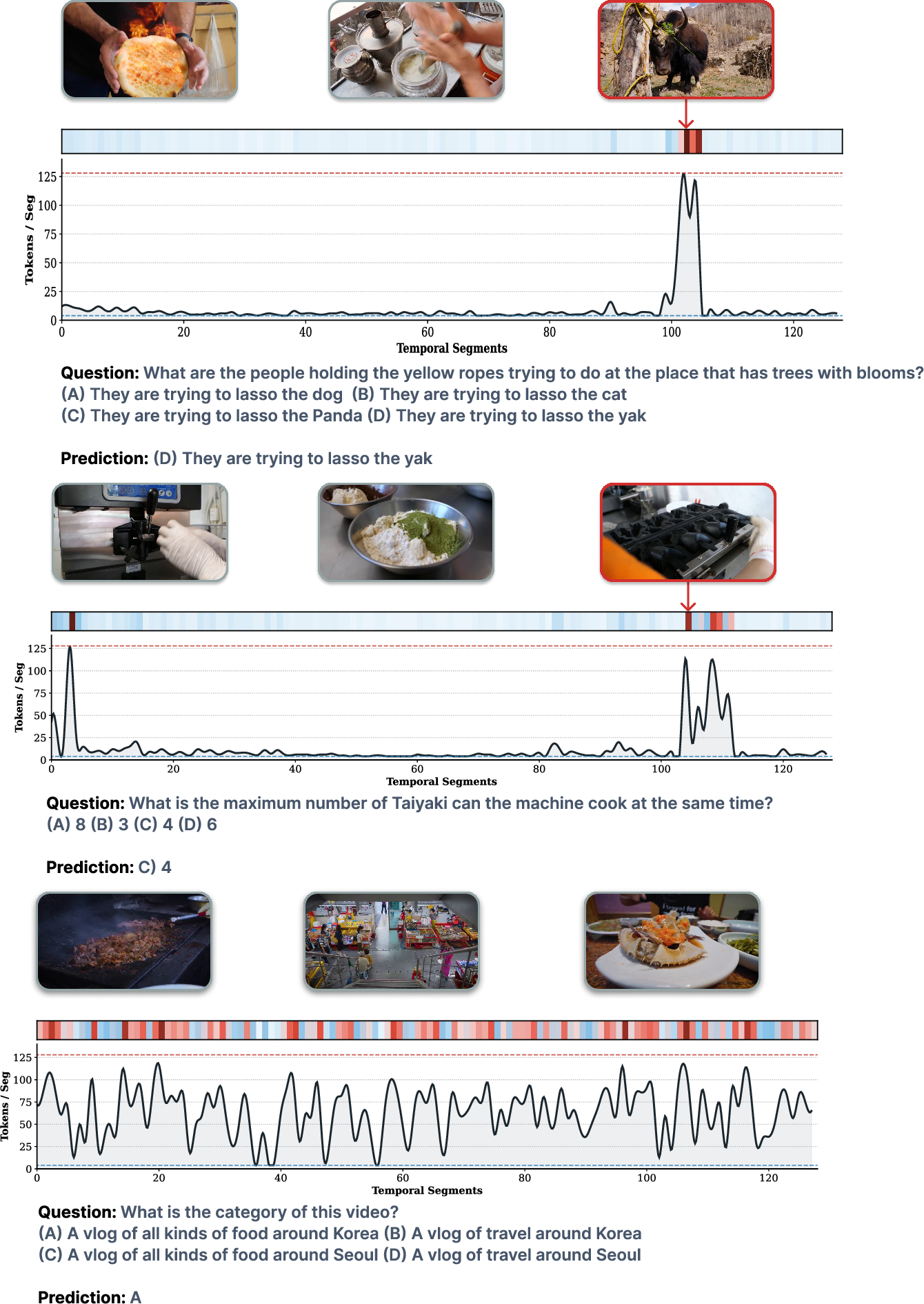
Figure 4: Qualitative ATA allocation: localizes high-density tokens to query-critical moments, while compressing generic contexts, across retrieval, object grounding, and summarization queries.
Experimental Evaluation
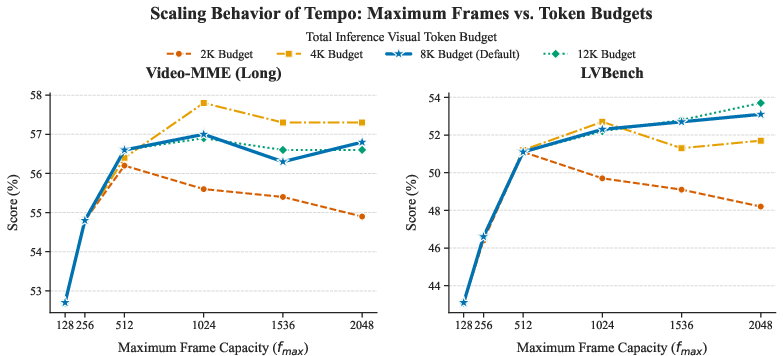
Tempo is rigorously evaluated on major long video benchmarks, including LVBench (hour-long videos), LongVideoBench, MLVU, and Video-MME (long-form and diverse tasks). The model achieves state-of-the-art performance on all domains, often outperforming both open-source and proprietary MLLMs with much larger parameter or context footprints.
Quantitative Highlights
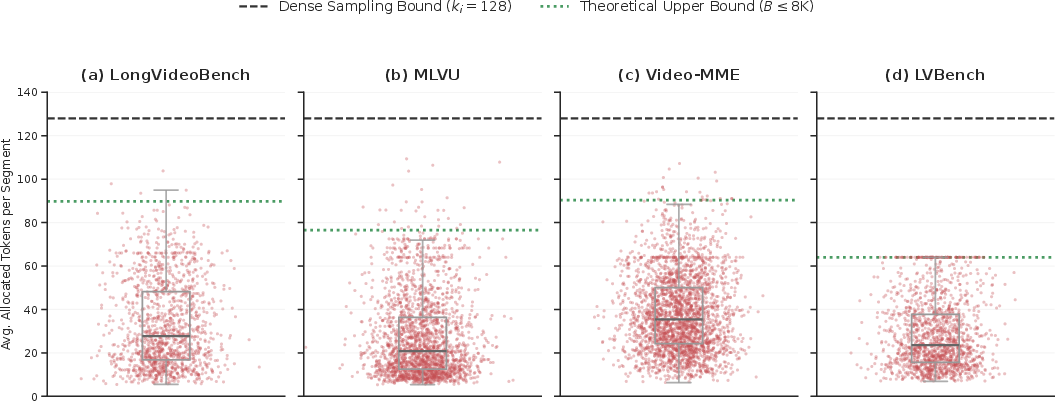
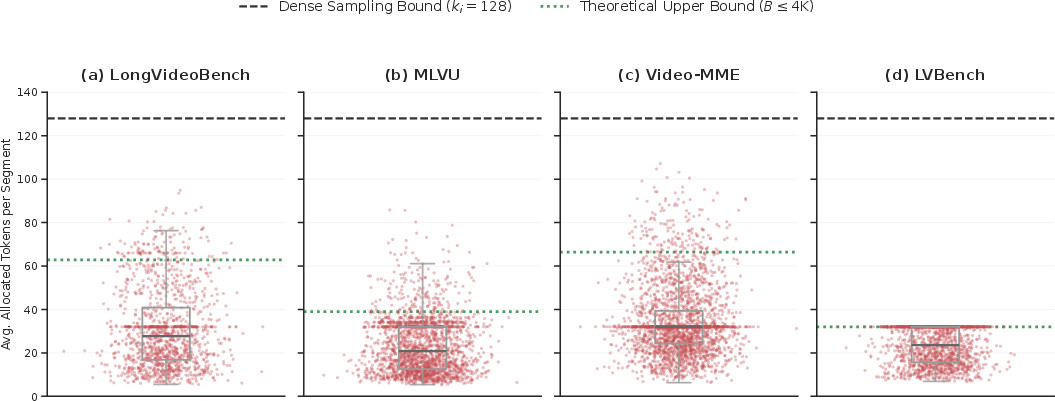
Figure 6: Macro-level consumption: real-world token usage remains well beneath theoretical capacity, except when dictated by extreme video length, confirming adaptive efficiency.
Ablative and Qualitative Analysis
Comprehensive ablation studies dissect the impact of each architectural and inference component, highlighting critical findings:
- ATA vs. Fixed/Random Allocation: Hard-pruning or naive uniform allocations degrade performance, particularly for evidence-sparse queries, confirming ATA’s effective identification of critical events.
- Head vs. Tail Truncation: Head truncation consistently outperforms, validating the semantic front-loading hypothesis and reducing computational overhead—spatial clustering or token merging add little at markedly increased cost.
- Relevance Scoring Source: The explicit routing prompt activates a robust zero-shot prior in the SVLM, providing routing precision that matches or exceeds external reranking modules at zero additional cost.
- Temporal Anchoring: Guaranteeing minimal tokens per segment (rather than dropping low-relevance segments entirely) measurably improves model memory and narrative tracking on hour-long content.
Qualitative visualization reveals context-sensitive allocation (Figure 4): for precise action questions, bandwidth is sharply localized; for global summarization, allocation is dense and smoothly distributed.
Implications and Future Perspectives
Tempo demonstrates that high-efficiency, query-aware visual compression can be achieved using compact SVLMs and adaptive routing without sacrificing performance. Theoretical implications include the confirmation that robust cross-modal distillation, conditioned end-to-end, can drastically mitigate the limitation of fixed LLM context. Practically, such compression enables scalable deployment of long video understanding on resource-constrained platforms, with applications in surveillance analysis, streaming content curation, and real-time video QA.
Noteworthy research trajectories include:
- Elicitation of Relevance Priors: Further post-training or RL could amplify SVLM routing capabilities, making allocation even more precise and potentially adaptive to evolving downstream requirements.
- Autoregressive Compression: Enabling segment-level compressors to determine allocation length at inference could further optimize both efficiency and fidelity, albeit at the cost of added inference complexity.
- Interactive and Multi-Turn Routing: Hierarchical or on-demand refinement could empower global LLMs to iteratively invoke compression on demand, closely integrating dialogue systems with real-time video evidence demands.
Conclusion
Tempo (2604.08120) establishes a new direction for long video understanding by explicitly unifying cross-modal compression and query-aware allocation. It leverages the zero-shot alignment capabilities of SVLMs for efficient, interpretable, and dynamically routed compression, outperforming substantially larger and more computationally expensive models. This study provides both methodological and empirical evidence that fine-grained, task-aware reduction is superior to naive context expansion or fixed sampling for scalable multimodal reasoning over temporally extended data.