TAM: Torque Adaptation Module for Robust Motion Transfer in Manipulation
Abstract: A policy tuned for one robot often behaves differently on another, whether due to the sim-to-real gap, unknown payloads, or the differing dynamics of two instances of the same robot. In contact-rich, dynamic manipulation, even small motion discrepancies can result in failure to track reference motion, since they disrupt the timing and modes of contact. Common remedies, such as domain randomization or system identification, either produce overly conservative task policies or require data that must be recollected for each robot or payload. We introduce the Torque Adaptation Module (TAM), a learned module that adapts the torque commands sent to the robot to match the behavior of an ideal robot. TAM operates between the low-level controller that tracks the policy's actions and the robot's torque interface. It includes a history encoder that embeds proprioceptive history into a latent state and a torque adaptor that computes residual torque corrections. Because TAM depends only on proprioceptive history and not on policy observations, or the action space, the same TAM weights can be reused to adapt policies with different action spaces (joint targets, end-effector targets, or direct torques). The policies themselves do not need to be trained with domain randomization of robot parameters. Instead, we offload the need for domain randomization to TAM by training it entirely in randomized simulation, using multi-robot pretraining followed by a robot-specific fine-tuning step that still requires no real-robot data. We evaluate TAM zero-shot on a real Franka Panda robot across dynamic manipulation tasks that include a vision-based box pushing policy (from RL), a flip policy (from BC), and an MPC ball-on-plate balancing. Our experiments show that TAM improves zero-shot real-robot execution compared to online system identification and RMA baselines and enables robust dynamic manipulation performance.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
Robots often learn skills in a computer simulation or on one “reference” robot. But in the real world, even small differences—like extra weight in the hand, slightly different motors, or friction—can make those same skills fail. This paper introduces a tool called the Torque Adaptation Module (TAM). Think of TAM as a super-fast “helper” that slightly adjusts the robot’s muscle signals (torques) so the real robot moves more like the perfect robot the skill was designed for.
The main questions the paper asks
- Can we fix motion mismatches by adjusting only the torques sent to the robot’s joints, without changing or retraining the task policy (the brain) that decides what to do?
- Can one single module work with many kinds of policies (from Reinforcement Learning, Behavior Cloning, or Model Predictive Control) and action types (joint targets, end‑effector targets, or direct torque)?
- Can we train this module entirely in simulation and still get good results on real robots, even when the robot carries unknown payloads?
- Will this approach generalize to different robot models?
How TAM works (in simple terms)
Imagine a coach (the policy) tells an athlete what movement to make. A regular controller translates that plan into muscle signals. But the athlete’s body is a little different from the coach’s assumptions—so the movement comes out wrong. TAM steps in like a tiny, super-quick physiotherapist, adding small, smart tweaks to those muscle signals so the movement matches what the coach intended.
Here’s the flow, with plain-language explanations of key pieces:
- Policy: The “brain” that outputs an action. It could be trained by:
- Reinforcement Learning (RL): learning by trial and error in simulation.
- Behavior Cloning (BC): copying demonstrations.
- Model Predictive Control (MPC): planning with a math model.
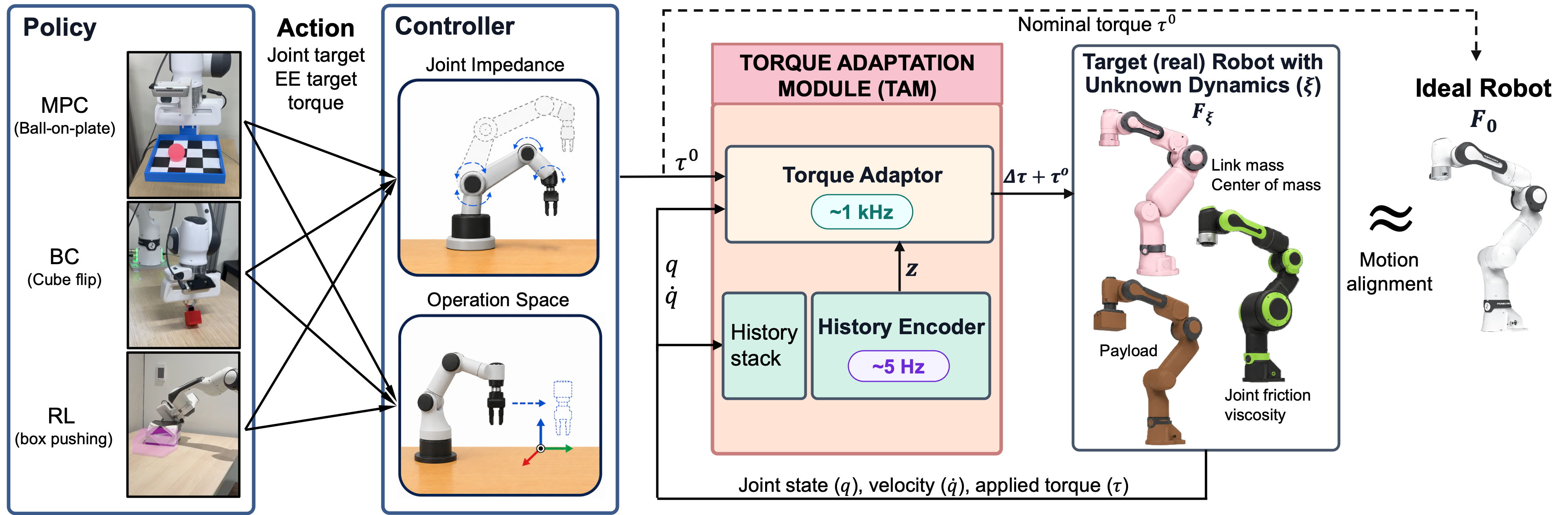
- Low-level controller: Converts the policy’s action into “nominal torque” (the torque you would send if the robot were perfect).
- TAM (the new part):
- History encoder (runs ~5 times per second): Looks at the recent “proprioceptive” history—what the robot felt in its joints (positions, speeds, and the torques it actually applied). It compresses this into a short summary called a “latent state” z. You can think of z as a quick guess of how this real robot differs from the ideal one (e.g., more friction, extra weight).
- Torque adaptor (runs 1,000 times per second): Uses z plus the current joint signals to add a tiny correction torque to the nominal torque. This is called a “residual.” The sum (nominal + residual) is what goes to the motors.
A few helpful definitions:
- Torque: The twisting force at a joint (like how hard you turn a screwdriver).
- Nominal torque: The torque you’d use if the robot matched its ideal model perfectly.
- Residual torque: A small correction added on top of the nominal torque.
- Proprioception: The robot’s built-in sense of its joint positions, speeds, and efforts.
- Latent state (z): A compact summary capturing how the real robot currently differs from the ideal one.
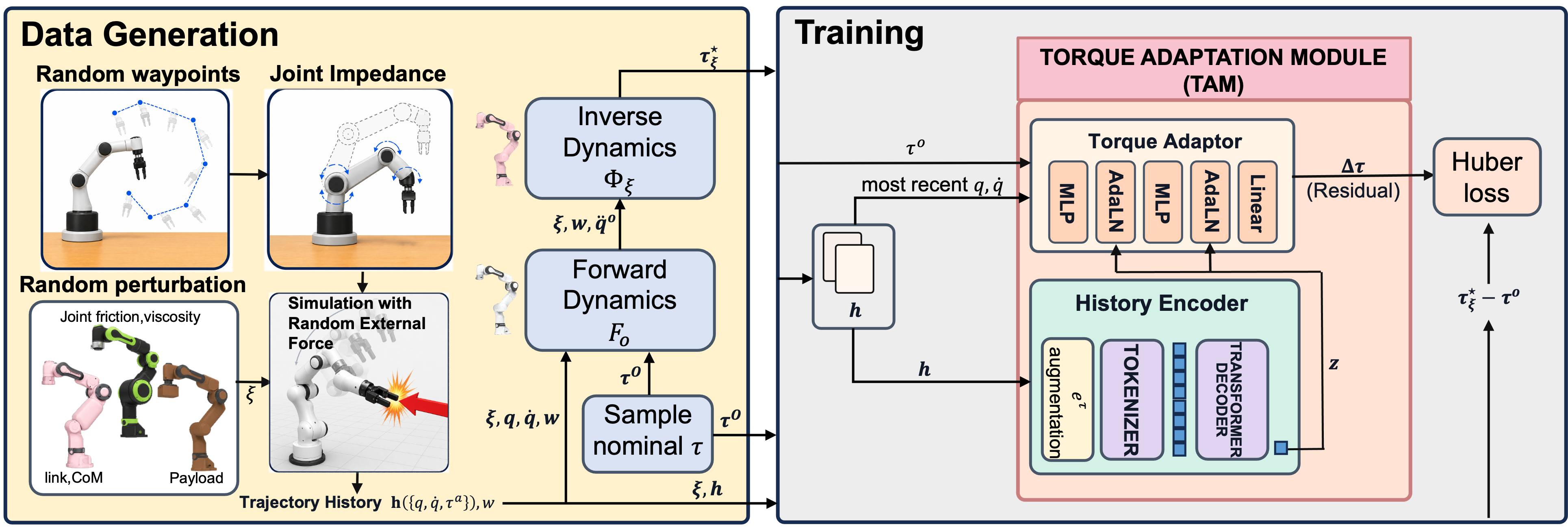
How TAM is trained (no real robot data needed)
- The team trains TAM entirely in simulation with lots of randomness: different robot parameters, pretend payloads, and gentle external forces (to mimic contacts).
- They first pretrain on several different robot models (multi-robot pretraining), then (optionally) fine-tune for a specific robot in simulation (robot-specific fine-tuning).
- Instead of making the policy itself robust to all these differences (which can make policies conservative or require retraining), TAM learns to fix the mismatch at the torque level. This means the same TAM can be reused across different policies and action spaces, as long as the system can compute nominal torques.
What they found and why it matters
Across several challenging tasks on a real Franka Panda robot, TAM made the real robot behave much closer to the ideal robot without changing the policies.
Here are the main results, summarized in simple terms:
- Vision-based box pushing (RL policy): With TAM, success improved notably compared to sending torques directly and compared to online system identification (a method that tries to estimate robot parameters during the task). It also improved a well-known adaptive policy baseline (RMA) when used together.
- Fast flipping (BC policy): This is a short, contact-heavy move that’s very timing-sensitive. TAM reached about 72% success, close to the ideal-simulation result (~73.5%), and clearly better than direct transfer (~50%) and online system identification (~34%).
- Ball-on-plate (MPC planner): The robot tilts a plate to move a ball to many targets. With TAM, the number of goals reached in 15 seconds rose to about 13.6, better than direct transfer (~8.8) and slightly better than online system identification (~13.1), and close to the ideal-simulation result (~15.9).
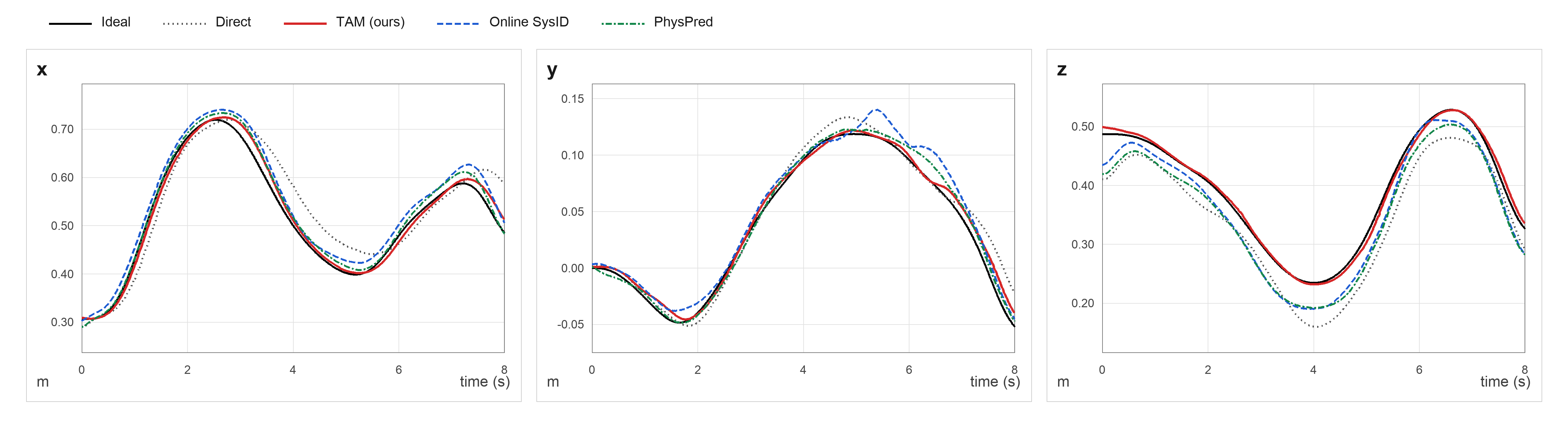
- Tracking accuracy with unknown payloads and controller changes: When switching controllers and adding a 1 kg payload, TAM reduced end-effector position errors from several centimeters (about 4–6 cm) down to around 1–1.3 cm.
- Generalization across robot models (in simulation): A single, shared TAM model (pretrained on multiple robots) lowered tracking errors for several different arms, including some never seen during training. Fine-tuning in simulation for the target robot improved accuracy even more.
Why this is important:
- You don’t need to retrain or redesign your task policy every time the robot changes or picks up a new object.
- You can reuse the same task policy (even a closed-source one) and just drop in TAM at the torque interface.
- It adapts fast (at 1 kHz), which helps with dynamic, contact-rich tasks where timing matters.
What this could change in the real world
- Easier deployment: Companies and labs can train policies once on an ideal model and then use TAM to handle real-world differences, saving time and effort.
- Greater reuse: The same TAM weights can work under many policies and action spaces—RL, BC, or MPC—so teams can mix and match.
- Fewer risky real-world trials: Because TAM is trained in simulation, you can avoid collecting new real-world data for every robot or payload.
- Better performance on dynamic tasks: Tasks that rely on precise timing and contact (like flipping or pushing) become more reliable.
Note: TAM needs access to the robot’s torque interface and assumes the real robot’s basic structure (joint layout) matches the ideal model. It also corrects locally (moment-to-moment), so extremely heavy payloads or forces beyond the robot’s limits can’t be fixed by software alone.
In short, TAM is like adding smart, adaptive “power steering” to a robot’s joints. It lets many different skills work more reliably on real hardware without retraining, bringing simulation-trained abilities much closer to plug-and-play in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains uncertain or unexplored, framed to guide follow-up research.
- Access constraints: TAM requires a torque interface and applied-torque telemetry; feasibility on robots with only position/velocity APIs or no torque sensing remains untested (e.g., can TAM operate with only commanded torque, or with an estimator?).
- Label generation dependence: Training relies on an analytic inverse torque-command map Φξ in simulation; many real actuators (backlash, saturations, nonlinear transmissions, SEA) lack accurate invertible models. How to train TAM when Φξ is unavailable or severely biased?
- Ideal-model fidelity: TAM aligns to F0 (the “ideal” model). If F0 is wrong (e.g., unmodeled elasticity or joint coupling), TAM may faithfully match the wrong target. How to detect and correct ideal-model misspecification or jointly refine F0?
- Local objective vs. global behavior: The learning target is one-step motion alignment; there are no guarantees of closed-loop stability, passivity, or constraint satisfaction over horizons. Can we provide Lyapunov/passivity guarantees or integrate CBF/CLF constraints at the torque-residual layer?
- Contact vs. robot-mismatch ambiguity: External contact w is unknown at deployment; randomized w during training may not cover real contact patterns. How can TAM robustly disambiguate contact forces from robot-side mismatch (e.g., via tactile/force sensors, vision, or contact classifiers)?
- Saturation handling: Residuals are clipped to torque limits; no strategy is provided for operation beyond actuator authority. How should TAM detect, predict, and gracefully degrade (e.g., replan, slow down, switch control modes) under persistent saturation?
- Cold-start latency: The history encoder takes ~0.5 s to produce a latent; short, contact-rich episodes (e.g., flips) are sensitive to this delay. Can pre-activation routines, priors, or fast “few-shot” history initialization reduce cold-start error?
- History design and identifiability: It is unproven which dynamics mismatches are identifiable from proprioception-only history. What classes of parametric and nonparametric deviations are observable, and what history length/features are minimally sufficient?
- Cross-joint coupling: The torque adaptor uses per-joint MLPs conditioned by a latent; it is unclear whether this architecture captures strong cross-joint couplings and non-diagonal inertial effects. Would explicitly coupled outputs or structured dynamics layers improve performance?
- Sensor noise and latency: Sensitivity to encoder quantization, torque sensor bias, clock drift, communication jitter, and filtering is not analyzed. What robustness margins and filtering/observer designs keep TAM stable at 1 kHz on embedded hardware?
- Runtime footprint: The adaptor runs at 1 kHz and the encoder at ~5 Hz; compute and memory budgets for embedded controllers are not reported. What is the worst-case latency, CPU/GPU footprint, and scheduling strategy needed for deterministic timing?
- Nonstationary dynamics: Real robots drift thermally, wear mechanically, and experience payload changes mid-episode. Can TAM track nonstationarity (e.g., adaptive encoder update rates, forgetting factors) without retraining?
- Continual/on-robot learning: TAM weights are fixed at deployment; only the latent state adapts. Is safe on-robot fine-tuning possible without Φξ or privileged labels, and how to constrain it for safety and data efficiency?
- Training coverage: Data are free-space joint rollouts with synthetic generalized torques; real manipulation involves structured, state-dependent contact dynamics. How to generate training data that capture realistic interaction modes (e.g., object sets, grasp states, friction regimes)?
- Policy/TAM co-design: Policies are trained without robot-side randomization and are not co-adapted with TAM. Would joint training (while preserving policy reusability) yield better performance, e.g., via modular distillation or adapters?
- Low-level controller diversity: Real tests switch between joint impedance and OSC; broader controllers (admittance, hybrid force/motion, factory torque loops with unknown filters) are untested. How robust is TAM across controller changes and nested filters?
- Safety and passivity: Injecting residual torques may reduce passivity margins or conflict with OEM safety controllers. Can TAM be constrained to maintain passivity/energy bounds and coexist with safety interlocks?
- Real-robot generalization: Real-world results are limited to a single physical robot (Franka Panda). Do the multi-robot simulation gains translate to other hardware (e.g., different transmissions, SEAs, cable drives, high-gear-ratio arms)?
- Task diversity and difficulty: Evaluations cover pushing, flipping, and ball-on-plate. Performance on force-controlled assembly, precision insertion, high-speed impacts, and constrained manipulation remains unknown.
- Baseline breadth: Comparisons omit strong neural actuator models and recent dynamics-alignment frameworks that directly model actuator nonlinearities. A head-to-head comparison would clarify the unique benefits of torque-residual adaptation.
- External-torque modeling: Training uses known w in simulation; the realism of w distributions and the impact of mis-specified contact forces on learned corrections are not quantified. How sensitive is TAM to w-model errors?
- Robustness to large morphology gaps: The method assumes matched kinematic structure and actuator ordering. Can TAM be extended to different kinematic trees or underactuated/branched manipulators via learned torque-space mappings?
- Energy and wear: Residual torques could increase energy consumption or mechanical stress. What are the impacts on thermal load, actuator wear, and compliance with duty-cycle limits?
- Scaling laws: It is unclear how multi-robot pretraining scales with the number/diversity of robots and data volume. What are the sample-efficiency and transfer scaling laws, and how much target-robot sim fine-tuning is needed?
- Latent refresh rate: The encoder updates z at ~5 Hz; how quickly must z adapt during abrupt changes (e.g., payload picked up mid-trajectory)? Would event-triggered updates or hierarchical latents improve responsiveness?
- Failure detection and recovery: No mechanisms are provided for detecting adaptation failure (e.g., persistent tracking error, oscillations) and triggering recovery (controller switch, replan, reduce gains).
- Missing ablations on hardware: Architectural ablations (history length, eτ feature, coupling) are reported primarily in simulation; real-hardware ablations would clarify practical trade-offs and minimal configurations.
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed now, derived from TAM’s torque-interface adaptation, history-encoder design, and multi-robot pretraining + robot-specific sim fine-tuning pipeline.
- Robust deployment of existing policies across robot instances and payloads (Manufacturing, Logistics, Robotics integration)
- Use TAM as a plug-in between the low-level controller and manipulator to compensate for sim–real gaps and unknown payloads without retraining policies (RL/BC/MPC). Reduces commissioning time when switching tools or adding payloads (e.g., +1 kg end-effector).
- Potential tools/products/workflows: ROS 2 controller plugin for TAM; pre-trained TAM weights for common arms (e.g., Franka Panda); “commissioning kit” to test and validate tracking RMSE before go-live.
- Assumptions/dependencies:
- Robot exposes a torque API and can run the torque adaptor at ~1 kHz (low-latency control loop).
- Ability to convert policy actions to nominal torque (joint targets, OSC, or direct torques).
- Access to a reasonable ideal model for the task and robot; safety torque clipping configured.
- Vendor-agnostic skill reuse with closed-/third-party policies (Systems integrators, OEMs, Software)
- Deploy third-party or closed-source policies without re-training by adapting at the torque interface (TAM is neutral to action space and policy internals).
- Potential tools/products/workflows: “TAM compatibility” badge for skill libraries; adapters for popular low-level controllers (impedance, OSC).
- Assumptions/dependencies:
- Action-to-torque conversion available; minimal integration effort to insert TAM below the controller.
- Sufficient compute to run a ~5 Hz encoder and 1 kHz torque adaptor on embedded or edge hardware.
- Rapid changeover and tool/payload variability compensation (SME cobots, Warehouse/fulfillment, Lab automation)
- Maintain task performance across frequent end-effector or payload changes (e.g., changing grippers, fixtures) without re-tuning policies or re-identifying system parameters.
- Potential tools/products/workflows: “Changeover mode” that cold-starts TAM and reaches steady adaptation within ~0.5 s; pre-run routines to prefill history for carried-state benefits.
- Assumptions/dependencies:
- Payloads and contact forces stay within actuator torque limits (clipping protects hardware but cannot fully compensate beyond limits).
- Controller migration with behavior preservation (Robotics integration, QA/Commissioning)
- Switch between joint impedance and operational-space control while maintaining motion tracking and task performance; helpful when moving from simulation to on-robot OSC.
- Potential tools/products/workflows: A/B controller testing with TAM in the loop; automated tracking RMSE dashboards.
- Assumptions/dependencies:
- Consistent kinematics and actuator ordering between the ideal and target robot.
- Sufficient historical context for the encoder; carried-state improves performance around controller switches.
- Improved performance for model-based controllers (MPC) on real hardware (R&D labs, Advanced automation)
- Use TAM to align real-robot responses to the ideal model assumed by MPC, improving goal completion rates in dynamic tasks (e.g., ball-on-plate).
- Potential tools/products/workflows: MuJoCo MPC + TAM packaged examples; “TAM-on” vs “TAM-off” validation scripts for planning stacks.
- Assumptions/dependencies:
- Ideal model quality is reasonable for MPC design; TAM handles residual mismatch but not gross modeling errors.
- Research and teaching in sim-to-real transfer without policy-side randomization (Academia, Education)
- Teach robust transfer by training policies on ideal models and offloading robot-side randomization to TAM; run lab exercises across multiple robot arms in simulation first.
- Potential tools/products/workflows: Curricula with multi-robot pretraining in MuJoCo Menagerie, robot-specific fine-tuning, and real-lab validation; shared model zoo of TAM weights.
- Assumptions/dependencies:
- Access to inverse torque-command maps in simulation for label generation during TAM training.
- Fleet-level maintenance and reproducibility (Service robotics, Fleet operators)
- Standardize on a single TAM model per robot type to reduce drift across units and improve reproducibility of skill performance across a fleet.
- Potential tools/products/workflows: Fleet manager integration that distributes updated TAM weights and tracks performance KPIs (tracking RMSE, success rates).
- Assumptions/dependencies:
- Versioning and telemetry to monitor adaptation quality; process for safe rollback.
- Safety envelope tightening during dynamic manipulation (Industrial safety engineering)
- Reduce overshoot and timing errors in contact-rich tasks (e.g., flipping) via local torque corrections and clipping, lowering likelihood of unintended impacts.
- Potential tools/products/workflows: TAM-enabled safety profiles; pre-task safety checks that verify torque headroom.
- Assumptions/dependencies:
- No formal stability guarantees; safety still requires conservative limits and monitoring.
Long-Term Applications
These use cases likely require further research, scaling, regulatory maturation, or additional tooling beyond what the paper demonstrates.
- Standardized, vendor-wide torque adaptation layer and “skill marketplaces” (Robotics, Software ecosystem, Policy/Standards)
- A common torque-adaptation API across vendors enabling cross-robot skill portability; skills shipped with TAM-compatibility metadata.
- Potential tools/products/workflows: Industry standards specifying torque-interface access and latency; certification test suites that include variable payload and controller-switch scenarios.
- Assumptions/dependencies:
- Broad adoption of torque-level APIs and agreed kinematic/actuator conventions.
- Legal/IP frameworks for distributing closed-source policies with TAM-based deployment.
- Extension to position-only or low-rate controllers via learned command inversion (Robotics, OEMs)
- Add a learned command-inversion layer to apply TAM for robots without torque interfaces or with low-rate control, broadening applicability to legacy systems.
- Potential tools/products/workflows: Position/velocity-to-torque proxy models integrated with TAM; hybrid control stacks.
- Assumptions/dependencies:
- Additional learning and validation to ensure stability with indirect torque inference.
- Potential performance loss vs. native torque control.
- Contact-rich assembly and force-aware manipulation with explicit external-wrench separation (Manufacturing, Electronics assembly)
- Train TAM variants to disentangle robot-side mismatch from external contact dynamics (e.g., tight-tolerance insertion), possibly fusing tactile/force sensors.
- Potential tools/products/workflows: Contact-mode-aware encoders; datasets with rich contact distributions and force profiles.
- Assumptions/dependencies:
- Richer sensing (force/torque, tactile); expanded training distributions to avoid confusing contact with mismatch.
- Unified adaptation for mobile manipulation and legged loco-manipulation (Warehousing, Field robotics)
- Extend torque adaptation to multi-body systems (manipulator + mobile base or legs), enabling consistent behavior across varied terrains and configurations.
- Potential tools/products/workflows: Joint adaptation that spans arm and base actuators; multi-rate encoders for different subsystems.
- Assumptions/dependencies:
- Coordinated control loops and accurate ideal models for all subsystems; increased compute and bandwidth.
- Healthcare and assistive robotics under regulatory constraints (Rehabilitation, Surgical robotics)
- Use TAM to reduce re-tuning for patient-specific loads or tool changes while preserving intended kinematics; potential to lower commissioning overhead in clinical settings.
- Potential tools/products/workflows: Safety-certified TAM variants with formal verification, runtime monitors, and fail-safe fallbacks.
- Assumptions/dependencies:
- Regulatory approval (ISO/IEC standards, clinical validation), formal safety analyses, and conservative torque limits.
- Energy-efficient torque shaping and thermal management (Energy, Sustainability)
- Modify training objectives to jointly align motion and minimize energy/heat, yielding lower operational costs and longer actuator life.
- Potential tools/products/workflows: TAM variants with energy-aware loss functions and telemetry-guided fine-tuning.
- Assumptions/dependencies:
- Accurate energy/thermal models; multi-objective optimization balancing tracking vs. energy.
- Self-calibrating fleets with minimal or no real data (Robotics, Cloud services)
- Cloud services that simulate robot-specific variations and deliver fine-tuned TAM weights, supplemented by minimal on-robot unsupervised adaptation.
- Potential tools/products/workflows: Automated simulation pipelines (digital twins), online confidence estimators triggering re-sim fine-tunes.
- Assumptions/dependencies:
- High-fidelity simulation assets and inverse command maps; robust domain coverage for new hardware revisions.
- Digital twin alignment as a service (Software, Industrial IoT)
- Integrate TAM into digital twins so that planning, forecasting, and virtual commissioning more closely match on-floor behavior.
- Potential tools/products/workflows: Twin-in-the-loop commissioning; APIs to stream encoder latents and residuals back to the twin for diagnostics.
- Assumptions/dependencies:
- Secure, low-latency data exchange; IT/OT integration; governance for data privacy.
- Generalization to other torque-controlled articulated systems (Exoskeletons, Haptic devices, Camera gimbals)
- Apply TAM’s history-conditioned residual correction to stabilize and align user-facing devices to their intended model behaviors, reducing drift and improving feel.
- Potential tools/products/workflows: Embedded TAM microcontrollers; SDKs for wearable robotics.
- Assumptions/dependencies:
- Safe real-time operation and user-in-the-loop safety measures; adaptation to human-in-the-loop variability.
- Formal guarantees and certification-ready adaptation (Safety engineering, Policy)
- Develop stability and constraint-satisfaction guarantees for torque residuals over long horizons, enabling certification for high-stakes deployments.
- Potential tools/products/workflows: Verified encoders/adaptors with bounded outputs; runtime supervisors enforcing invariants.
- Assumptions/dependencies:
- New theory and tooling to connect local alignment to global safety; conservative bounding of residual torques.
Cross-cutting assumptions and dependencies
- Torque interface: Immediate deployment relies on access to joint-torque commands and ~1 kHz control; otherwise, a command-inversion layer is needed.
- Ideal model and inverse maps: Training TAM needs an ideal model and inverse torque-command maps in simulation for label generation; inaccuracies limit achievable alignment.
- Kinematic/actuator compatibility: Ideal and target robots must share kinematic structure and actuator ordering; major morphology changes require re-architecting.
- Compute and latency: On-robot or edge compute must support a ~5 Hz history encoder and a 1 kHz torque adaptor with minimal added latency.
- Safety and torque limits: All corrections are clipped; tasks must remain within actuator authority and adhere to safety limits; no formal guarantees are provided by default.
- Training distribution coverage: Randomizations must cover likely real-world parameter variations, payloads, and contact patterns; out-of-distribution contacts may degrade performance.
Glossary
- Adaptive layer normalization: A conditioning technique that modulates normalization statistics using a context vector to adapt network behavior. "through adaptive layer normalization"
- Behavior Cloning (BC): A supervised learning approach that learns a policy by imitating actions from demonstrations. "behavior cloning (BC)"
- Causal Transformer: A Transformer architecture with causal masking so each token attends only to past tokens, enabling autoregressive sequence modeling. "A naive causal Transformer"
- Contact wrench: A 6D vector of forces and torques at a contact, often mapped to joint space via the Jacobian transpose. "e.g., a contact wrench mapped through "
- Dead zone: An actuator nonlinearity where small input commands produce no output. "dead zones"
- Domain randomization: A sim-to-real technique that randomizes simulator parameters during training to improve robustness to real-world variation. "domain randomization"
- End-effector: The tool or distal part of a manipulator (e.g., gripper) whose target pose or trajectory is commanded. "end-effector targets"
- Forward dynamics: The mapping from current state and input torques (and external forces) to resulting accelerations. "forward-dynamics map"
- Generalized torque: Joint-space torques that include the effect of external forces/contacts expressed in joint coordinates. "external generalized torque"
- Huber loss: A robust loss that is quadratic near zero error and linear for large errors, reducing sensitivity to outliers. "the Huber loss is applied"
- iLQR (iterative Linear Quadratic Regulator): An optimal control algorithm that iteratively solves locally linear-quadratic approximations of a nonlinear control problem. "with an iLQR planner implemented through MuJoCo MPC"
- Impedance control: A control strategy that regulates the dynamic relationship between motion and force like a virtual spring-damper system. "joint impedance control"
- Inverse torque-command map: A model-based mapping that returns the torque needed to achieve a desired acceleration under given dynamics. "inverse torque-command map"
- Jacobian transpose (JT): The transpose of the manipulator Jacobian used to map task-space forces to joint torques. "mapped through "
- Kinematic structure: The arrangement of links and joints defining the robot’s geometry independent of dynamics. "share kinematic structure"
- Latent state: A compact hidden representation inferred from history that summarizes properties (e.g., dynamics mismatch) relevant to control. "latent state"
- Low-level controller: The controller that converts high-level policy actions (e.g., targets) into torque commands at high frequency. "low-level controller"
- Model Predictive Control (MPC): An optimization-based control method that solves a finite-horizon control problem online at each step. "model predictive control (MPC)"
- MuJoCo Menagerie: A curated collection of MuJoCo robot models and assets for simulation. "MuJoCo Menagerie"
- Operational-Space Control (OSC): A control framework that regulates motion/force in task space rather than joint space. "operational-space control (OSC)"
- Particle filter: A sequential Monte Carlo method for online state or parameter estimation using a set of weighted samples. "particle filter"
- Patch-wise time-series tokenization: Splitting long time series into overlapping temporal patches to form tokens for attention models. "patch-wise time-series tokenization"
- Plant (robot plant): The physical system being controlled, here the robot hardware receiving torque commands. "robot plant"
- Point cloud: A set of 3D points (often from depth sensing) used as visual input for policies. "partial point cloud"
- Proprioception: Sensing of the robot’s internal state, such as joint positions, velocities, and torques. "current proprioception"
- Rapid Motor Adaptation (RMA): A method that infers latent dynamics from observation history to adapt a control policy online. "RMA adapts inside the policy"
- Residual policy: A policy that outputs additive corrections on top of a nominal command to improve performance. "Learn a residual policy"
- Residual torque: An additional torque added to nominal torque to compensate for dynamics mismatch. "residual torque corrections"
- Sim-to-real gap: The mismatch between simulated and real-world dynamics that causes performance degradation when transferring policies. "sim-to-real gap"
- System identification: Estimating model parameters of a system from observed inputs and outputs to better match real dynamics. "system identification"
- Torque adaptor: The learned module that predicts residual torques to correct nominal torque commands. "torque adaptor"
- Torque interface: The control boundary/API where joint torques are commanded to the robot actuators. "torque interface"
- Unified Robot Description Format (URDF): A standardized XML format describing a robot’s kinematics and inertial parameters. "URDF provided by the manufacturer"
- Zero-shot: Deploying to a new condition or hardware without additional fine-tuning or real-world data collection. "TAM zero-shot"
Collections
Sign up for free to add this paper to one or more collections.

