M3imic: Learning a Versatile Whole-Body Controller for Multimodal Motion Mimicking
Abstract: Building a general-purpose whole-body controller is essential for enabling diverse motion capabilities in humanoid robots across a wide range of downstream tasks, including locomotion and loco-manipulation. Different tasks rely on distinct motion reference modalities: locomotion primarily depends on coordinated robot joint trajectories, whereas manipulation requires precise end-effector trajectory tracking. Existing methods often overlook the representational mismatch between dense robot joint angles and sparse end-effector poses. To address this, we propose Multi-Modal Mimic (M3imic), a versatile multi-modal whole-body control framework that unifies heterogeneous motion reference modalities, including robot joint angles, human pose trajectories, and end-effector poses, using modality-specific encoders to map them into a shared latent space. Leveraging large-scale reinforcement learning in the simulator, we train a single policy that achieves sim-to-real transfer across multiple motion reference modalities without modality-specific retraining. Extensive simulation and real-world experiments on the Unitree G1 robot are conducted to evaluate the proposed framework. In simulation, the policy achieves a peak success rate of 98.42\% on an unseen test dataset, demonstrating its exceptional generalization capability. The code is available at https://github.com/Renforce-Dynamics/MultiModalWBC


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper is about teaching a humanoid robot (a robot shaped like a person) to copy many kinds of movements—like walking, dancing, or using its hands—using one smart controller. The special trick: the robot can follow different kinds of instructions (for example, full joint angles, a human body pose, or just where hands and feet should go) without needing to be retrained for each type. The authors call their method M3imic (Multi-Modal Mimic).
What questions the researchers wanted to answer
The study focuses on three easy-to-understand questions:
- Can one robot controller learn to follow different kinds of movement instructions (detailed or simple) equally well?
- How do training choices—like model size and how much data you use—change how good the robot becomes?
- Will a controller trained in a simulator still work well in the real world (on a real robot), even for movements it wasn’t directly trained to copy from a person in real time?
How they did it (explained simply)
Think of giving a robot instructions like giving directions. There are several “languages” you might use:
- Robot joint angles: exact bend amounts for each of the robot’s joints (very detailed).
- Human pose: the positions/rotations of human body joints from motion capture (like a 3D cartoon skeleton).
- End-effector poses: where the key parts—hands, feet, chest—should be in space (simpler and sparser).
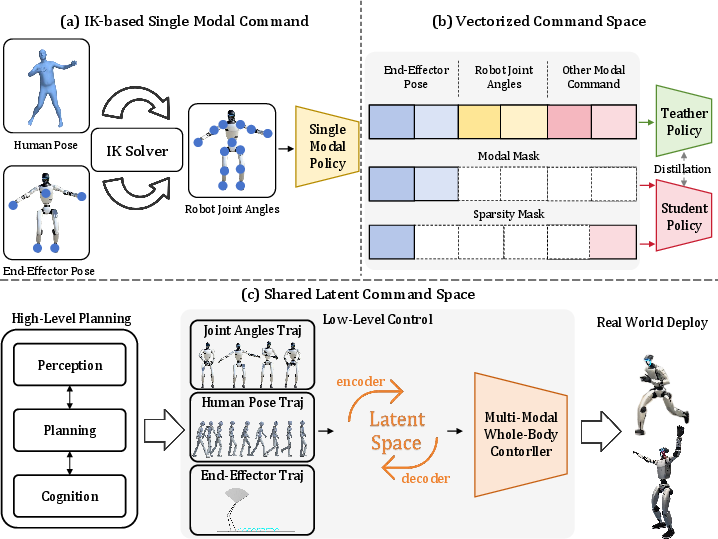
The problem: these instruction types are very different. Past methods often force everything into one format using extra steps like inverse kinematics (IK), or they train multiple models and then “distill” them into one. Those steps add complexity, delay, and errors.
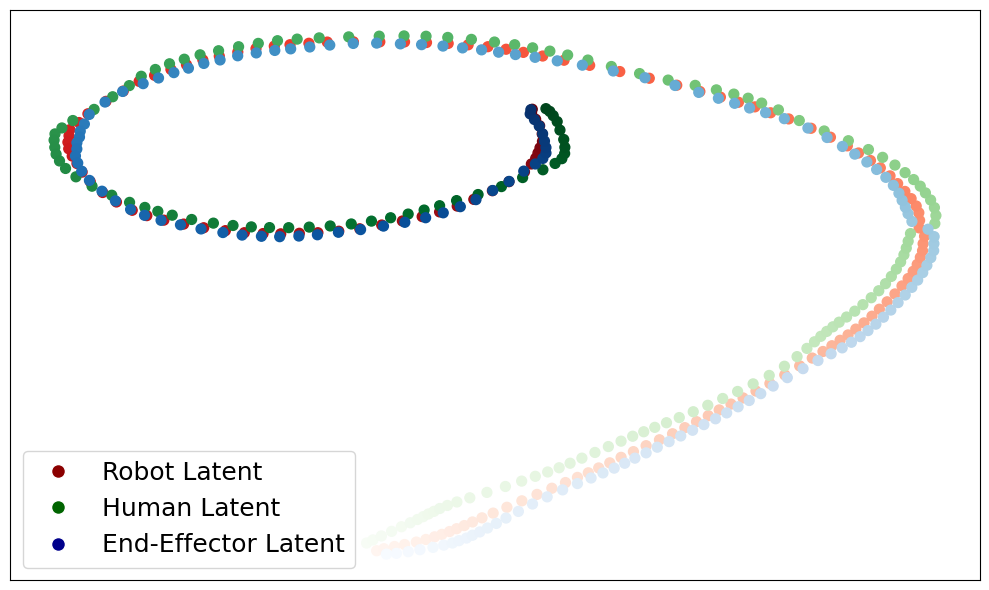
The authors’ key idea is to learn a shared “secret code” (a common representation) for all instruction types:
- Each instruction type gets its own “encoder”—a small network that translates that type into the same kind of compact code (a shared “latent space”).
- Once in that shared code, a single policy (the controller) decides how to move the robot’s motors.
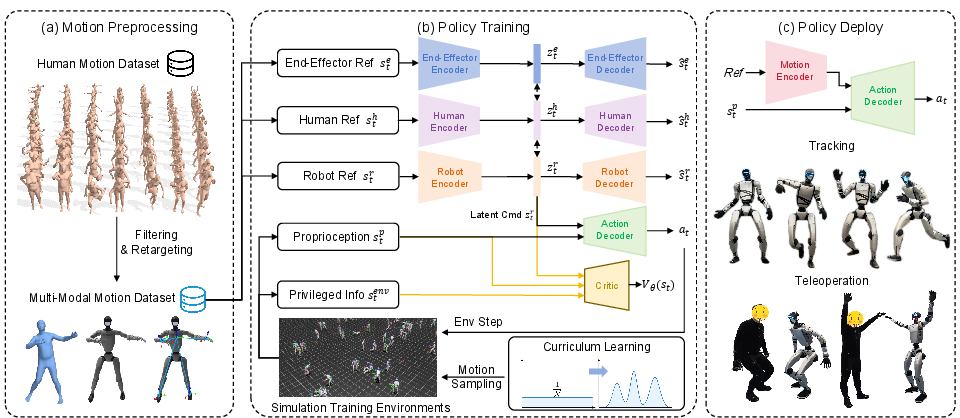
To make this work robustly, they combine three training ingredients:
- Reinforcement learning (RL): The robot practices in a simulator, tries movements, and gets rewards when it matches the target motions and stays physically stable—like learning by trial and error in a safe virtual gym.
- Autoencoding: Each encoder must compress its input and then reconstruct it (decode it) accurately. This forces different instruction types to map into a compatible shared code, as if different “languages” get translated into one common “robot language.”
- Curriculum learning: The training focuses more and more on the motion pieces the robot fails at, similar to a student practicing the hardest questions more often as the course goes on.
They also use:
- Asymmetric actor-critic: The “actor” (the policy that decides movements) only sees what would be available on the real robot (like joint sensors), but the “critic” (the coach that judges how good actions are) can see extra simulator info to give better feedback during training.
- Domain randomization: They vary friction, mass, sensor noise, and other physics in the simulator. This is like practicing on many slightly different floors and with slightly different shoes so the robot won’t be surprised in the real world.
They train and test on large motion datasets and then deploy the learned policy directly on a real Unitree G1 humanoid robot.
What they found and why it matters
Main takeaways:
- One model, many instruction types: The single controller successfully follows different kinds of motion references—no extra conversion with IK and no multi-stage retraining needed.
- Strong performance in simulation: On unseen test motions, the best setting reaches a 98.42% success rate. It also beats several strong baseline methods in tracking accuracy and stability.
- Sim-to-real transfer works: Without collecting special teleoperation data for training, the same controller runs on the real robot and tracks a variety of actions (dancing, running, walking, boxing, squatting, pushing).
- Accuracy vs. robustness trade-off across instruction types:
- Dense joint-angle instructions give the most precise pose tracking (best “fidelity”).
- Sparse end-effector instructions (just hands/feet/chest) are more robust when the test motions differ from the training data, leading to higher overall success on unfamiliar movements.
- Human-pose commands land in between and perform comparably well.
- Scaling matters: More diverse data helps more than just making the network bigger. Larger models help, especially with small datasets, but increasing data variety boosts generalization even more.
Why this is important:
- It shows a clean way to unify very different ways of telling a robot what to do. Instead of writing special converters or training multiple models, you learn one shared “command language” and one controller.
- It reduces engineering overhead and makes it easier to plug in new sources of motion (like VR controllers, motion capture, or pre-recorded animations).
- It helps robots handle real-world messiness because of robust training strategies (curriculum plus domain randomization).
What this could lead to next
- Easier teleoperation and task control: People could steer a humanoid using whichever signals are convenient (just hand targets, a full-body suit, or pre-made animations) and the same controller would work.
- Faster deployment: Fewer special conversion steps and no multi-round retraining mean moving from simulation to a real robot can be quicker and more reliable.
- Building full robot “brains”: This versatile low-level controller can be plugged beneath high-level perception and planning modules so humanoids can not only copy motion but also achieve goals (like fetching or assembling) with stable, human-like movement.
In short, M3imic teaches a humanoid to understand many “motion languages” by translating them into one shared code, and it learns to move smoothly and robustly in both simulation and the real world—without needing a different controller for each type of input.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and could guide future research:
- Lack of quantitative real-world comparisons against strong baselines (e.g., HOVER, TWIST2, ExBody2, OmniH2O); only the proposed method is evaluated on hardware.
- No task-level loco-manipulation metrics (e.g., grasp success, object pose error, task completion time, contact forces) despite claims of applicability to manipulation; evaluation focuses on pose/velocity errors.
- Success criterion in simulation (root orientation within ±45°) may mask drift and foot slippage; absence of stability/fall metrics (e.g., CoM/ZMP margin, foot slip distance, contact consistency).
- Limited terrain diversity in experiments (no uneven terrain, stairs, or compliant/low-friction surfaces); robustness on varied contact conditions remains untested.
- Sim-to-real randomization omits important real-world factors (e.g., actuator latency and saturation, sensor latency/packet loss, joint backlash, foot compliance, contact model errors); impact of adding these factors is unknown.
- The actor intentionally excludes global position and linear velocity; long-horizon drift and navigation accuracy are not quantified, and trade-offs for tasks requiring global tracking remain unclear.
- The shared latent command space is trained with L2 alignment/consistency losses but without constraints to resolve kinematic underdetermination for sparse end-effector inputs; how to disambiguate multiple valid whole-body configurations remains open.
- No ablation of the autoencoder losses (reconstruction, alignment, consistency) or latent dimensionality; sensitivity of performance to these design choices is unknown.
- Short temporal window for command encoding (H=10, Δ=2) without analysis of control-rate variability or long-horizon dependencies; effectiveness under different control frequencies and latencies is untested.
- Policy/network are purely MLP-based with no recurrence or attention; capacity to model long-term dependencies and multi-phase skills over minutes remains unverified.
- Runtime multi-modal fusion is not demonstrated; the policy is evaluated per-modality, but benefits/risks of combining modalities online (e.g., human pose + end-effectors) and handling conflicts are unexplored.
- Robustness to partial observability of command inputs (e.g., missing markers, occlusions, intermittent dropouts, asynchronous streams) is not quantified; failure-handling logic is unspecified.
- Modality switching within an episode (e.g., transitioning from teleop end-effector control to joint targets) and associated hysteresis/stability issues are not addressed.
- No cross-robot generalization experiments; transferability to other humanoids with different kinematics/actuation is untested.
- Real-time performance on hardware (control frequency, end-to-end latency budget, compute resource utilization) is not reported; scalability on embedded compute remains unclear.
- Reward shaping includes dense body pose/velocity terms but no explicit energy/torque penalties or contact regularization (e.g., friction cone compliance, foot rotation penalties); impact on safety, efficiency, and wear is unknown.
- The curriculum emphasizes failure-heavy segments but does not reweight across modalities; potential modality imbalance and strategies for modality-aware sampling are not studied.
- The curriculum’s theoretical properties and sensitivity (e.g., α schedule, segment length, P_max) and its interaction with exploration are not analyzed; no alternative curricula (e.g., competence-based or uncertainty-based) are considered.
- Handling of end-effector under-specification for fine manipulation (e.g., wrist orientation precision, finger/dexterous hands) is absent; extension beyond 5 end-effectors (feet, hands, chest) is unaddressed.
- Encoder pretraining vs joint training with RL is not compared; potential non-stationarity and representation drift during policy learning remain uncharacterized.
- The method assumes paired, time-aligned multi-modal references; robustness to temporal misalignment and bias introduced by retargeting (e.g., GMR artifacts) is not evaluated.
- No analysis of failure modes (e.g., when dense joint tracking degrades stability or when end-effector guidance induces unsafe postures); lack of diagnostics for policy recovery behaviors.
- OOD sensing sources (e.g., IMU/VR-based inputs with higher noise/latency than optical mocap) are not tested; performance under consumer-grade teleoperation hardware remains unknown.
- No integration with high-level perception or planning in closed-loop tasks; how the latent command space interacts with planners or vision-language modules remains to be shown.
- No safety assurance framework (constraints/verification) or risk-aware control; absence of guarantees under distribution shift or unexpected contacts.
Practical Applications
Overview
This paper proposes M3imic, a multi-modal whole-body control framework for humanoid robots that learns a shared latent command space from heterogeneous motion references (robot joint angles, human pose trajectories, end-effector poses). A single policy trained with large-scale reinforcement learning and curriculum-based sampling achieves zero-shot sim-to-real on a Unitree G1 robot across modalities (πr, πh, πe), with robust teleoperation and motion tracking. Below are actionable applications derived from these findings, methods, and innovations.
Immediate Applications
The following applications are deployable now, leveraging the released codebase, demonstrated sim-to-real capabilities, and existing hardware (e.g., Unitree G1).
- Multi-modal teleoperation of humanoid robots — sectors: robotics, logistics, field service, entertainment
- What this enables/workflow: Operators use optical mocap or VR/handheld trackers to drive end-effector or pose commands; M3imic’s πe provides robust execution under distribution shift, while πr offers high-fidelity tracking.
- Potential tools/products: Teleop console with MoCap/VR integration; ROS2 nodes wrapping the encoder and policy; operator safety UI; cloud-to-edge streaming.
- Assumptions/dependencies: Reliable tracking hardware (mocap/VR), calibrated robot kinematics, safety interlocks; policies currently validated on Unitree G1—porting to other platforms requires retargeting and domain randomization tuning.
- IK-free whole-body command tracking for humanoid deployments — sectors: software, robotics
- What this enables/workflow: Replace latency-prone or brittle IK pipelines with a direct latent-space command interface; reduce engineering overhead for multi-modal inputs.
- Potential tools/products: “M3imic Controller” SDK/plugin for popular humanoids; encoder microservice accepting joint/human pose/end-effector sequences and outputting latent commands.
- Assumptions/dependencies: Accurate retargeting from human poses to robot frames improves performance; environment conditions should fall within the domain randomization ranges used during training.
- Rapid skill prototyping from motion libraries — sectors: R&D, academia, creative industries
- What this enables/workflow: Curate a short motion clip (e.g., LAFAN1, 100STYLE, custom mocap), encode, and immediately test on a robot without retraining; iterate over stylized motion for demos or studies.
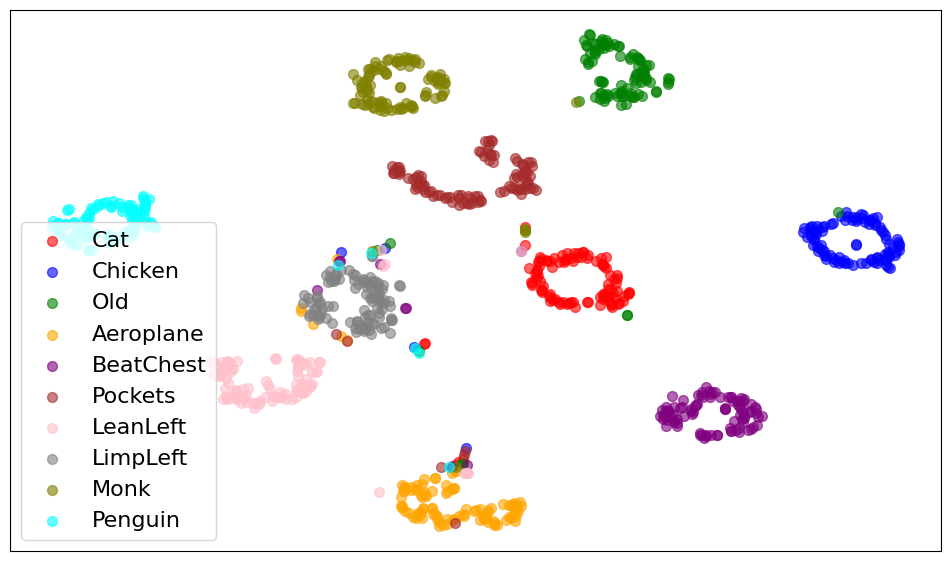
- Potential tools/products: Dataset ingestion and filtering tools; pipeline scripts to convert motion sequences to multi-modal references; t-SNE visualization utilities to audit latent coverage.
- Assumptions/dependencies: Motion quality and diversity are critical; ensure motion categories are within the training distribution for best fidelity.
- Performance and event robots that mimic human choreography — sectors: entertainment, marketing
- What this enables/workflow: Show robots reproducing dancing, boxing, walking styles; robust execution via πe to handle stage variability (pushes, friction changes).
- Potential tools/products: Show-control timeline integration; DMX/MIDI-to-latent adapters for stage tech; pre-validated style libraries.
- Assumptions/dependencies: Venue safety, stage-specific calibration; battery and thermal limits for high-dynamics motions.
- Human-in-the-loop data collection for future tasks — sectors: robotics, software
- What this enables/workflow: Use teleoperation to collect paired latent-command and robot execution logs for later imitation learning or task-specific fine-tuning (e.g., loco-manipulation).
- Potential tools/products: Logging and replay utilities; data governance workflows; synthetic data augmentation in Isaac Sim.
- Assumptions/dependencies: Consistent timestamping across sensors; privacy and consent for human motion data.
- Educational platforms for RL-based whole-body control — sectors: education, academia
- What this enables/workflow: Teaching modules using Isaac Sim + M3imic to illustrate RL, sim-to-real, curriculum design, and multi-modal command representations.
- Potential tools/products: Course labs, dockerized environments; reproducible training configs; dashboards to monitor reward terms and success metrics.
- Assumptions/dependencies: GPU availability; licensing for datasets and simulators.
- Benchmarking and QA harness for humanoid control stacks — sectors: robotics QA, standards efforts
- What this enables/workflow: Adopt M3imic’s metrics (MPKPE, MPJAE, success rate) and episodic evaluation scripts to stress-test whole-body controllers against diverse motion clips and disturbances.
- Potential tools/products: Continuous-integration test suites for controller updates; report generators with standardized metrics and plots.
- Assumptions/dependencies: Access to similar datasets and physics sim configurations; cross-robot retargeting for fair comparison.
- Warehouse or facility pilot tasks with minimal manipulation — sectors: logistics, facilities management
- What this enables/workflow: Demonstrate robust walking, posture changes, pushing/light interaction using end-effector references; exploit πe robustness for distribution shifts (e.g., surface friction).
- Potential tools/products: Pilot scripts for site surveys; safety-rated motion sets; monitoring and remote-stop integrations.
- Assumptions/dependencies: Limited to tasks not requiring precise force-controlled manipulation; safety certification for on-site trials.
Long-Term Applications
These applications will benefit from further research, scaling, integration with perception and planning, or hardware maturation.
- General-purpose humanoid assistants with multi-modal command interfaces — sectors: robotics, services, consumer robotics
- Vision: Robots accept joint/pose/EE commands from planners, humans, or LLM-based task managers, dynamically trading fidelity and robustness.
- Potential tools/products: Unified command APIs across vendors; planners emitting latent commands; on-device adaptation policies.
- Assumptions/dependencies: Robust perception, high-level planning, and safety layers; generalized sim-to-real across varied morphologies and contact-rich tasks.
- Integrated loco-manipulation in unstructured environments — sectors: manufacturing, logistics, construction
- Vision: Combine M3imic with perception and grasp planners to perform carrying, assembly, and inspection with whole-body balance and motion style control.
- Potential tools/products: Perception-to-latent pipelines; grasp and trajectory synthesis front-ends; compliance and force control modules integrated with latent commands.
- Assumptions/dependencies: Accurate contact modeling and force sensing; richer reward shaping for manipulation; safety-rated control under physical contact.
- Cross-embodiment transfer and adaptation (humanoids, exoskeletons, avatars) — sectors: healthcare, defense, sports tech
- Vision: Shared latent commands adapted across robots or exoskeletons for training, rehab, or telepresence; human motions transmitted to multiple embodiments.
- Potential tools/products: Morphology-aware encoders/decoders; calibration wizards; transfer learning toolkits.
- Assumptions/dependencies: Additional training/retargeting for different kinematics and actuator capabilities; medical-grade safety and ergonomics for exoskeletons.
- Standardization of multi-modal command APIs and safety certification for RL controllers — sectors: policy, standards, insurance
- Vision: Define open standards for latent command interfaces and test protocols for RL-based whole-body controllers (disturbance tests, OOD benchmarks).
- Potential tools/products: Certification test suites; insurer-accepted risk profiles using MPKPE/MPJAE/success-rate thresholds; regulator guidance.
- Assumptions/dependencies: Multi-stakeholder consortia (vendors, labs, regulators); incident reporting and data-sharing frameworks.
- On-robot continual learning and personalization — sectors: software, robotics
- Vision: Policies refine latent representations and tracking in situ based on operator preferences, workspace idiosyncrasies, and wear-and-tear.
- Potential tools/products: Safe online adaptation with guardrails; drift detection; federated updates across fleets.
- Assumptions/dependencies: Reliable safety monitors; sample-efficient adaptation; privacy-preserving updates.
- Energy- and compute-efficient deployment stacks — sectors: hardware, edge AI
- Vision: Compress encoders/policies to run on embedded GPUs/NPUs without compromising robustness, enabling longer runtime and lower latency.
- Potential tools/products: Quantized models, sparsity-aware MLPs; runtime schedulers integrated with robot OS.
- Assumptions/dependencies: Hardware acceleration availability; validation that compression preserves safety margins.
- Human-robot collaboration and training platforms — sectors: workforce development, education
- Vision: Workers demonstrate tasks via pose or end-effector demonstrations; robots learn whole-body behaviors more naturally than via scripts.
- Potential tools/products: Authoring tools for task libraries; hybrid human-in-the-loop training with alignment feedback.
- Assumptions/dependencies: Task decomposition and failure recovery; ergonomic co-working safety standards.
- Privacy-aware motion data ecosystems — sectors: policy, legal, data management
- Vision: Policies and tooling to govern collection and use of human motion data for training multi-modal controllers (consent, anonymization, provenance).
- Potential tools/products: Secure data lakes; synthetic motion generation and augmentation routines.
- Assumptions/dependencies: Legal frameworks and auditing; technical mechanisms for de-identification without degrading control quality.
- Consumer telepresence and home robotics — sectors: consumer electronics, assistive tech
- Vision: Home humanoids mimic personalized motions for communication, companionship, or demonstration (e.g., exercise guidance), using robust EE or pose inputs.
- Potential tools/products: App ecosystems for motion sharing; cloud-based motion libraries; safety-certified home runtimes.
- Assumptions/dependencies: Cost reductions, strong safety and reliability guarantees, intuitive operator interfaces.
Key Assumptions and Dependencies (Cross-Cutting)
- Hardware and morphology: Results are validated on Unitree G1 (29 DoF). Porting to other platforms requires motion retargeting, revised domain randomization, and potentially re-training.
- Sensors and inputs: Teleoperation quality depends on MoCap/VR accuracy and calibration; end-effector-only inputs favor robustness but can reduce pose fidelity, while dense joint inputs maximize fidelity but are less robust to distribution shifts.
- Environment and safety: Domain randomization covers specific ranges (e.g., friction 0.1–1.6); out-of-range conditions may require retraining or policy fine-tuning. Safety interlocks and fall recovery layers remain necessary for real deployments.
- Compute and data: Training used large datasets (~3.9M frames) and multi-GPU resources; greater motion diversity improves generalization more than simply scaling model size.
- Navigation and global localization: The actor excludes global position/linear velocity to enable deployment without external localization; autonomous navigation requires a higher-level planner and localization system integrated above M3imic.
These applications illustrate how a shared latent command space and a single end-to-end policy across modalities can reduce integration complexity, accelerate deployment, and broaden the operational envelope of humanoid robots across sectors.
Glossary
- 6D rotation representation: A continuous rotation parameterization using two 3D vectors to represent orientation and avoid discontinuities. Example: "converted from axis-angle to a 6D rotation representation"
- Advantage estimate: In policy gradient methods, a quantity estimating how much better an action is than the baseline (value) at a state. Example: "where denotes the actor input state, is the advantage estimate, $\mathbf{V}_{\boldsymbol{\theta}$ is the value function, is the value loss coefficient..."
- Adversarial priors: Learned discriminators or distributions used to make generated motions appear human-like within reinforcement learning or imitation frameworks. Example: "Motion stylization methods use adversarial priors to encourage human-like behaviors while optimizing task rewards"
- Asymmetric actor-critic: An architecture where the actor uses partial observations (deployable inputs) while the critic has access to additional privileged information during training. Example: "we adopt an asymmetric actor-critic architecture."
- Autoencoder: A neural network trained to compress inputs into a latent code and reconstruct them, used here to unify heterogeneous motion references. Example: "the autoencoder takes as input a short-horizon reference sequence for each modality."
- Axis-angle representation: A rotation representation defined by an axis and an angle around that axis. Example: "converted from axis-angle to a 6D rotation representation"
- Clipped surrogate objective: The PPO training objective that clips policy ratio updates to stabilize policy optimization. Example: "We adopt a clipped surrogate objective with value function and entropy regularization:"
- Command masking: A training technique where parts of the input commands are masked to teach robustness to missing modalities. Example: "Through command masking and teacher-student distillation, it trains a universal multi-modal motion tracking controller for diverse high-level tasks."
- Curriculum learning: A training strategy that gradually adjusts sampling or task difficulty to stabilize and improve learning. Example: "We adopt a curriculum learning strategy that adaptively reshapes the sampling distribution during training."
- DoF (Degrees of Freedom): The number of independent parameters that define a system’s configuration, e.g., joint angles in a robot. Example: "the 29-DoF Unitree G1 humanoid robot."
- Domain randomization: Randomizing simulation parameters to improve robustness and facilitate transfer to real-world systems. Example: "we employ domain randomization during training."
- End-effector: The terminal parts of a robot (e.g., hands, feet) that interact with the environment. Example: "The former provides dense, high-precision full-body joint trajectories, whereas the latter usually offers sparse end-effector trajectories better suited for interactive tasks."
- Entropy regularization: A term added to the RL objective to encourage exploration by increasing policy entropy. Example: "with value function and entropy regularization:"
- Exponential moving average (EMA): A smoothing method giving more weight to recent observations. Example: "we maintain an exponential moving average (EMA) of the termination failure rate"
- Failure-rate-based adaptive sampling: A data sampling scheme that prioritizes segments with higher failure rates to focus learning on difficult cases. Example: "failure-rate-based adaptive sampling improves training efficiency by emphasizing difficult motion segments;"
- Hierarchical control architecture: A control design that separates high-level planning from low-level stabilization and execution. Example: "Hierarchical control architectures have emerged as the dominant paradigm, decoupling low-frequency perception and planning at the high level from high-frequency stability control and motion execution at the low level."
- Inverse kinematics (IK): Computing joint configurations that achieve desired end-effector positions and orientations. Example: "converts heterogeneous motion references into the target robot joint space using inverse kinematics (IK)"
- Kinematic redundancy: Having more degrees of freedom than strictly necessary for a task, allowing multiple valid configurations. Example: "while exploits the kinematic redundancy of sparse end-effector references to achieve higher robustness."
- Kinematic underdetermination: When available constraints (e.g., sparse end-effector trajectories) are insufficient to uniquely determine full-body configurations. Example: "This sparsity inherently leads to kinematic underdetermination, where a single end-effector trajectory can correspond to multiple valid full-body configurations."
- Latent space: A lower-dimensional encoded representation capturing essential features of inputs. Example: "using modality-specific encoders to map them into a shared latent space."
- Loco-manipulation: Tasks that require simultaneous locomotion and manipulation capabilities. Example: "including locomotion and loco-manipulation."
- Markov Decision Process (MDP): A formal framework for sequential decision-making defined by states, actions, transitions, rewards, and discount factors. Example: "modeled as a Markov Decision Process (MDP) ."
- Mean per-joint angle error (MPJAE): An evaluation metric measuring average joint angle error, often root-relative. Example: "root-relative mean per-joint angle error ($E_{\text{mpjae}$, rad)"
- Mean per-keypoint position error (MPKPE): An evaluation metric measuring average position error across body keypoints, often root-relative. Example: "root-relative mean per-keypoint position error ($E_{\text{mpkpe}$, mm)"
- Motion stylization: Learning to produce motions with specific styles or human-likeness, often via adversarial objectives. Example: "Motion stylization methods use adversarial priors to encourage human-like behaviors while optimizing task rewards"
- Multi-layer perceptron (MLP): A feedforward neural network with multiple fully connected layers. Example: "All encoders and decoders are implemented as multi-layer perceptrons (MLPs)."
- Oracle policy: A policy trained with access to privileged or idealized information unavailable at deployment. Example: "training an oracle policy using privileged information in the simulator."
- Orthogonal Mixture-of-Experts (OMoE): A mixture-of-experts model variant encouraging expert specialization via orthogonality constraints. Example: "uses Orthogonal Mixture-of-Experts (OMoE) and segment-level rewards to disentangle skills and enable efficient multi-skill learning."
- Privileged information: Extra information available during training (e.g., full state) but not at test time. Example: "training an oracle policy using privileged information in the simulator."
- Privileged supervision: Training signals or critic inputs leveraging information not available to the actor at deployment. Example: "to provide privileged supervision;"
- Proprioceptive state: Internal robot sensing of its own configuration and motion (e.g., joint angles, velocities). Example: "represents the robot's proprioceptive state"
- Retargeting: Mapping human motion data to robot-specific references or kinematics. Example: "and employ GMR~\cite{ze2025gmr} for data retargeting."
- SE(3): The Lie group of 3D rigid body transformations (rotations and translations). Example: "encodes the poses of end-effectors"
- Sim-to-real transfer: Deploying a policy trained in simulation directly on real hardware. Example: "achieves sim-to-real transfer across multiple motion reference modalities"
- SMPL-X: A parametric human body model with expressive shape and pose parameters. Example: "SMPL-X body pose~\cite{SMPL-X:2019}"
- t-SNE: A nonlinear dimensionality reduction technique for visualizing high-dimensional data. Example: "We visualize the latent space distribution after multi-modal encoding using t-SNE~\cite{maaten2008visualizing}."
- Teacher-student distillation: Training a student policy to mimic a stronger teacher policy, often under different input conditions. Example: "Through command masking and teacher-student distillation, it trains a universal multi-modal motion tracking controller..."
- Teleoperation: Controlling a robot remotely using human input devices or motion capture. Example: "Real-world teleoperation experiments using an optical motion capture system."
- Tokenized unified motion representation: Discrete token-based encoding of motion used to unify multiple reference modalities. Example: "Sonic~\cite{luo2025sonic} introduces a tokenized unified motion representation for multi-modal references"
- Zero-shot: Performing a task without any additional fine-tuning or retraining on that task or environment. Example: "enabling successful zero-shot sim-to-real deployment on a humanoid robot."
Collections
Sign up for free to add this paper to one or more collections.