- The paper introduces a teacher-student architecture where a robot arm safely guides a humanoid during reinforcement learning to achieve robust policy adaptation.
- The system integrates sim-to-real training with universal latent optimization and FiLM-based modulation, enhancing data efficiency and policy transfer.
- Experimental results demonstrate stable treadmill walking and swing-up tasks with significant performance improvements over baseline methods.
Robot Trains Robot: Automatic Real-World Policy Adaptation and Learning for Humanoids
Introduction and Motivation
The paper introduces the Robot-Trains-Robot (RTR) framework, a hardware-software system for real-world reinforcement learning (RL) and sim-to-real adaptation in humanoid robots. The RTR paradigm leverages a teacher-student architecture, where a robot arm (teacher) actively supports, guides, and interacts with a humanoid robot (student) during policy learning. This approach addresses critical challenges in real-world humanoid RL: safety during exploration, reward signal acquisition, and learning efficiency. The system is designed to minimize human intervention, automate resets, and provide dynamic curriculum scheduling, enabling efficient and robust policy learning directly on physical robots.
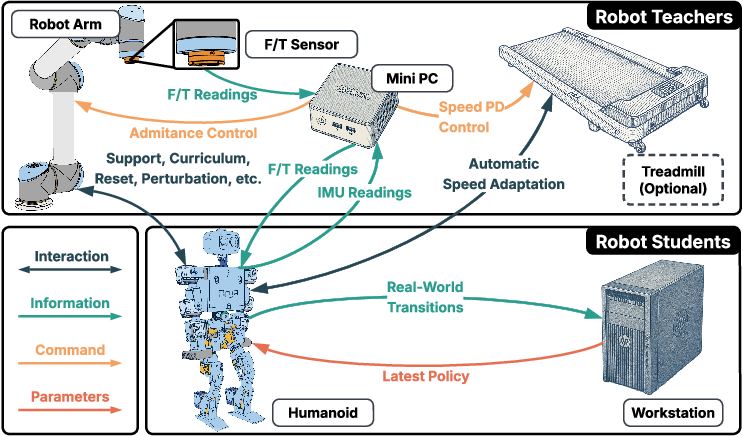
Figure 1: System Setup. The teacher (robot arm with F/T sensor, mini PC, treadmill) interacts with the student (humanoid robot, workstation) via physical, data, control, and neural network parameter channels.
System Architecture and Hardware Design
The RTR system comprises two main components:
- Teacher Group: A 6-DoF UR5 robot arm equipped with an ATI mini45 force-torque sensor, elastic ropes for compliant support, and an optional treadmill for locomotion tasks. The teacher's mini PC orchestrates control, data collection, and curriculum scheduling.
- Student Group: The ToddlerBot humanoid (30 DoF, 3.4 kg, 0.56 m), selected for its robustness and suitability for unattended operation, and a workstation for policy training.
The teacher provides active compliance via admittance control, enabling safe exploration and dynamic support. The treadmill, controlled via feedback from the F/T sensor and IMU, maintains the robot's position and supplies proxy reward signals. The system automates failure detection and resets, significantly reducing manual labor and increasing data throughput.
Sim-to-Real Adaptation Algorithm
The RTR framework introduces a three-stage sim-to-real adaptation pipeline for policy transfer and fine-tuning:
- Dynamics-Conditioned Policy Training: In simulation, a policy π(s,z) is trained across N=1000 domain-randomized environments. Environment-specific physical parameters μ(i) are encoded into a latent z(i) via an MLP encoder fϕ. The latent modulates the policy network through FiLM layers, enabling adaptation to diverse dynamics.
- Universal Latent Optimization: To address the unknown real-world latent, a universal latent z∗ is optimized across all simulation domains, providing a robust initialization for real-world deployment. The policy and FiLM parameters are frozen during this stage.
- Real-World Finetuning: In the real world, the actor and FiLM layers remain frozen, while z∗ is further refined using PPO. The critic is retrained from scratch to accommodate differences in observation space. The reward is based on treadmill speed tracking, approximating the robot's velocity.
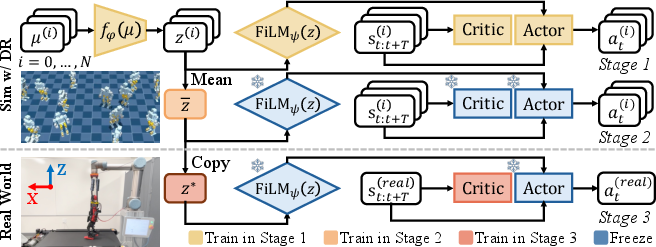
Figure 2: Sim-to-real Fine-tuning Algorithm. Three-stage process: simulation training with domain randomization, universal latent optimization, and real-world latent refinement.
The teacher's curriculum dynamically reduces support, transitioning from high to low assistance, and automates resets based on force and posture thresholds.
Real-World RL from Scratch: Swing-Up Task
RTR is also applied to direct real-world RL for tasks with complex, hard-to-simulate dynamics, such as humanoid swing-up. The training pipeline consists of:
- Online RL Data Collection: Actor and critic are trained from scratch using PPO, collecting $50,000$ steps of suboptimal data.
- Offline Critic Pretraining: The critic is pretrained on collected data to accelerate subsequent learning.
- Joint Actor-Critic Training: A new actor is initialized, and both networks are trained jointly.
The reward is defined via FFT analysis of force sensor data, targeting maximization of the dominant periodic force amplitude. The teacher arm provides phase-aligned guidance (amplifying or damping the swing) according to the robot's swing angle, with randomized schedules for helping, perturbing, or remaining static.
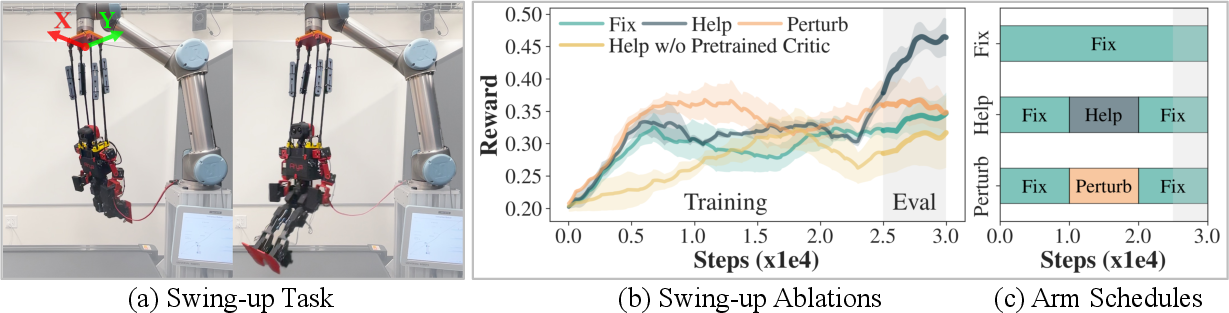
Figure 3: Swing-up Ablation. (a) Humanoid suspended from arm, swinging via leg actuation. (b) Comparison of arm schedules and critic pretraining. (c) Arm schedule visualization.
Experimental Results and Ablations
Walking Task: Sim-to-Real Adaptation
Experiments on treadmill walking demonstrate the efficacy of RTR in real-world adaptation. Key findings include:
- Arm Compliance: XY-compliant arm control significantly improves policy adaptation and stability compared to fixed-arm baselines.
- Arm Schedule: Gradual reduction of support yields better transfer and evaluation performance than static high or low support.
- Latent Fine-tuning: Fine-tuning the universal latent z∗ is more data-efficient and robust than direct policy or residual policy fine-tuning.
RTR achieves stable walking at 0.15 m/s, doubling zero-shot speed after only $20$ minutes of real-world training. Metrics show reduced torso roll/pitch and end-effector forces compared to baselines.
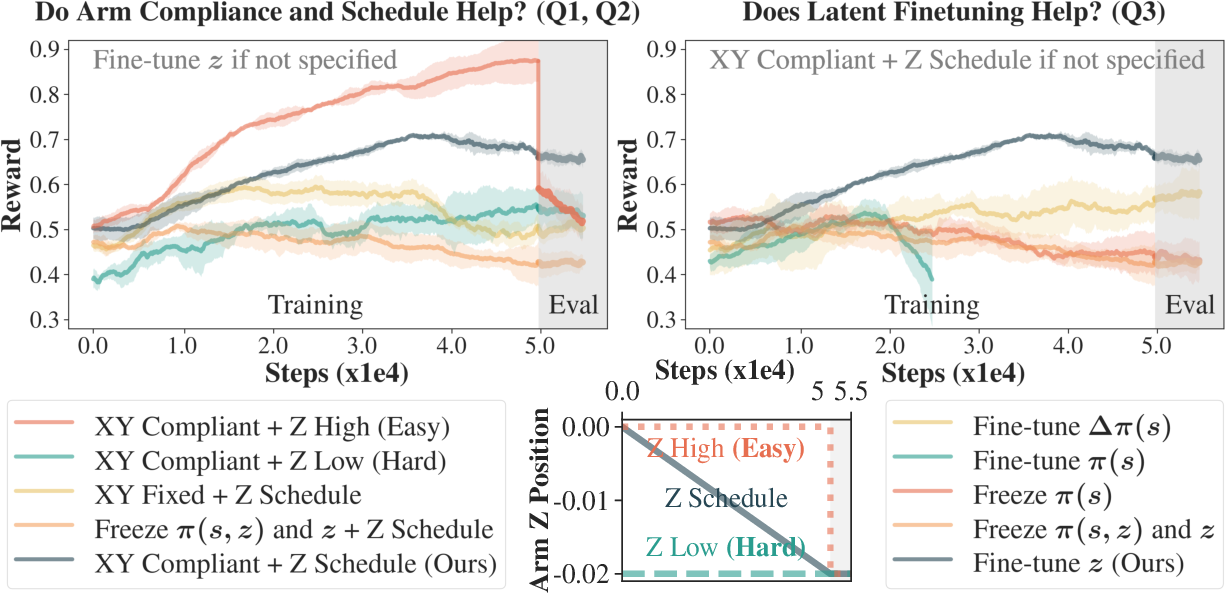
Figure 4: Walking Ablation. Training/evaluation rewards for different arm feedback and latent fine-tuning strategies.
Swing-Up Task: Real-World RL
In the swing-up task, active arm involvement (helping/perturbing) outperforms fixed-arm schedules, with helping yielding the highest swing amplitude. Critic pretraining accelerates early-stage learning. The humanoid achieves periodic swing-up motion within $15$ minutes of real-world interaction.
FiLM Layer Learning Rate Ablation
Ablation studies on FiLM layer learning rates reveal a trade-off: low rates cause the policy to ignore latent dynamics, while high rates induce instability. An intermediate rate ($5e-5$) balances performance and latent utilization.
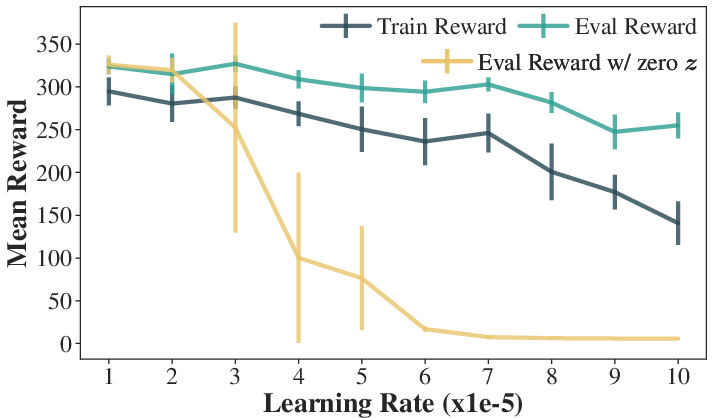
Figure 5: FiLM learning rate ablation. Policy performance and latent utilization across different learning rates.
Comparison with RMA
RTR is compared to Rapid Motor Adaptation (RMA), a sim-to-real method using latent concatenation and adaptation modules. RTR's FiLM-based latent modulation outperforms RMA's concatenation in both simulation and real-world experiments. Universal latent optimization in RTR provides a more stable and effective initialization for real-world adaptation, especially for high-DoF humanoids. Real-world metrics confirm superior stability and force profiles for RTR.
Limitations and Future Directions
While RTR automates real-world training, curriculum design remains task-specific and requires manual tuning. Reward design is constrained by available sensors; for example, ground reaction forces are not directly measured. Extending RTR to full-scale humanoids will require higher payload teacher robots (industrial arms or bridge cranes) and more generalizable curriculum generation. Advancing real-world sensing and data efficiency are promising future directions.
Conclusion
RTR presents a comprehensive framework for automatic real-world policy adaptation and learning in humanoid robots, integrating hardware support, curriculum scheduling, and dynamics-aware RL algorithms. The system enables efficient, robust, and largely autonomous real-world training, validated on walking and swing-up tasks. The approach generalizes to larger platforms and more complex behaviors, with future work aimed at scaling, sensor integration, and curriculum automation.