- The paper introduces GAP, a new alignment strategy to stabilize visual latent reasoning in MLLMs by reconciling feature-space mismatches.
- It leverages a three-level approach—data, feature, and model-level alignment—with a lightweight PCA-aligned latent head to improve both interpretability and accuracy.
- Experimental results show notable gains in perception and reasoning metrics, confirming that controlled latent feedback enhances multimodal reasoning performance.
Granular Alignment Paradigm for Visual Latent Reasoning in MLLMs
Motivation and Feature-Space Mismatch Analysis
This paper introduces the Granular Alignment Paradigm (GAP) for visual latent reasoning in multimodal LLMs (MLLMs), focusing on the empirical instability and lack of transferability observed in prior latent-token generation schemes. Recent approaches have attempted to interleave visual and linguistic evidence within the token generation pipeline by creating continuous visual latent tokens, but these outputs are often fed back as subsequent latent inputs, creating a fundamental feature-space mismatch and optimization instability. In pre-norm transformer architectures, decoder hidden states exhibit substantially larger norms than the input vision embeddings, as evidenced by profiling Monet-7B, which shows text hidden states reaching 546× the norm of input text embeddings and vision hidden states 8.7× the norm of vision inputs.
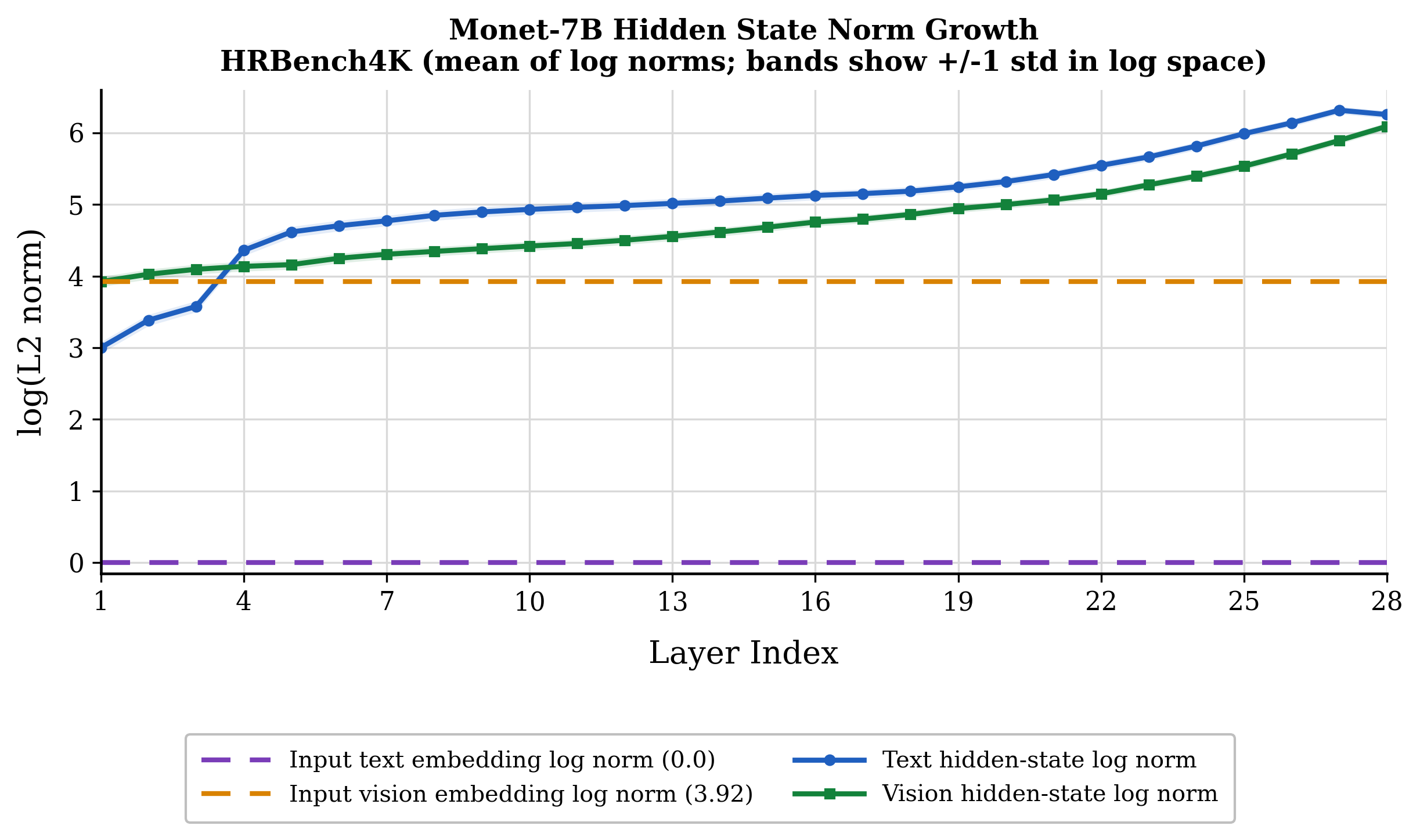
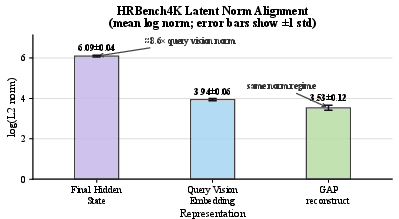
Figure 1: Layer-wise hidden-state norm growth demonstrates sharp norm escalation across model depth, indicating feature-space mismatch between output hidden states and input embeddings.
Direct latent feedback via output hidden states disrupts the input calibration, destabilizing the autoregressive feedback loop. The authors demonstrate that simple training-free Exponential Moving Average (EMA) norm matching at inference improves accuracy by +2.00 on MathVista, showing the feature-level compatibility as a practical factor for stable latent reuse. However, norm rescaling alone addresses only the symptom, motivating their more holistic alignment strategy.
Three-Level Alignment Design: GAP Methodology
GAP proposes a multi-level alignment approach—data-level, feature-level, and model-level—to reconcile the generated latents with the model input distribution and improve interpretability and training stability.
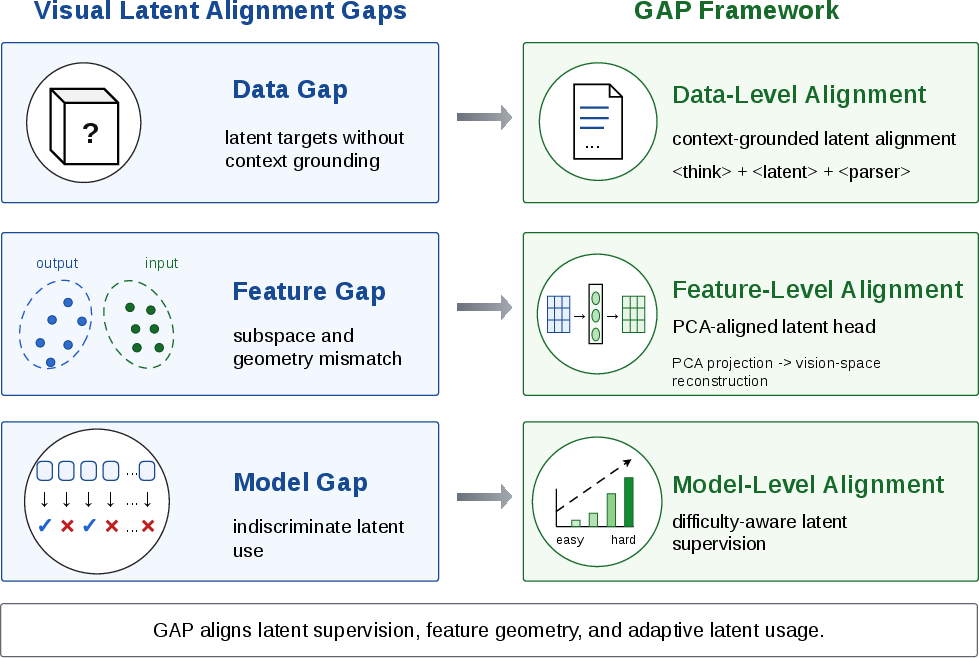
Figure 2: Conceptual overview of GAP, illustrating context-grounded latent supervision, PCA-aligned latent head, and difficulty-aware supervision as integrated alignment mechanisms.
Data-Level Alignment
Inspectability is achieved by pairing each training query with an auxiliary image whose frozen-ViT embeddings serve as latent supervision targets, without being visible to the model at inference. Responses interleave text reasoning, <latent> visual latent tokens, <parser> textual descriptions, and continued textual reasoning. The curated dataset contains 49,309 examples emphasizing visual chain-of-thought (CoT), chart analysis, multimodal math, geometry, visual search, and counting.
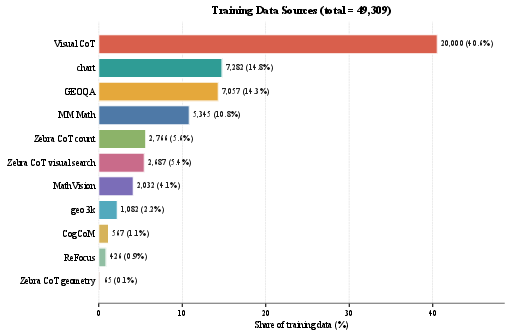
Figure 3: Composition of the 49K curated training set, highlighting Visual CoT, chart, GEOQA, and multimodal math as primary sources for latent-target supervision.
Feature-Level Alignment
Feature-level alignment is realized by a lightweight PCA-aligned latent head, which maps backbone-normalized decoder states into the principal subspace of vision embeddings. Instead of predicting full-dimensional embeddings, the head predicts low-rank PCA coefficients that are reconstructed into the empirical vision input space, returning generated latents to the input-compatible regime before autoregressive feedback. This capacity control both regularizes the latent head and enhances compatibility with the vision encoder's empirical distribution.
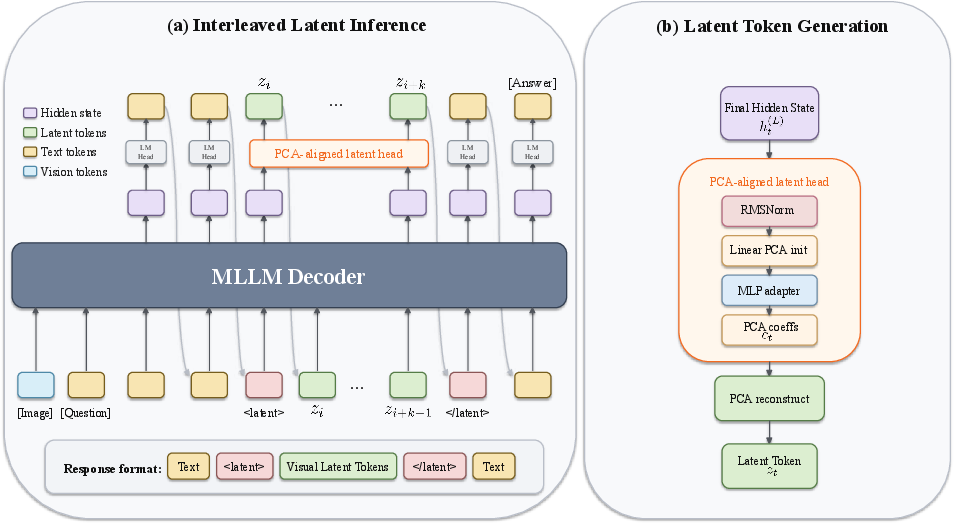
Figure 4: Interleaved visual latent inference and latent-token generation, depicting the autoregressive feedback loop and PCA-aligned latent head reconstruction pathway.
Model-Level Alignment
Difficulty-aware latent supervision minimizes unnecessary latent-target assignment by empirically estimating base-model accuracy per training example and assigning latent supervision only when the base model underperforms. This selective supervision reduces noise and prevents degradation on instances already solved by the base model, leading to improved training stability.
Experimental Results and Ablation Studies
The GAP model, trained on Qwen2.5-VL 7B, is evaluated across HRBench4K, MMStar, MME-RealWorld-Lite, MathVista, and WeMath. GAP achieves the best aggregate perception and reasoning scores among supervised variants, with notable improvements:
- Perception aggregate (Avg-P): GAP achieves $61.32$, outperforming prior latent baselines (Monet-7B: $59.58$, LVR: $60.75$).
- Reasoning aggregate (Avg-R): GAP achieves $53.97$, higher than Monet-7B ($47.99$) and LVR ($47.66$).
Difficulty-aware latent assignment, PCA-aligned latent head, and curated training data each contribute to the numerical gains. Ablations indicate that PCA-based capacity control is advantageous; retaining 95% variance (k=629 components) results in a relative reconstruction error of 8.7×0 and the highest three-benchmark average (Avg-3: 8.7×1). Zero-latent checkpoint and noise-infused latent interventions demonstrate that clean latent generation provides task-relevant signal at inference, improving performance from 8.7×2 to 8.7×3 in Avg-2 (HRBench4K and MathVista).
Token-budget analysis reveals performance saturation—36 tokens yield optimal results, while excessive tokens can degrade performance without corresponding accuracy gains.
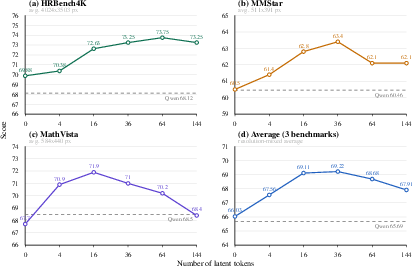
Figure 5: Effect of latent-token budget, showing performance across token count sweeps—visual latent capacity benefits performance but exhibits saturation and over-capacity effects.
Practical and Theoretical Implications
GAP demonstrates that robust visual latent reasoning requires geometric alignment in the latent-token feedback loop, inspection capability in supervision, and selective training signal. This paradigm enables MLLMs to generate interpretable, contentful visual latents within a single model architecture, obviating the need for external tools or vision generator calls that complicate inference and system design. By constraining the latent vector space to the empirical vision-embedding subspace, GAP reduces error propagation due to distribution mismatch and enhances generalization within visual reasoning benchmarks.
The release of a high-quality multimodal latent-supervision dataset further provides resources for future exploration in visual reasoning and latent feedback calibration. Theoretical implications extend to understanding norm accumulation in residual streams, subspace parameterization for capacity control, and the necessity of aligning latent feedback with the input geometry of deep transformer models.
Future Directions
The GAP methodology prompts several future research avenues, including the exploration of random-basis and matched-parameter low-rank alternatives, parser-latent faithfulness verification, adaptation to post-norm architectures, and reinforcement learning-based latent training. Additional work is necessary to confirm universality across diverse MLLM backbones and to address off-distribution hallucination, as evidenced by POPE OOD evaluations. Further scaling and automated latent-token budgeting may advance efficiency/accuracy trade-offs.
Conclusion
GAP systematically addresses feature-space incompatibility and supervision noisiness in visual latent modeling for MLLMs, attaining superior perception and reasoning performance by integrating PCA-aligned latent head, context-grounded supervision, and difficulty-aware assignment. The proposed alignment paradigm validates that content-bearing, input-compatible latent feedback is critical for stable and interpretable visual reasoning, setting robust foundations for future advances in multimodal cognitive architectures (2605.12374).

