- The paper introduces GraphGPO, a novel method that aggregates rollout trajectories into a unified state-transition graph for precise step-level credit assignment.
- It leverages a graph-based distance metric to compute rewards, ensuring actions that reduce the shortest-path distance to the goal are appropriately incentivized.
- Empirical evaluations on ALFWorld, WebShop, and Sokoban demonstrate significant success rate gains and robust learning efficiency with negligible computational overhead.
Motivation and Problem Statement
Agentic tasks solved by LLMs in complex, multi-turn environments require precise credit assignment for effective RL optimization. Traditional group-based RL frameworks, such as GRPO, rely on trajectory-level outcome attribution, granting uniform positive credit to all steps in successful trajectories and penalizing all steps in failed ones. This coarse mechanism fails to distinguish steps genuinely advancing toward the goal and overlooks progress hidden within failed trajectories. Empirical evidence shows that 22.0% of steps in failed trajectories actually contribute to task progress in ALFWorld, while 65.3% of steps in successful trajectories are non-progress steps (Figure 1).
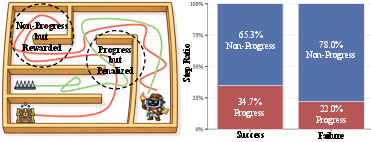
Figure 1: Trajectory-level credit assignment misaligns step-level progress statistics in multi-turn ALFWorld tasks, with substantial progress obscured in failed trajectories and redundant actions rewarded in successful ones.
These findings motivate a finer-grained approach that transcends trajectory-level attribution to capture the true contribution of individual steps, especially in sparse-reward environments and long-horizon agentic settings.
Methodological Advances: GraphGPO
Aggregated State-Transition Graph Construction
GraphGPO introduces a paradigm shift by synthesizing all rollout trajectories into a unified directed state-transition graph. Each state encountered across all trajectories is mapped to a node, and each action-induced transition forms a directed edge with an associated cost. Identical states across different trajectories are merged into single nodes, facilitating the aggregation of global experiential information. The terminal states include both success (goal completion) and predefined failure (over-length or dead-end).
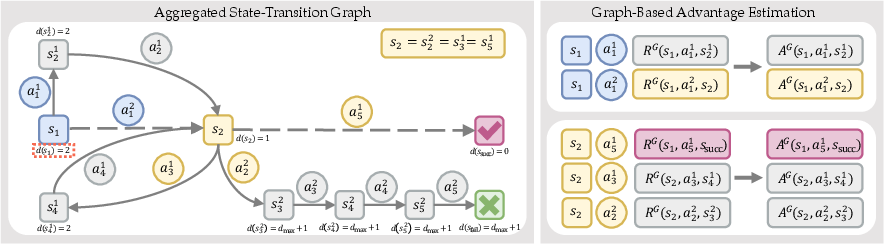
Figure 2: State-transition graph aggregates trajectory rollouts, merging identical states and encoding transitions across paths; credit is assigned via shortest-path distance to goal.
Graph-Based Step-Level Credit Assignment
For any state, the minimum-cost path to the goal is computed—yielding a distance metric d(s). Step-level rewards are defined as:
RG(s,a,s′)=rsucc⋅ωd(s′)+c(s,a)
where rsucc is the scalar reward for success, and ω is a discount factor. States empirically unable to reach the goal are penalized by substituting dmax+1 for +∞. Each outbound edge from a state is grouped, facilitating per-state group-based advantage estimation:
AG(s,a,s′)=σ(GG(s))RG(s,a,s′)−μ(GG(s))
where μ and σ are group-level statistics. This advantage function is strictly monotonic: actions that move closer to the goal receive higher credit regardless of their trajectory outcome.
Policy Optimization Objective
To ensure robustness where graph-based credit could degenerate (e.g., singleton transitions), the final advantage used for policy optimization is a weighted sum of graph-based and episode-level advantage. Policy update follows a clipped importance-sampling formulation with a KL-divergence penalty to maintain reference policy proximity.
Empirical Results
GraphGPO is evaluated on challenging multi-turn agentic benchmarks—ALFWorld, WebShop, and Sokoban—using Qwen2.5-1.5B-Instruct and Qwen2.5-7B-Instruct as base LLMs, and Qwen2.5-VL-3B-Instruct for VLM scenarios. Results are benchmarked against competitive baselines: GRPO, GiGPO, PPO, prompting-based (ReAct, Reflexion), and closed-source LLMs (GPT-4o, Gemini-2.5-Pro).
- GraphGPO achieves average success rate gains of 14.85% and 11.98% over GRPO for Qwen2.5-1.5B and Qwen2.5-7B-Instruct respectively on ALFWorld.
- On WebShop, GraphGPO improves success rate by 7.30% and 5.31% over GRPO.
- In Sokoban, deterministic vision-language settings, GraphGPO surpasses GRPO by 19.88% and GiGPO by 10.06%.
Training dynamics consistently show faster early-stage improvement, superior convergence, and persistent lead of GraphGPO versus baselines, attributable to globally-informed step credit signals.
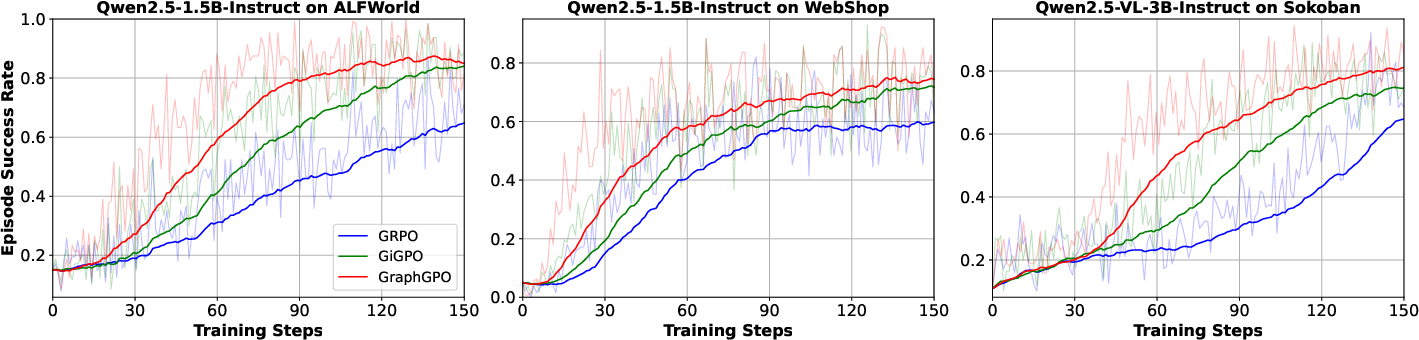
Figure 3: GraphGPO training curves across ALFWorld, WebShop and Sokoban display improved convergence and sustained advantage over GiGPO and GRPO.
Validation success rates reinforce these training trends, and ablation studies demonstrate that step-level graph-based advantages (AG) deliver higher fidelity supervision than GiGPO's trajectory-based step grouping, especially when combined with episode-level advantage.
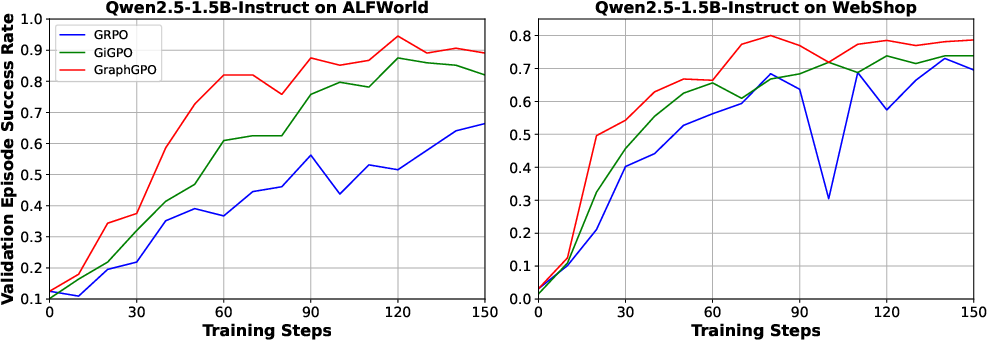
Figure 4: Validation episode success rates versus training steps show robust generalization and efficiency of GraphGPO’s credit assignment.
Computational Efficiency
Despite the global aggregation and shortest-path computations, GraphGPO incurs negligible time and memory overhead. The graph is maintained via hash table structures, and Dijkstra-based distance calculations are dominated by rollout sampling and policy update costs (RG(s,a,s′)=rsucc⋅ωd(s′)+c(s,a)0 of total iteration runtime). Thus, GraphGPO retains the critic-free, low-memory, stable convergence characteristics of group-based RL.
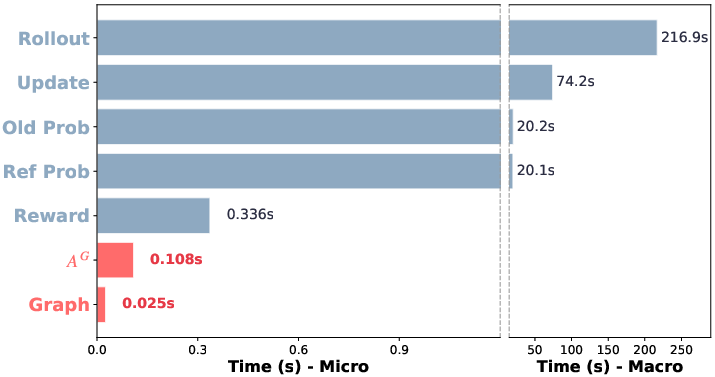
Figure 5: Per-iteration runtime breakdown demonstrates minimal computation overhead for graph construction and advantage calculation in GraphGPO.
Theoretical Implications
GraphGPO demonstrates two key theoretical properties:
- Monotonicity: Actions reducing shortest-path distance to the goal always receive higher advantage, controlling for episode-level outcome.
- Conditional variance reduction: Graph-based step-level feedback exhibits strictly lower conditional variance compared to episode-attributed step feedback (GiGPO/GRPO), ensuring higher signal-to-noise ratio for RL gradients and more efficient learning.
Practical Implications and Prospects
GraphGPO establishes a scalable, critic-free RL framework for LLM-powered agents that faithfully uncovers latent progress within failed trajectories, penalizes redundancy, and leverages global rollout structure for rapid policy improvement. The formulation is robust to observation noise (with embedding-based state matching available), and flexible to rollout group size. As LLM agents transition to increasingly complex, high-dimensional, and real-world settings, graph-based credit assignment will serve as a foundational principle for learning in sparse-reward, long-horizon agentic domains.
Further avenues include hierarchical graph aggregation, dynamic group sampling, and extension to multi-agent or tool-use RL paradigms, potentially advancing autonomous reasoning and planning for future generalist models.
Conclusion
GraphGPO enables fine-grained, globally-informed, step-level credit assignment by aggregating episode rollouts into a state-transition graph and assigning rewards based on progress toward the goal. This approach outperforms trajectory-level baselines across diverse agentic tasks, improves learning efficiency, and retains operational scalability. It delivers a principled mechanism for RL optimization in LLM-powered agents, complementing and extending existing group-based RL techniques for long-horizon environments (2605.26684).

