- The paper presents HGPO, which applies context-aware hierarchical grouping and adaptive advantage aggregation to reduce bias in long-horizon reinforcement learning.
- It addresses historical context inconsistency by interpolating between high-bias large groups and low-bias small groups, leading to improved credit assignment.
- Experimental results show HGPO outperforms previous methods on ALFWorld and WebShop benchmarks, particularly benefiting smaller LLM-based models.
Hierarchy-of-Groups Policy Optimization for Long-Horizon Agentic Tasks
Introduction
The increasing deployment of LLM-based agents in complex, open-ended, long-horizon tasks has highlighted the limitations of standard post-training reinforcement learning (RL) algorithms, especially in the context of effective credit assignment. While group-based RL methods such as GRPO and GiGPO have provided scalable critic-free RL for large models, they persistently suffer from bias in advantage estimation due to inconsistency in historical context—an effect that is amplified in stepwise frameworks where context length and variability become prominent.
The paper "Hierarchy-of-Groups Policy Optimization for Long-Horizon Agentic Tasks" (2602.22817) addresses this core issue by introducing Hierarchy-of-Groups Policy Optimization (HGPO), which incorporates context-aware hierarchical grouping and adaptive advantage aggregation to mitigate the adverse effects of context inconsistency on long-horizon policy optimization.
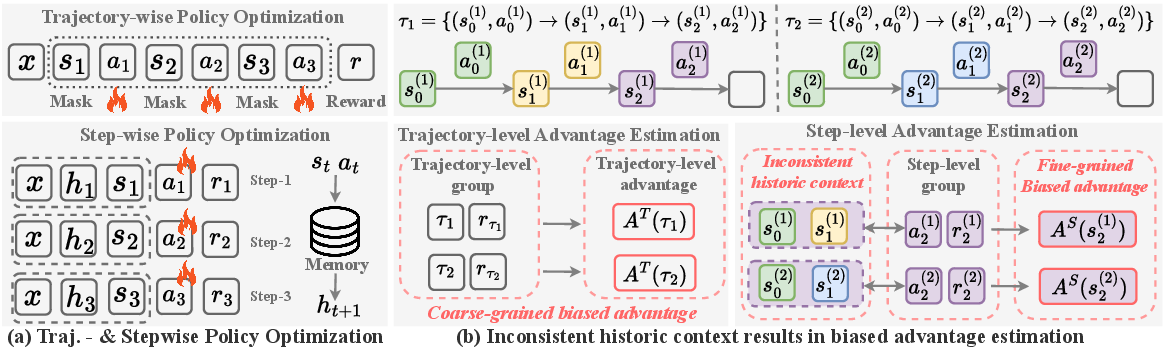
Figure 1: Comparison of trajectory-wise and stepwise policy optimization frameworks. Stepwise grouping allows finer credit assignment but exposes inconsistency issues in historical context.
Context Inconsistency in Long-Horizon Group-Based RL
Group-based RL, especially under the stepwise paradigm, performs advantage estimation by pooling steps that share the same current state, ignoring divergence in their historical contexts—a point illustrated by inconsistent prompts in the memory buffer even when observing the same state. The paper empirically demonstrates that both trajectory-level (high bias) and step-level (less but significant bias) advantage estimations fail to correctly capture the true relative advantage, except for the notionally ‘Oracle’ grouping, which aligns both state and historical context. However, Oracle steps are rare, resulting in high-variance estimates and ineffective training.

Figure 2: Advantage estimation bias and group size statistics for GRPO/GiGPO, illustrating the trade-off between bias (trajectory-/step-level) and sample scarcity (Oracle level).
The HGPO Algorithm
HGPO introduces two main innovations:
Context-Aware Hierarchical Grouping
Instead of a flat grouping, HGPO hierarchically partitions steps first by current state and recursively by increasing lengths of shared history. For a maximum context length K, this yields groupings from state-only (lowest level) to fully-aligned historical context (highest, i.e., Oracle). Each hierarchical group supports localized advantage estimation, interpolating between the high-bias/low-variance (large groups) and low-bias/high-variance (small groups) regimes.
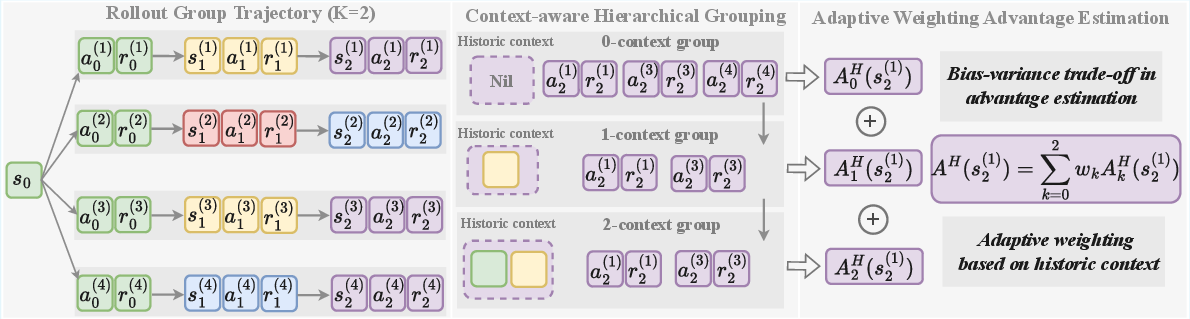
Figure 3: HGPO groups rollout steps according to the depth of shared history, assigning each step to a multi-level group structure for context-sensitive advantage estimation.
Adaptive Weighted Advantage Aggregation
HGPO adaptively aggregates the advantage estimates across hierarchical groups for each step using a closed-form weighting scheme, where higher weights are assigned to groups with longer shared contexts (parameterized by exponent α). This blending enables a favorable bias-variance trade-off for the final advantage estimate used in policy gradients. Theoretical analysis establishes that the bias and variance of the HGPO estimator interpolate between those of the step-level and Oracle estimators.
Experimental Results
Experiments are performed on two challenging agentic RL benchmarks—ALFWorld and WebShop—using Qwen2.5-1.5B-Instruct and Qwen2.5-7B-Instruct as base LLM agents. Strong baselines include prompting-only agents, classic PPO, RLOO, GRPO, and GiGPO.
Key findings include:
- HGPO achieves the highest overall success and task rates across both environments and models, surpassing GiGPO by up to 4.36% on WebShop and 1.08–4.01% on ALFWorld depending on K, under identical computational constraints.
- HGPO's gains are especially pronounced for smaller models (Qwen2.5-1.5B), attributed to their increased tendency for redundant or inconsistent behavior during rollouts.
- Increasing K (more context remembered per step) further boosts performance for both GiGPO and HGPO, but only HGPO maintains robust generalization on out-of-distribution tasks.
- Oracle groupings (complete context alignment) are too sparse for reliable estimates, confirming the necessity of hierarchical aggregation.
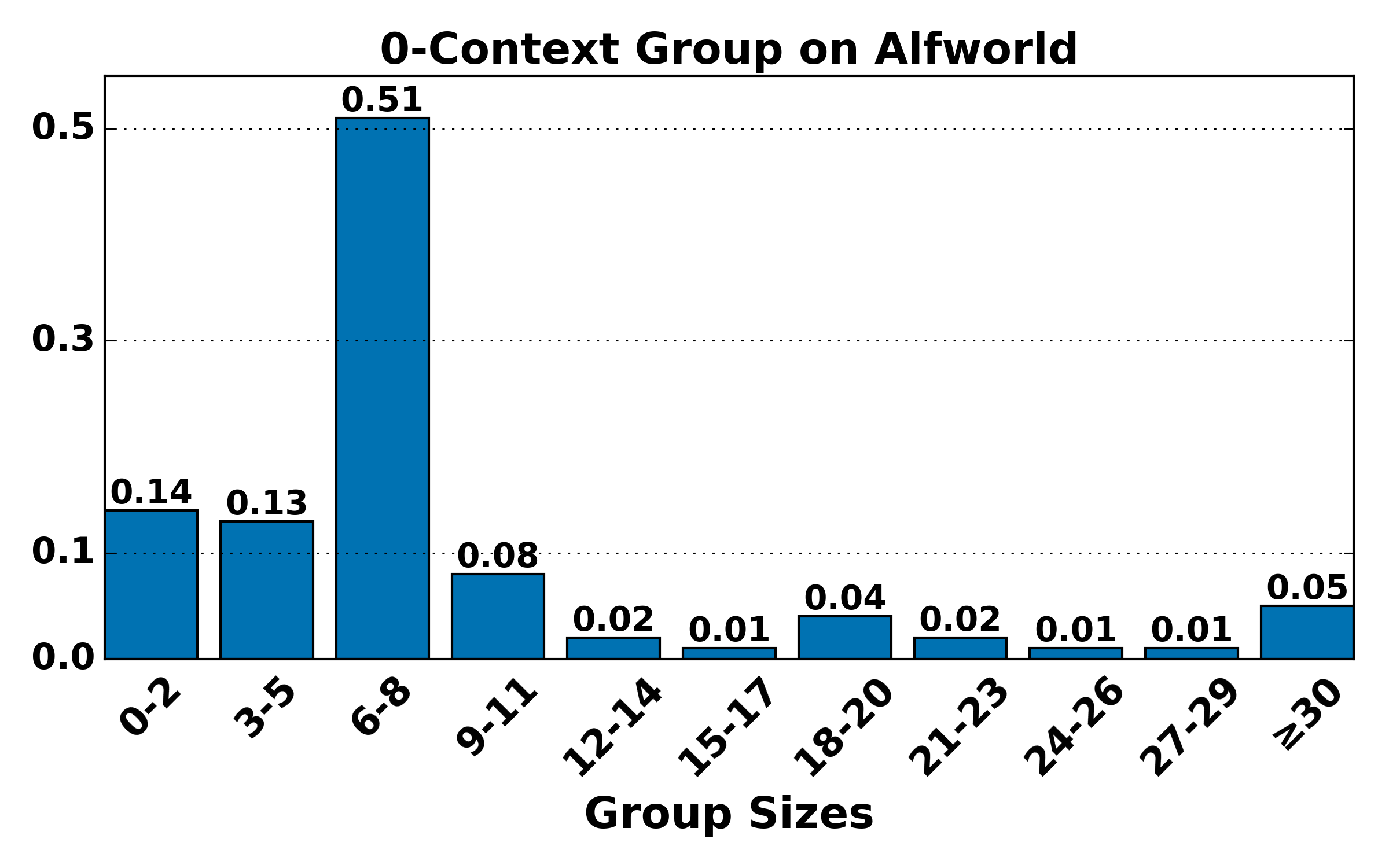
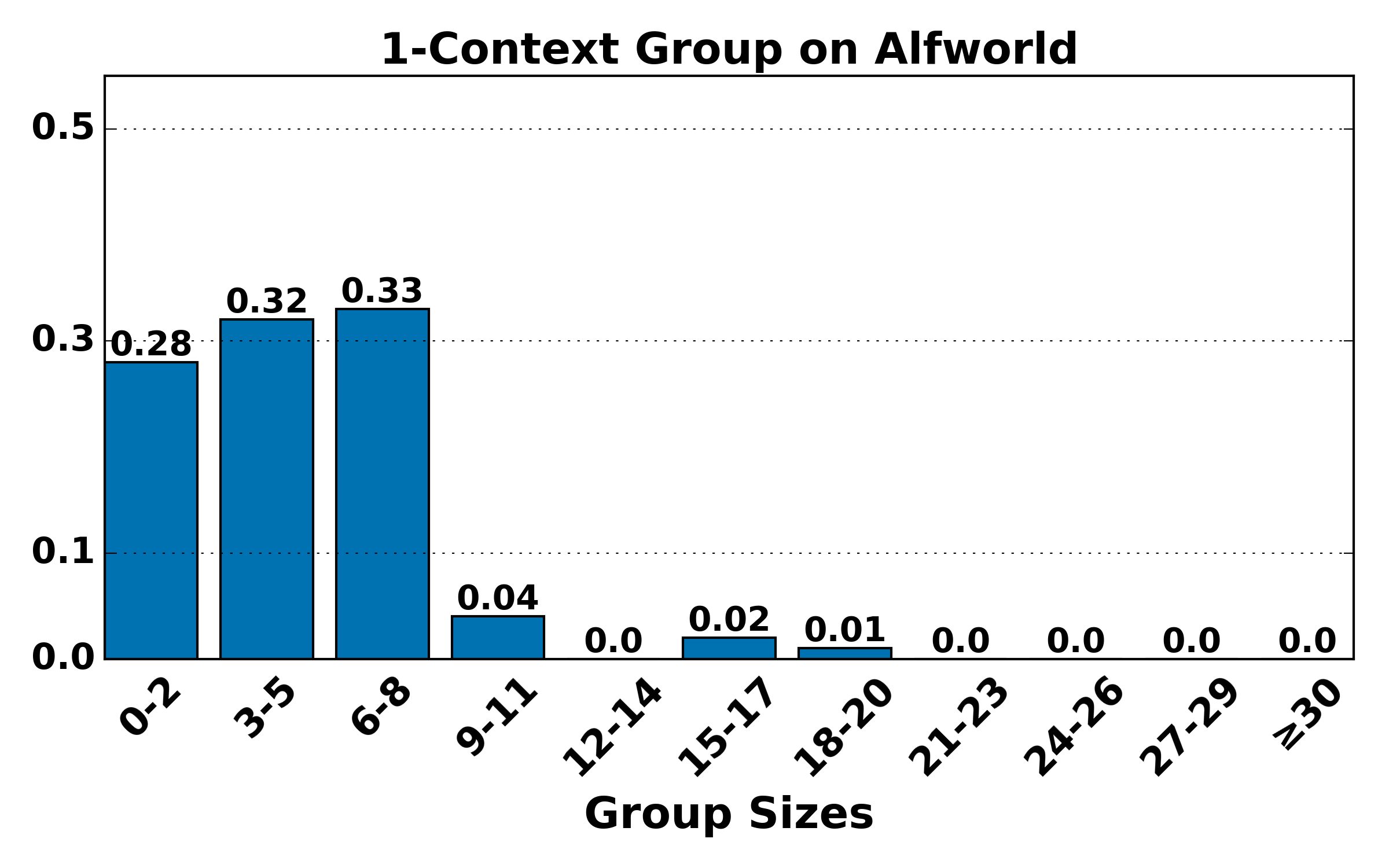
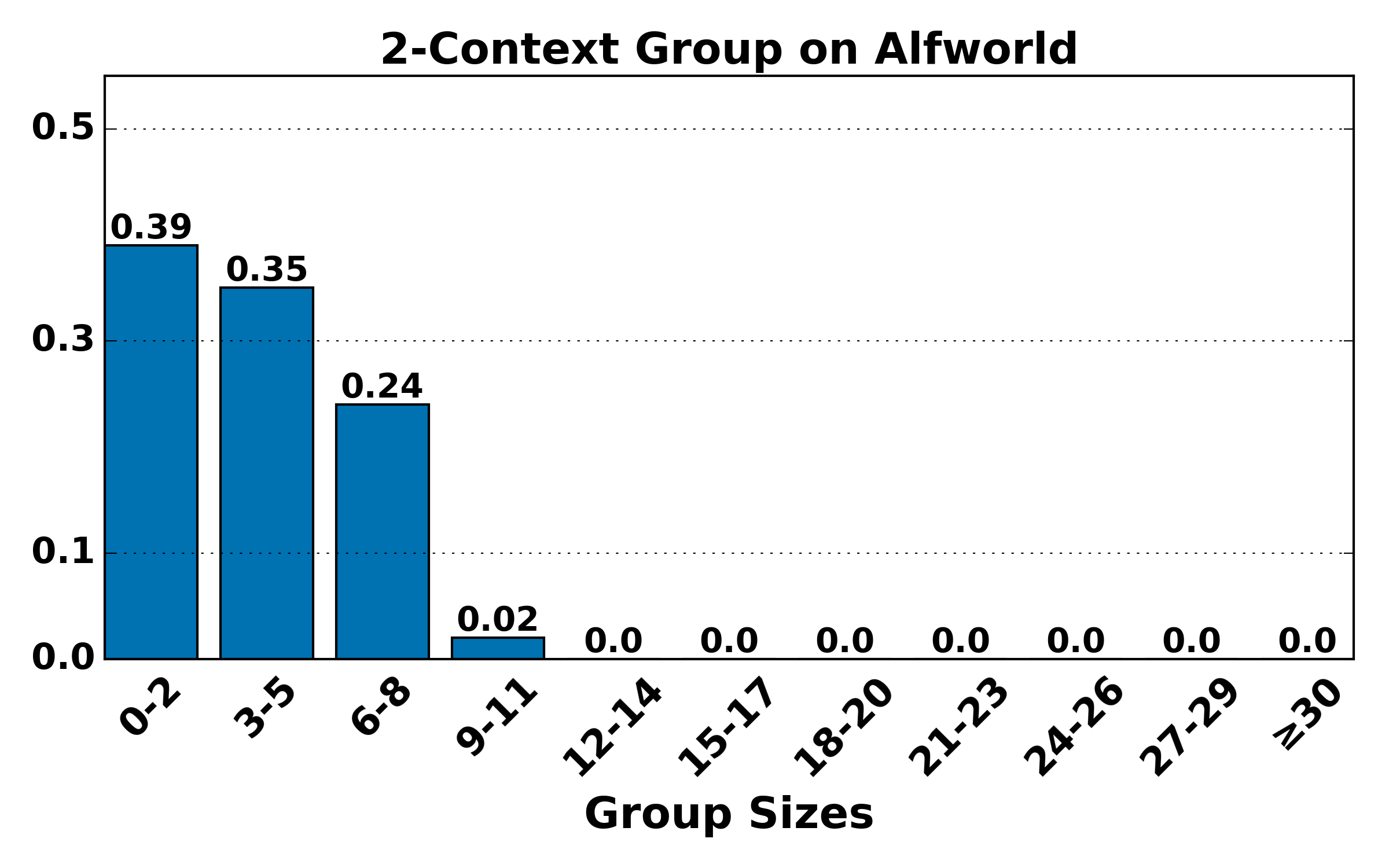
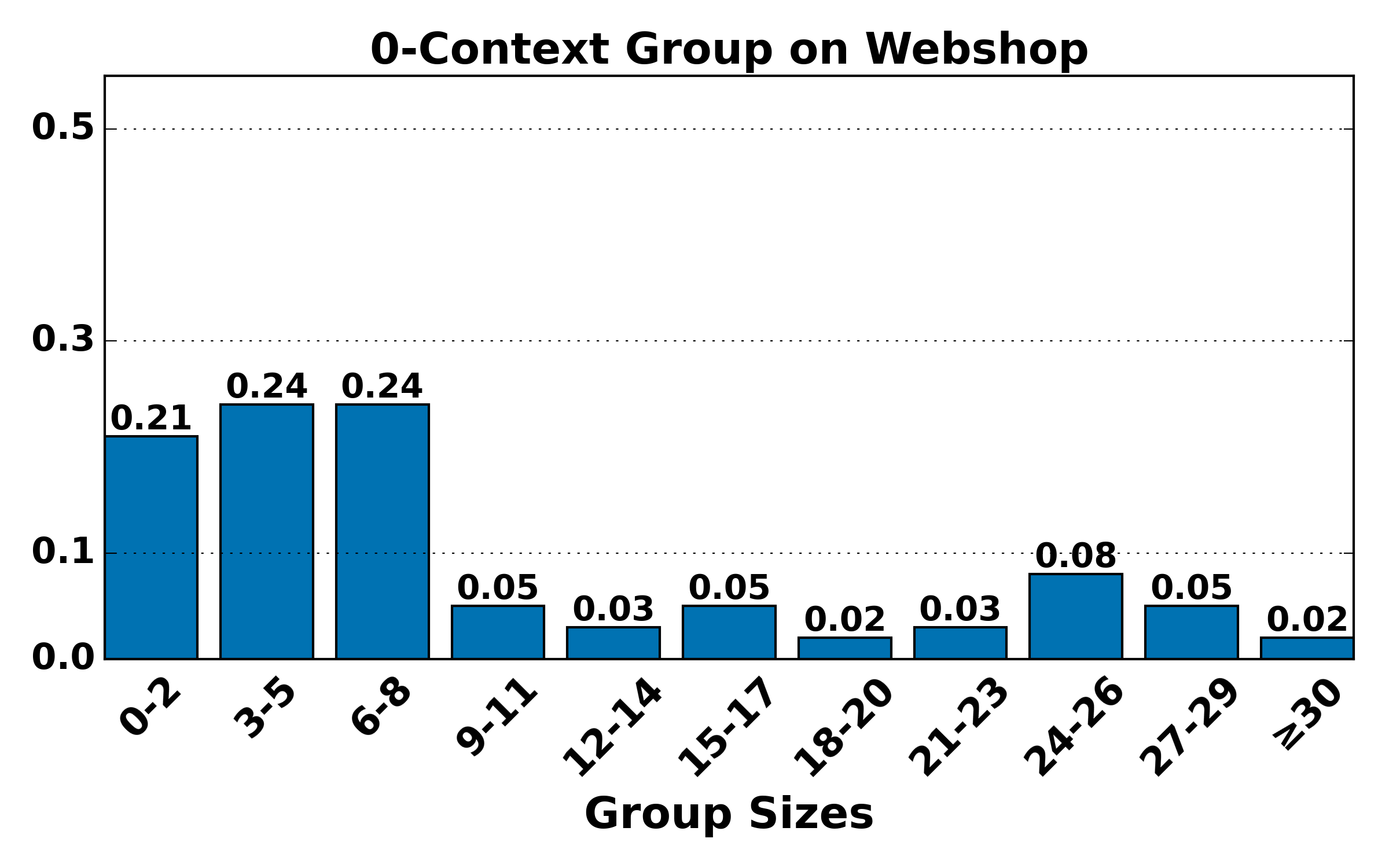
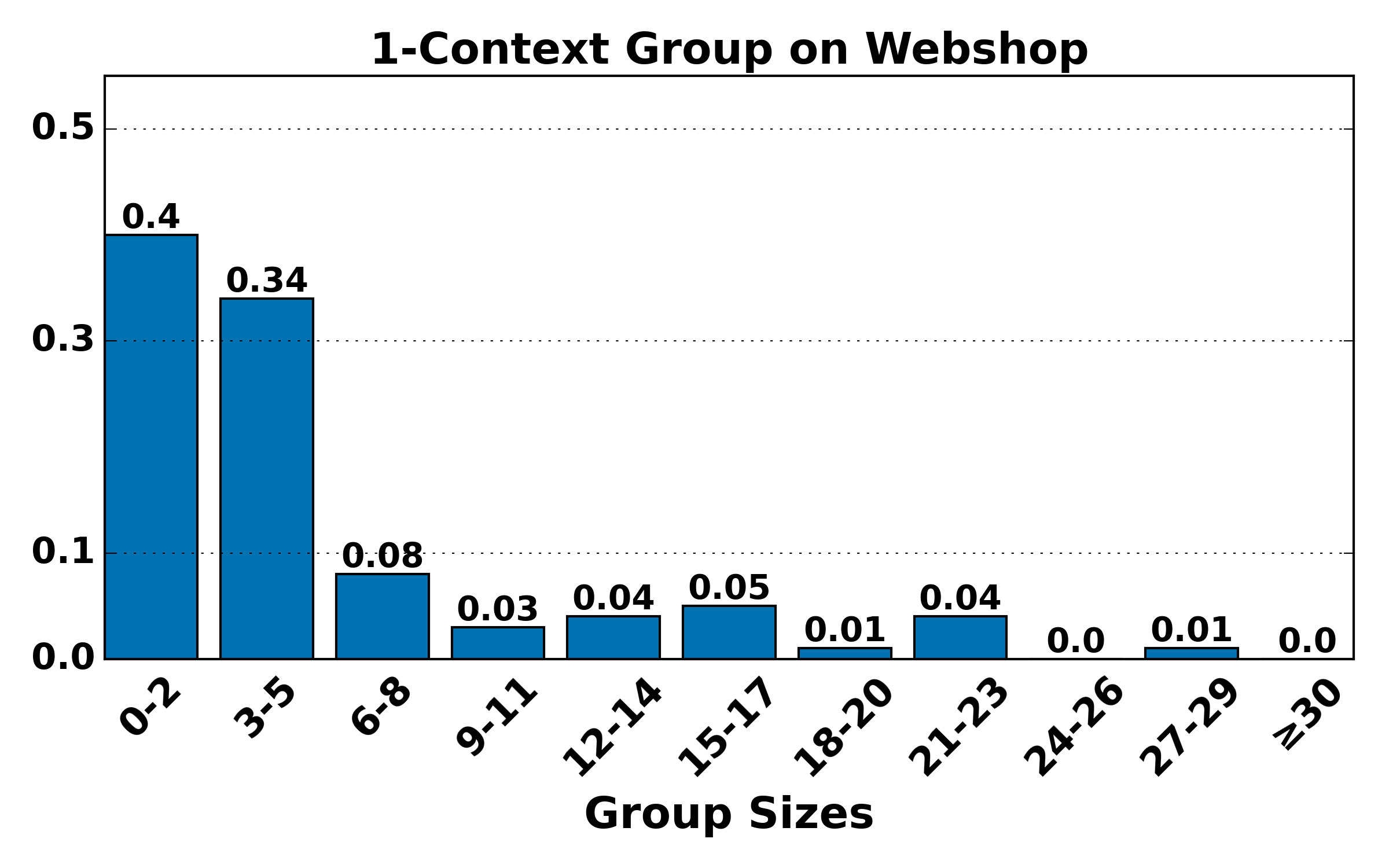
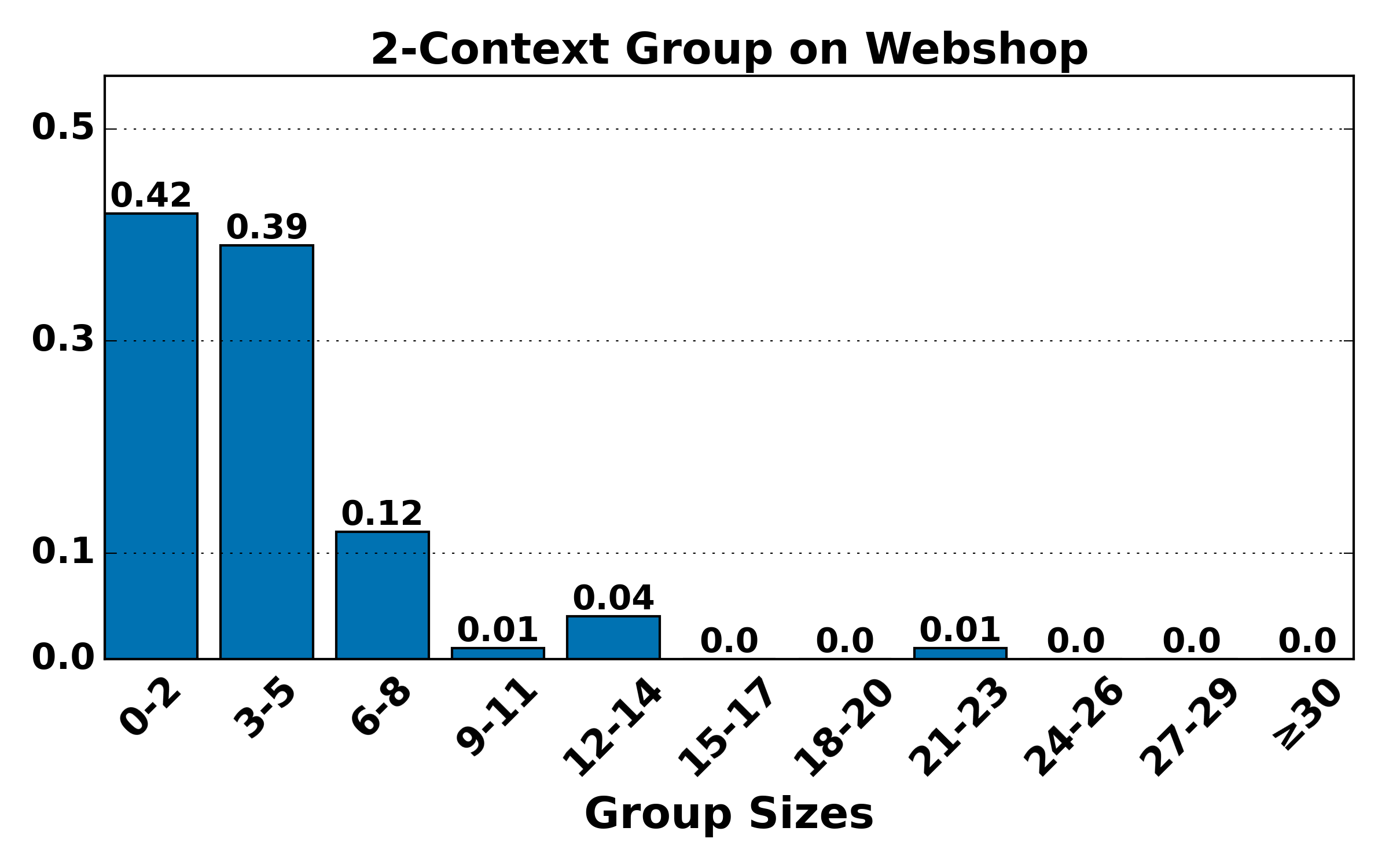
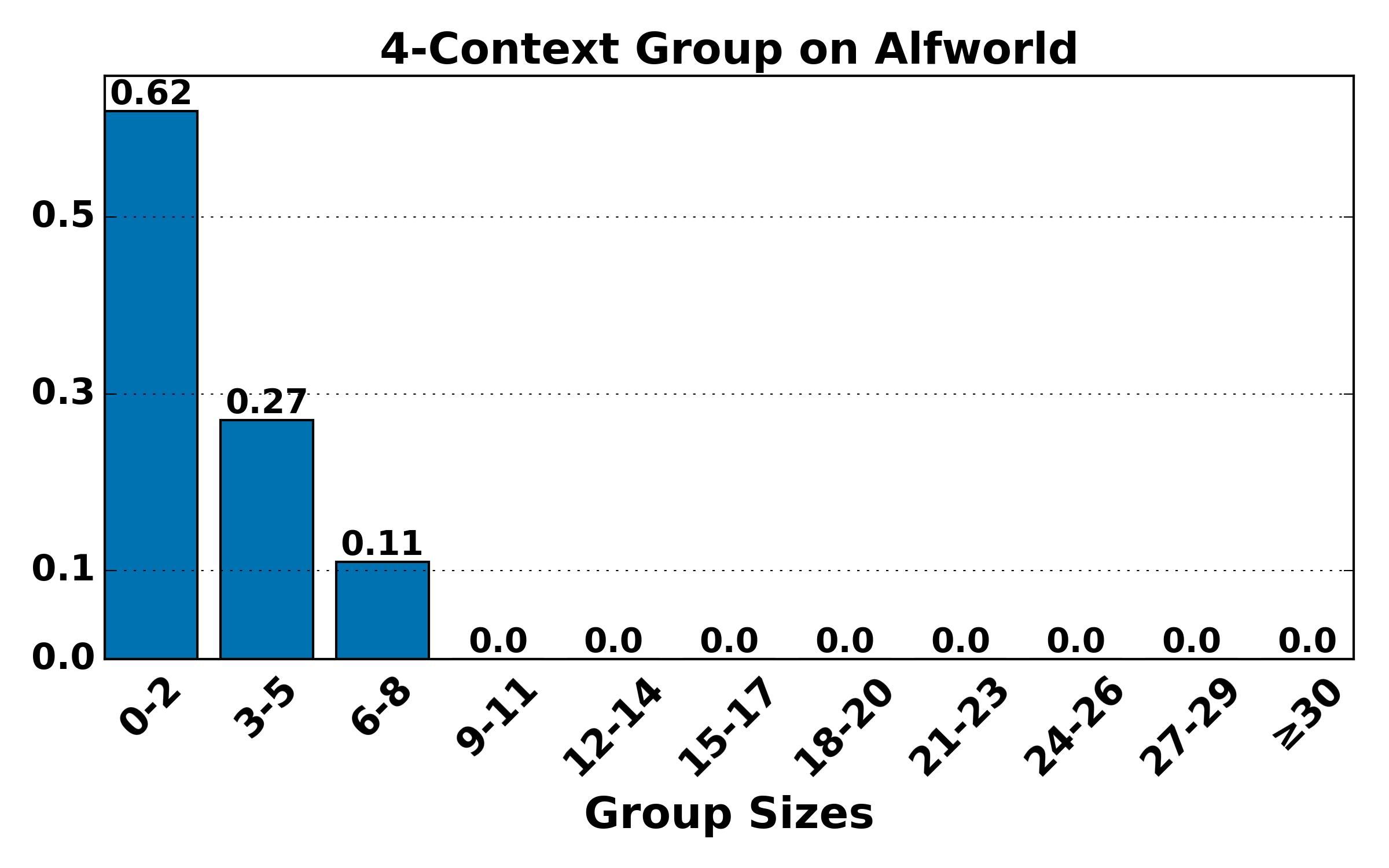
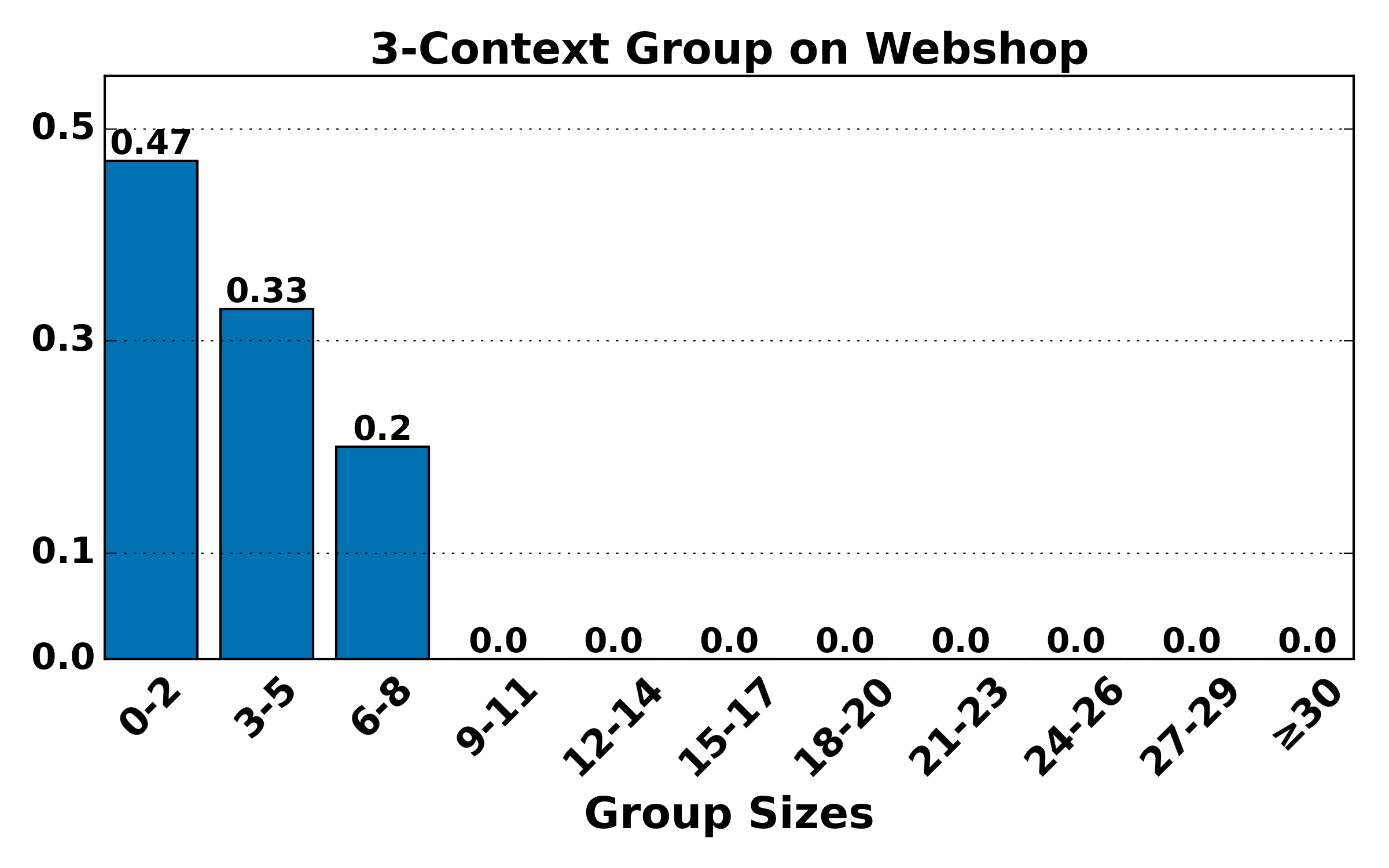
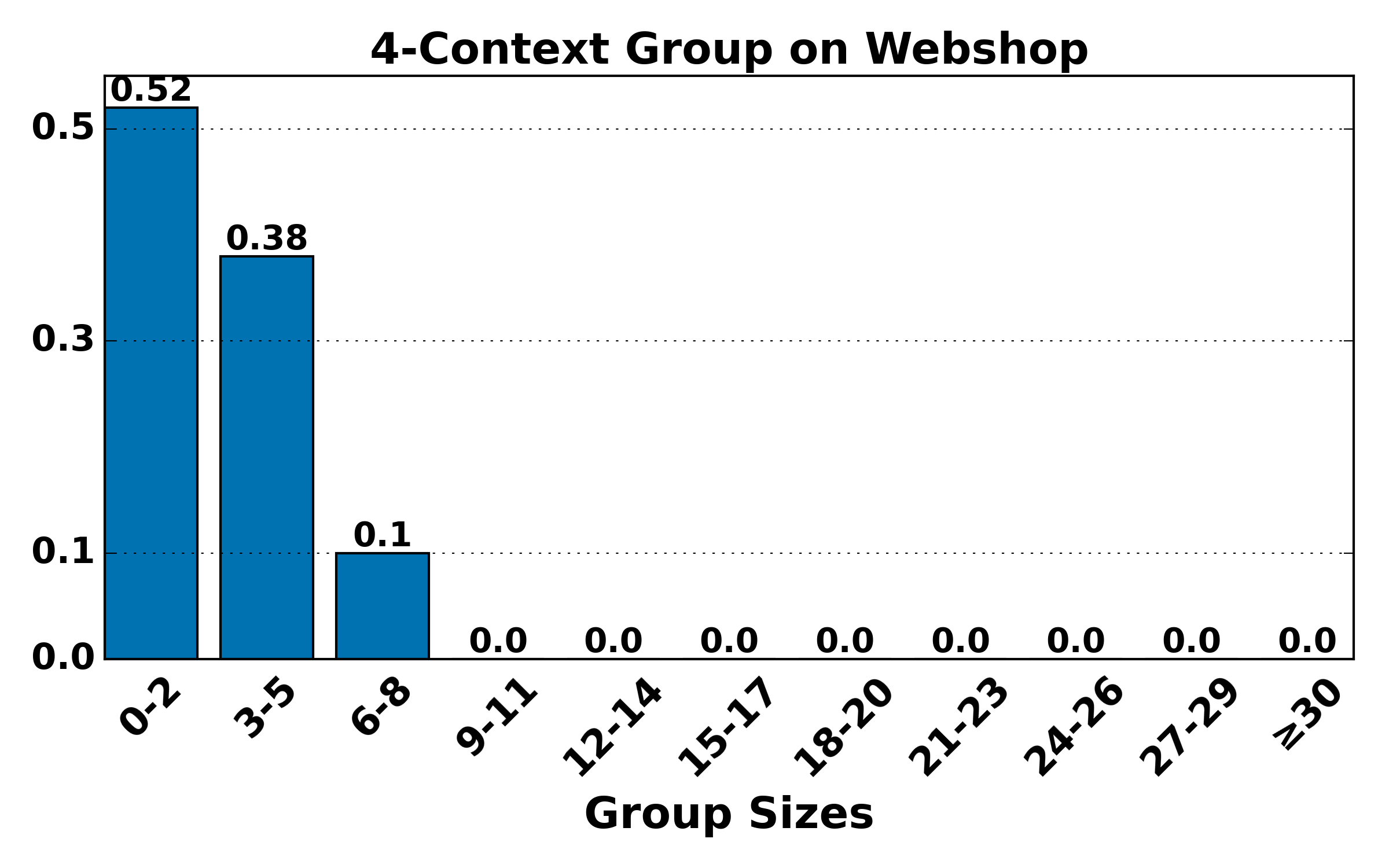
Figure 4: Distribution of group sizes for contexts of various lengths on ALFWorld and WebShop; large-group mass shifts toward smaller sizes as context alignment increases, raising variance but reducing bias.
HGPO further exhibits stable training dynamics and negligible time and memory overhead relative to prior stepwise group-based approaches.
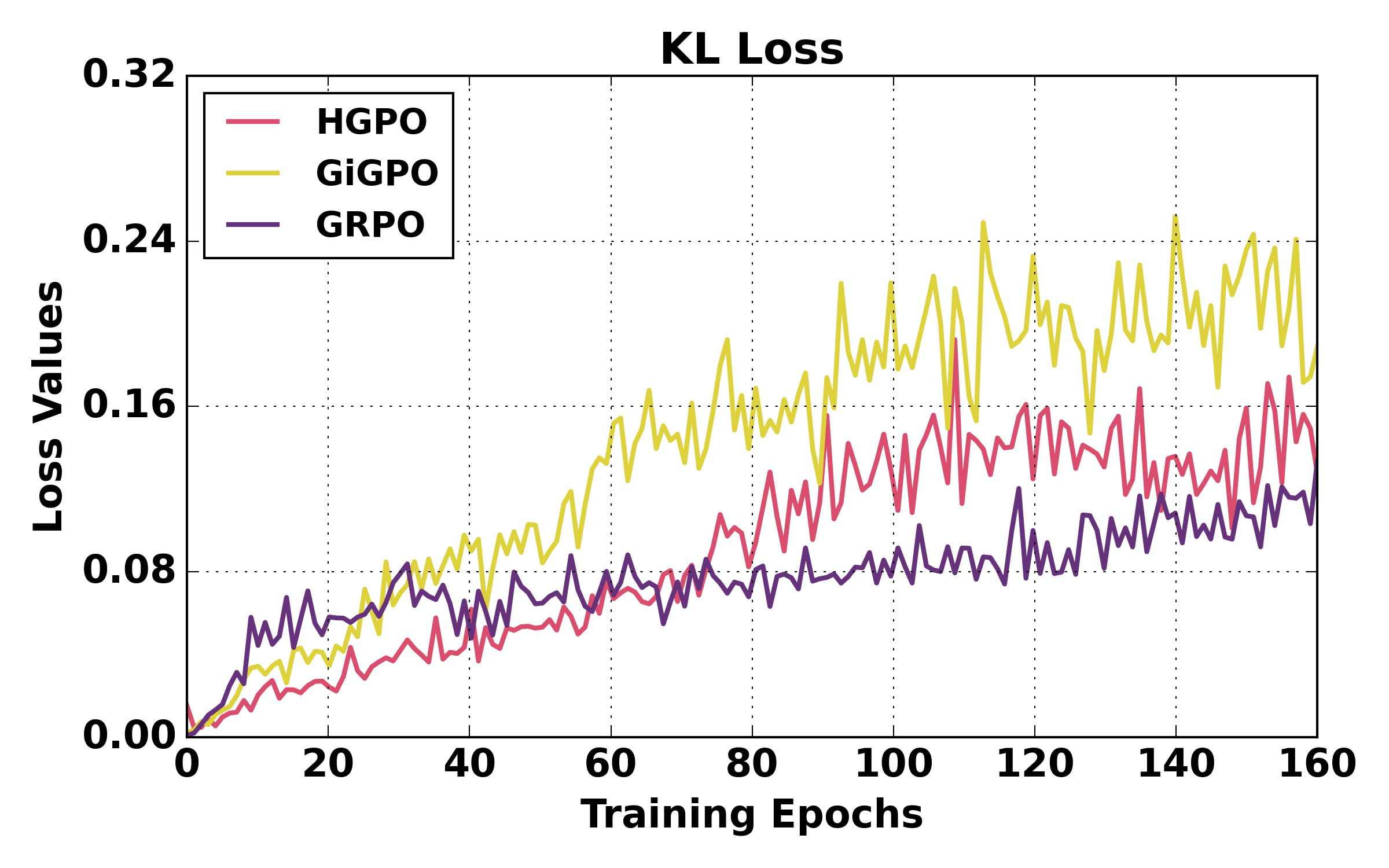
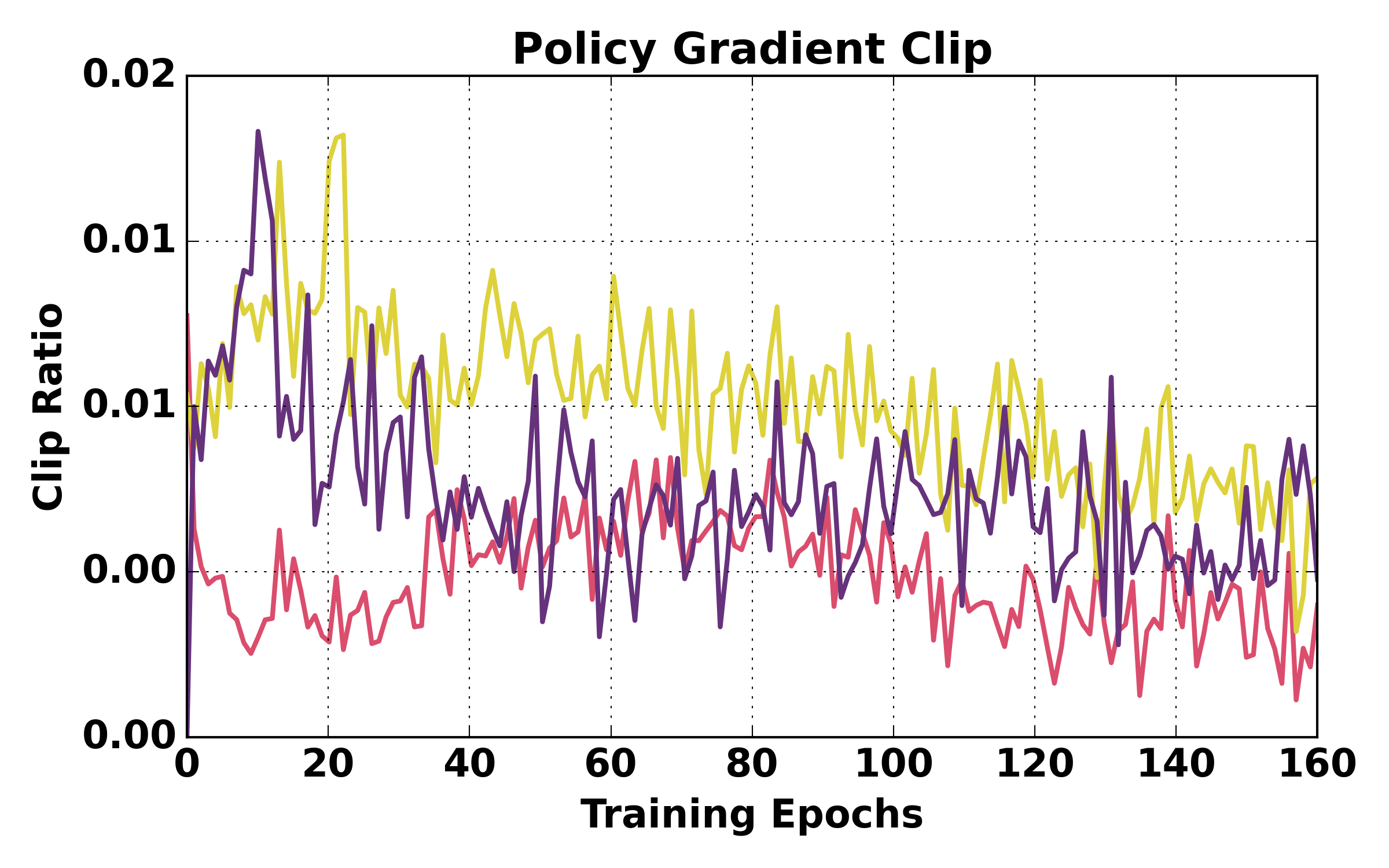
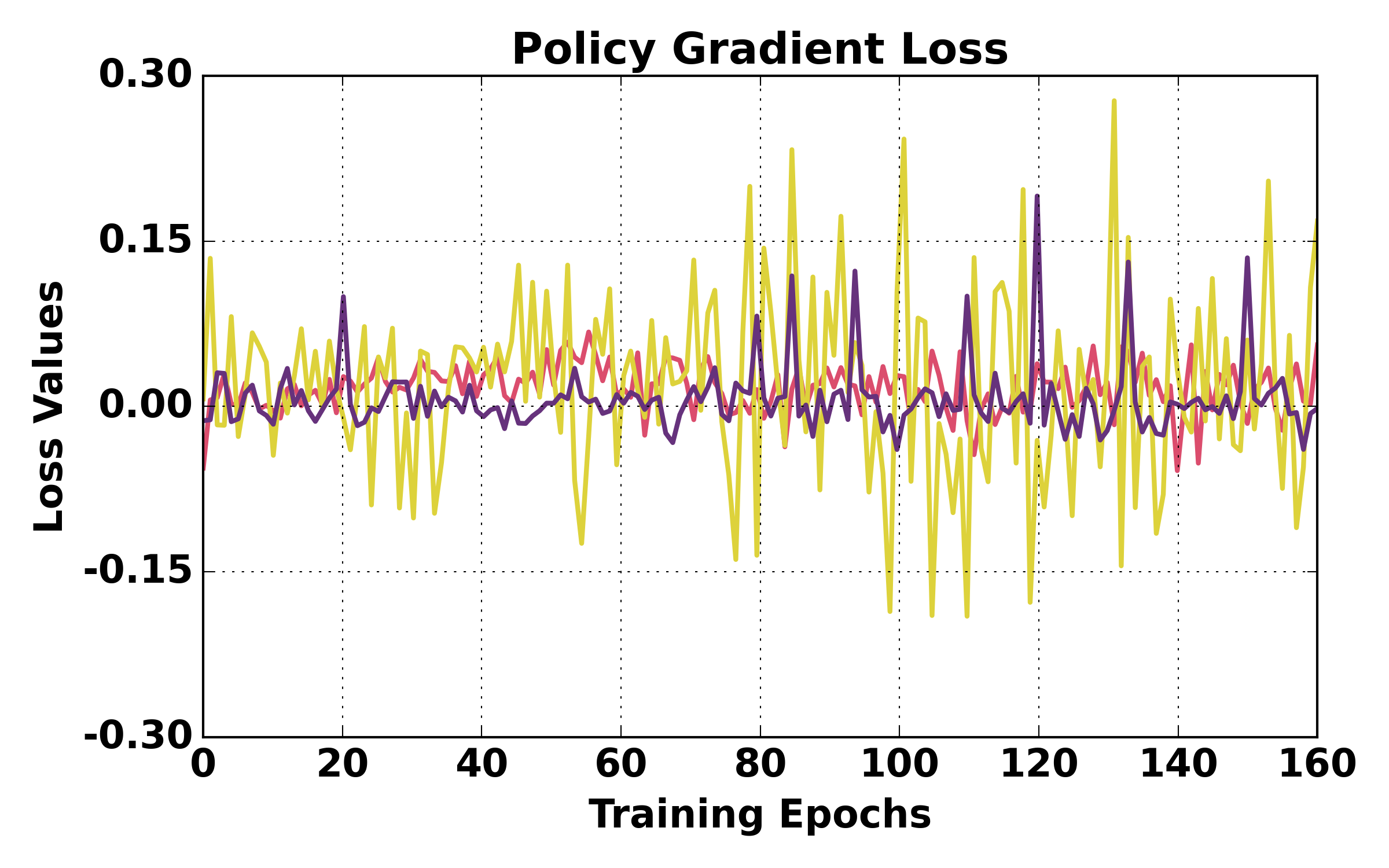
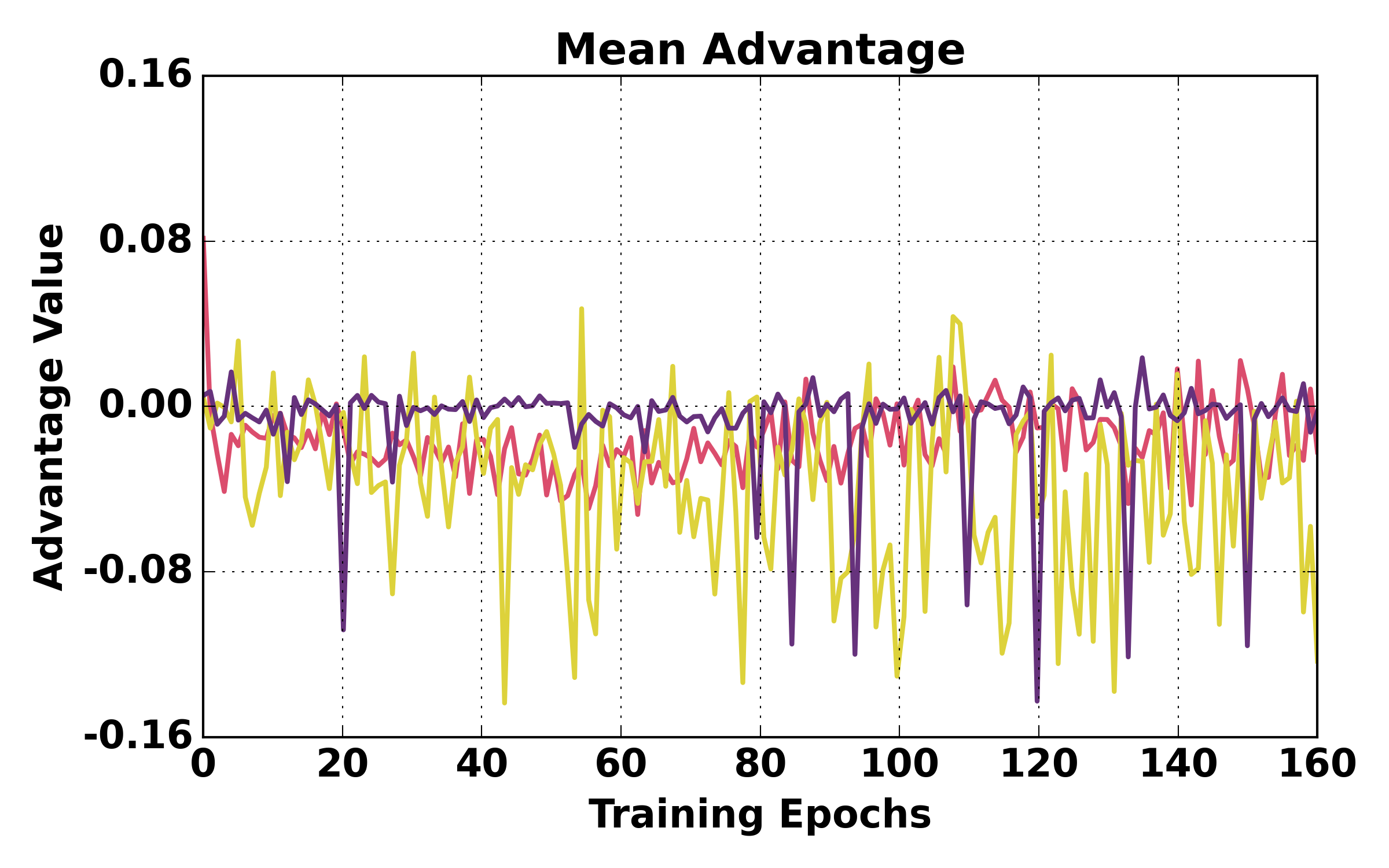
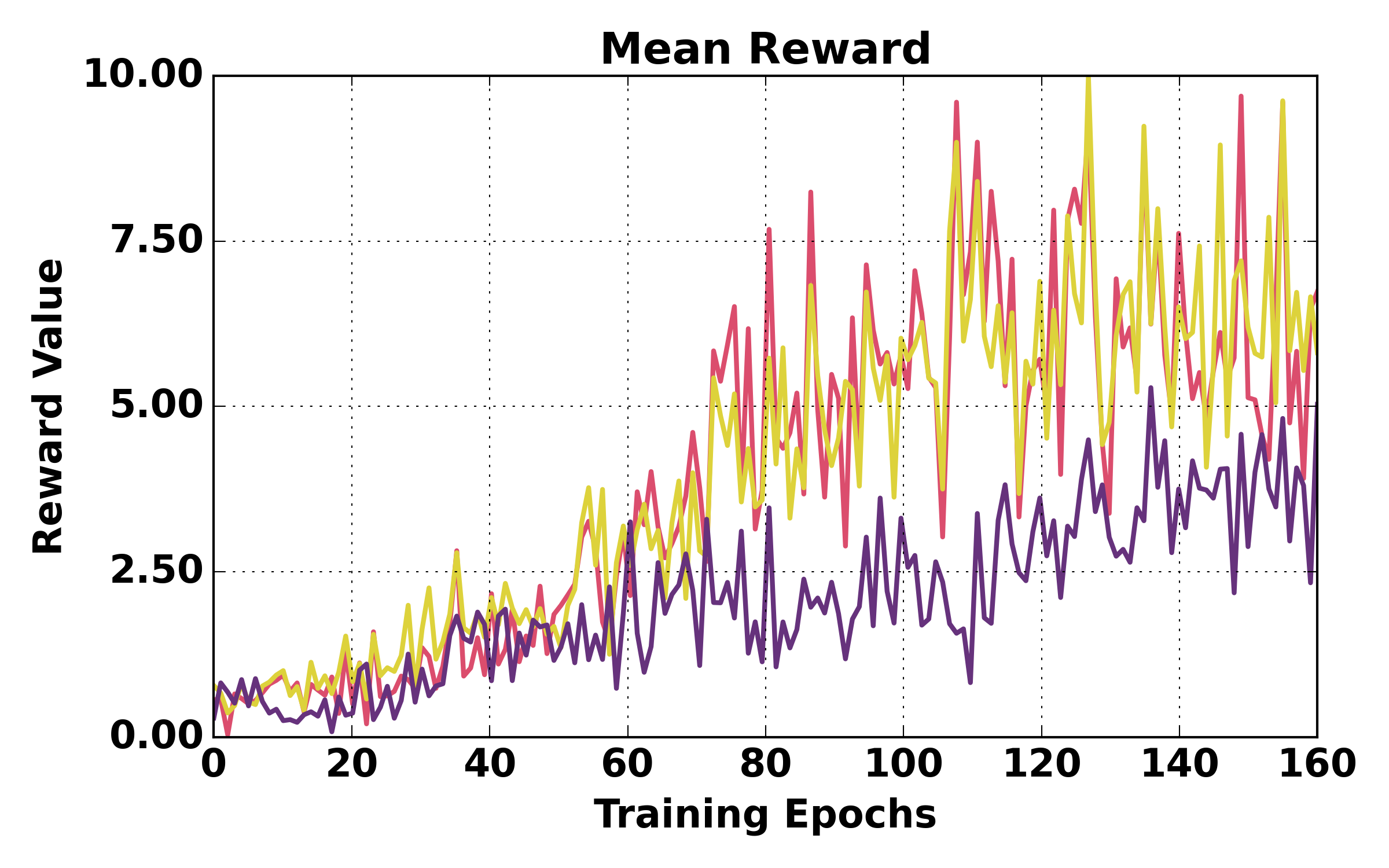
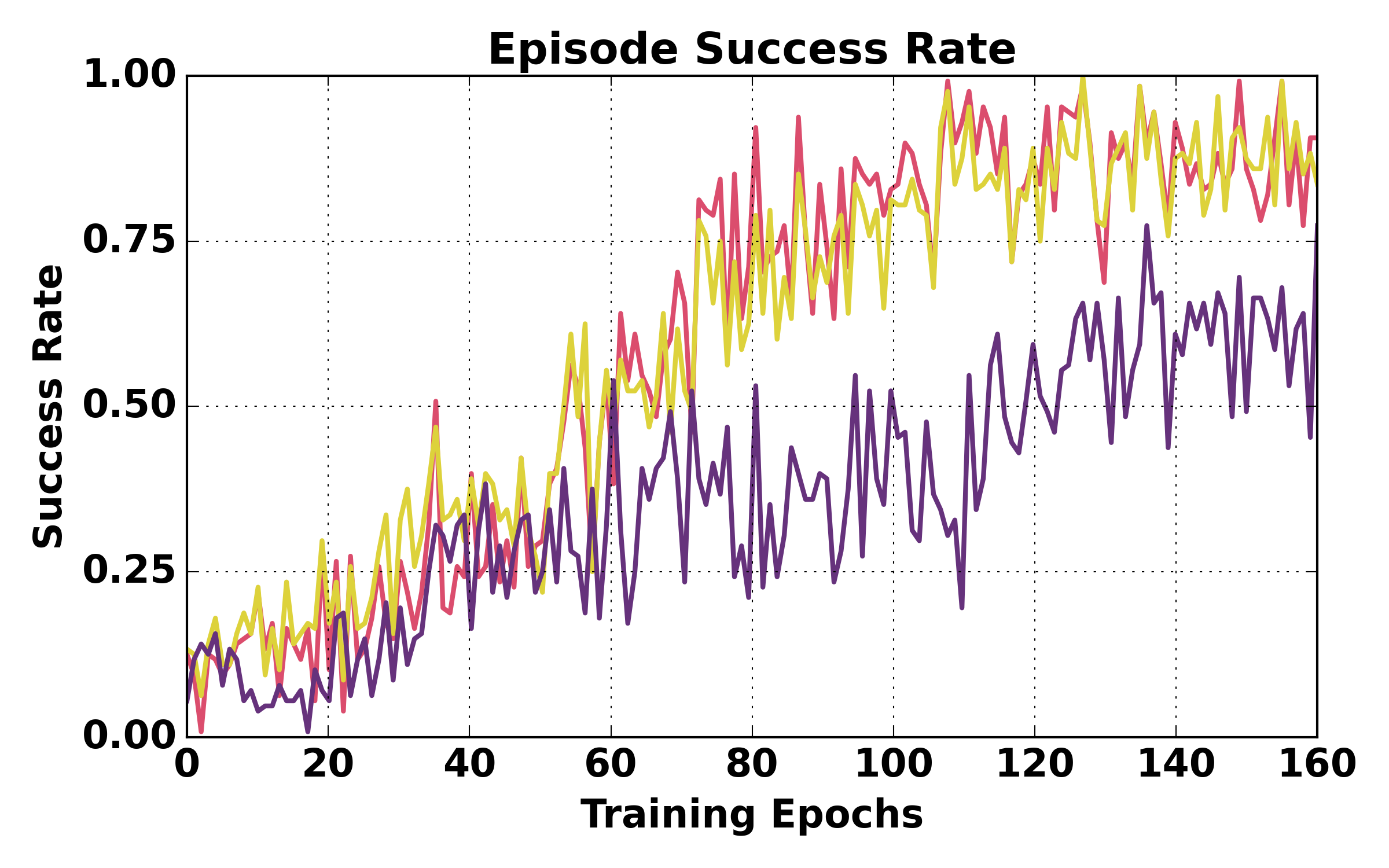
Figure 5: Training dynamics comparison (ALFWorld). HGPO exhibits smoother loss, higher mean reward, and better episode success rates over training relative to GiGPO and GRPO.
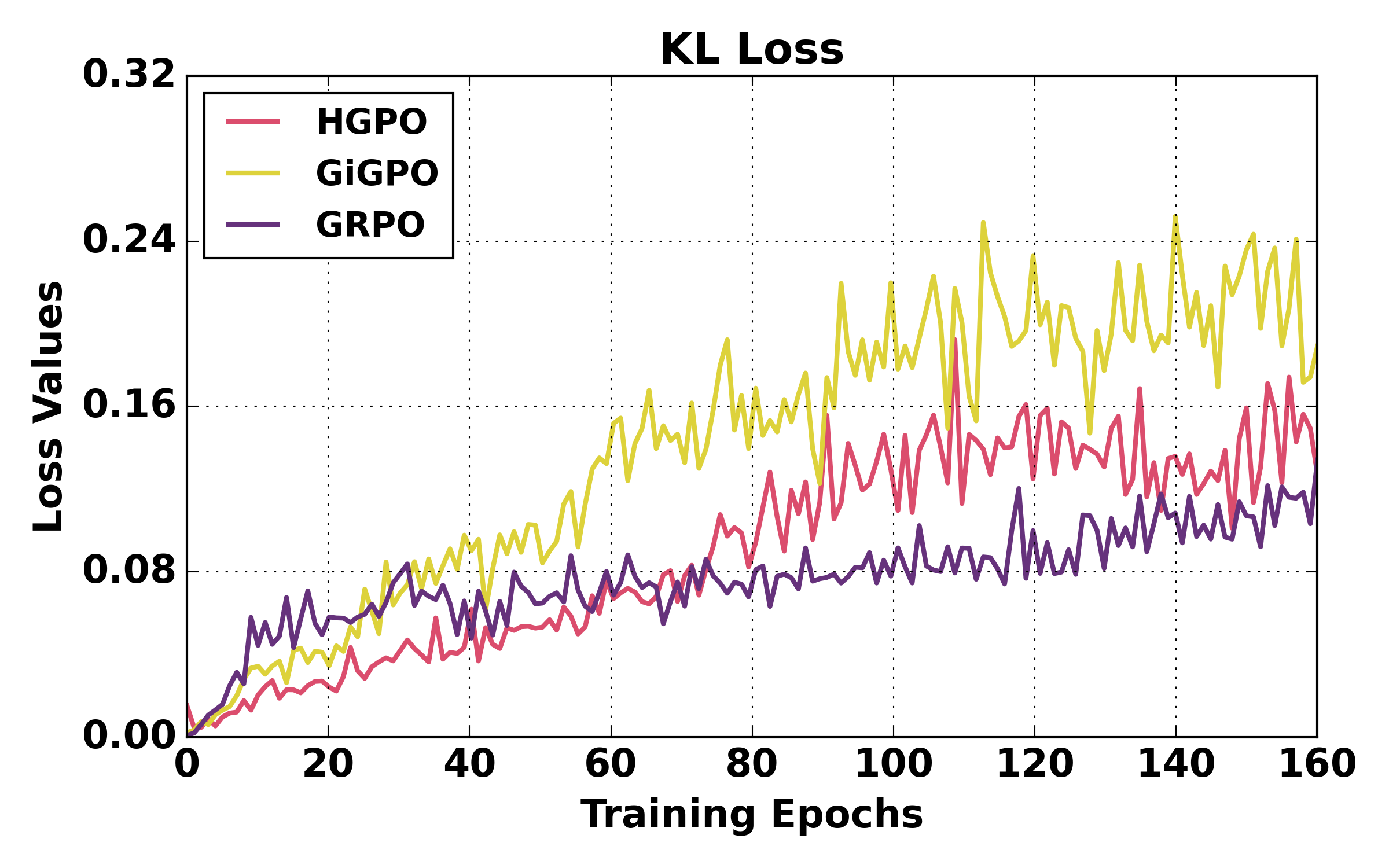
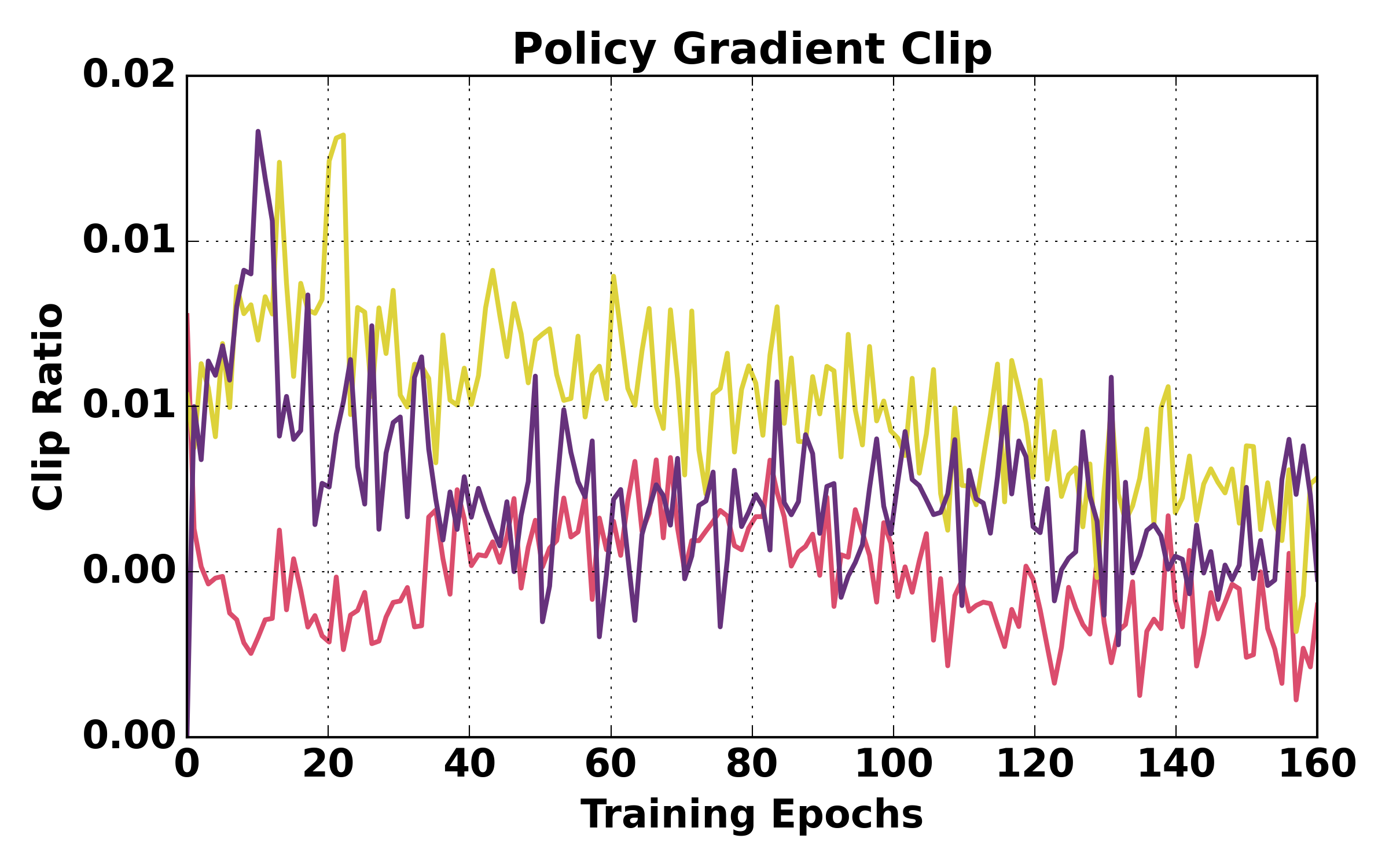
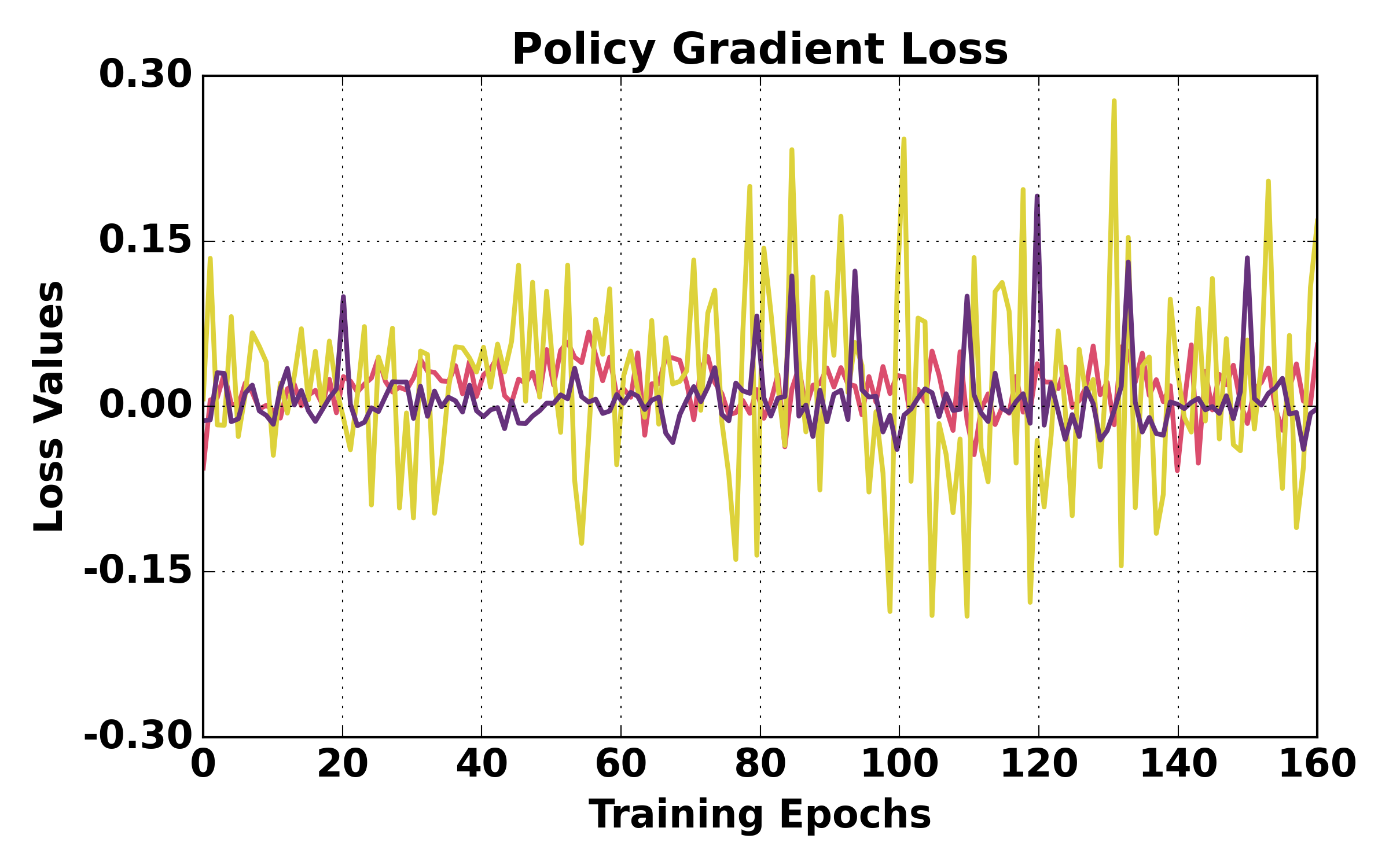
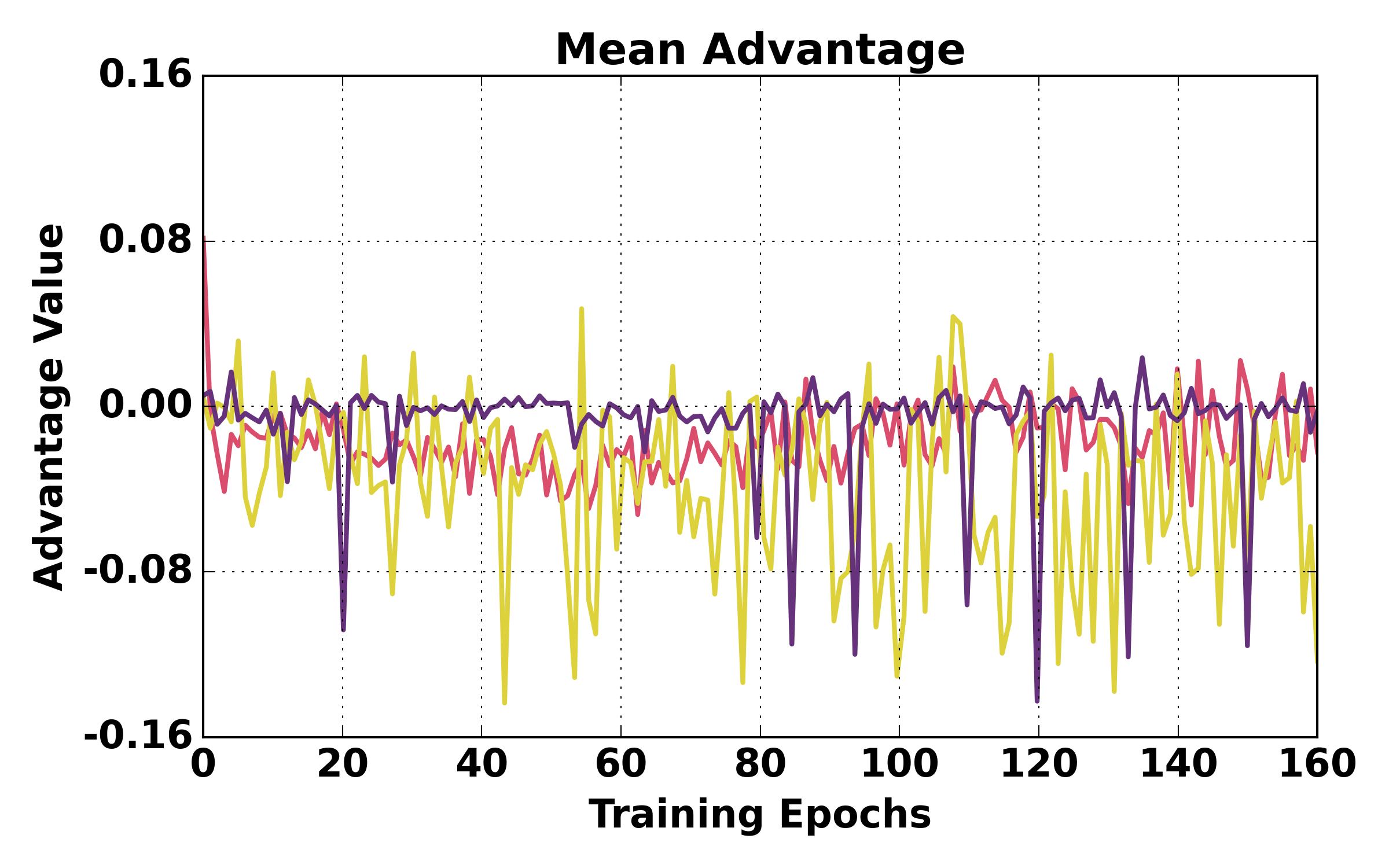
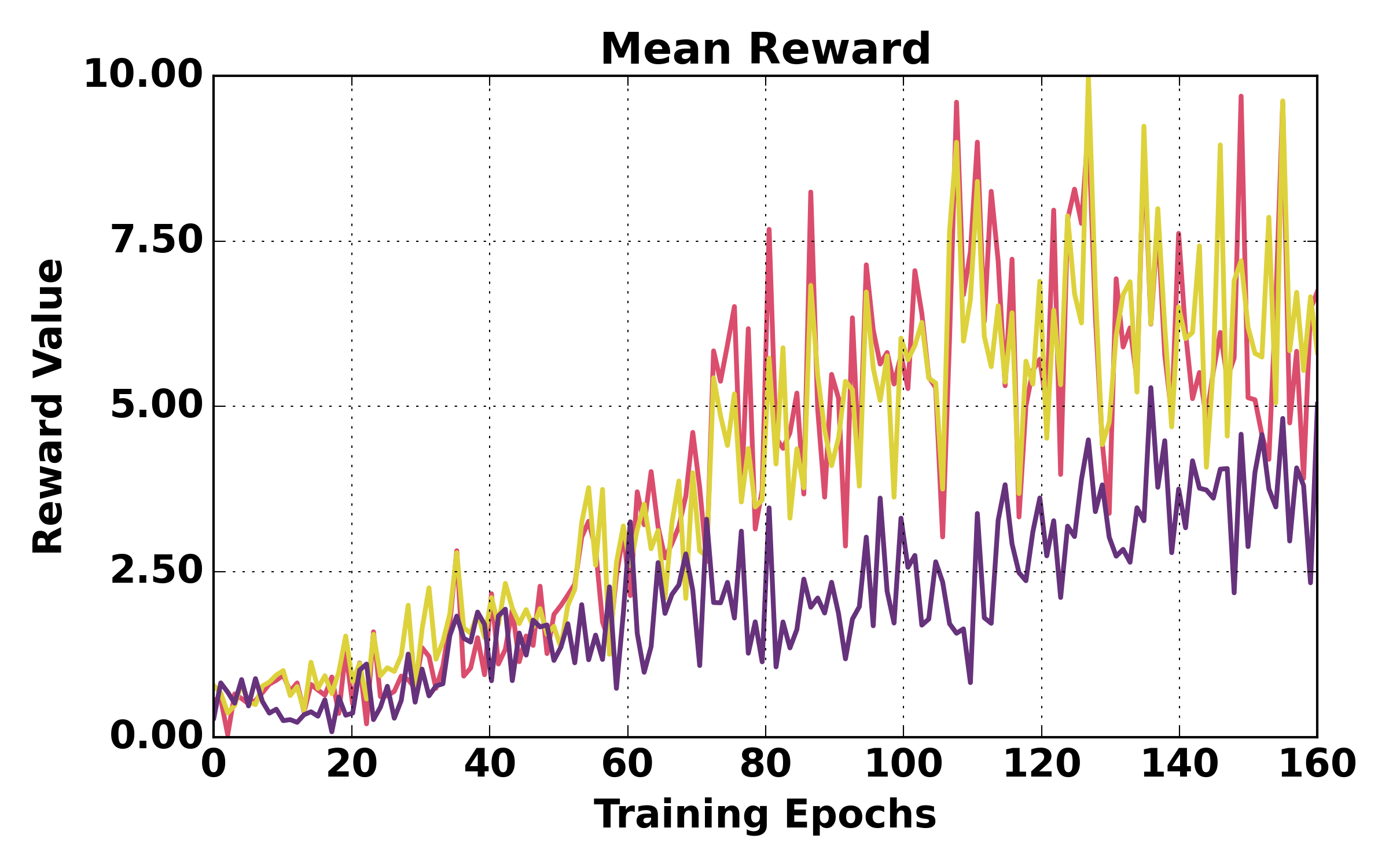
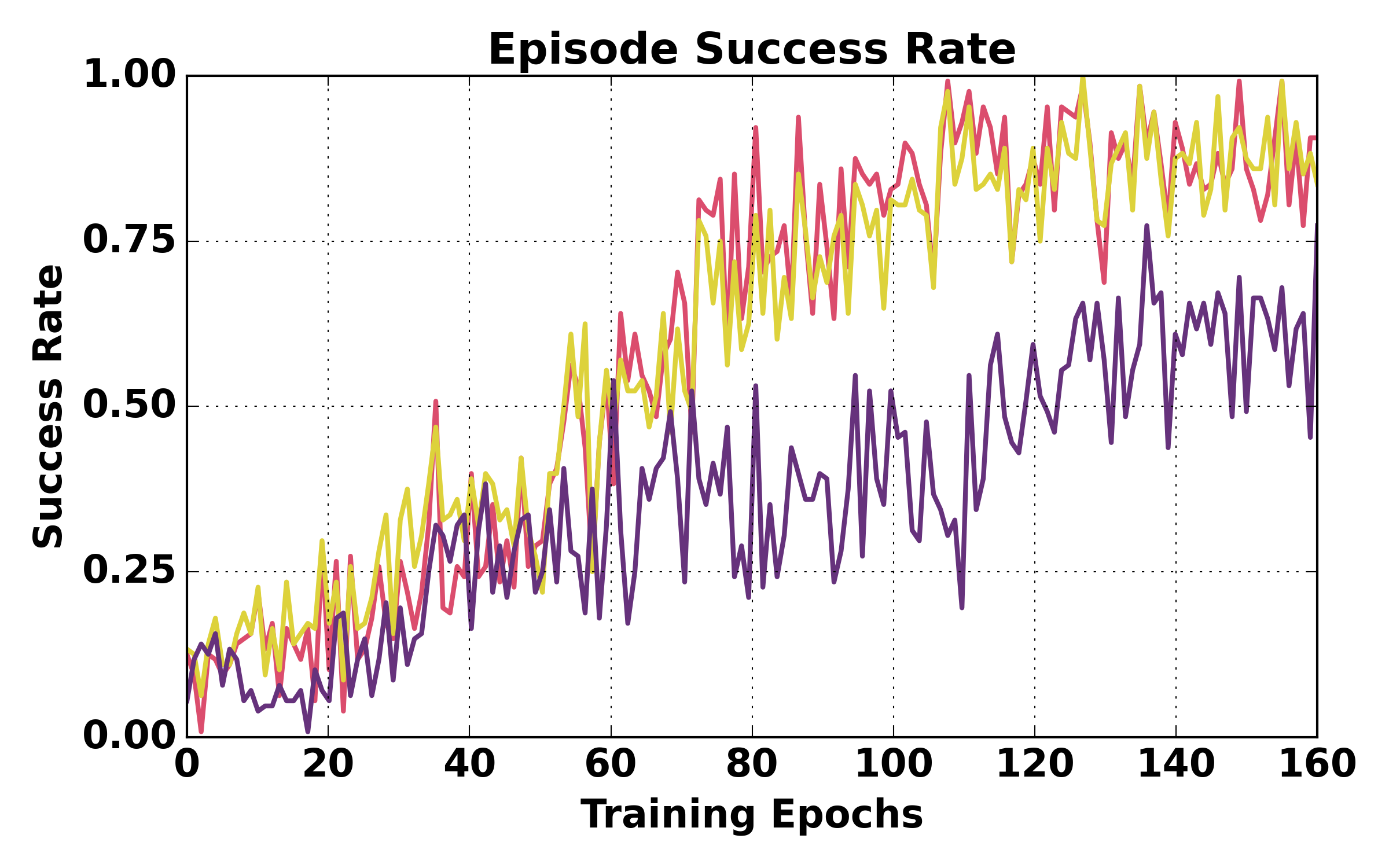
Figure 6: Training dynamics comparison (WebShop). HGPO achieves more stable optimization and higher success rates.
Analysis and Ablations
Extensive ablations confirm:
- Removing hierarchical grouping leads to systematic degradation in both in- and out-of-distribution success rates (up to 5.8% drop).
- Eliminating the adaptive weighting (α=0) is suboptimal for larger K, as over-emphasizing high-variance Oracle groups reduces performance.
- Training cost and peak memory remain nearly unchanged as HGPO operates fully offline.
Further, a parametric study of the weighting coefficient α shows optimality around $1$ for balancing the contribution of higher-level groups.
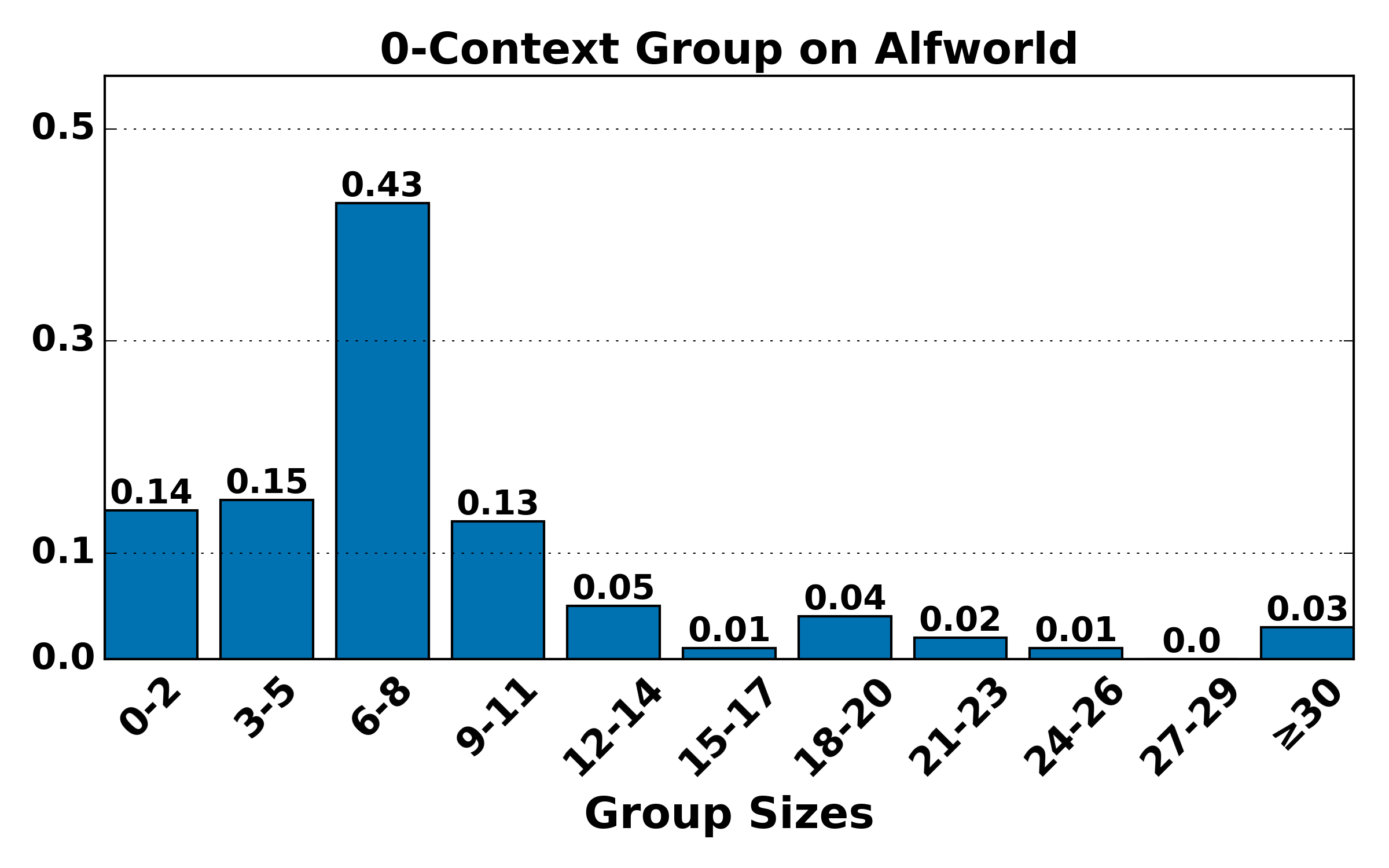
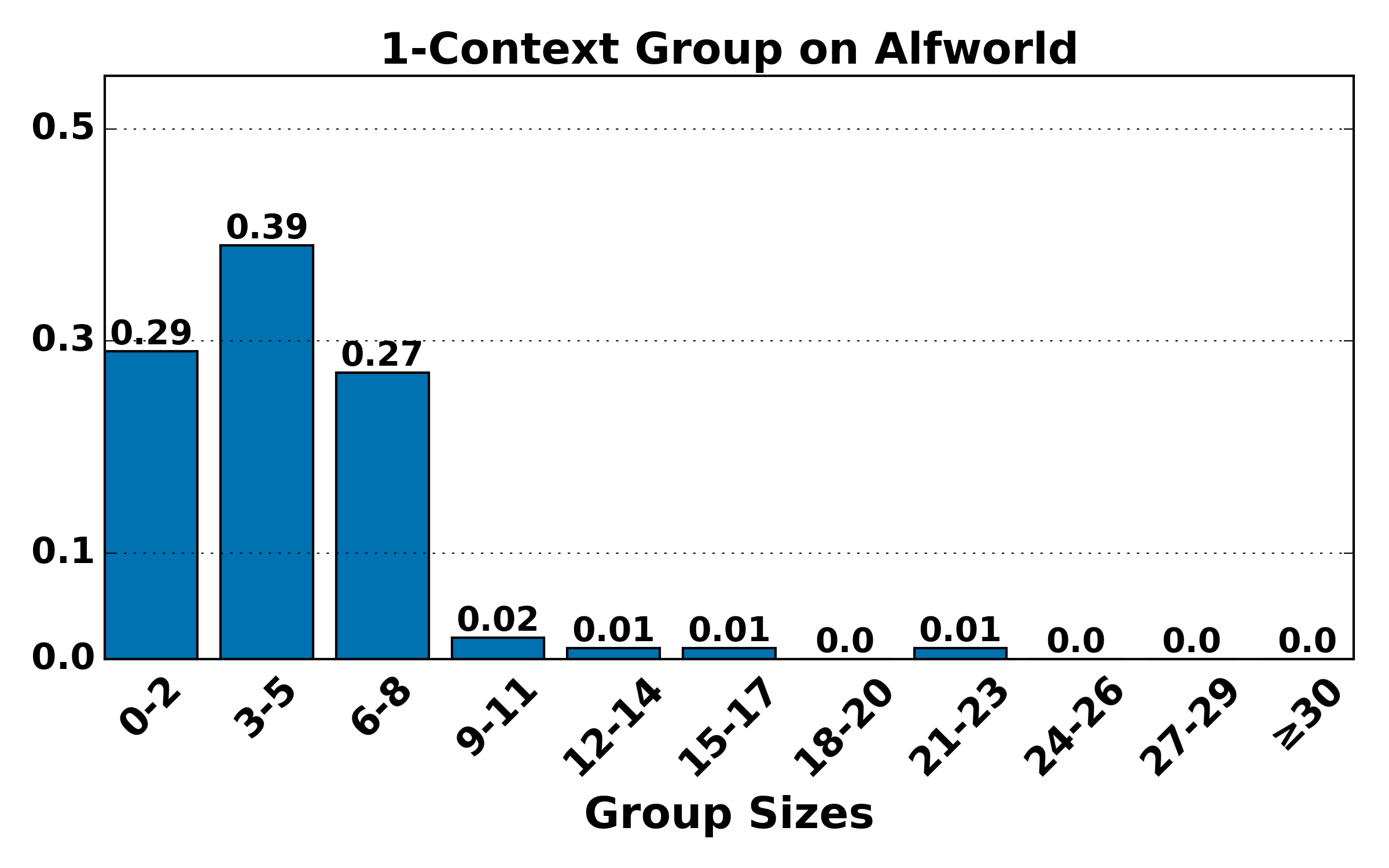
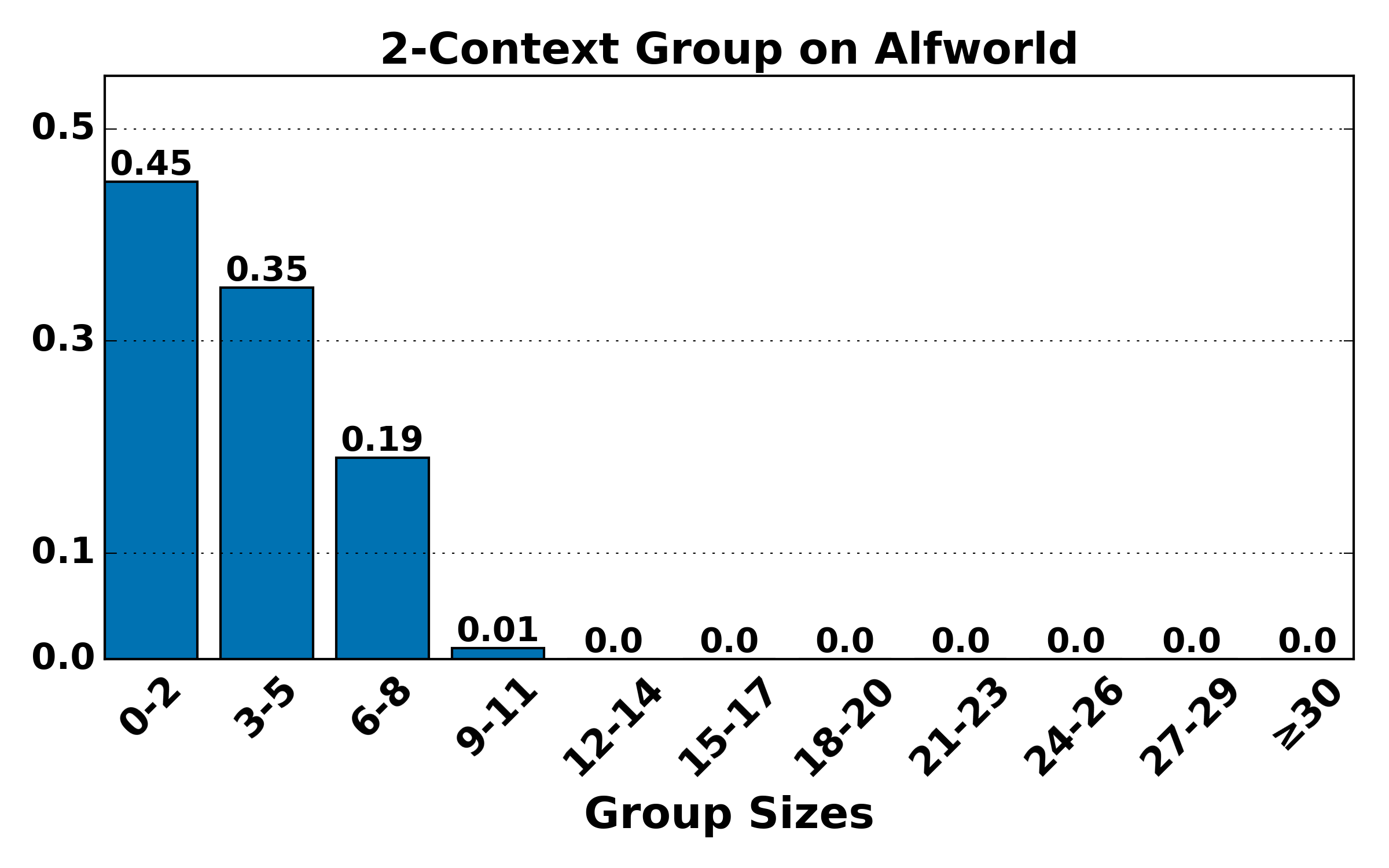
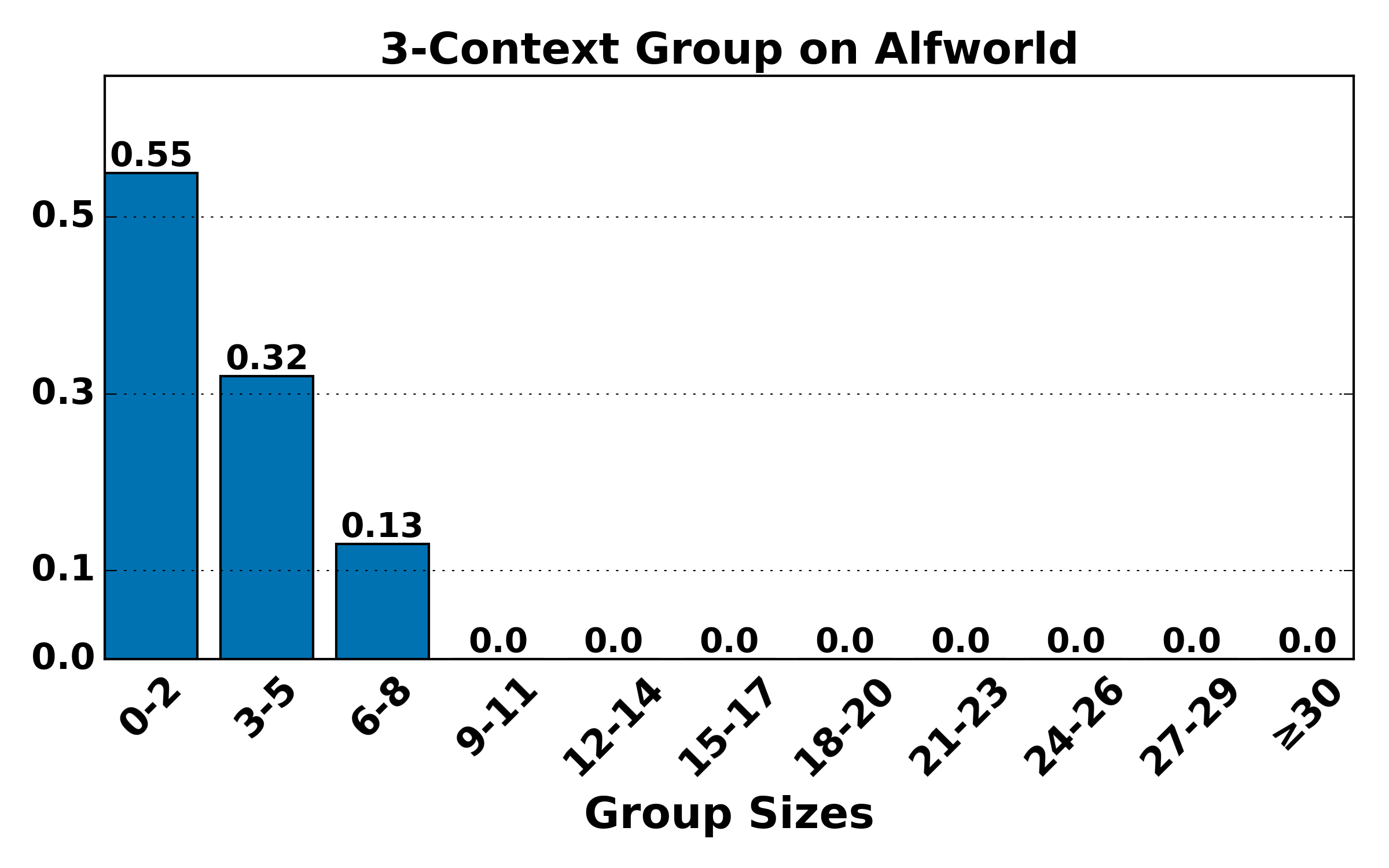
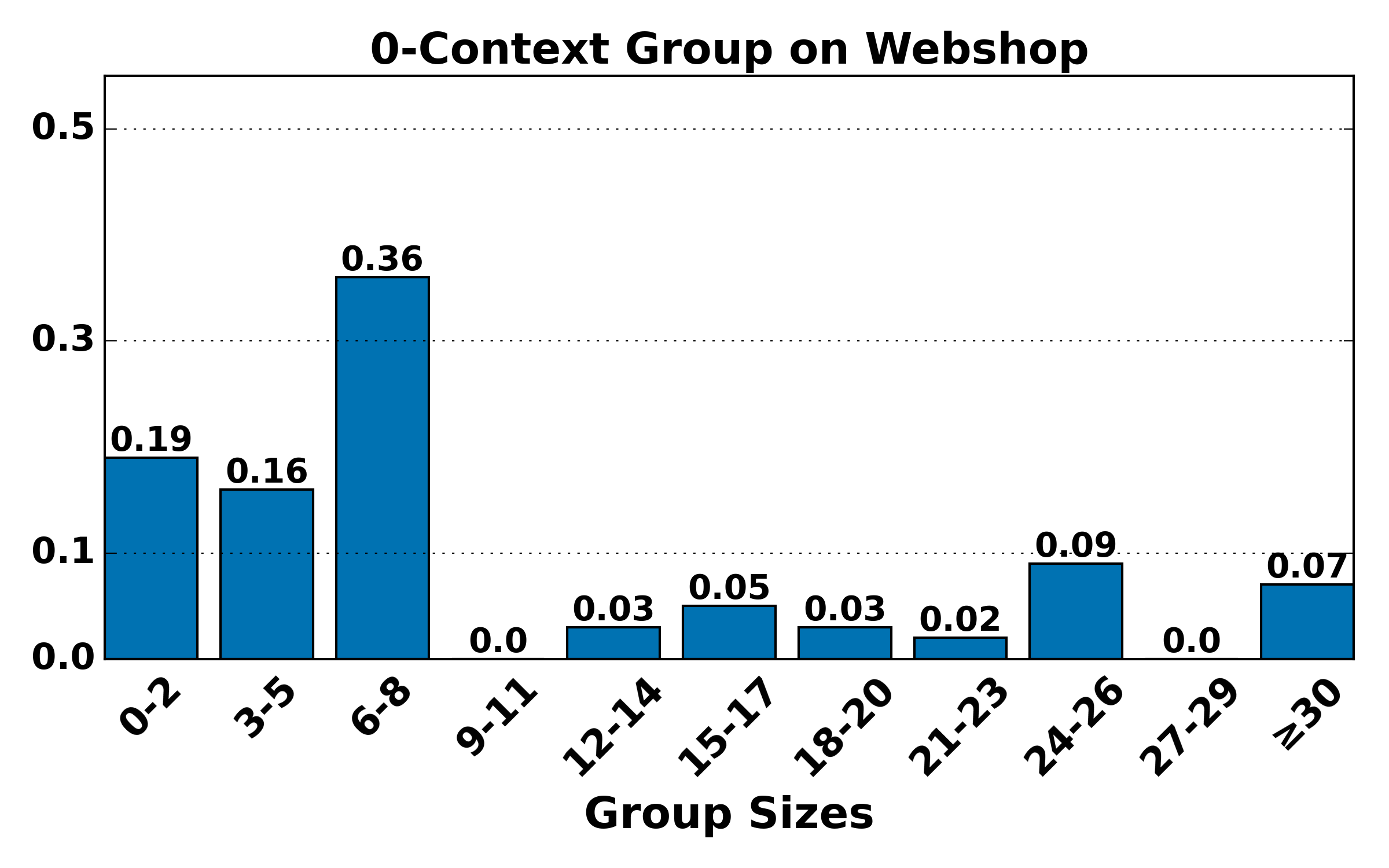
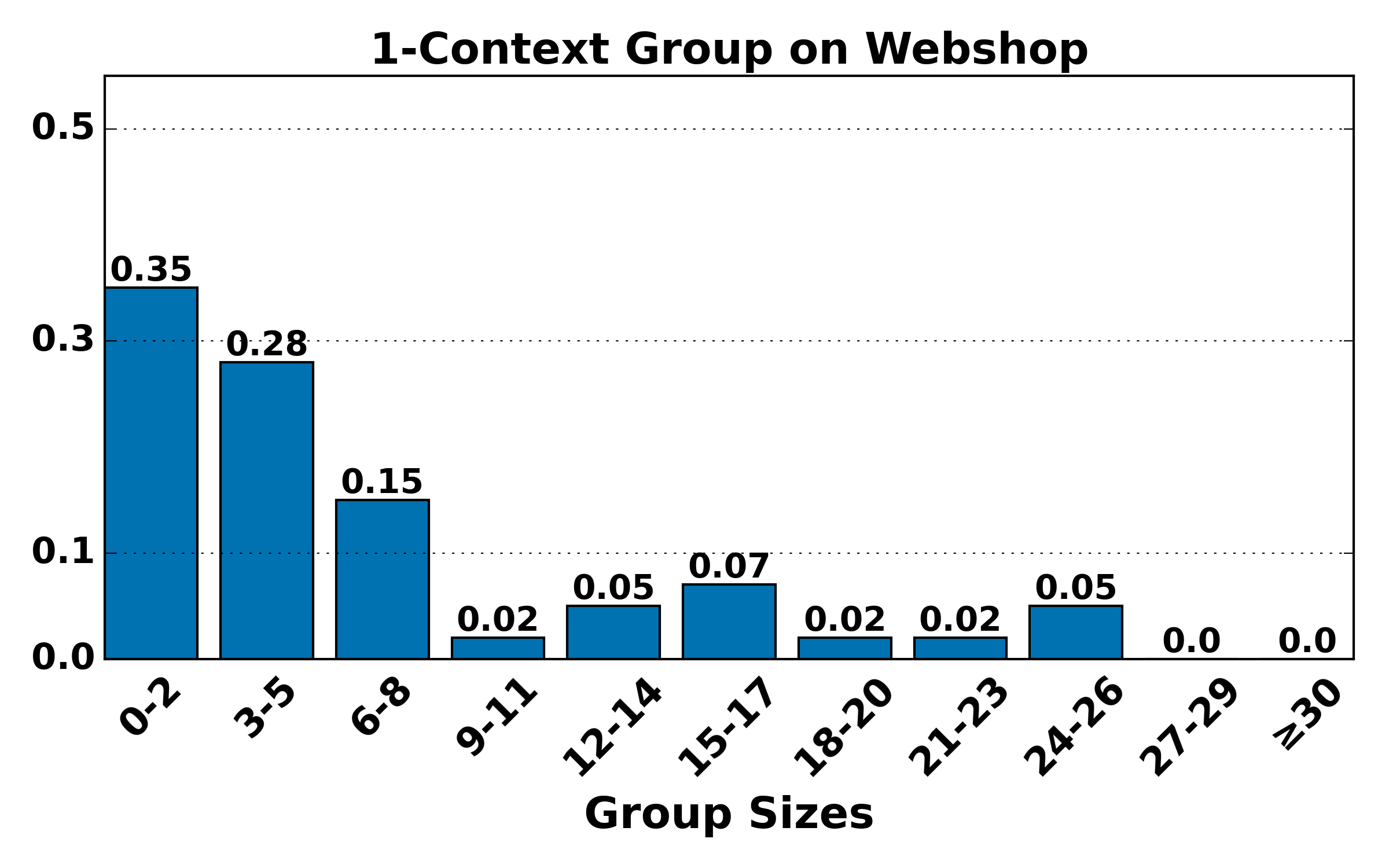
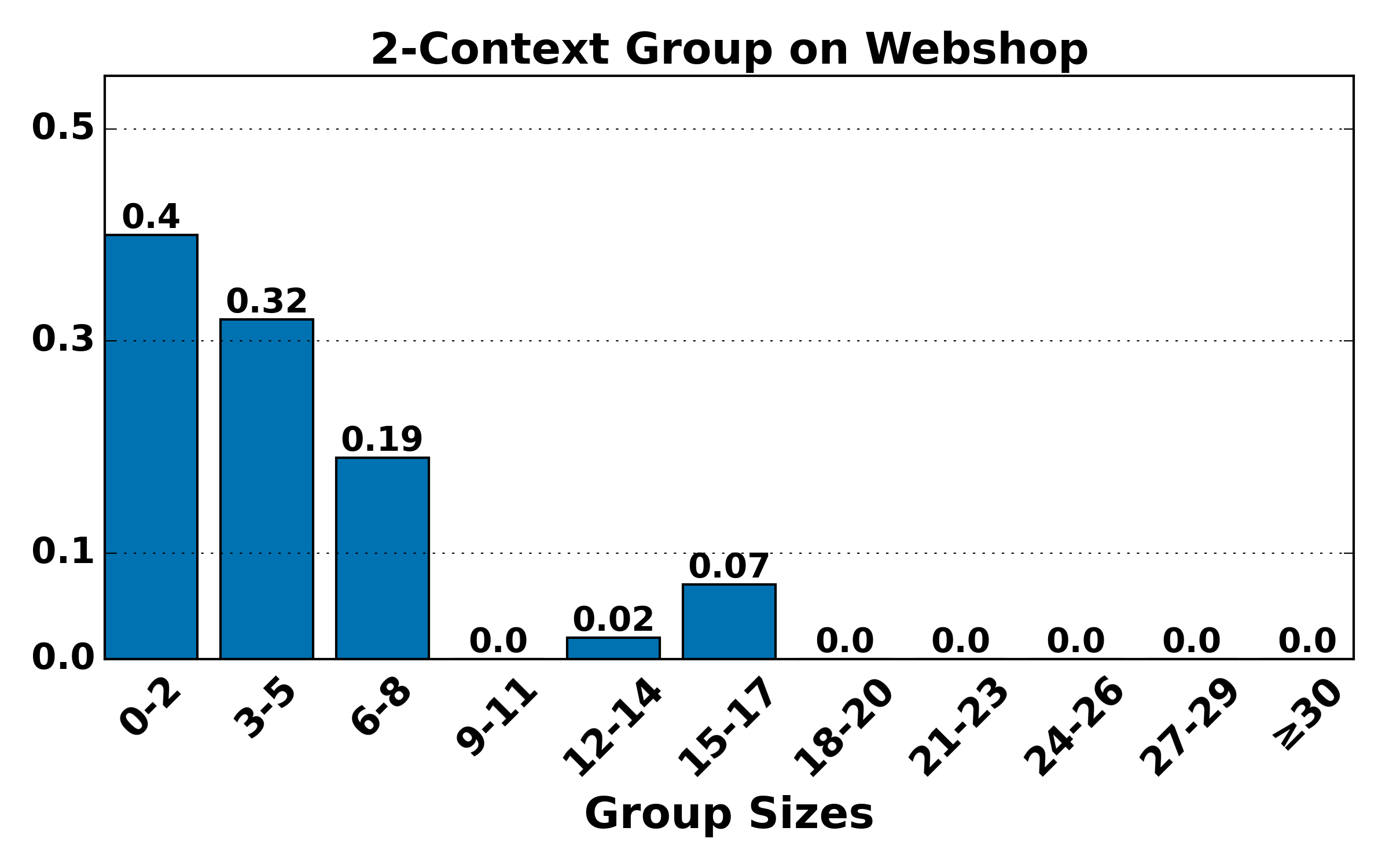
Figure 7: Hierarchical group size distributions (K=4) remain consistent with theoretical expectations: higher-order groups are smaller and rarer, validating the bias-variance trade-off underpinning HGPO.
Implications and Future Directions
HGPO sets a new benchmark for RL-based credit assignment in LLM-driven long-horizon tasks by tightly coupling the exploitation of historical context structure with adaptive estimation. The method removes the dependence on value networks and auxiliary models, enhancing reliability and transparency in training large agentic models. Practically, HGPO is robust to rollout artifacts arising from limited context lengths or weaker backbones, which is critical for scaling RL to real-world agentic environments with sparse rewards and high step counts.
Future research directions include:
- Extending HGPO to memory modules employing explicit summarization, where hierarchical groupings must be inferred via embedding similarity rather than strict step identities;
- Investigating fully Bayesian or uncertainty-aware aggregation weights for further variance reduction;
- Integrating HGPO with multitask or meta-RL regimes to enable robust few-shot out-of-distribution generalization.
Conclusion
Hierarchy-of-Groups Policy Optimization (HGPO) advances the state-of-the-art in RL for long-horizon, LLM-based agentic tasks by reconciling context alignment and group-based advantage estimation. Through context-aware hierarchical grouping and adaptive weighted aggregation, HGPO delivers superior empirical performance, theoretical rigor in estimator bias-variance, and computational efficiency, offering a principled solution to persistent credit assignment challenges in large-scale agent RL (2602.22817).