- The paper introduces Ecpo, a method that recalibrates step-level credit via evidence-calibrated action advantage and variance-gated weighting to mitigate divergent anchor bias.
- It demonstrates that Ecpo achieves performance improvements up to +7.3 percentage points and markedly reduces reward variance compared to existing methods.
- The approach is critic-free, scalable, and validated on benchmarks such as ALFWorld and WebShop, underscoring its practical impact for long-horizon LLM training.
Evidence-Calibrated Policy Optimization for Long-Horizon LLM Agent Training
Motivation and Problem Analysis
The training of long-horizon LLM agents in interactive RL environments presents severe challenges for temporal credit assignment due to delayed, sparse rewards and extended action sequences. Existing state-of-the-art group-based RL methods, such as GRPO and GiGPO, address reward sparsity by assigning denser credit at intermediate anchor states. GiGPO specifically leverages repeated anchor states to compare action outcomes and assign relative advantages. However, this occurrence-level step-wise advantage assignment can result in statistically unreliable credit signals, especially under limited rollout budgets with imbalanced action sampling. The proposed term “divergent anchor bias” denotes anchor states where rare actions, sampled infrequently but with high observed returns (often due to stochasticity), are overweighted, leading to over-rewarding and destabilized late-stage policy optimization. The proportion of such divergent anchors increases significantly during training, inducing high-variance gradients, reward oscillations, and impaired convergence.
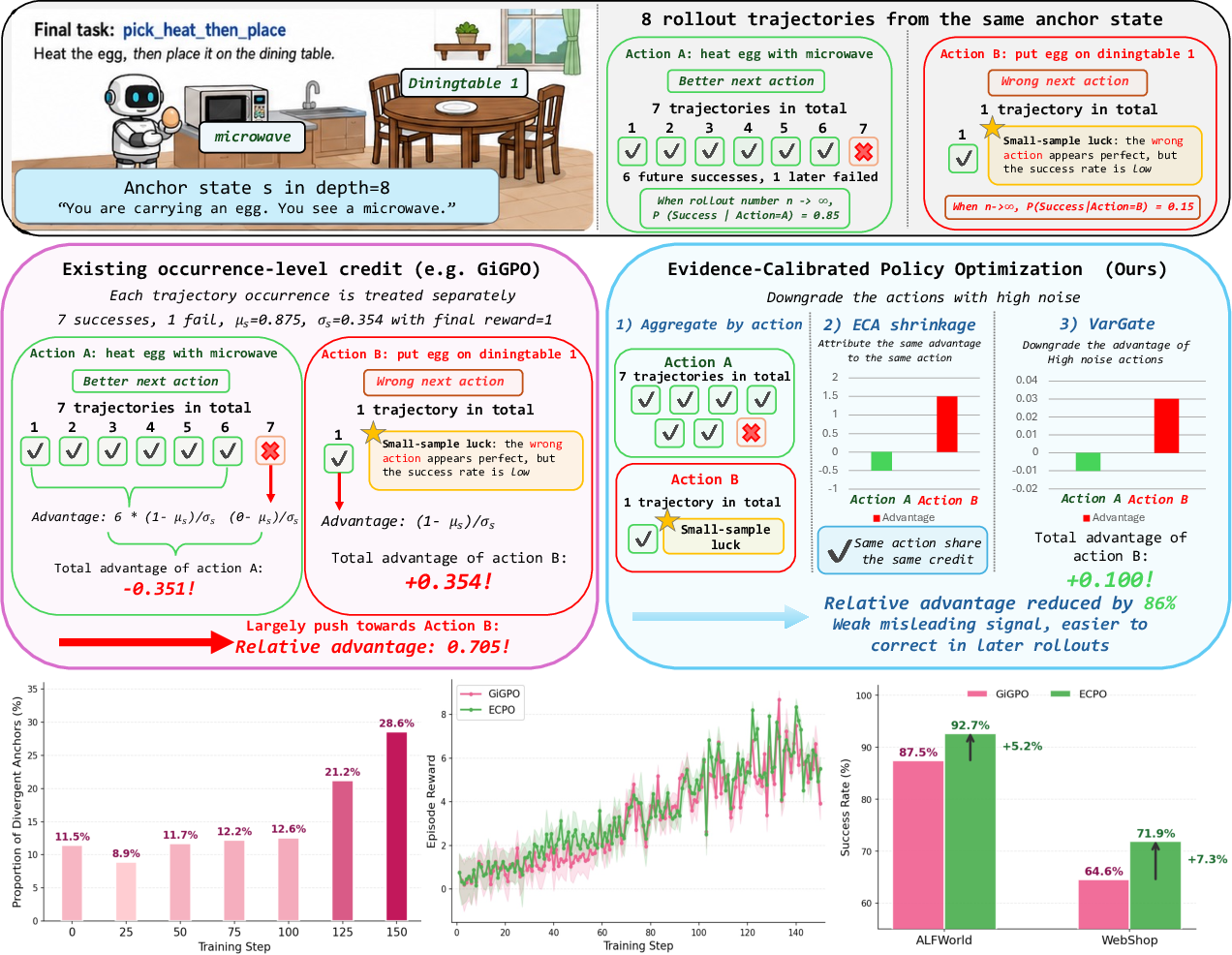
Figure 1: Ecpo mitigates divergent anchor bias in ALFWorld by calibrating action-level evidence, transforming the distribution of anchor state credit assignment and reducing reward variance.
Method: Evidence-Calibrated Policy Optimization (Ecpo)
Ecpo reframes step-level credit assignment as an evidence calibration problem, introducing two critical algorithmic components over standard group-based RL:
- Evidence-Calibrated Action Advantage (ECA): Occurrence-wise returns at each anchor state are grouped by canonical actions. Calibrated action advantage estimates are computed via shrinkage—low-count actions are interpolated toward the anchor mean, reducing the likelihood of overestimating actions with insufficient evidence. This avoids systematic over-rewarding of rare lucky actions and corrects for estimation bias due to finite-sample variance.
- Variance-Gated Credit Weighting (VarGate): Since not all anchor states provide reliable separation between action choices, Ecpo computes both between-action variance (the extent to which action choice explains future returns) and within-action variance (residual stochasticity after fixing action choice). The reliability weight quantifies the statistical trust in the observed between-action differences, gating the strength of step-level credit injected into policy updates. When anchor reliability is low (e.g., due to high stochasticity or degenerate action groups), Ecpo suppresses the step-level signal, falling back to trajectory-level (group-relative) advantages.
The algorithm remains critic-free and scalable, with calibrated, reliability-weighted advantages aggregated into a PPO-style clipped objective for stable optimization.
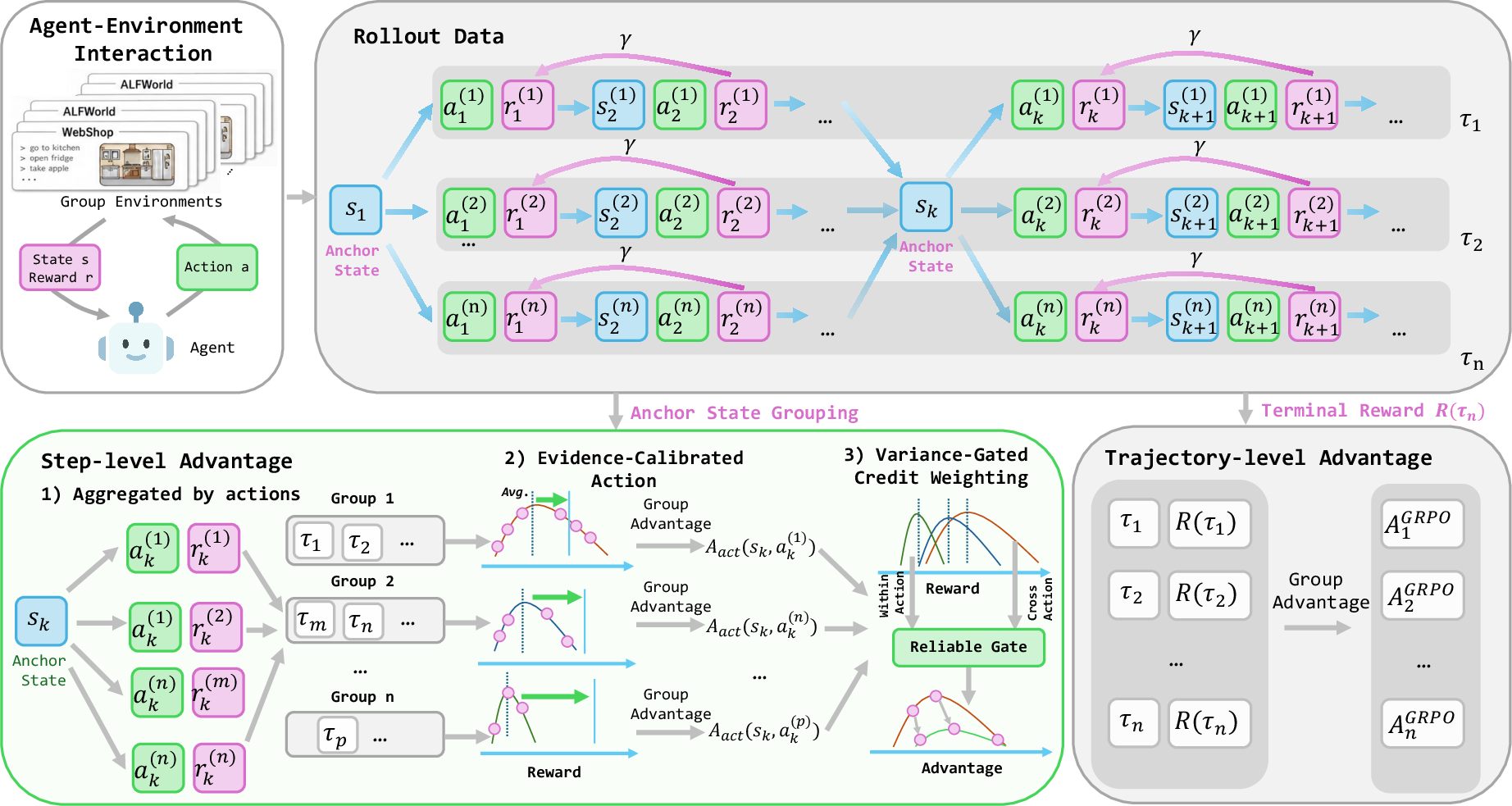
Figure 2: Ecpo workflow: grouped rollouts, action-level calibration, reliability weighting, and integration into stable policy optimization.
Experimental Validation and Results
Comprehensive evaluations on ALFWorld and WebShop—two benchmarks featuring multi-step agentic decision making and highly delayed rewards—demonstrate the advantage of Ecpo using Qwen2.5-1.5B and Qwen2.5-7B base models. Several salient findings are evident:
- Performance Gains: Ecpo consistently outperforms all baselines, including GiGPO, PPO, and RLOO. On ALFWorld, Ecpo delivers a +5.2 percentage point increase in overall success rate (1.5B model). On WebShop, the gain is +7.3 percentage points over GiGPO under identical settings.
- Stability: Ecpo substantially reduces late-stage reward variance and mitigates optimization oscillations present in GiGPO learning curves. The final reward standard deviation in ALFWorld is reduced from σ=0.746 (GiGPO) to σ=0.555 (Ecpo), indicating markedly more stable policy improvement.
- Robustness Across Rollout Budgets: Ecpo’s performance advantage is robust for rollout group sizes N∈{4,8,10}, suggesting the method generalizes beyond a fixed group size and adapts to available sample budgets via evidence calibration.
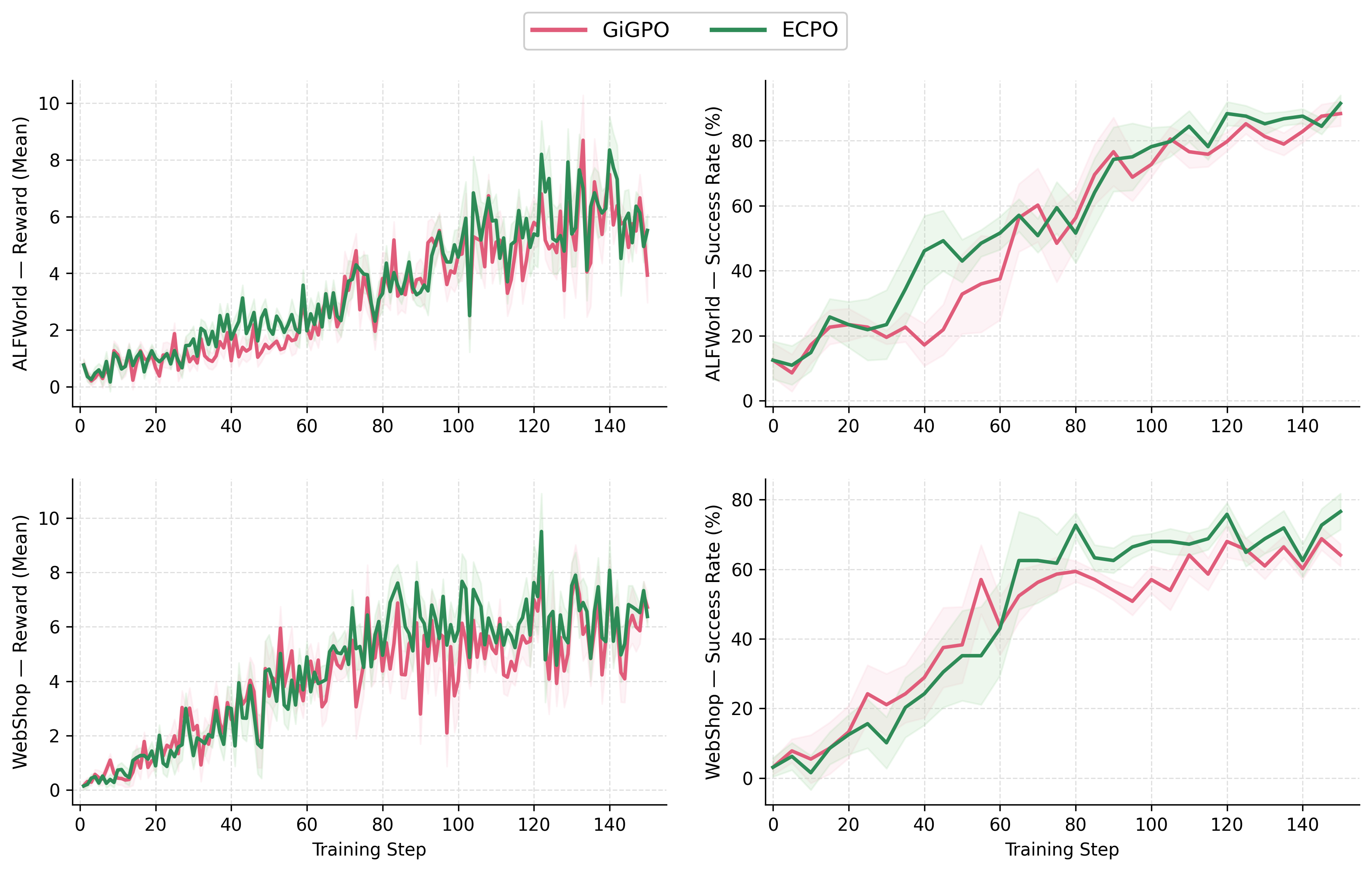
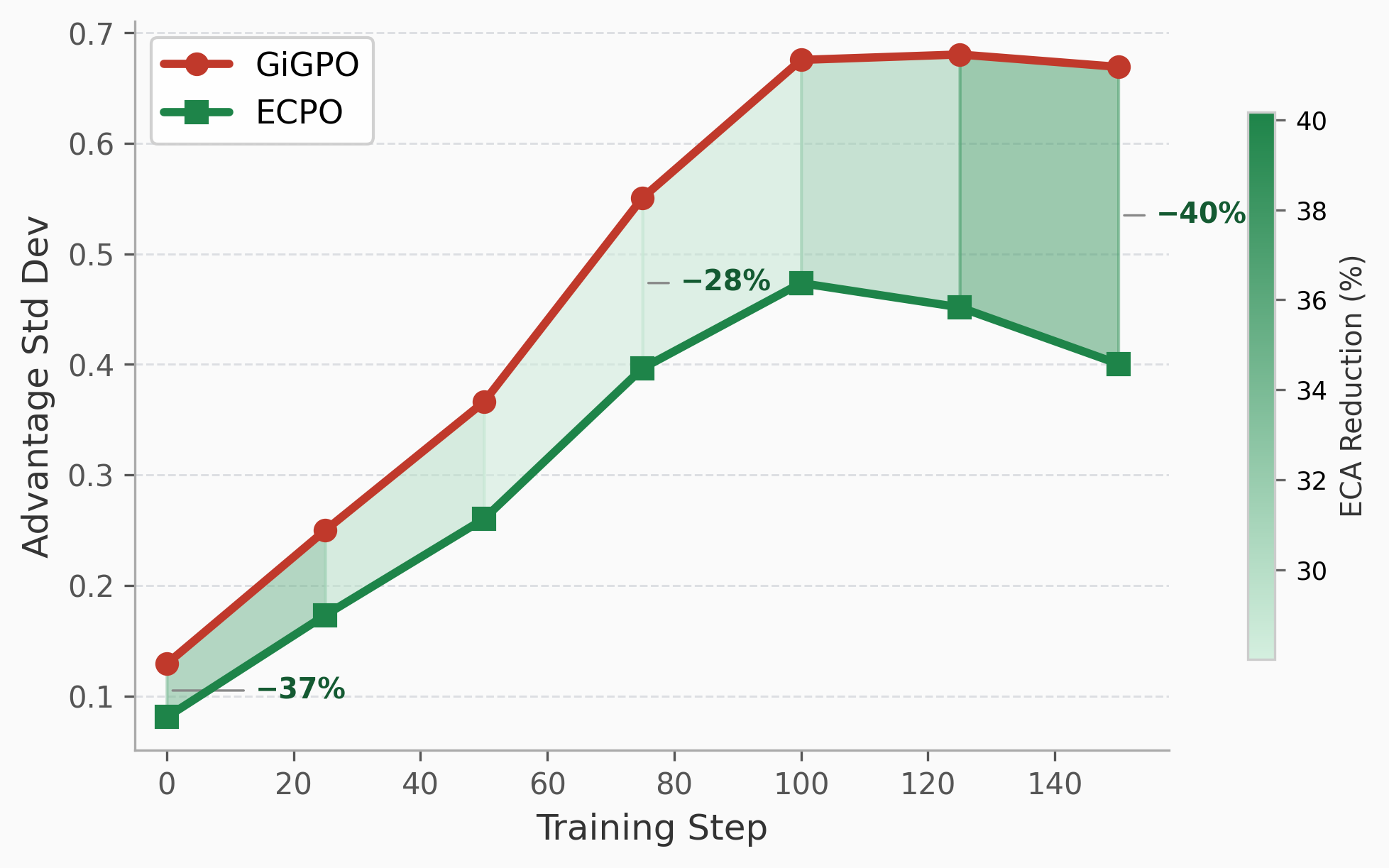
Figure 3: Ecpo yields higher final validation success and reduced reward oscillation on both ALFWorld and WebShop compared to GiGPO.
Ablation and Diagnostic Analysis
Targeted ablation studies underline the necessity and complementary effect of both ECA and VarGate. ECA alone lessens estimation bias by shrinkage, and VarGate independently suppresses unreliable anchor states. However, combining both mechanisms yields the highest task performance—confirming that reliable credit assignment requires both calibrated action evidence and anchor-level reliability gating.
Analyses of group size, estimated advantage ranges, and the distribution of reliability weights verify:
- ECA is especially crucial with smaller rollout groups, where sparsity amplifies estimation noise.
- VarGate effectively detects unreliable anchors and adaptively attenuates their influence.
- Increased rollout group sizes do not fully eliminate divergent anchor bias, supporting the claim that better statistical management, not merely more samples, is key to stable long-horizon RL.
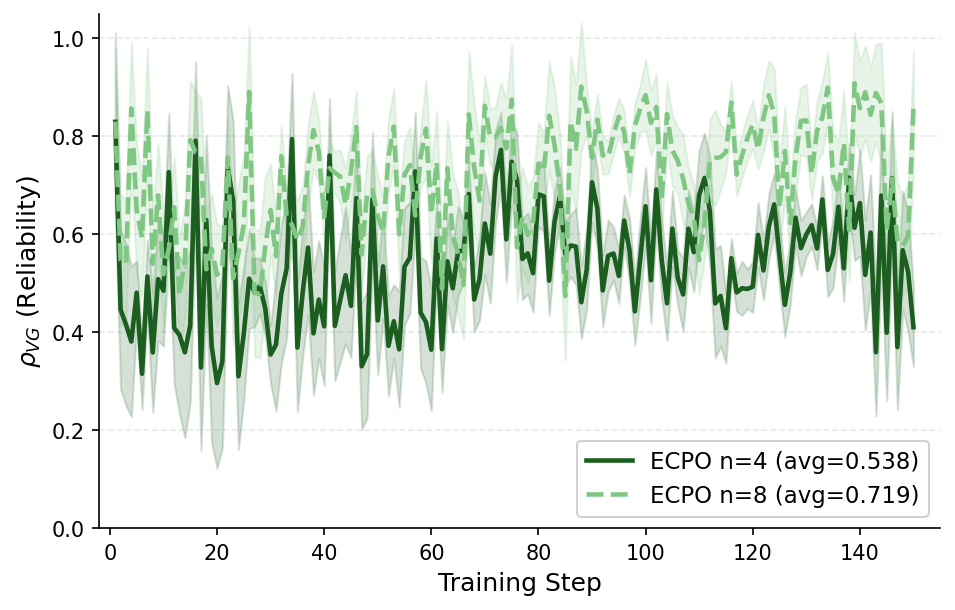
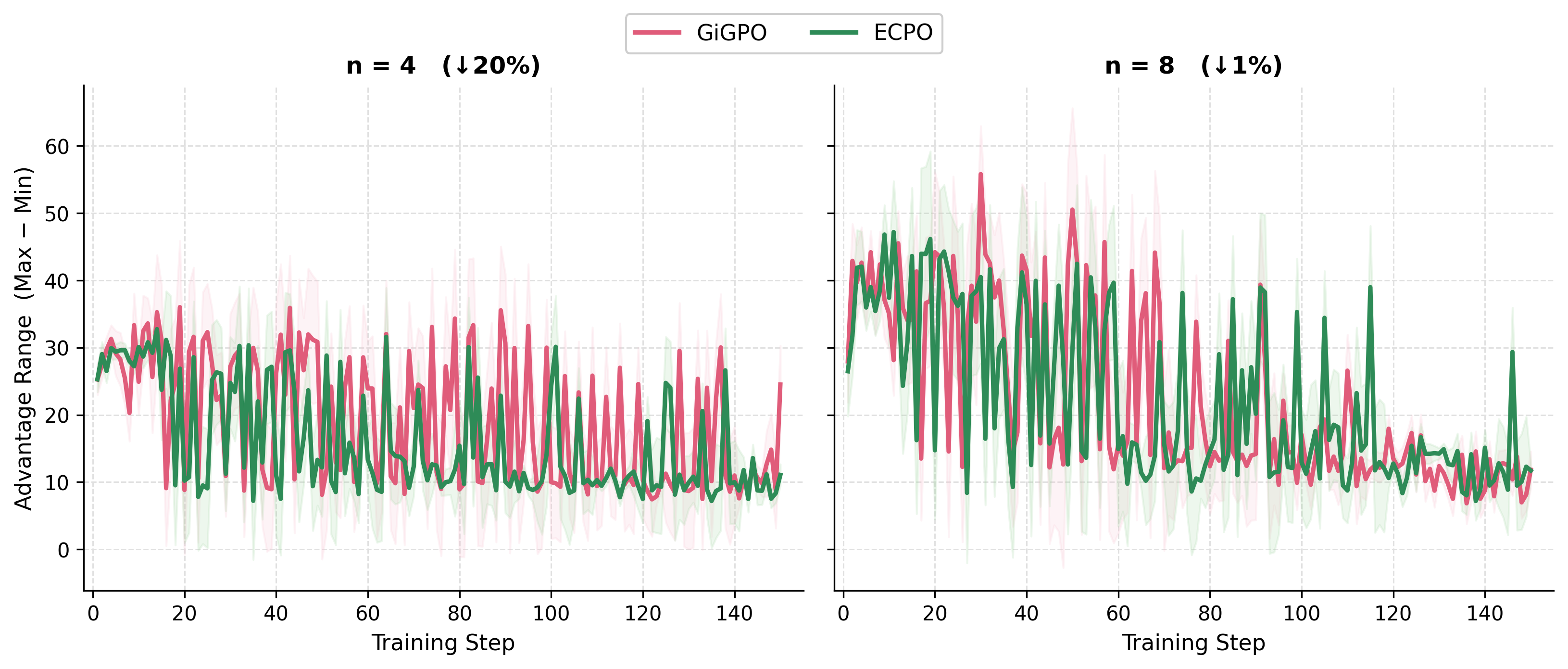
Figure 4: VarGate reliability weight decreases with smaller rollout groups, confirming automatic downweighting of unreliable anchor states when evidence is limited.
Theoretical and Practical Implications
This work reconceptualizes dense credit assignment as statistical evidence estimation, illustrating that in long-horizon, sparse-reward RL, more granular credit signals alone are insufficient and may even be detrimental if not accompanied by reliability corrections. The analysis shows how singleton (rare) actions cannot be robustly separated from noise, and why shrinkage and variance-gated mechanisms are required to limit policy update variance and catastrophic overfitting to noisy anchor states. Practically, Ecpo demonstrates that such statistical calibration can be implemented with negligible computational cost (0.1% overhead) in modern distributed RL training pipelines, making it suitable for scaling to large agentic LLMs and complex environments.
Theoretically, Ecpo’s calibration mechanism aligns with recent trends in RL for LLMs (Zhang, 10 Apr 2026, 2603.08754), which emphasize counterfactual reasoning, credit reliability, and critic-free stable updates. The methodology is likely to generalize to tool-augmented RL, hierarchical RL for LLMs, and multi-agent LLM coordination. Future directions may include more advanced Bayesian calibration, task-adaptive reliability criteria, and combination with high-fidelity behavioral cloning.
Conclusion
The introduction of Evidence-Calibrated Policy Optimization (Ecpo) establishes that reliable, stable long-horizon RL for LLM agents requires statistically calibrated step-level advantage estimation, not merely increased credit density. By shrinking low-count action estimates and variance-gating anchor state contributions, Ecpo suppresses divergent anchor bias, yields higher final performance, and delivers more consistent optimization dynamics with minimal additional cost. This framework is extensible and paves the way for the next generation of robust long-horizon RL methods for autonomous LLM agents.