Do Transformers Need Three Projections? Systematic Study of QKV Variants
Abstract: Transformers have become the standard solution for various AI tasks, with the query, key, and value (QKV) attention formulation playing a central role. However, the individual contribution of these three projections and the impact of omitting some remain poorly understood. We systematically evaluate three projection sharing constraints: a) Q-K=V (shared key-value), b) Q=K-V (shared query-key), and c) Q=K=V (single projection). The last two variants produce symmetric attention maps; to address this, we also explore asymmetric attention via 2D positional encodings. Through experiments spanning synthetic tasks, vision (MNIST, CIFAR, TinyImageNet, anomaly), and language modeling (300M and 1.2B parameter models on 10B tokens), we discovered that our transformers perform on par or occasionally better than the QKV transformer. In language modeling, Q-K=V projection sharing achieves 50% KV cache reduction with only 3.1% perplexity degradation. Crucially, projection sharing is complementary to head sharing (GQA/MQA): combining Q-K=V with GQA-4 yields 87.5% cache reduction, while Q-K=V + MQA achieves 96.9%, enabling practical on-device inference. We show that Q-K=V preserves quality because keys and values can occupy similar representational spaces and attention operates in a low-rank regime, whereas Q=K-V breaks attention directionality. Our results systematically characterize projection sharing as an underexplored instance of weight tying in attention, with direct, quantifiable inference memory benefits, particularly valuable for edge deployment. The code is publicly available at https://github.com/Brainchip-Inc/Do-Transformers-Need-3-Projections
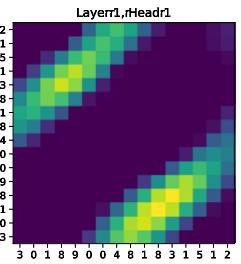
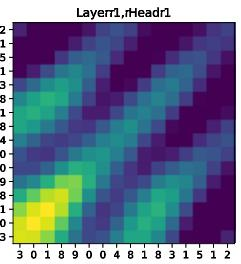
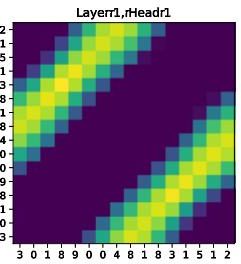
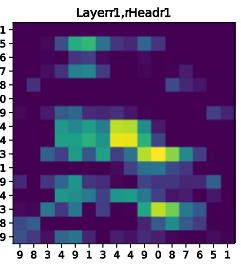


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A Simple Explanation of “Do Transformers Need Three Projections? Systematic Study of QKV Variants”
What is this paper about?
Transformers are a popular kind of AI model used for language, images, and more. They use a part called “attention,” which looks at information using three versions of the input: Queries (Q), Keys (K), and Values (V). This paper asks a simple question: do we really need all three separate versions, or can we share some of them to make the model smaller and faster without losing much quality?
To picture Q, K, and V, think of a library:
- Q is your question.
- K are the labels on the books.
- V is the actual content inside the books. Attention finds which books (K) match your question (Q) and then reads the useful content (V).
What questions do the researchers try to answer?
The paper explores three easy-to-understand questions:
- What happens if we make Keys and Values the same (K=V)? Can the model still work well?
- What happens if we make Queries and Keys the same (Q=K)? Does that help or hurt?
- What if we make Q, K, and V all the same (Q=K=V)? Is that too simple?
- Can these changes save memory and speed up the model (especially during generation), and do the results stay good enough?
What did they do to test this?
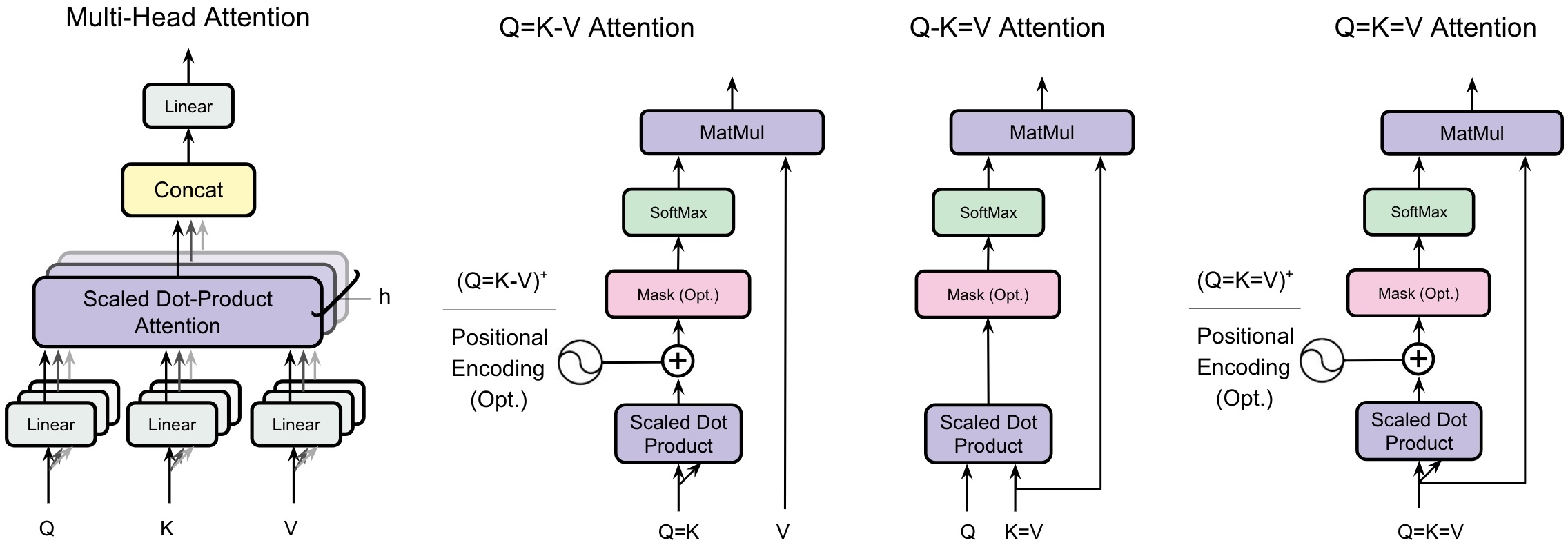
The researchers tried three “projection-sharing” versions of attention, where some of Q, K, and V are literally the same:
- Q=K-V: Use the same projection for Q and K, keep V separate.
- Q-K=V: Keep Q separate, but make K and V the same (K=V).
- Q=K=V: Use one projection for all three.
They also tried a small trick for the Q=K cases: adding special 2D positional encodings (marked as “+”) to re-introduce directionality. In simple terms, this helps the model tell “who attends to whom” even when Q and K are identical.
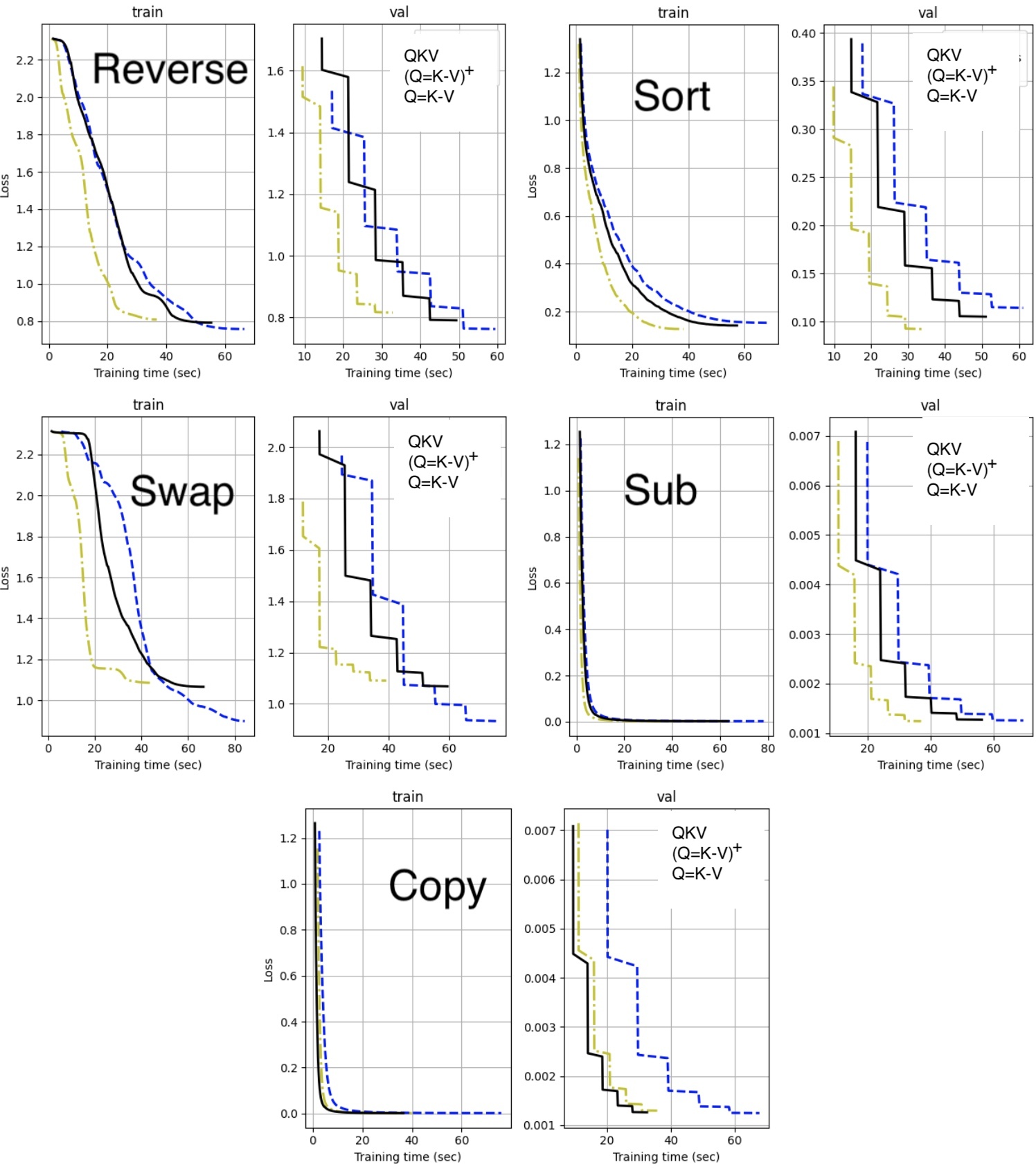
They ran these versions across many tasks:
- Synthetic list tasks (like reversing or sorting numbers)
- Vision (MNIST, CIFAR-10/100, TinyImageNet, and anomaly detection)
- Language modeling (training large text models with 300M and 1.2B parameters on 10 billion tokens)
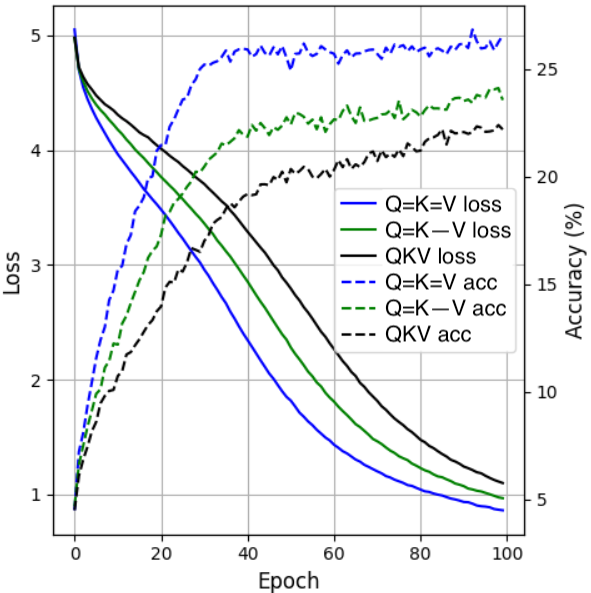
They kept everything else the same (layers, optimizer, training setup) so differences come from the attention change. They measured:
- Quality (accuracy for images/tasks; perplexity for language, where lower is better)
- Speed (tokens per second)
- Memory use during generation, especially the “KV cache,” which stores past K and V to generate the next tokens efficiently
What did they find, and why does it matter?
Here are the main results in plain language:
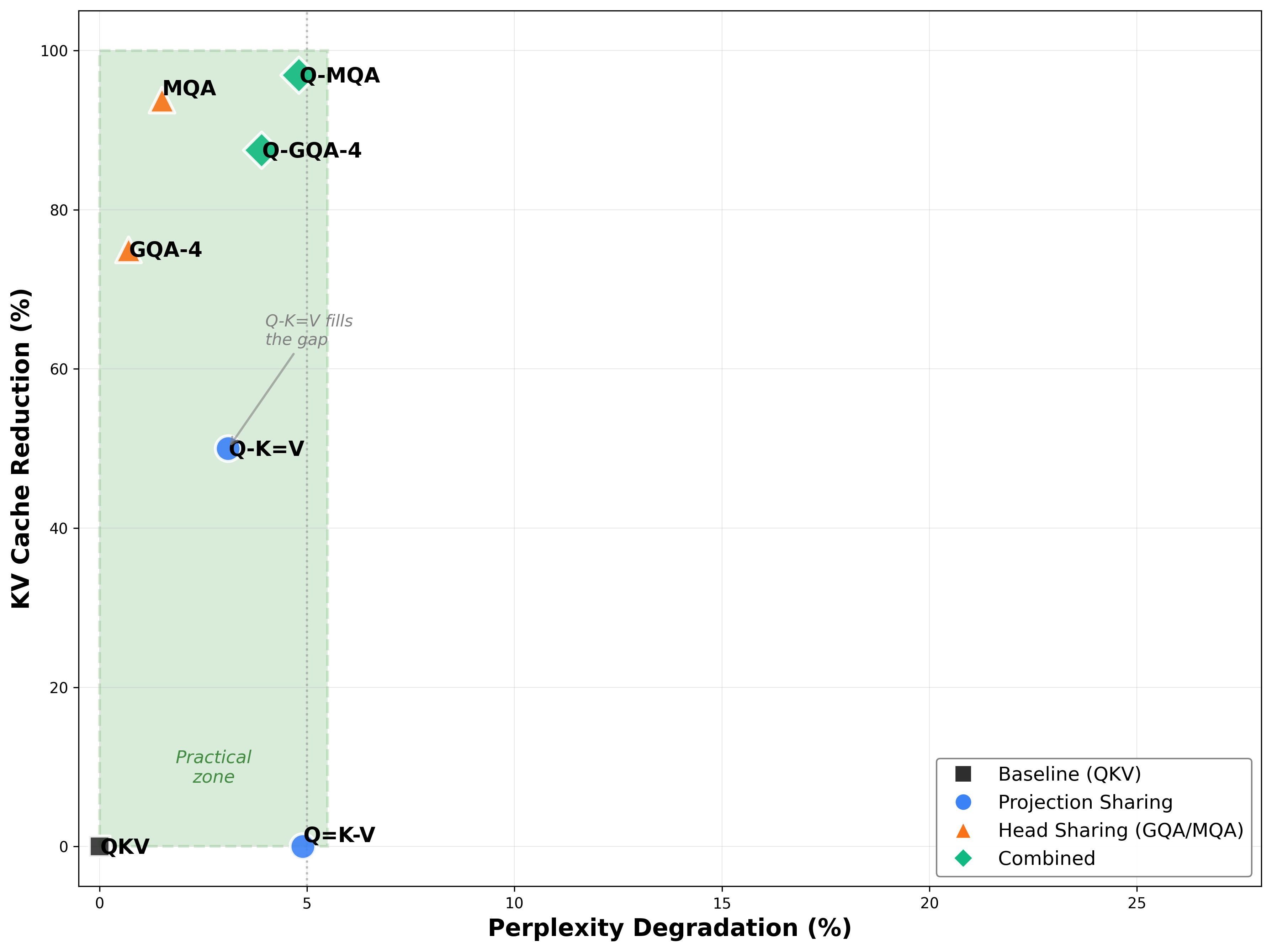
- The standout winner for LLMs is Q-K=V (make K and V the same):
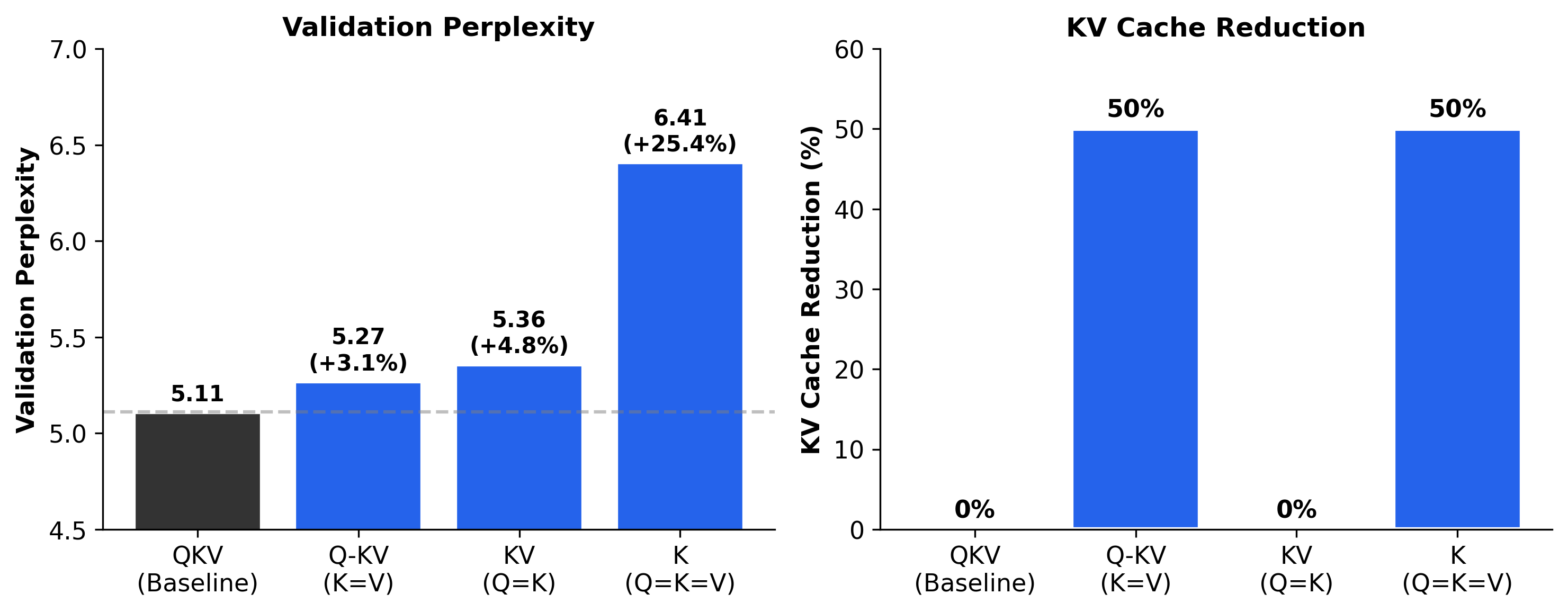
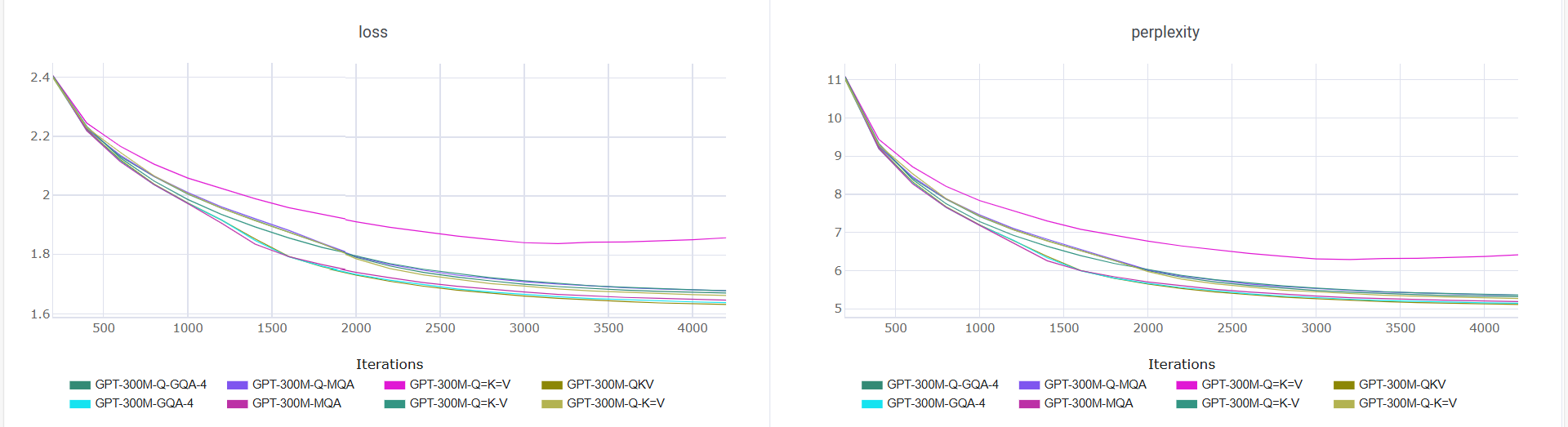
- It cuts the KV cache memory in half (50% reduction), which is a big deal during generation.
- It keeps quality almost the same. For a 300M model, perplexity only worsened by about 3.1%, and for a 1.2B model, by about 2.5%.
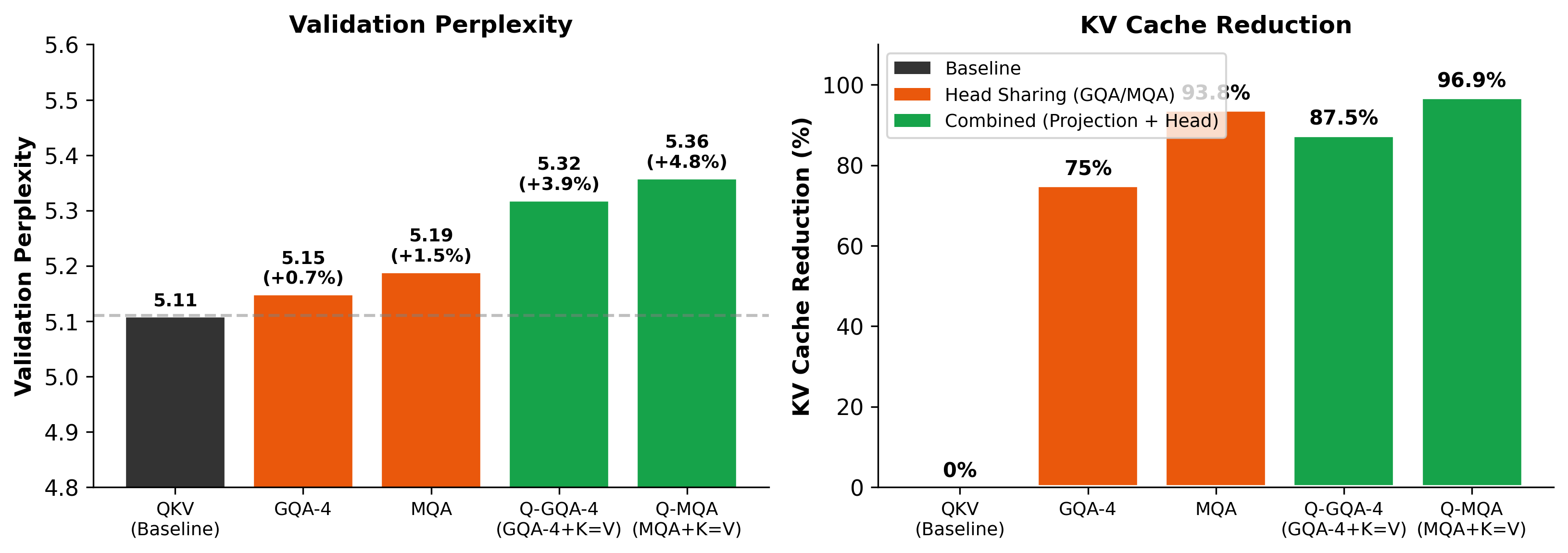
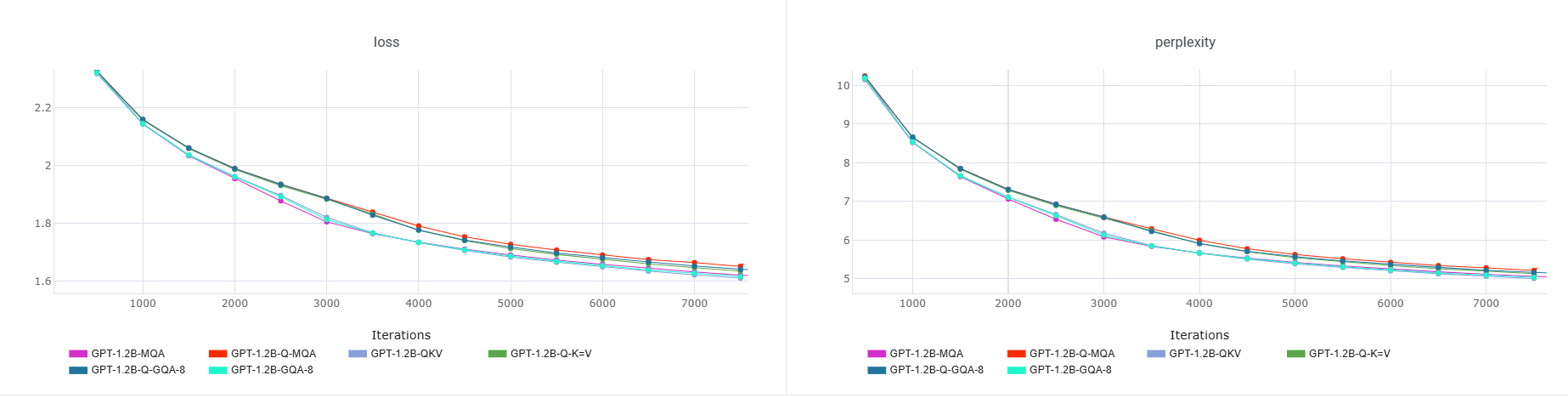
- When combined with industry methods that share heads (GQA/MQA), memory drops even more:
- Q-K=V + GQA-4: about 87.5% cache reduction
- Q-K=V + MQA: about 96.9% cache reduction
- Q=K-V (make Q and K the same) often works fine on non-sequential tasks like images, especially with the “+” positional encoding. But for language (which is time-ordered), it hurts directionality and gives no memory savings during generation, so it’s not a good trade-off for deployment.
- Q=K=V (make all three the same) is usually too restrictive for language modeling. It can work okay on some vision tasks but loses too much quality for text.
- In downstream testing (like HellaSwag, PIQA, ARC, WinoGrande), the small perplexity gap from Q-K=V didn’t turn into a big drop in accuracy. That means the memory savings often come with minimal real-world quality loss.
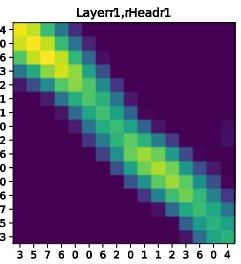
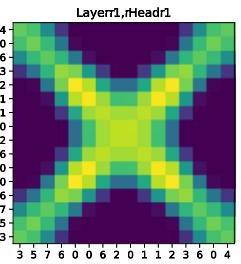
Why Q-K=V works: Keys and Values carry very similar information in practice, so sharing them is natural. But Queries need to be different to point attention in a direction. If Q=K, the attention becomes “symmetric” (it does not clearly point from one token to another), which is harmful for tasks like language where order matters.
How did they do it? A bit more detail in everyday terms
- Projection sharing: Normally, the model learns three separate linear layers to make Q, K, and V. The authors tied some of them together so the same layer is used twice, reducing parameters and compute.
- Symmetry vs asymmetry: When Q=K, the attention map becomes symmetric—like saying “A attends to B” and “B attends to A” equally. That’s fine for images or sets (no order), but not for language (needs direction from past to future).
- Positional encodings “+”: For non-causal tasks, they added 2D positional features to break symmetry and give the model a sense of structure even when Q=K.
- KV cache: During text generation, models save K and V of past tokens to avoid recomputing. If K=V, you only need to store one of them, cutting memory in half. This is crucial for long contexts or serving many users at once.
Key takeaways and why this matters
For clarity, here are the main practical takeaways:
- If you’re building LLMs: use Q-K=V. You get big memory savings with tiny quality cost. It stacks well with GQA/MQA for even more savings.
- For vision or set-like tasks: Q=K-V or Q=K=V might be enough, and the “+” version can help when direction information is needed.
- Memory savings = longer context or more users at once. With the same hardware, you can:
- Handle longer inputs
- Serve more people simultaneously
- Cut costs for on-device or edge deployment
What’s the broader impact?
This work shows that attention can be simpler without losing much power. Sharing K and V:
- Makes models lighter during inference
- Enables longer contexts and more efficient real-time use
- Works well with existing techniques like GQA/MQA and quantization
- Helps bring capable models to smaller devices, not just big servers
In short: We don’t always need three separate projections in attention. Sharing Keys and Values (Q-K=V) is a smart, practical shortcut that keeps models strong while making them much easier to run in the real world. The code is available so others can try it out and build on it.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains uncertain or unexplored, framed to guide concrete follow-up research.
- Scaling and training budget
- Validate projection-sharing rankings at larger scales (≥7B parameters) and longer training (≥100B tokens); current results top out at 1.2B and 10B tokens and may be under-trained.
- Assess whether Q-K=V’s relative advantage persists with larger context sizes (≥128k) and extreme batch sizes in production-grade settings.
- Long-context behavior and benchmarks
- Directly evaluate on long-context benchmarks (e.g., LongBench, Needle-in-a-Haystack, PG-19, NarrativeQA long), measuring retrieval fidelity, attention drift, and degradation with context length for K=V.
- Characterize KV-cache reuse accuracy across very long horizons when K serves both addressing and content roles.
- Downstream breadth and capability
- Expand beyond a small 5-task 5-shot suite to include MMLU, Big-Bench, MBPP/HumanEval (code), GSM8K/MATH (reasoning), QA (open-domain, multi-hop), and tool-use to verify capability retention under K=V.
- Measure calibration (ECE/Brier), uncertainty, and robustness (OOD and adversarial prompts), which may be sensitive to representational tying.
- Instruction tuning and alignment
- Test effects of projection sharing on instruction tuning, SFT, RLHF/DPO, and safety filters; analyze whether K=V affects conversational quality and refusal/safety behavior.
- Cross-attention and encoder–decoder models
- Empirically evaluate projection sharing in cross-attention (machine translation, summarization, VLMs) where aligning encoder keys with decoder values may have different dynamics.
- Determine whether K=V in cross-attention harms pointer-like behaviors or alignment quality.
- Vision and multimodal scope
- Validate on ImageNet-1K pretraining and modern transfer protocols; extend to detection/segmentation (COCO), video (Kinetics), and VLMs to test symmetry/asymmetry needs across modalities.
- Systematically ablate (X)+ positional scheme design (channel dimension m, alternatives like learned relative bias or rotary) and compare to strong baselines (RoPE/ALiBi/LePE).
- Hyperparameter and architecture fairness
- Tune hyperparameters per variant (LR, wd, dropout, norms, initialization) rather than reusing QKV settings; quantify how much performance can be recovered with variant-specific tuning.
- Explore compensating for fewer projections by reallocating parameters/compute (e.g., deeper networks, larger MLPs, more heads) under matched FLOPs or memory budgets.
- Head-sharing interactions and design space
- Systematically sweep GQA group sizes and head dimensions with K=V across scales to map the full Pareto frontier and identify instability regions.
- Study whether head mixing, learned routing, or per-head K=V gates can mitigate K=V’s degradation at high compression.
- Positional asymmetry and symmetric attention issues
- Investigate stronger methods to mitigate diagonal dominance for Q=K (e.g., subtractive/learned bias on diagonals, gating, attention masks with learned anti-diagonal bias).
- Test whether modern positional schemes (RoPE/ALiBi/relative bias) salvage Q=K for causal language modeling, potentially narrowing the gap to QKV.
- Theoretical grounding
- Provide a formal analysis of when K and V can share a representational space without loss (e.g., conditions on task distribution, attention kernel rank, spectrum of QKᵀ).
- Quantify low-rank regimes across layers and datasets (effective rank of K, V; rank of attention maps; sensitivity to head dimension), and link to generalization/performance.
- Validate or refute the “V is less essential” hypothesis with causal interventions (e.g., swap/permute K vs V subspaces, targeted ablations) across tasks.
- Retrieval and associative memory behavior
- Evaluate associative recall, copy/pointer tasks, key–value mismatches, and memory-intensive retrieval QA to detect failure modes when K=V conflates address and content vectors.
- Measure how K=V affects precision/recall trade-offs in retrieval-augmented generation and dense passage retrieval settings.
- Practical deployment and systems claims
- Provide end-to-end latency/throughput benchmarks under real serving loads (concurrent sessions, paged attention, variable sequence lengths) on diverse hardware (A100/H100/TPU, CPU/edge NPUs).
- Quantify energy efficiency and cost savings (Joules/token, $/million tokens) and verify cache savings with memory-fragmentation-aware allocators.
- Validate on-device/mobile inference claims with measured memory, thermals, and latency on target hardware; assess integration with paged attention and FlashAttention2/3 kernels.
- KV cache techniques and quantization
- Empirically test composition with KV quantization (INT8/INT4), eviction/windowed strategies, and compression (e.g., MLA, low-rank KV, token pruning); report quality–memory trade-offs and failure modes.
- Explore “K-only quantization” for K=V and its error propagation versus standard K and V quantization.
- Training dynamics and stability
- Analyze convergence speed, optimization stability, and gradient flow differences across variants; identify failure modes (e.g., dead heads, collapse) and remedies.
- Study sensitivity to normalization choices (pre-/post-LN, RMSNorm), activation functions, and optimizer settings.
- Robustness and safety
- Evaluate resilience to distribution shift, noise, and adversarial attacks in both language and vision; assess bias/fairness impacts introduced by projection tying.
- Reproducibility and statistical confidence
- Report multiple seeds and confidence intervals for LLM experiments; many presented results are single-run and may be within noise at current scales.
- Comparative baselines
- Provide direct empirical comparisons against alternative KV-reduction/compression methods (e.g., DeepSeek-V2’s MLA, low-rank KV, cross-layer KV reuse) at matched memory budgets.
- Compare to linear/kernalized attention baselines and recent efficient attention methods under equalized training compute and data.
- Training-time memory and efficiency
- Quantify training-time memory/compute savings (not just inference) for K=V, including effects on activation checkpointing, batch size scaling, and wall-clock speed.
- Generalization and transfer
- Test how projection sharing affects transfer learning (domain adaptation, low-shot fine-tuning), catastrophic forgetting, and adapter/LORA fine-tuning compatibility and performance.
Practical Applications
Immediate Applications
Below are actionable, near-term uses that can be deployed with current tools and engineering resources, drawing directly from the paper’s findings on Q-K=V (K=V), Q=K-V, and Q=K=V (plus the (X)+ 2D positional encoding for non-causal tasks).
- Memory-optimized LLM serving with Q-K=V
- Sectors: software, cloud, enterprise IT, finance, customer support, developer tools
- What to do: Train or fine-tune decoder-only LLMs with Q-K=V (K=V) and swap serving to cache only K tensors. Optionally combine with head sharing (GQA/MQA) and KV quantization (INT8/INT4).
- Benefits: 50% KV cache reduction with ~3% perplexity increase at 300M, ~2.5% at 1.2B; up to 87.5–96.9% cache reduction with GQA/MQA; higher concurrency per GPU, lower serving cost, longer context windows without extra VRAM.
- Tools/workflows: Integrate Q-K=V as an attention variant in PyTorch/Hugging Face Transformers; update inference engines (e.g., vLLM, TensorRT-LLM) to store only K; combine with FlashAttention and KV quantization; add capacity planning dashboards using new cache sizes.
- Assumptions/dependencies: Must train or fine-tune models with K=V from scratch; cannot enable by swapping kernels only; gains are largest in memory-bound serving (long context or high concurrency).
- On-device and edge LLMs using Q-K=V + MQA/GQA
- Sectors: mobile, IoT, automotive, robotics, defense
- What to do: Build small-to-mid-scale LLMs with Q-K=V and MQA/GQA to minimize cache (96.9%+ reductions); deploy for offline voice assistants, car infotainment, or robot task planning.
- Benefits: Orders-of-magnitude smaller KV cache (e.g., 32k context ~88 MB at 1.2B with Q-MQA), enabling on-device inference without offloading.
- Tools/workflows: INT4 KV cache, weight-only quantization, fused kernels; battery and thermal testing; on-device privacy workflows for PII.
- Assumptions/dependencies: Slightly higher perplexity; ensure task-level accuracy remains sufficient; device NPUs/accelerators may need custom kernels.
- Longer context features without more memory
- Sectors: legal tech, code intelligence, research, insurance
- What to do: Use Q-K=V to double context length under the same VRAM budget (e.g., from 16k to 32k), or hold more concurrent sessions per GPU.
- Benefits: Enables retrieval-augmented generation with larger document batches, broad-context code completion, and larger contracts/records.
- Tools/workflows: Adjust tokenizer and server configs; update RAG chunking and re-ranking to exploit longer windows; add monitoring for latency vs. quality.
- Assumptions/dependencies: Compute still scales with O(n2) attention; choose batch sizes carefully to avoid latency spikes.
- Cost-optimized LLM SaaS and enterprise deployments
- Sectors: enterprise IT, SMB SaaS, finance, contact centers
- What to do: Migrate serving to Q-K=V-based models to halve KV cache; combine with GQA/MQA for more aggressive cost/performance options.
- Benefits: 40–50%+ serving cost reduction in memory-bound settings; improved GPU utilization.
- Tools/workflows: A/B test user satisfaction/latency; revise SLAs and pricing; auto-scaling policies based on reduced per-session VRAM.
- Assumptions/dependencies: Ensure fine-tuned domain tasks retain accuracy; some customers may prefer baseline quality over maximal compression.
- Efficient ViT-based classification/segmentation with Q=K-V or Q=K=V(+)
- Sectors: healthcare imaging, manufacturing, retail analytics, agriculture
- What to do: For non-causal vision tasks (ViT backbones, segmentation), use Q=K-V or Q=K=V with (X)+ 2D positional encodings to maintain performance while cutting projection parameters/compute.
- Benefits: Comparable accuracy on MNIST/CIFAR and competitive TinyImageNet results; reduced compute and memory for on-device/edge vision.
- Tools/workflows: Integrate into segmentation/classification pipelines (e.g., MONAI, mmsegmentation); deploy on embedded GPUs/NPUs.
- Assumptions/dependencies: (X)+ is suited to non-causal tasks; for causal or temporal vision tasks, prefer Q-K=V.
- Set anomaly detection on edge cameras (Q=K-V(+))
- Sectors: manufacturing QC, retail loss prevention, logistics
- What to do: Use Q=K-V(+2D positional encoding) for set-based anomaly detection pipelines (e.g., odd-one-out detection) to run locally at the edge.
- Benefits: Maintains accuracy with lower compute than QKV; supports real-time inspection with embedded hardware.
- Tools/workflows: Precompute CNN features (e.g., ResNet34) and stream to transformer; use on-device event triggers.
- Assumptions/dependencies: Best for non-sequential set inputs; validate on domain-specific datasets.
- Academic baselines and ablations for attention weight tying
- Sectors: academia, open-source research
- What to do: Adopt Q-K=V and Q=K-V as canonical baselines; analyze representational similarity between K and V; evaluate across domains.
- Benefits: Clear, reproducible trade-offs for studies of attention redundancy and low-rank behavior.
- Tools/workflows: Provide training scripts and configs (repo referenced in paper); publish ablations across sizes/datasets.
- Assumptions/dependencies: Ensure matched training settings to isolate projection effects.
- MLOps: capacity planning and infra refactoring for KV-light serving
- Sectors: platform engineering, DevOps, cloud
- What to do: Update schedulers and placement (Kubernetes/Slurm) to exploit lower per-session VRAM; implement mixed Q-K=V and baseline pools based on workloads.
- Benefits: Higher density per GPU, fewer nodes for same throughput, reduced carbon footprint.
- Tools/workflows: Observability for KV cache hit/miss; GPU memory fragmentation mitigation.
- Assumptions/dependencies: Memory savings most impactful when attention cache dominates VRAM usage.
- Encoder–decoder systems with selective projection sharing
- Sectors: speech recognition/translation, multimodal assistants
- What to do: Apply Q-K=V in self-attention blocks while retaining standard QKV or Q-K=V in cross-attention as appropriate.
- Benefits: Memory savings in core layers without sacrificing cross-attention flexibility.
- Tools/workflows: T5/FLAN-like training; per-layer attention variant configs.
- Assumptions/dependencies: Validate on sequence-to-sequence benchmarks; cross-attention may need standard QKV for best quality.
- Green AI and procurement quick wins
- Sectors: policy, sustainability, public sector IT
- What to do: Specify projection-sharing (Q-K=V) as a preferred configuration in RFPs for memory-bound AI services; require reporting on KV cache per user.
- Benefits: Lower energy/CO2 by cutting VRAM and node count; cost savings without major quality loss.
- Tools/workflows: Include efficiency metrics (cache/user, users/GPU) in vendor evaluation.
- Assumptions/dependencies: Requires vendors to (re)train with projection sharing; ensure downstream task parity via evaluation harnesses.
Long-Term Applications
These opportunities require further R&D, scaling studies (e.g., 7B–70B parameters), software ecosystem updates, or hardware support.
- Standardization of projection sharing in large-scale foundation models
- Sectors: general AI, cloud, open-source
- Vision: Establish Q-K=V (and Q-K=V+GQA/MQA) as first-class attention variants for 7B+ models, with checkpoints and inference kernels.
- Dependencies: Extensive evaluations on safety, instruction following, multi-lingual, and tool-use benchmarks; robust compatibility with flash-attention kernels and serving engines.
- Specialized hardware and kernels for single-cache attention
- Sectors: semiconductors, mobile/edge NPUs
- Vision: Design memory hierarchies and kernels optimized for K-only cache paths, exploiting reduced memory traffic and simpler dataflows.
- Dependencies: Vendor compiler support (TVM, XLA), custom tensor cores, co-design with FlashAttention-like algorithms.
- Dynamic projection-sharing policies per layer/task
- Sectors: AutoML, adaptive systems
- Vision: Learn when to tie K=V or keep QKV per layer, conditioned on domain/task or during fine-tuning; “Auto-tie” schedules with constraints.
- Dependencies: Robust training recipes, interpretability for safety review, per-layer gating overhead.
- Attention–SSM hybrids leveraging K=V recurrence view
- Sectors: research, time-series, speech, robotics
- Vision: Use the paper’s insight that kernelized attention under projection collapse admits recurrent/state-space formulations; design models with adaptive observations for ultra-long contexts.
- Dependencies: Stable training with softmax-free or kernelized attention; integration with SSMs (e.g., Mamba-like blocks).
- Cross-attention–aware projection sharing in multimodal systems
- Sectors: healthcare (radiology reporting), VLMs, education
- Vision: Apply projection sharing to self-attention while devising selective policies for cross-attention (e.g., preserving QKV where modality alignment is critical).
- Dependencies: Pretraining at scale on image–text, video–text; alignment and safety guardrails.
- Privacy-first, on-device professional assistants
- Sectors: healthcare, finance, legal, public sector
- Vision: Strongly private assistants running entirely on-device using Q-K=V+MQA variants; process PHI/PII locally.
- Dependencies: Verifiable privacy claims, secure enclaves, policy and compliance frameworks (HIPAA, GDPR), safety-tuned instruction data.
- Green AI policy and procurement standards
- Sectors: policy, ESG reporting
- Vision: Develop guidelines incentivizing projection/head sharing for memory-bound inference; include cache-per-token and users-per-GPU metrics in green certifications.
- Dependencies: Standard benchmarks and reporting methods; alignment with industry groups and regulators.
- Integration with softmax-free/sparse attention for extreme contexts
- Sectors: scientific computing, document analysis, retrieval
- Vision: Combine projection sharing with sparse patterns or softmax-free attention to reduce both cache and compute for 128k–1M token contexts.
- Dependencies: Stability/accuracy in ultra-long contexts, new training schedules, memory- and compute-efficient kernels.
- Automated compression planners in MLOps
- Sectors: platform engineering, DevOps
- Vision: Tools that pick Q-K=V, GQA/MQA levels, and KV quantization per model/deployment target, trading quality vs. cache automatically.
- Dependencies: Telemetry-driven optimization, per-tenant SLAs, guardrails for over-compression.
- Secure deployment in constrained or regulated environments
- Sectors: defense, critical infrastructure
- Vision: Reduced memory footprint enables running in secure enclaves and legacy hardware, lowering attack surface and deployment cost.
- Dependencies: Certification, formal verification of kernels, hardened runtime environments.
- Open-source ecosystem upgrades
- Sectors: community tooling
- Vision: First-class support for projection sharing in Hugging Face, vLLM, DeepSpeed, TensorRT-LLM; model hubs tagged with cache-per-token and projection-sharing metadata.
- Dependencies: Maintainer support, reproducible training scripts, broad benchmarking across tasks.
Key Assumptions and Dependencies Across Applications
- Training requirement: Projection sharing must be applied during training or fine-tuning; simply changing the inference kernel on a QKV model will not deliver benefits.
- Variant selection: For causal/sequential tasks, use Q-K=V; avoid Q=K-V and especially Q=K=V for language modeling. For non-causal vision/set tasks, Q=K-V or Q=K=V with 2D positional encoding ((X)+) can work well.
- Bottleneck profile: Benefits are largest in memory-bound scenarios (long context, high concurrency). Compute savings are modest because attention score computation (O(n2 d)) is unchanged.
- Scale generalization: Results validated up to 1.2B parameters/10B tokens; more testing at 7B–70B is prudent, though trends appear stable.
- Quality trade-offs: Small perplexity degradations do not always translate to downstream accuracy drops; nonetheless, evaluate task-specific metrics before production rollout.
- Compatibility: For maximum gains, combine with head sharing (GQA/MQA), KV quantization, and flash-attention-style kernels; ensure inference stacks support K-only caching paths.
Glossary
- 2D positional encodings: Positional features defined over pairwise token indices to inject directionality or structure into attention maps. Example: "we also explore asymmetric attention via 2D positional encodings."
- 2D sinusoidal positional encoding: A fixed, channelized sinusoidal feature map over the attention matrix used to break symmetry. Example: "We first construct a fixed 2D sinusoidal positional encoding P ∈ ℝ{n × n × m}."
- AdamW optimizer: A variant of Adam with decoupled weight decay that improves generalization. Example: "We used the AdamW optimizer with β1=0.9, β2=0.95, weight decay of 0.1, and a cosine learning rate schedule with linear warmup."
- adaptive observation: In state-space formulations, reading out the evolving state through an input-dependent observation mechanism. Example: "making linear attention a special case of a state-space model with adaptive observation"
- anomaly detection: Identifying outliers or odd items in a set, often treated as a set-processing task. Example: "as well as anomaly detection."
- attention-free models: Architectures that avoid explicit attention mechanisms while aiming to capture similar dependencies. Example: "attention-free models~\citep{zhai2021attentionfree} suggest that simpler mechanisms may suffice."
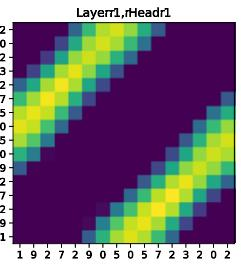
- asymmetric attention: Attention where query and key roles are distinct, enabling directionality (e.g., in sequences). Example: "This formulation preserves asymmetric attention maps"
- autoregressive generation: Token-by-token generation where past states are cached to avoid recomputation. Example: "During autoregressive generation, Transformers cache past key-value states to avoid recomputation."
- bfloat16: A 16-bit floating-point format commonly used for mixed-precision training. Example: "mixed precision (bfloat16)"
- blockwise schemes: Attention implementations that operate on blocks to improve efficiency and memory locality. Example: "Ring Attention and blockwise schemes"
- causal language modeling: Training setup where each token predicts the next, enforcing a causal (uni-directional) constraint. Example: "Causal language modeling already enforces asymmetry via the causal mask,"
- causal mask: A masking mechanism that prevents attention to future tokens in sequence models. Example: "causal mask"
- CosineWarmupScheduler: A training schedule with an initial warmup phase followed by cosine decay. Example: "CosineWarmupScheduler"
- cosine learning rate schedule: A learning-rate schedule that follows a cosine decay curve after warmup. Example: "a cosine learning rate schedule with linear warmup."
- cosine similarity: A measure of alignment between vectors or matrices used to assess representational similarity. Example: "cosine similarity (0.73 across layers)"
- cross-attention: Attention mechanism where queries attend to a different source (e.g., decoder attending to encoder outputs). Example: "Tasks requiring cross-attention---such as machine translation"
- decoder-only models: Transformer architectures that use only decoding blocks, common in modern LLMs. Example: "decoder-only models (prevalent in modern LLMs~\citep{brown2020language})"
- distributed data parallel (DDP): A framework for parallelizing training across multiple devices by synchronizing gradients. Example: "distributed data parallel (DDP) training"
- EleutherAI lm-eval-harness: A standardized benchmarking toolkit for evaluating LLMs on downstream tasks. Example: "using the EleutherAI lm-eval-harness"
- effective rank: An estimate of the dimensionality captured by a matrix, indicating redundancy or compression. Example: "effective rank (687 vs 702 out of 1024 dimensions)"
- Flash Attention: A memory-efficient attention algorithm that optimizes GPU utilization and reduces memory traffic. Example: "Flash Attention and other hardware-efficient implementations"
- Grouped Query Attention (GQA): A head-sharing mechanism where many query heads share fewer key-value heads to reduce cache size. Example: "Grouped Query Attention (GQA)"
- GQA-4: A configuration of GQA with 4 KV groups shared across more query heads, reducing cache memory. Example: "GQA-4 alone provides 75\% cache reduction"
- GQA-8: A configuration of GQA with 8 KV groups that often balances quality and cache reduction effectively. Example: "GQA-8 provides the best quality-efficiency balance"
- head sharing: Sharing key-value heads across multiple query heads to reduce memory and compute. Example: "head sharing (reducing the number of KV heads)"
- INT8/INT4 quantization: Low-bit numerical formats used to compress model weights or caches for memory savings. Example: "INT8 or INT4"
- kernelized attention: Attention reinterpreted via kernel feature maps, enabling recurrent or linear-time formulations. Example: "kernelized attention admits a purely recurrent formulation"
- KV cache: The stored keys and values from prior tokens during inference to avoid recomputation. Example: "KV cache as the primary bottleneck"
- KV cache footprint: The memory consumed by the KV cache during inference. Example: "reduces the KV cache footprint"
- linear attention: An attention variant with linear complexity in sequence length using kernel tricks or feature maps. Example: "linear attention a special case"
- Linformer: An efficient Transformer variant that approximates attention with low-rank projections. Example: "the Performer and Linformer"
- low-rank regime: A setting where attention computations effectively operate in a subspace of much lower dimension. Example: "attention operates in a low-rank regime"
- MACs: Multiply-accumulate operations, a proxy for computational cost. Example: "Inference computational cost (MACs) at sequence length 2048."
- mixed precision: Training with reduced-precision arithmetic to improve throughput and reduce memory. Example: "mixed precision (bfloat16)"
- Multi-Head Latent Attention (MLA): A method that compresses K and V into a shared latent vector to shrink cache size. Example: "Multi-Head Latent Attention (MLA)"
- Multi-Query Attention (MQA): A mechanism where multiple query heads share a single KV head to drastically reduce cache. Example: "Multi-Query Attention (MQA)"
- MultiStepLR scheduler: A learning-rate scheduler that decays the rate at predefined epochs or steps. Example: "with the MultiStepLR scheduler"
- multi-head self-attention: Parallel attention heads operating on different subspaces, then combined. Example: "multi-head self-attention"
- outer-product updates: Recurrent updates to an attention state using outer products of features. Example: "outer-product updates"
- efficiency-quality Pareto frontier: The trade-off curve showing optimal balances between efficiency and model quality. Example: "The efficiency-quality Pareto frontier clearly demonstrates this complementarity"
- perplexity: An intrinsic language-model metric measuring how well the model predicts a distribution over tokens. Example: "perplexity degradation."
- positional embeddings: Learned or fixed vectors encoding token positions to inform attention. Example: "2D positional embeddings in vision Transformers"
- positional encodings: Additive or multiplicative signals that inject position information into sequences. Example: "positional encodings."
- projection sharing: Constraining or tying Q, K, and/or V projections to reduce parameters and cache. Example: "projection sharing is complementary to head sharing"
- quantization: Reducing numerical precision to compress memory and accelerate inference. Example: "Quantization offers immediate compounding benefits"
- relative positional encodings: Position features defined relative to token pairs, improving generalization across lengths. Example: "relative positional encodings"
- residual connections: Skip connections that add inputs to outputs of layers to stabilize training. Example: "residual connections"
- Ring Attention: An efficient attention implementation that improves memory locality and scaling. Example: "Ring Attention"
- self-attention: Mechanism allowing each token to attend to others in the sequence to compute contextualized representations. Example: "The self-attention mechanism"
- softmax temperature annealing: Adjusting the softmax temperature during training to shape attention distributions. Example: "softmax temperature annealing"
- State Space Models (SSMs): Sequence models defined by latent states evolving over time with input-driven updates. Example: "State Space Models (SSMs)"
- symmetric attention: Attention where Q equals K, yielding symmetric score matrices that can limit directionality. Example: "symmetric attention maps"
- Vision Transformer (ViT): A transformer architecture applied to images by dividing them into patches. Example: "Vision Transformer (ViT) model"
- weight tying: Sharing parameters between components (e.g., K and V projections) to reduce redundancy. Example: "weight tying"
- windowed attention: Limiting attention to local windows to reduce quadratic complexity. Example: "windowed attention"
Collections
Sign up for free to add this paper to one or more collections.