- The paper introduces a dynamic cost-quality control mechanism that adjusts compute allocation based on success likelihood.
- It employs a modular, lemma-driven proof generation pipeline using trajectory-derived features for cost and accuracy estimation.
- Empirical evaluations on PutnamBench demonstrate up to a 59.9% cost reduction with minimal accuracy loss, affirming the method's efficiency.
Optimizing the Cost-Quality Tradeoff in Agentic Lean Theorem Provers
Introduction
The proliferation of LLMs in automated formal theorem proving has significantly advanced the state of the art in systems such as Lean, enabling scalable, precise, and verifiable proof synthesis. However, state-of-the-art agentic theorem-proving frameworks, which recursively decompose problems and sample numerous attempts per subproblem, incur substantial computational cost, often allocating extensive resources to trajectories with little prospect of success. The paper "Optimizing the Cost-Quality Tradeoff of Agentic Theorem Provers in Lean" (2606.04883) addresses the inefficiency inherent in static, fixed-step allocation policies by proposing and empirically validating a routing-centric control mechanism for agentic Lean provers. This approach dynamically allocates compute based on the evolving likelihood of successful proof discovery, as inferred from the agent’s interaction trajectory with the theorem prover and Lean compiler feedback.
The authors introduce a modular agent architecture partitioned into a proof-generation data plane and a cost-quality control plane. The data plane follows prior agentic prover frameworks by hierarchically decomposing formal problems into lemmas, formalizing them, and recursively attempting proofs—each direct interaction with a verified Lean environment. The control plane operates orthogonally, observing the failure/success history within a proof attempt trajectory and extracting features such as proof similarity and error diversity to estimate both the expected cost and the probability of future success. At each routing juncture, the agent uses a cost-quality utility function
τ(s)=q^(s)−λc^(s)
where q^(s) is the predicted next-attempt solve rate, c^(s) is the expected compute cost, and λ controls the cost-quality imbalance to enact an optimal stopping policy.
This design can be straightforwardly extended to richer agentic action spaces, subsuming actions such as model switching and self-correction, so long as suitable estimators for cost and utility are constructed per action.
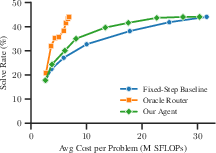
(Figure 1)
Figure 1: Cost-quality curve comparison between the proposed agentic router, a fixed-step baseline, and a zero-noise oracle, demonstrating substantial resource savings at comparable accuracy.
Empirical Evaluation and Numerical Results
Experiments are conducted on an 85-problem subset of PutnamBench, using Goedel-Prover-V2-8B as the proof-generating backend. The adaptive routing agent is compared against a fixed-step baseline (fixed budget per subproblem) and an oracle agent with access to ground-truth success probability. The primary evaluation metric is SFLOPs, and the systems are benchmarked for both constant-performance and constant-budget regimes.
Key numerical results include:
Ablation studies confirm the significance of trajectory-derived features, with error diversity being especially salient for next-attempt success estimation.
Analysis of Data Plane Architectural Impact
The agent’s data plane—based on recursive lemma-driven decomposition (as opposed to monolithic, end-to-end proof generation)—is shown to confer substantial performance gains, even for a fixed inference budget. Using identical model capacity, the lemma-driven pipeline nearly matches the accuracy of a much larger 32B-parameter model configured for whole-proof generation, doubling the solve rate compared to an 8B whole-proof baseline.
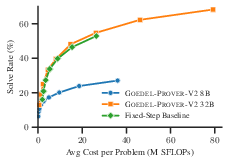
Figure 2: Comparison between fixed-step data plane pipeline and whole-proof generation, highlighting superior performance due to the modular, decompositional prover architecture.
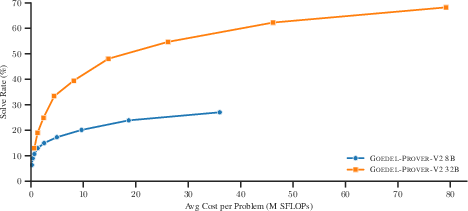
Figure 4: Whole-proof cost-quality curves on PutnamBench baseline for context; decompositional pipelines approach the accuracy region of significantly larger single-step models at lower compute cost.
Theoretical and Practical Implications
This work exposes the substantial inefficiency of static compute-allocation strategies in agentic theorem-proving systems and demonstrates that policy-based, trajectory-aware routing yields substantial savings without degrading problem-solving performance. Furthermore, the observation that even a simple proxy feature vector—incorporating proof similarity, error diversity, and attempt count—enables much of the theoretical benefit achievable by an oracle suggests significant opportunities for further optimization via richer trajectory representations and more expressive estimators.
Practically, this approach provides a pathway to reduce the prohibitive runtime cost associated with competitive formal reasoning agents ($40–50 per problem on PutnamBench in reported state-of-the-art), allowing for more scalable research, experimentation, and deployment.
Limitations and Prospective Future Directions
The study’s limitation lies primarily in computational cost, restricting empirical validation to a mid-scale slice of PutnamBench. Nonetheless, the generality of the agentic routing framework admits numerous future extensions:
- Learned cost/utility estimation with deep models rather than linear regression.
- Generalization to broader agent action spaces, including hierarchical action selection, model switching, fine-tuned self-correction, and depth-adaptive recursion.
- Application to other formal systems and mathematical domains, leveraging runtime verifiability as an information source for control.
The explicit gap to oracle routing underscores the need for stronger, possibly learned trajectory embeddings and exploration of unsupervised or semi-supervised quality estimation.
Conclusion
The paper demonstrates that cost-quality-aware routing in agentic Lean theorem provers enables significant reductions in inference resource consumption at minimal or no loss in success rate. The decoupled agent architecture and trajectory-derived estimation framework are empirically validated and theoretically extensible, laying foundational methodology for future scalable and efficient agentic mathematical reasoning systems. The results suggest that adaptive control, grounded in observed trajectory statistics, should be the default design for cost-sensitive formal reasoning agents.