Supervised Dimensionality Reduction Revisited: Why LDA on Frozen CNN Features Deserves a Second Look
Published 5 Apr 2026 in cs.LG, cs.AI, and cs.CV | (2604.03928v1)
Abstract: Effective ride-hailing dispatch requires anticipating demand patterns that vary substantially across time-of-day, day-of-week, season, and special events. We propose a regime-calibrated approach that (i) segments historical trip data into demand regimes, (ii) matches the current operating period to the most similar historical analogues via a six-metric similarity ensemble (Kolmogorov-Smirnov, Wasserstein-1, feature distance, variance ratio, event pattern, temporal proximity), and (iii) uses the resulting calibrated demand prior to drive both an LP-based fleet repositioning policy and batch dispatch with Hungarian matching. In ablation, a distributional-only subset is strongest on mean wait, while the full ensemble is retained as a robustness-oriented default. Evaluated on 5.2 million NYC TLC trips across 8 diverse scenarios (winter/summer, weekday/weekend/holiday, morning/evening/night) with 5 random seeds each, our method reduces mean rider wait times by 31.1% (bootstrap 95% CI: [26.5, 36.6]%; Friedman chi-sq = 80.0, p = 4.25e-18; Cohen's d = 7.5-29.9 across scenarios). The improvement extends to the tail: P95 wait drops 37.6% and the Gini coefficient of wait times improves from 0.441 to 0.409 (7.3% relative). The two contributions compose multiplicatively and are independently validated: calibration provides 16.9% reduction; LP repositioning adds a further 15.5%. The approach requires no training, is deterministic and explainable, generalizes to Chicago (23.3% wait reduction via NYC-built regime library), and is robust across fleet sizes (32-47% improvement for 0.5-2x fleet scaling). We provide comprehensive ablation studies, formal statistical tests, and routing-fidelity validation with OSRM.
The paper demonstrates that applying LDA on frozen CNN features consistently improves top-1 accuracy by up to 4.58% across multiple backbones.
The paper shows that LDA reduces feature dimensionality by 61%–95%, leading to a 2–5× reduction in classifier training time.
The paper validates that standard LDA outperforms more complex alternatives, confirming the optimal projection cap of d = C–1 for label-informed feature selection.
Revisiting Supervised Dimensionality Reduction: LDA on Frozen CNN Features
Introduction
This work systematically investigates the effect of supervised dimensionality reduction—specifically, Linear Discriminant Analysis (LDA)—applied post-hoc to frozen CNN features for image classification. Contrary to the current de facto pipeline, which feeds high-dimensional penultimate layer features directly into a linear classifier, the study addresses whether projecting these features into a lower-dimensional, label-informed subspace improves downstream classification accuracy. Broad experimental coverage spans four backbones (ResNet-18, ResNet-50, MobileNetV3-Small, EfficientNet-B0), two datasets (CIFAR-100, Tiny ImageNet), and ten dimensionality reduction procedures, including novel extensions.
Motivation and Problem Setting
Frozen-feature transfer learning has become standard for scenarios with limited labeled data or computational budget. However, the high-dimensional ImageNet-derived features are rarely interrogated for intrinsic, task-relevant dimensionality. Given that typical target tasks have orders of magnitude fewer classes than ImageNet, most axes in the frozen feature space encode variance not relevant to the class separation problem at hand. While principal component analysis (PCA) and other variance-based reductions are occasionally used, supervised projections exploiting label information are under-explored in the contemporary deep transfer pipeline.
The study formalizes the pipeline as a mapping
XfθRDWRdgPrediction,
evaluating variants of W: identity (full features), unsupervised PCA, classical and regularized LDA, Local Fisher Discriminant Analysis (LFDA), Neighbourhood Components Analysis (NCA), and two new variants—Residual Discriminant Augmentation (RDA) and Discriminant Subspace Boosting (DSB).
Empirical Results and Comparative Analysis
Consistent Performance Gains with LDA
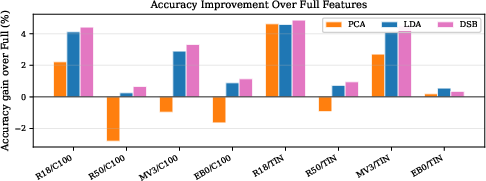
Across all 8 backbone–dataset configurations, LDA achieves superior or matched top-1 accuracy compared to the full-feature baseline, with dimensionality reduction between 61% and 95%. The improvement is both statistically significant and practically meaningful, ranging from +0.26% to +4.58% (paired t-test, p<0.001). LDA consistently outperforms PCA and more complex alternatives in 7 of 8 settings, with the largest gains on compact backbones such as MobileNetV3-Small.
Figure 1: LDA delivers accuracy improvements over full features across all backbones, with the most pronounced effects for smaller models.
Supervised methods (LDA and its extensions) outperform unsupervised PCA due to targeted removal of task-irrelevant variance—an advantage more salient as the ratio D/(C−1) increases. LDA's benefit emerges robustly in regimes where the number of output classes is much less than the feature dimension, and when sufficient training data allow stable estimation of scatter matrices.
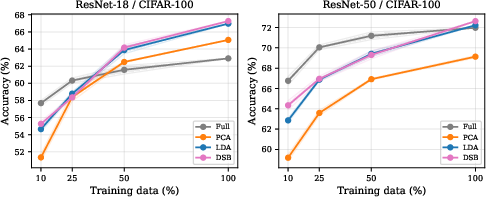
Training Data Efficiency and Crossover Regimes
LDA's advantage manifests once training sets reach moderate sizes (typically >50 samples per class). At lower sample counts, full features (combined with strong regularization) can outperform LDA due to instability in estimating within-class scatter.
Figure 2: As training set size increases, LDA overtakes full features in test accuracy, particularly beyond 25-50% of the available data.
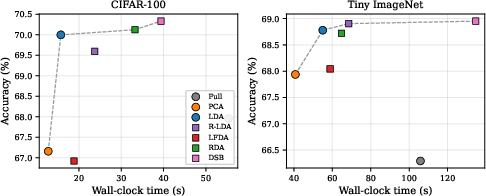
Computational Efficiency and Pareto Frontier
Owing to reduced dimensionality, LDA confers not only accuracy advantages but also reduced wall-clock classifier training time—as much as 2–5× faster than the full-feature pipeline. The method lies near or on the accuracy–efficiency Pareto frontier for all tested scenarios.
Figure 3: LDA dominates full features in both speed and accuracy; no pipeline using the unreduced feature set is ever Pareto-optimal.
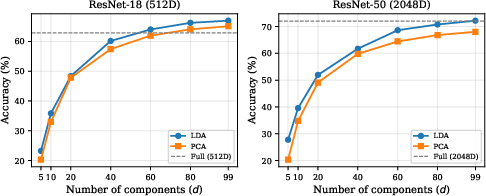
Effect of Number of Components
Accuracy for both LDA and PCA increases monotonically with d, but LDA systematically achieves a higher performance ceiling. The conventional cap of d=C−1 is empirically validated as optimal.
Figure 4: LDA and PCA test accuracy as a function of retained dimensions, with LDA leading across the spectrum and saturating at C−1.
Benchmarking Against Advanced Alternatives
Plain LDA achieves the best accuracy-to-cost ratio compared to Regularized LDA, LFDA, NCA, and other methods. More complex academic variants and metric learning approaches (e.g., NCA) deliver neither accuracy benefits nor computational savings over LDA in the frozen-feature regime. Two new lightweight extensions—Residual Discriminant Augmentation (RDA) and Discriminant Subspace Boosting (DSB)—offer marginal accuracy gains (0.2–0.4%) at a significant increase in computational time, rendering standard LDA preferable for most cases.
Statistical Validity
All major claims are rigorously backed by statistical testing over randomized seeds. LDA's advantage is highly significant in nearly all scenarios; variance in classifier performance is near zero for most methods thanks to deterministic projections and convex classifier optimization.
Mechanistic Interpretation
The improvements conferred by LDA are attributed to:
Implicit regularization, preventing overfitting in the downstream classifier by focusing on a lower-dimensional, label-informative projection;
Removal of off-task variance, where the bulk of high-variance directions from ImageNet pretraining are not relevant for the target classification task;
Improved conditioning, facilitating efficient solver convergence and yielding more stable feature statistics.
The observed magnitude of gains correlates with the excess dimensionality of the backbone relative to the complexity of the target task.
Guidelines for Practice
The study offers actionable guidelines for researchers and practitioners in transfer learning:
Use LDA in preference to full features when data are sufficient (≈50 samples/class or more), and set output dimension W0.
Avoid two-stage PCA+LDA, LFDA, and NCA, as they do not improve over or are inefficient compared to plain LDA.
Consider variant extensions (DSB, RDA) only if extreme accuracy optimization justifies the computational cost.
For settings with very few samples per class, use full features due to instability in LDA’s estimates.
Always standardize features post-projection for stable classifier training.
Broader Implications and Future Directions
The findings prompt a reassessment of the high-dimensional transfer learning pipeline. The underuse of supervised dimensionality reduction results in wasted computational cost and missed accuracy gains. The results pose important implications for resource-constrained inference (e.g., edge deployments) and automated model compression, where feature selection matters.
Open theoretical questions remain regarding LDA’s scalability to ultra-large class counts, its interaction with fine-tuned rather than frozen features, and the generality of findings to non-linear classifiers. Additional avenues include integrating differentiable LDA layers into deep pipelines and extending the study to continual and few-shot learning settings.
Conclusion
Comprehensive empirical evidence demonstrates that the classical LDA projection step—long neglected in the deep learning era—should be reinstated as a standard element of frozen-feature classification pipelines. LDA provides a robust, efficient, statistically validated way to simultaneously enhance accuracy and reduce classifier complexity in transfer learning setups.
Reference: "Supervised Dimensionality Reduction Revisited: Why LDA on Frozen CNN Features Deserves a Second Look" (2604.03928)