Lost in Embeddings: Information Loss in Vision-Language Models
Abstract: Vision--LLMs (VLMs) often process visual inputs through a pretrained vision encoder, followed by a projection into the LLM's embedding space via a connector component. While crucial for modality fusion, the potential information loss induced by this projection step and its direct impact on model capabilities remain understudied. We introduce two complementary approaches to examine and quantify this loss by analyzing the latent representation space. First, we evaluate semantic information preservation by analyzing changes in k-nearest neighbor relationships between image representations, before and after projection. Second, we directly measure information loss by reconstructing visual embeddings from the projected representation, localizing loss at an image patch level. Experiments reveal that connectors substantially distort the local geometry of visual representations, with k-nearest neighbors diverging by 40--60\% post-projection, correlating with degradation in retrieval performance. The patch-level embedding reconstruction provides interpretable insights for model behavior on visually grounded question-answering tasks, finding that areas of high information loss reliably predict instances where models struggle.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at a hidden but very important step inside vision–LLMs (VLMs)—AI systems that look at pictures and talk about them. Most VLMs take the picture, turn it into numbers (a “visual embedding”), then pass those numbers through a small bridge called a connector so a LLM can understand them. The big question: does this connector accidentally throw away useful visual information?
The main questions, in simple terms
- When a VLM turns image features into a form the LLM can read, how much detail is lost?
- Does this loss of detail make the model worse at tasks like finding similar images, writing captions, or answering questions about pictures?
- Can we see where in the image that information gets lost?
How the researchers studied it
They used two ideas to measure information loss. Think of an “embedding” as a compact digital summary of an image, like a special fingerprint made of numbers.
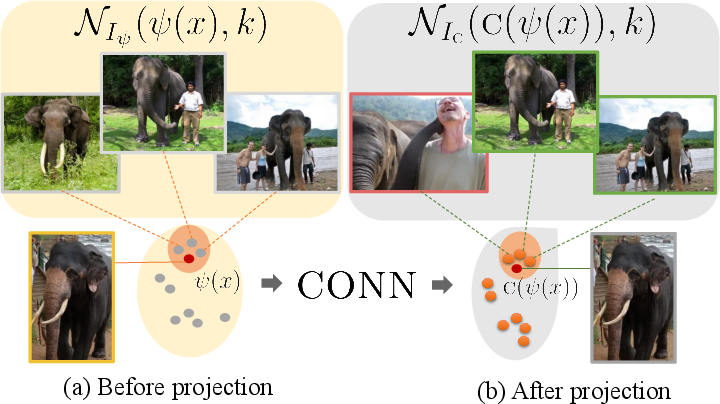
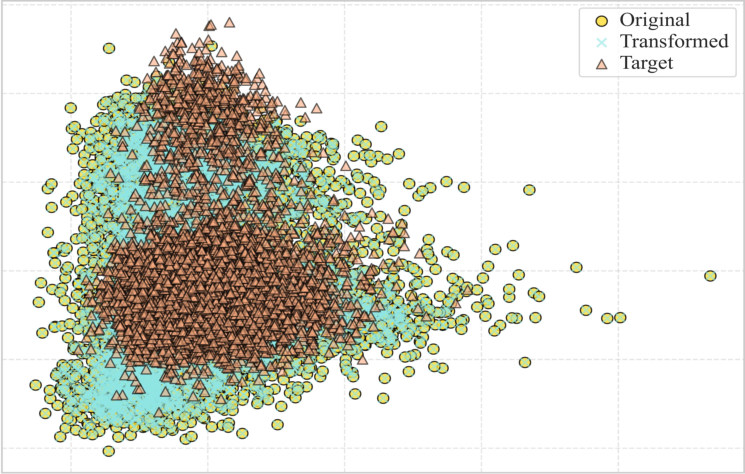
1) Neighborhood comparisons (k-nearest neighbors overlap)
Imagine every image lives on a big map, and each image has its “closest neighbors” (the most similar images). The team checked how an image’s nearest neighbors change:
- Before the connector (raw visual features).
- After the connector (features translated for the LLM).
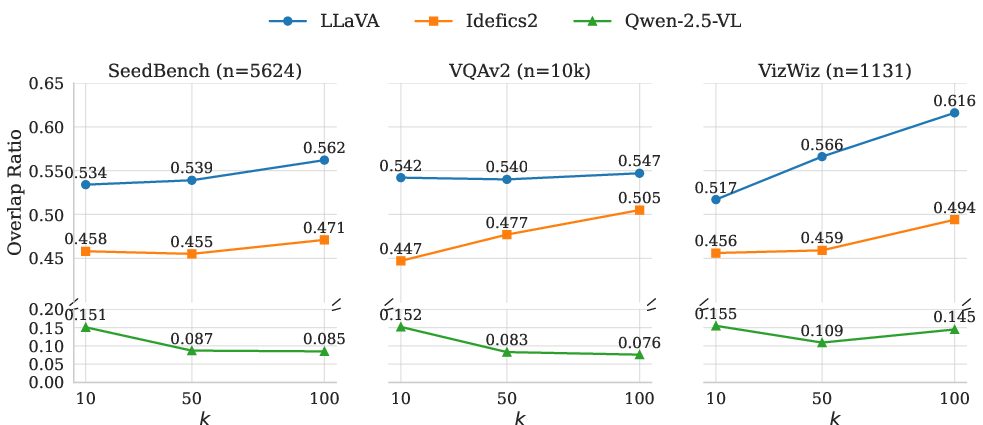
If the “neighborhood” changes a lot after the connector, it means the connector is reshaping the image information, possibly losing important structure. They measure this with a score called k-NN overlap ratio: the higher the overlap, the better the preservation.
Analogy: If your top 10 best friends suddenly become a mostly different group after translation, something changed in how you’re represented.
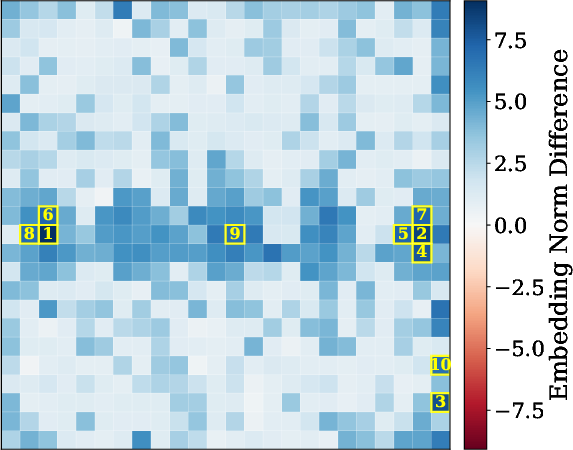
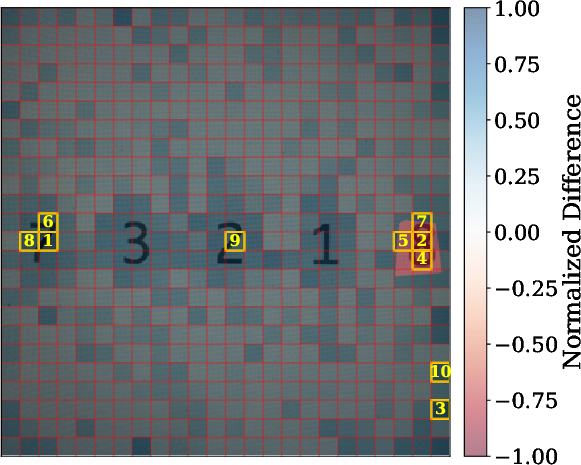
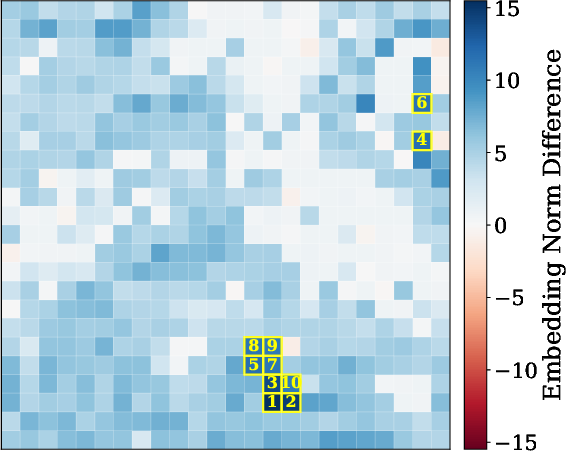
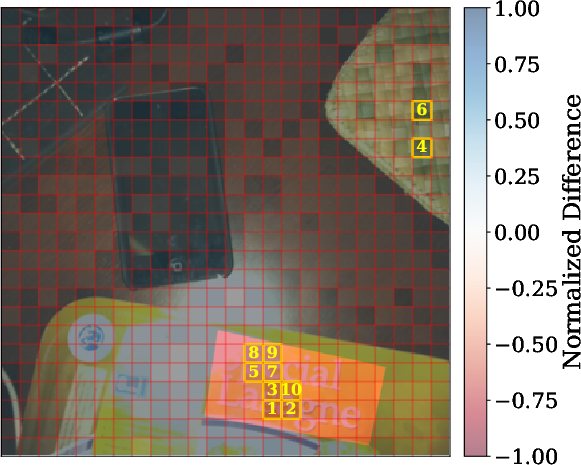
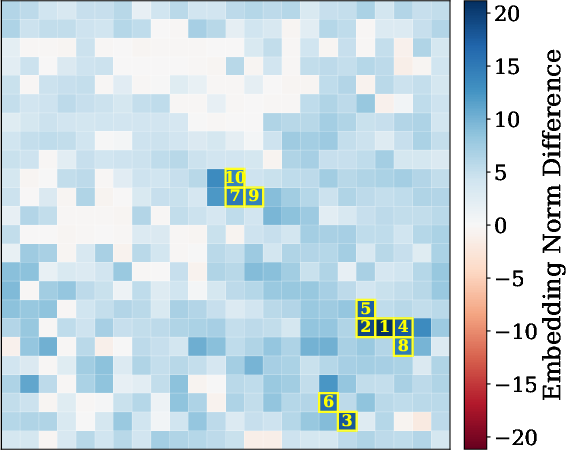
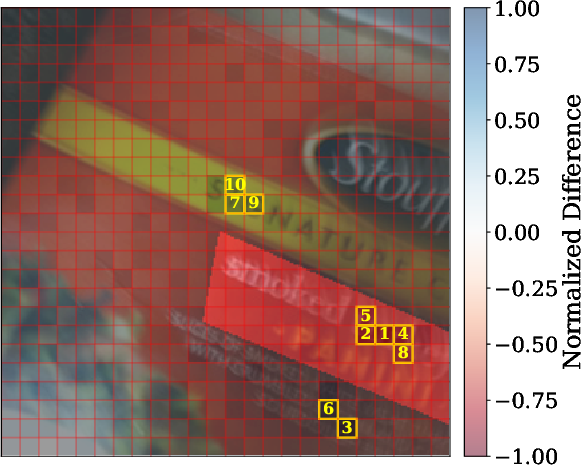
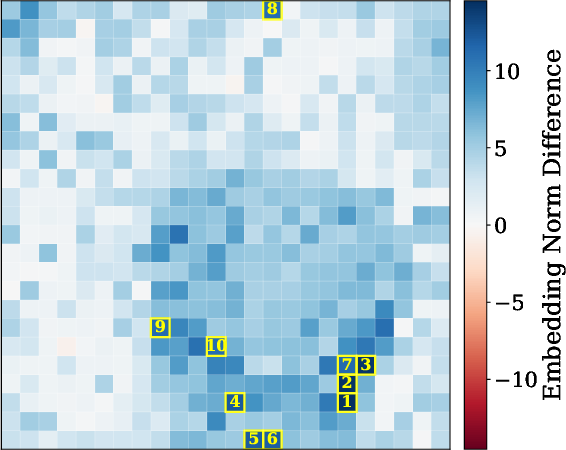
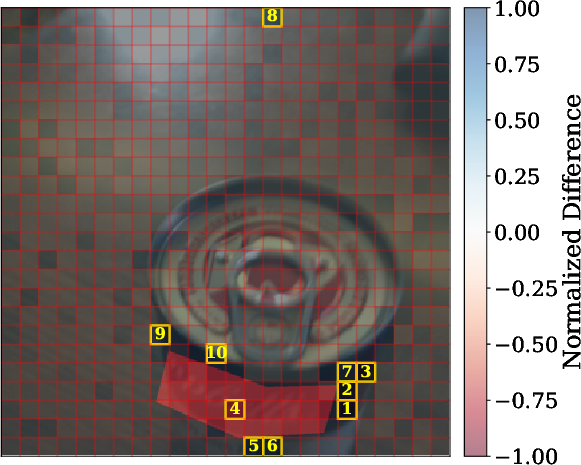
2) Patch-by-patch reconstruction (finding where details go missing)
Images are split into small tiles called patches. The researchers trained a separate model to reverse the connector: given the connector’s output, try to rebuild the original visual features, patch by patch. If some patches are hard to reconstruct, that suggests the connector discarded or scrambled details there.
Analogy: It’s like compressing a photo and then trying to uncompress it. Where the “uncompression” fails, you likely lost detail.
Models and tasks they tested
They tested three popular, open models with different connector designs:
- LLaVA (uses an MLP connector and keeps all patches).
- Idefics2 (uses a Perceiver-like connector that compresses patches).
- Qwen2.5-VL (merges patches; also continues training the vision part).
They evaluated on:
- Finding similar images (image retrieval).
- Writing captions (COCO, Flickr30k).
- Answering questions about images, including a dataset that marks which image regions matter for the answer (VizWiz Grounding VQA).
What they discovered and why it matters
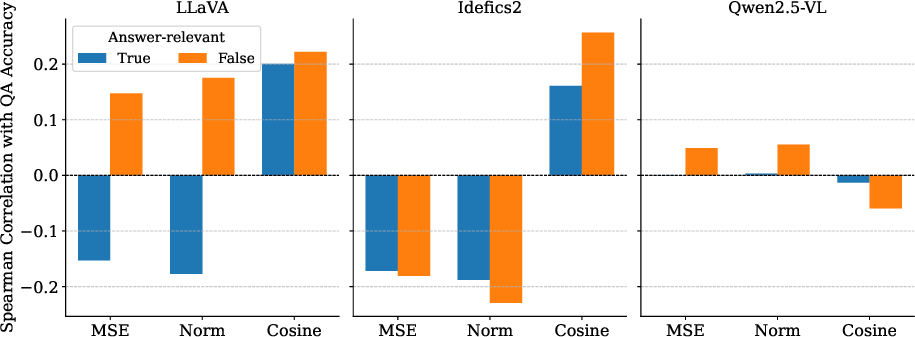
- Connectors change neighborhoods a lot. Across datasets and models, 40–60% of the nearest neighbors changed after the connector. This means the connector significantly reshapes how images are organized in the model’s “map.”
- This reshaping often hurts image retrieval. When neighborhoods change more, the model gets worse at finding the right similar images—there’s a measurable drop in retrieval scores for LLaVA and Idefics2.
- One exception: Qwen2.5-VL. Even though its neighbor overlap was low, its post-connector features sometimes worked better for retrieval. The authors suspect this is because Qwen2.5-VL keeps training its vision encoder and merges patches, so the “after” space is just a different, possibly more semantic space—not a simpler copy of the “before” space.
- Patch-level loss predicts performance. When reconstruction shows high loss in important patches (the regions that matter for the answer), models are more likely to get visual questions wrong. For captioning, images with higher reconstruction loss tend to get worse scores, especially for LLaVA and Idefics2.
- Visual explanations help diagnose failures. The patch-level maps highlight exactly where information is lost, making it clearer why a model missed a detail (for example, failing to read a specific number in the image).
What this means going forward
Connectors are not just simple translators—they can reshape and sometimes degrade visual information that the LLM relies on. This research suggests:
- Good connectors should keep meaningful image relationships intact or improve them in a thoughtful way.
- They should preserve the parts of the image that matter for the current task (like text regions when the question asks about a number).
- Training methods could include a “reconstruction loss” (a penalty when important details can’t be recovered) to encourage connectors to retain key information.
- Future designs might use smarter, dynamic projection layers that adapt to the image and the question, or better ways to select which visual features to pass on.
In short: the bridge between seeing and talking matters a lot. Measuring and reducing information loss at that bridge can make multimodal AI both smarter and more reliable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, framed to be directly actionable for future research.
- Metric validity and alternatives
- Validate whether low -NN overlap necessarily indicates harmful information loss, given cases like Qwen2.5-VL where overlap is low yet retrieval improves.
- Compare KNOR with manifold-preservation metrics (e.g., trustworthiness/continuity, rank-based Kendall’s tau, CCA-based similarity, Centered Kernel Alignment) and isotropy measures (e.g., IsoScore) to test robustness.
- Assess sensitivity of KNOR to choices of distance metric (cosine vs ), normalization, dataset size, class balance, and values beyond 10/50/100.
- Provide formal statistical testing and confidence intervals for KNOR across datasets and models, not only correlations on a per-sample basis.
- Causality vs correlation
- Establish causal links between connector-induced changes and downstream errors via controlled interventions (e.g., patch-level feature masking, adversarial modifications, connector regularization during fine-tuning).
- Run ablations where only the connector is altered (keeping vision encoder/LLM frozen) vs end-to-end co-training to isolate the source of observed effects.
- Scope of models and architectures
- Extend analysis beyond three connector-based VLMs to cover more connector variants (e.g., InternVL/InternVL2, LLaVA variants, LION, Gemini-like systems) and different compression ratios.
- Include cross-attention fusion architectures (e.g., BLIP-2-style, Flamingo-like) to determine whether the documented information loss is connector-specific or a general property of multimodal fusion.
- Evaluate scaling effects by testing small and very large models (>30B) to characterize how model size modulates information loss.
- Reconstruction methodology and identifiability
- Disentangle whether reconstruction error reflects true information loss vs limits of the trained reconstructor; quantify identifiability in many-to-one mappings (e.g., when connectors compress sequences).
- Benchmark multiple reconstruction families (MLP/Transformer/U-Net, diffusion-based inversion, invertible networks) and report capacity–performance curves for all three VLMs (not only LLaVA).
- Measure other reconstruction fidelity metrics beyond MSE/L2 norm differences (e.g., cosine similarity at patch level, feature-level LPIPS, CLIP score between original and reconstructed visual features).
- Provide theoretical bounds or identifiability conditions under which pre-projection embeddings are recoverable from post-projection embeddings.
- Dependence on training data and generalization
- Test reconstruction models trained on COCO against out-of-domain datasets (medical, satellite, documents) to assess generalization of the inferred “loss maps.”
- Investigate whether reconstruction models overfit to COCO statistics; include cross-dataset and few-shot evaluation of reconstructor robustness.
- Patch-level grounding and relevance
- Go beyond VizWiz masks by using diverse grounding sources (RefCOCO/RefCOCO+, PhraseCut, Visual Genome) to validate that high-loss regions consistently align with task-critical regions.
- Compare multiple patch-importance estimators (e.g., Grad-CAM/attention rollout/attribution maps from the LLM) to verify that “relevant” patches are correctly identified and that loss in those patches best predicts errors.
- Task coverage and evaluation breadth
- Extend beyond captioning/VQA/retrieval to fine-grained recognition, OCR/text-in-image, referring expression comprehension, detection/segmentation, and robustness (occlusion, low-light, blur).
- Evaluate instruction-following tasks requiring multi-hop visual reasoning to see if loss concentrates on compositional cues.
- Connector design and training signals
- Systematically vary connector architectures (depth, width, bottleneck size, residual/skip connections, attention vs MLP) and quantify how each design choice impacts KNOR and reconstruction loss.
- Integrate reconstruction-based regularizers (e.g., embedding-level distillation, rate–distortion objectives, Jacobian penalties) during connector training and report improvements in geometry preservation and downstream tasks.
- Explore dynamic or content-adaptive connectors (e.g., routing, conditional computation, mixture-of-experts, token pruning guided by textual context) to preferentially preserve task-relevant visual features.
- Role of the vision encoder
- Analyze the impact of freezing vs unfreezing the vision encoder on KNOR and reconstruction (e.g., Qwen2.5-VL continues to pretrain the vision encoder).
- Quantify how different vision encoders (CLIP, SigLIP, ConvNeXt, Swin, EVA) affect pre/post projection geometry and the connector’s learned mapping.
- Interaction with the LLM and flattener
- Measure how the flattener ordering and positional encodings affect post-projection utility; test whether reordering tokens or altering positional schemes changes downstream performance.
- Evaluate information preservation not only at the connector output but after the first few LLM layers to capture how the LLM transforms and potentially discards visual signals.
- Theoretical characterization
- Develop information-theoretic measures (e.g., mutual information estimates, rate–distortion trade-offs) to complement geometric metrics and provide principled notions of “loss.”
- Analyze connector mappings through Jacobian spectra, Lipschitz constants, and volume-preservation (or collapse) to relate local geometry distortions to global structure changes.
- Procrustes and manifold alignment
- Go beyond linear Procrustes by testing nonlinear manifold alignment (e.g., autoencoder alignment, optimal transport) to quantify whether nonlinearity suffices to reconcile pre/post spaces.
- Compare alignment errors across pooled vs token-level embeddings and across multiple pooling strategies (mean/max/attention pooling).
- Retrieval evaluation details
- Report full inner-product vs retrieval comparisons on CUB (and other retrieval datasets) in the main text; evaluate sensitivity to index settings (FAISS variants) and gallery size.
- Conduct class- and attribute-level error analysis to determine which fine-grained attributes are most affected by connector-induced loss.
- Robustness and uncertainty
- Test metric stability under input perturbations (noise, blur, compression, adversarial edits) to see whether connectors amplify vulnerability to distribution shifts.
- Quantify uncertainty in reconstruction (e.g., via ensembles or Bayesian models) and examine whether high predictive uncertainty correlates better with downstream failures than raw reconstruction error.
- Practicality and efficiency
- Assess the computational cost of large reconstructors (up to 844M params) and develop lightweight, training-free proxies for estimating information loss (e.g., local intrinsic dimensionality).
- Provide guidelines for estimating loss during pretraining without expensive auxiliary models.
- Reporting and reproducibility
- Release per-sample KNOR and loss maps for all datasets to enable meta-analysis; document seeds, data splits, and hyperparameters for KNOR, retrieval, and reconstruction.
- Perform significance testing for model–dataset differences in KNOR and reconstruction metrics, not only per-sample correlations.
- Open question on metric alignment with human utility
- Determine how well KNOR and reconstruction loss predict human-perceived failures in explanations or visual reasoning; include human studies or expert annotations linking loss regions to missed concepts.
- Pixel-level reconstruction and perceptual fidelity
- Revisit pixel-level inversion with stronger generative priors (e.g., diffusion-based inversion, high-capacity VAEs, NeRF-style priors) and larger/cleaner training sets to test whether connector outputs retain sufficient information for faithful image recovery.
- Time and video
- Extend to video-LLMs to measure whether connectors disproportionately discard temporal cues or motion features relative to spatial content.
- Multi-image and document settings
- Evaluate multi-image/context fusion and document understanding (tables/charts) where spatial layout and fine-grained symbols are critical, testing whether connectors lose structured relations.
These gaps collectively point to the need for broader architectural coverage, causal experiments, more principled metrics, richer tasks, and targeted connector training strategies that explicitly preserve task-relevant visual information while improving semantic alignment.
Collections
Sign up for free to add this paper to one or more collections.