- The paper introduces SA-AH-GRPO, a method that selectively applies entropy-based discounting on negative advantage rollouts to preserve full gradients on promising completions.
- The approach significantly reduces training variance (up to 3.6×) while achieving high Pass@1 scores on both 1.5B and 3B scale models in RL fine-tuning.
- It leverages per-token normalized entropy to dynamically adjust gradient credit assignment, promoting stable training and improved sample efficiency in language model optimization.
Selective-Advantage Entropy-Adaptive Horizon GRPO: Asymmetric Token-Level Discounting for Efficient RL of LLMs
Introduction and Motivation
This work systematically investigates the limitations of symmetric, uniform token-level weighting in RL-from-verifiable-reward (RLVR) LLM fine-tuning, particularly with Group Relative Policy Optimisation (GRPO). The authors introduce two methodologically principled extensions—Adaptive-Horizon GRPO (AH-GRPO) and its asymmetric variant, Selective-Advantage AH-GRPO (SA-AH-GRPO). Both leverage the model's predictive uncertainty, quantified by per-token normalized entropy, to re-weight the policy gradient loss dynamically. Unlike prior approaches, SA-AH-GRPO restricts this entropy-based discounting to rollouts with negative (group-normalized) advantage, preserving the full gradient signal on promising completions. The result is a significant reduction in training variance (especially pronounced at larger scale), aligning with theoretical expectations from variance reduction and decision theory in RL.
Methodology
The central insight is that the informativeness of each token position during autoregressive generation is contextually variable. When the model is confident (low entropy), the sampled token represents a high-fidelity local mode of the distribution, supporting robust policy updates. When uncertainty is high (high entropy), a single sampled token is a weak proxy, and enforcing aggressive updates can destabilize training. AH-GRPO introduces an exponentially decaying discount to token-level gradients as a function of cumulative entropy, shortening the effective credit assignment horizon at uncertain positions:
wt(i)=s=1∏texp(−αHs(i))
where Ht(i) is the model's normalized entropy at position t in rollout i, and α is a tunable hyperparameter controlling the degree of discounting.
In SA-AH-GRPO, this discount is selectively applied—limited only to rollouts with negative group-normalized advantage. Thus, positive-advantage (correct) trajectories propagate an unaltered gradient through all token positions.
Main Results
The empirical evaluation is conducted on mathematical reasoning (GSM8K), testing Qwen2.5-1.5B-Instruct and Qwen2.5-3B-Instruct models fine-tuned with LoRA. The three variants (GRPO, AH-GRPO, SA-AH-GRPO) are compared in terms of Pass@1, training variance, and KL divergence.
On the 3B model, all methods achieve high final Pass@1 scores (0.846–0.862), outperforming the zero-shot baseline. SA-AH-GRPO reduces training variance by 3.6× compared to standard GRPO with no loss in peak accuracy. On the 1.5B model, where the zero-shot baseline is lower, the best final accuracy (Pass@1 of 0.686, a +4.9 percentage-point gain) is observed with SA-AH-GRPO.
The variance reduction with SA-AH-GRPO is especially notable at the 3B scale, while at 1.5B it yields superior accuracy with higher reward variation—likely due to increased policy plasticity and more aggressive exploration (mirrored in higher mean KL). An α-ablation study on the 1.5B model shows all positive α values outperform baseline and all negative (entropy-amplifying) settings, confirming the central design hypothesis.
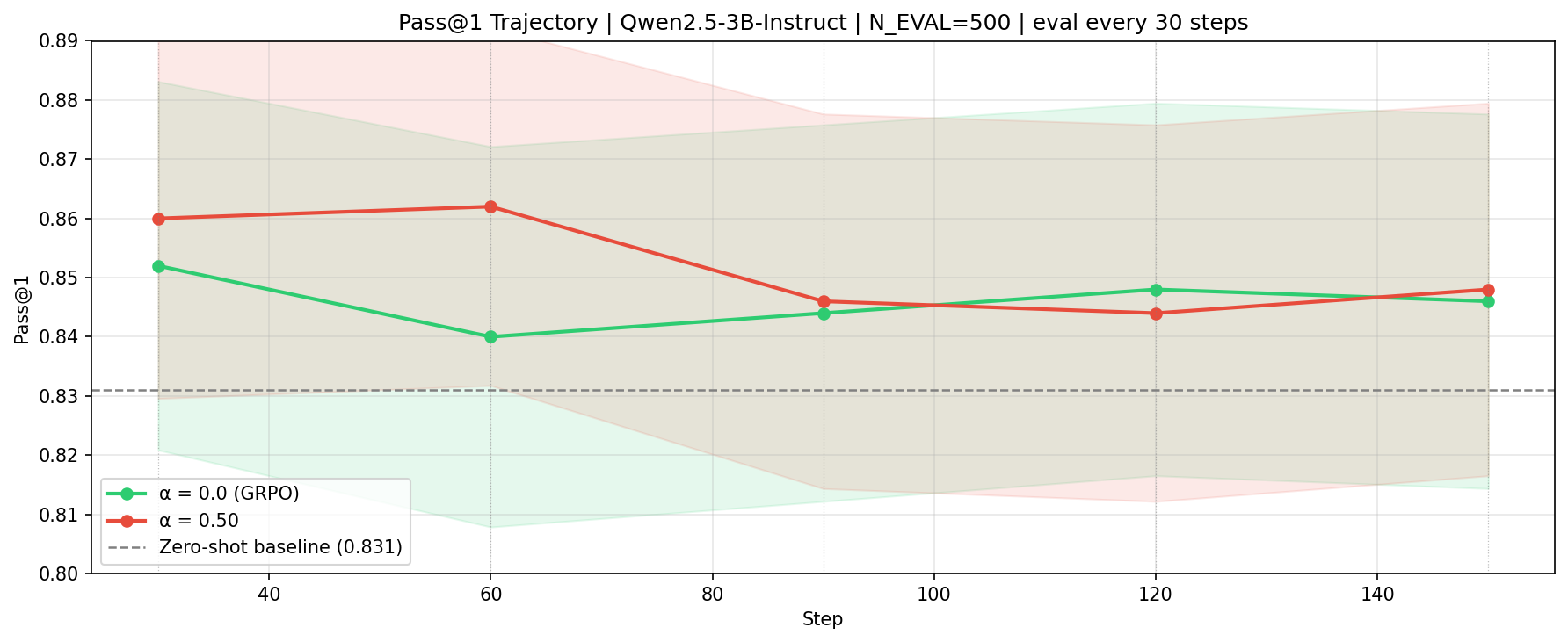
Figure 1: Pass@1 on GSM8K (3B model) for GRPO; shows convergence and performance under uniform weighting.
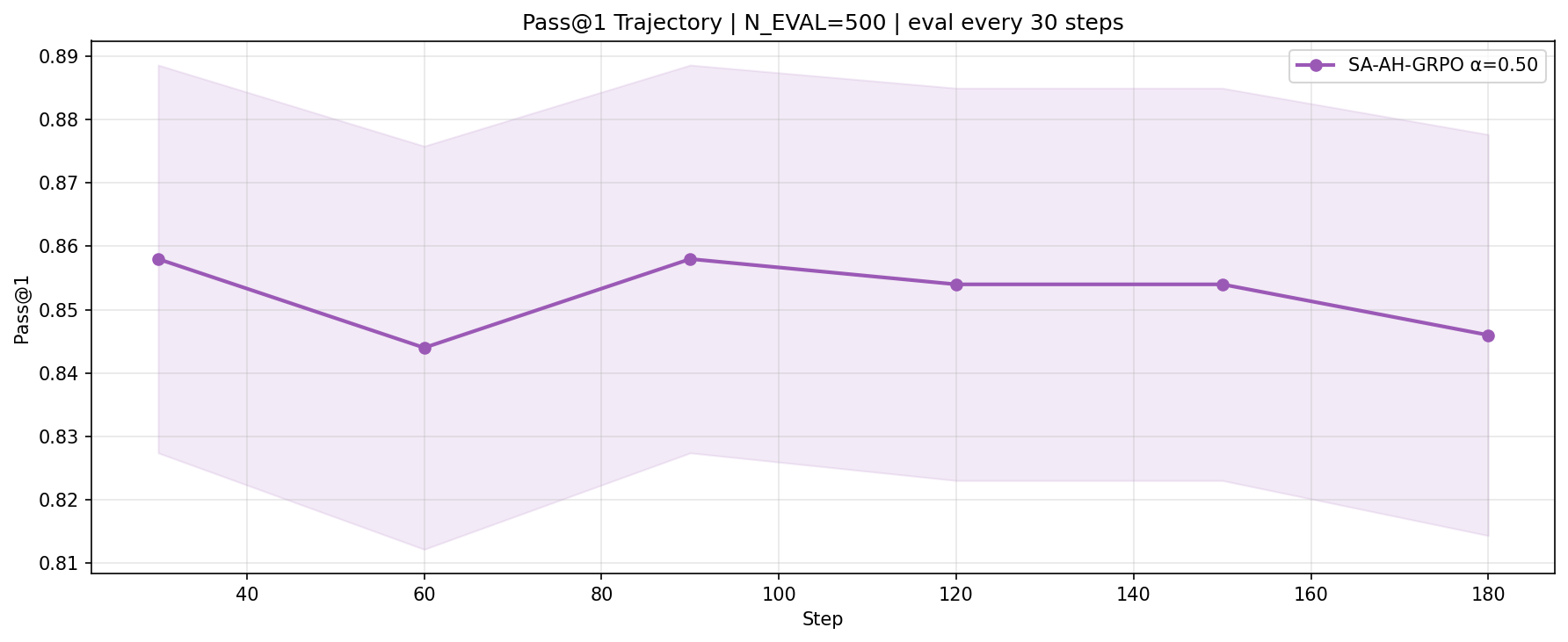
Figure 2: Pass@1 for SA-AH-GRPO (α=0.5) on 3B; demonstrates sustained accuracy and reduced variance over training.
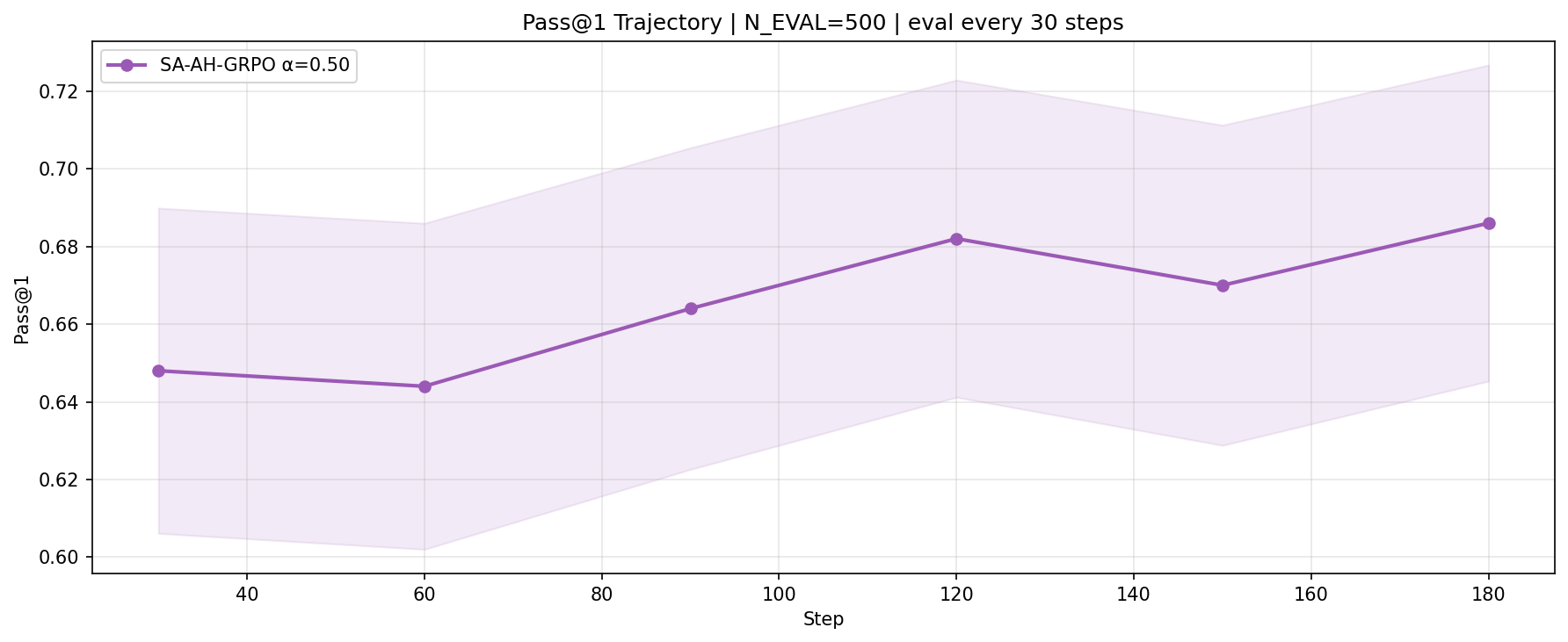
Figure 3: Pass@1 for SA-AH-GRPO (α=0.5) on 1.5B; shows consistent gains over baseline and increasing accuracy.
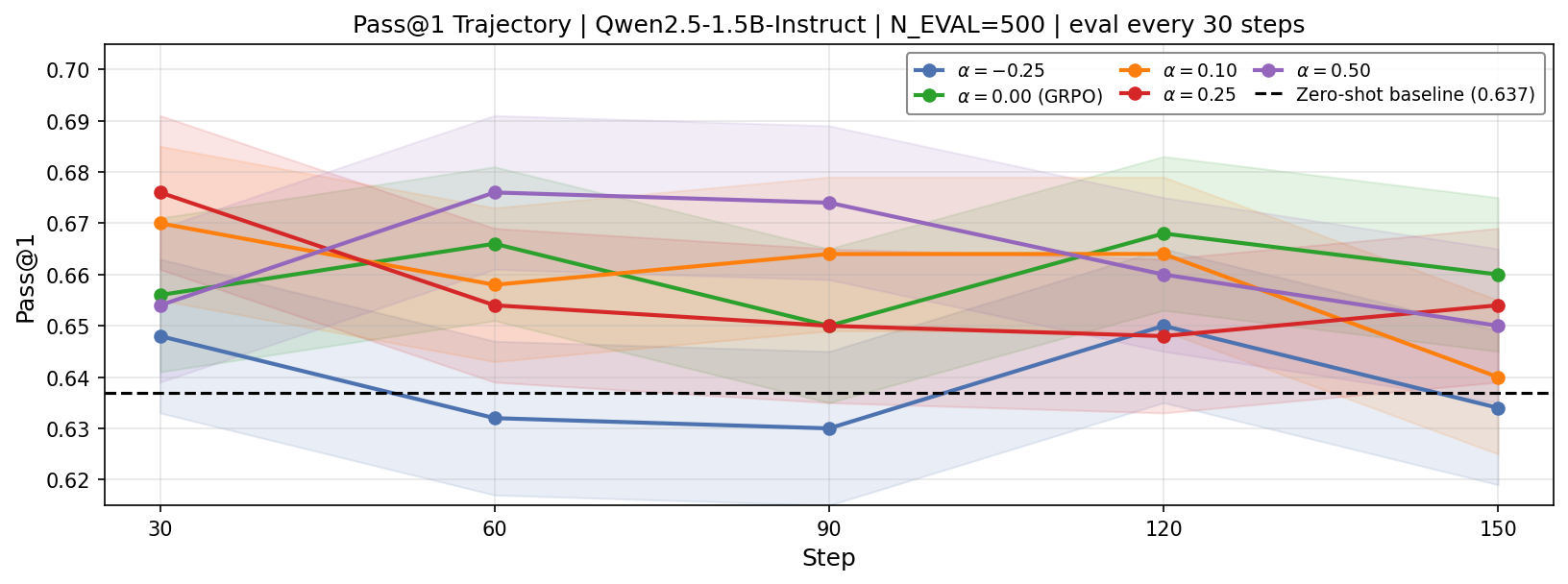
Figure 4: α-ablation of AH-GRPO; positive Ht(i)0 consistently outperforms the entropy-amplifying regime.
Analysis and Theoretical Implications
SA-AH-GRPO introduces a form of inductive bias: correct trajectories, regardless of local uncertainty, propagate full gradient credit, supporting robust model improvement. By contrast, erroneous completions with high-entropy positions have their gradients attenuated, preventing spurious updates from ambiguous contexts—a well-aligned intervention in the RLVR setting where supervision is outcome-grounded.
This asymmetric approach avoids over-penalization of tokens that, while uncertain, contributed to successful completions, addressing a fundamental inefficiency in prior symmetric techniques. The entropy-adaptive discount also implicitly implements a curriculum: as model confidence increases during training, the effective horizon lengthens, annealing the regularisation effect and naturally transitioning to standard GRPO near convergence.
Relation to Prior Work
Prior work on RLHF and RLVR (e.g., PPO, process rewards, per-token RL) either relies on auxiliary reward models, fixed heuristics, or lacks adaptation to model uncertainty in loss weighting. Entropy regularisation has typically been formulated as explicit maximization (e.g., maximum entropy RL) rather than uncertainty-weighted gradient discounting. The present approach distinguishes itself by deriving token-level weights analytically from the model's own predictive distribution, and by introducing outcome-conditioned, per-rollout asymmetry.
Practical and Future Implications
The demonstrated variance reduction at scale has direct implications for improved training stability and decreased fine-tuning cost. The methods are broadly applicable: per-token discounting mechanisms are orthogonal to reward shaping and can be deployed in RLVR settings with verifiable rewards, multi-step reasoning, or code generation. The natural curriculum inherent in the entropy-based approach is likely to generalize robustly to settings where exploration-exploitation balance is challenging.
Extensions include scaling to even larger architectures (e.g., 7B, 70B) and diverse task domains (code synthesis, logic). A full joint sweep over Ht(i)1 and asymmetry is warranted. The implications for sample complexity, convergence rate, and optimality in low-resource regimes merit dedicated study.
Conclusion
The paper introduces and rigorously validates entropy-adaptive, asymmetric token-level discounting (SA-AH-GRPO) as an effective variance-reduction and stability mechanism for RL-based LLM fine-tuning with verifiable rewards. The results support the thesis that per-token uncertainty should guide gradient credit assignment, especially in autoregressive structured prediction. The work sets a new methodological baseline for RLVR training protocols and informs the design of scalable, stable RL algorithms for LLMs.