- The paper presents a novel method that couples queries and keys to mitigate attention sinks and enhance language modeling performance.
- It demonstrates that the coupled dynamics reduce validation perplexity by up to 6.9% at moderate scales while achieving an 8× reduction in training variance.
- Findings reveal that the approach benefits domain-homogeneous corpora despite a slight computational overhead, highlighting clear design trade-offs.
Coupled Query-Key Dynamics for Attention: A Technical Review
Introduction
The paper "Coupled Query-Key Dynamics for Attention" (2604.01683) introduces a structural modification to Transformer attention mechanisms, employing coupled dynamical systems to jointly evolve queries (Q) and keys (K) prior to dot-product scoring. This method outperforms standard independent Q/K projections in terms of language modeling perplexity and training stability at small to medium parameter regimes. The study addresses both the mechanistic motivation for coupling and comprehensive ablations to dissect the origins and boundaries of the empirical improvement.
Methodology and Architectural Innovations
Standard Transformers execute attention by projecting inputs to query and key spaces independently, which recent analyses associate with representational collapse, attention sinks, and increased spectral gap as model depth and sequence length scale. The proposed "coupled QK dynamics" alters this protocol by evolving Q and K through a shared parametric update rule:
qt+1=qt+Δt⋅kt,kt+1=kt+Δt⋅f(qt)
where f is a learned per-head two-layer MLP with SiLU activation and Δt is a learned step-size. This pre-attention enrichment couples Q/K trajectories, inspired by Hamiltonian mechanics but shown empirically to not rely on symplecticity; a non-symplectic Euler update achieves identical performance. This mechanism introduces only a minor parameter and computational overhead.
The coupled dynamics are employed for multiple integration steps (typically n=1 suffices), with ablations demonstrating that neither increased step count nor adherence to symplectic integration are material—the advantage originates directly from Q/K coupling.
Empirical Results
On the WikiText-103 benchmark at 60M parameters, coupled QK dynamics achieves 22.55--22.62 validation perplexity—a 6.6–6.9% reduction over standard attention (24.22). Increments in parameter count are minimal (+0.11%). Extensive ablations confirm that this improvement arises solely from coupling, not increased model capacity, as an MLP-only non-coupled baseline matches neither the perplexity nor training variance.
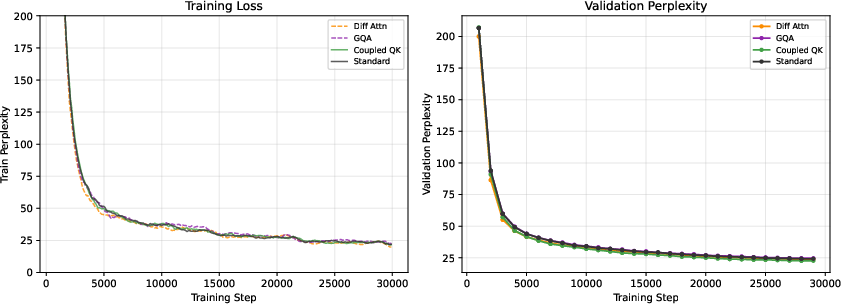
Figure 1: Training and validation perplexity versus step for the 60M WikiText-103 model. Coupled QK dynamics diverges favorably from other mechanisms from early stages.
At 150M parameters, the benefit persists, with coupled QK dynamics reducing perplexity to 20.12 (−6.7% vs. standard), outpacing Differential Attention (21.11) and GQA (21.87).
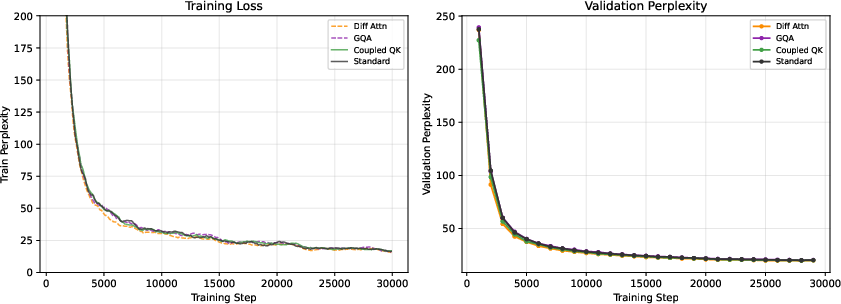
Figure 2: Convergence of training and validation perplexity for 150M models. Coupled QK maintains a superior lead throughout training.
At 350M parameters, the advantage narrows to −1.0% compared to baseline, and Differential Attention surpasses coupled QK (18.93 vs. 19.35). This scaling trend indicates divergence in the efficacy of pre-scoring versus post-scoring modifications as model size increases.
Corpus Sensitivity
The coupled QK benefit is highly corpus-dependent. It yields strong improvements on structurally coherent, single-domain corpora (WikiText-103, PubMed abstracts) but degrades perplexity by 10.3% on heterogeneous web-scale text (OpenWebText). No downstream benefit is observed on GLUE benchmarks, and the method's effectiveness appears tightly linked to structural uniformity within the training corpus. This is hypothesized to reflect the learned coupling network's assumption of a global coupling dynamic, which is effective only in coherent environments.
Structural and Behavioral Analysis
Coupled QK dynamics not only enhances attention matrix rank in most layers but also mitigates the entropy collapse and attention sink phenomena found in standard attention heads. In attention pattern visualizations, coupled QK yields more diverse inter-head and inter-layer attention behaviors.
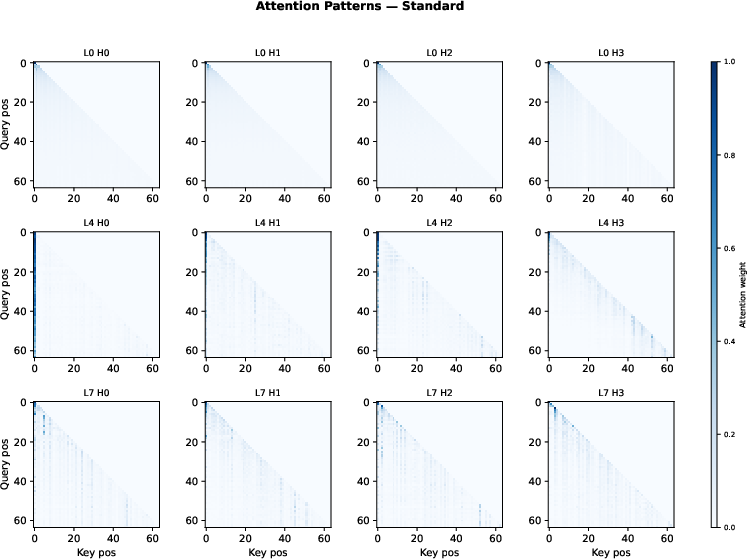
Figure 3: In standard attention, later layers exhibit an attention sink at position 0, dominating all heads and reducing representational diversity.
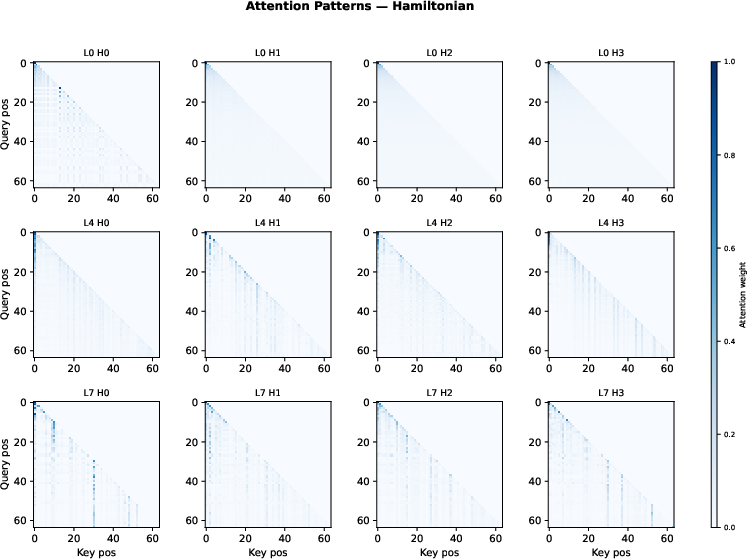
Figure 4: Coupled QK dynamics produce less extreme attention sinks and more prominent off-diagonal, content-driven patterns across heads and layers, evidencing richer QK interaction.
An explicit ablation against MLP-capacity-matched non-coupling baselines reveals an 8× reduction in training variance with coupled QK, underscoring the inductive bias and optimization stability conferred by the coupling mechanism.
Sample Efficiency and Overhead
Although coupled QK dynamics introduce a moderate compute overhead (0.82× throughput of baseline attention), a compute-matched experiment shows that standard attention requires 2.4× more tokens to reach equivalent perplexity, indicating coupled QK is a substantial sample-efficiency improvement mechanism.
Comparative Analysis and Theoretical Context
Unlike post-scoring methods (e.g., Differential Attention), which offer robustness across heterogeneous corpora via noise cancellation, coupled QK operates in a pre-scoring regime, augmenting QK states directly in a corpus-sensitive manner. This distinction provides actionable design guidance: coupled QK should be preferred for domain-homogeneous corpora (encyclopedic, scientific text, code) while post-scoring methods are preferable for broad, heterogeneous data.
Implications for Theory and Practice
The demonstrated efficacy of coupled QK dynamics at small and medium scales, and its corpus sensitivity, elucidate both the power and limits of structural modifications to attention. The results emphasize that the architecture of Q/K interaction—rather than specific properties such as symplecticity or integration fidelity—is the critical factor in achieving empirical gains. Future avenues include combining pre-scoring (coupled dynamics) and post-scoring (Differential Attention) paradigms, as well as clarifying the molecular basis of variance reduction and optimization stability induced by structural coupling.
Conclusion
Coupled query-key dynamics constitute a robust mechanism for enhancing Transformer attention by enabling Q and K to co-evolve through learnable joint dynamics prior to scoring. This method yields consistent perplexity improvements and stability advantages on domain-uniform corpora at moderate model scales, with sample efficiency gains that are especially valuable when data or compute is constrained. The core insight—that enriching QK interaction space is more consequential than any particular mathematical structure of that enrichment—provides practical guidance and theoretical direction for future design and analysis of attention mechanisms. The corpus dependence observed delineates clear application boundaries, while scaling trends suggest diminishing returns compared to alternative strategies at very large parameter counts.
References
See (2604.01683) for all references and extended analysis.