- The paper reveals that a higher cosine similarity in latent alignment is counterintuitively linked to lower task accuracy.
- The PRISM diagnostic framework uncovers that perturbing latents minimally affects accuracy, suggesting that supervision alters shared parameters rather than explicit latents.
- Empirical results across multiple benchmarks indicate that auxiliary losses reshape global model behavior, challenging the effectiveness of conventional latent-target similarity metrics.
Cosine Misleads: Diagnostic Limitations of Latent Supervision in Vision-LLMs
Introduction and Motivation
Latent Visual Reasoning (LVR) structures Vision-LLMs (VLMs) by inserting continuous latent tokens between visual perception and autoregressive language generation, typically supervising these latents to align with ground-truth visual representations using Mean Squared Error (MSE) or cosine similarity. The prevailing assumption is that improved latent-target alignment, as measured by cosine or MSE, enhances overall model accuracy. This work systematically interrogates that assumption by evaluating five LVR variants differing in their supervision and latent manipulation strategies, revealing a striking negative correlation between cosine similarity and task accuracy. The authors introduce PRISM, a suite of inference-time diagnostics, to directly assess the functional contribution of LVR latents, exposing a fundamental disconnect between the optimization signal and its intended mechanistic purpose.
Experimental Matrix and Empirical Findings
A matrix of five LVR variants was constructed:
- LVR Baseline: MSE-supervised latent reconstruction.
- Progressive LVR (P-LVR-2/3): Two/three-stage scaffolding aligning latents at progressively more detailed targets.
- D-LVR: Switches off reconstruction midway to isolate cross-entropy effects.
- N-LVR: Adds noise regularization to latent supervision, inducing information-bottleneck (IB) style smoothness.
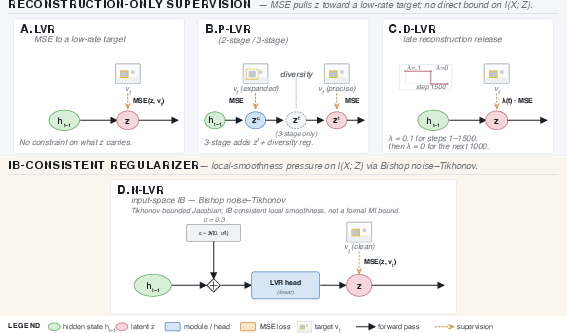
Figure 1: The five-variant LVR matrix, contrasting reconstruction-only, progressive scaffolding, and IB-motivated regularization.
Surprisingly, cosine alignment between LVR latents and their targets showed r=−0.94 correlation with task accuracy on V∗Bench. Progressive-scaffolding variants achieved up to 40% higher cosine but exhibited a 13-point drop in accuracy. The N-LVR variant, despite nearly identical cosine values to the baseline, reliably outperformed or behaved fundamentally differently under latent perturbation.
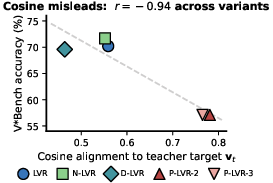
Figure 2: Cosine alignment is negatively correlated with V∗Bench accuracy across all LVR variants.
These results were replicated on additional benchmarks (MMVP, BLINK), ruling out dataset- or architecture-specific artifacts. The results directly contradict the common practice of using cosine or MSE-based alignment both as training loss and evaluation metric.
Diagnostic Framework: PRISM
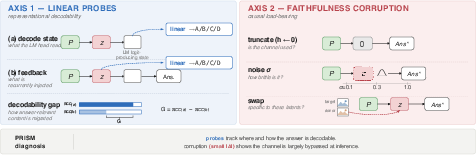
The PRISM diagnostic consists of two orthogonal axes:
Latent Bypass Phenomenon
Corruption tests reveal that all variants' latents are functionally bypassed in the forward pass: perturbing or removing latents shifts accuracy by at most four points, and in some cases improves performance (e.g., P-LVR-3, where zeroing latents increased accuracy). A positive delta under swap or noise indicates the latent is not just unused but may actively interfere.
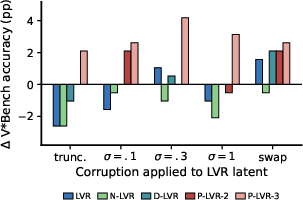
Figure 4: Benchmark accuracy change under different latent corruptions, demonstrating widespread bypass.
Despite differing in training signals and latent construction, variants diverge primarily through gradients flowing into the shared VLM parameters, not through differences in latent content. The probe analysis localizes answer information downstream of the latent, not within it.
Answer Localization and Decodability Gap
Probing exposes a fundamental decoupling: the answer is almost perfectly decodable at the answer-decoding state, but usually not decodable at the latent-feedback variable. The magnitude of the gap (G) robustly predicts both benchmark accuracy and perturbation reliance. Specifically, higher probe accuracy at the answer state correlates with higher task accuracy (r=+0.98), and a larger decodability gap predicts higher sensitivity to latent corruption.
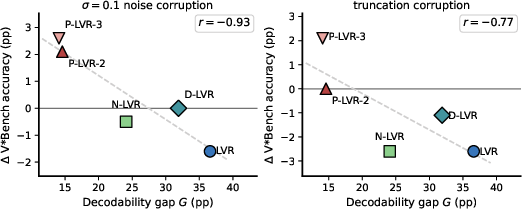
Figure 5: Decodability gap versus corruption response demonstrates that probe contrast tracks practical latent reliance.
This pattern suggests that the LVR objective reconfigures the VLM primarily through shared parameter adaptation, rather than by injecting content into the explicit latent variable. Cosine and MSE, as local latent metrics, are insensitive to this effect.
From the IB viewpoint, the LVR loss using cosine or MSE only enforces compression towards the teacher target (lowering I(X;Z)), while the cross-entropy loss applies pressure to preserve answer-relevant information (maximizing I(Z;Y)) across the computation graph. As a result, the network maximizes answer decodability wherever gradients permit, and nothing enforces that the supervised latent must actually be used at inference. This disconnect explains the empirical dissociation and cautions against using latent-target alignment as a proxy for functional representation.
Practical and Theoretical Implications
- Diagnostic Implications: Standard latent alignment metrics (cosine/MSE) are neither necessary nor sufficient indicators of model faithfulness to intermediate supervision. PRISM provides a protocol to verify whether a supervised latent is load-bearing or simply bypassed.
- Design Recommendations: Mechanisms supervising intermediate representations must be paired with causality or decodability checks; otherwise, auxiliary losses may reshape model behavior via shared parameters while leaving the supervised variable functionally obsolete.
- Generalizability: The decoupling uncovered here likely extends beyond vision-LLMs to any architecture employing auxiliary losses over intermediate representations (e.g., multitask, modular, or interpretable architectures).
Future Directions
Further work should extend this diagnostic methodology to:
- Larger and more diverse architectures and datasets to test robustness.
- Alternative scoring functions, including non-linear probes or causal interventions, to bound model reliance more tightly.
- Revisiting practices in multimodal and modular model design, including interpretability, to reconsider the role and measurement of supervision signals at latent or hidden variables.
Conclusion
This study rigorously demonstrates that standard alignment metrics, such as cosine similarity between LVR latents and their supervision targets, systematically misrepresent both the functional utilization and predictive accuracy of vision-LLMs. PRISM's two-axis diagnostic offers a direct and reliable alternative, revealing that auxiliary objectives act through global model adaptation rather than through the explicit latents they nominally constrain. Careful diagnostic scrutiny is essential when employing and evaluating auxiliary loss paradigms in contemporary deep learning architectures.