Physics-Guided Policy Optimization with Self-Distillation
Published 2 Jun 2026 in cs.LG and cs.AI | (2606.03620v1)
Abstract: Self-distilled policy optimization (SDPO) has become a popular paradigm for LLM post-training, where a model learns from its own predictions conditioned on privileged information. SDPO, however, is sensitive to how much each update step should be trusted: corrections from a self-teacher can be highly informative on some batches and misleading on others, and applying them uniformly with a fixed step size can destabilize training. Drawing inspiration from viscous-fluid dynamics and formalizing the analogy at the SDE level, we propose Physics-Guided Policy Optimization (PGPO), which introduces an information-modulated step-size multiplier derived from a mutual-information estimate between the student's predictions and the feedback-conditioned teacher. We show that this modulation preserves the order-1 weak-approximation guarantees of vanilla SGD, and incurs negligible overhead per iteration. We evaluate PGPO on the Science-QA dataset, where it outperforms SDPO on 3 of the 4 domains with gains of up to +4.5 points, while remaining stable in a setting where SDPO collapses late in training.
The paper introduces PGPO, an approach that adapts step sizes via a viscosity mechanism guided by mutual information to address credit assignment issues in self-distilled models.
The paper demonstrates significant empirical improvements over SDPO, with notable gains in Chemistry and Materials Science performance metrics.
The paper grounds its methodology in stochastic differential equations, ensuring weak-approximation guarantees while mitigating instability during late-stage training.
Physics-Guided Policy Optimization with Self-Distillation: A Technical Analysis
Motivation and Problem Setup
Self-distilled policy optimization (SDPO) is a widely-adopted approach for post-training large autoregressive LLMs, leveraging privileged teacher signals produced by the model itself. While SDPO offers efficient token-level supervision and eliminates dependence on external teacher models, it is inherently unstable during late-stage training. Uniform step sizes can amplify misleading self-teacher corrections, corrupting learned behaviors and exacerbating the credit assignment problem. These instabilities stem from the inability of SDPO to differentiate between highly informative and spurious corrections, resulting in model collapse under extreme token-level rewards.
The paper addresses these deficiencies by introducing Physics-Guided Policy Optimization (PGPO), rooted in an analogy with viscous-fluid dynamics. PGPO posits that optimization can be viewed as a particle traversing a medium whose viscosity adapts according to the informativeness of teacher feedback, quantified via a batch-level mutual information signal. This adaptive mechanism offers a principled solution to the credit assignment dilemma, modulating step sizes to preserve signal fidelity and suppress noise.
Theoretical Foundations
The stochastic gradient descent (SGD) dynamics are formalized through stochastic differential equations (SDEs), with the drift term corresponding to the gradient of the empirical loss and the diffusion term capturing batch-induced stochasticity. PGPO introduces a physics-guided multiplier ρ(Ik) applied to the learning rate, with Ik representing the mutual information between model predictions and teacher feedback. The modulated update rule is:
θk+1=θk−η⋅ρ(Ik)⋅∇L(θk)
where ρ(Ik)=min(exp(αIk),ρmax) ensures bounded adaptation.
The weak-approximation guarantees are detailed, showing that PGPO remains consistent with SDE modeling in the weak sense (order-1 convergence). This formalizes that PGPO’s stochastic process tracks that of standard SGD and SDPO as η→0, justifying the physical analogy and ensuring that adaptation does not destabilize the optimization trajectory.
PGPO Algorithm and Implementation Details
PGPO wraps the SDPO paradigm in an adaptive viscosity mechanism. For each mini-batch, mutual information Ik is computed using cross-entropy estimates between student and teacher outputs. The multiplier ρ(Ik) is then applied to the gradient update, with sensitivity parameter α and maximum cap ρmax controlling the aggressiveness and safety of adaptation. The method is computationally efficient, incurring only O(1) additional overhead per training iteration due to reuse of forward computation.
Hyperparameters are largely inherited from standard SDPO setups, with the Qwen3-8B checkpoint serving as the initialization and Science-QA providing domain benchmarks. Sensitivities of Ik0 are probed in ablations.
Empirical Results
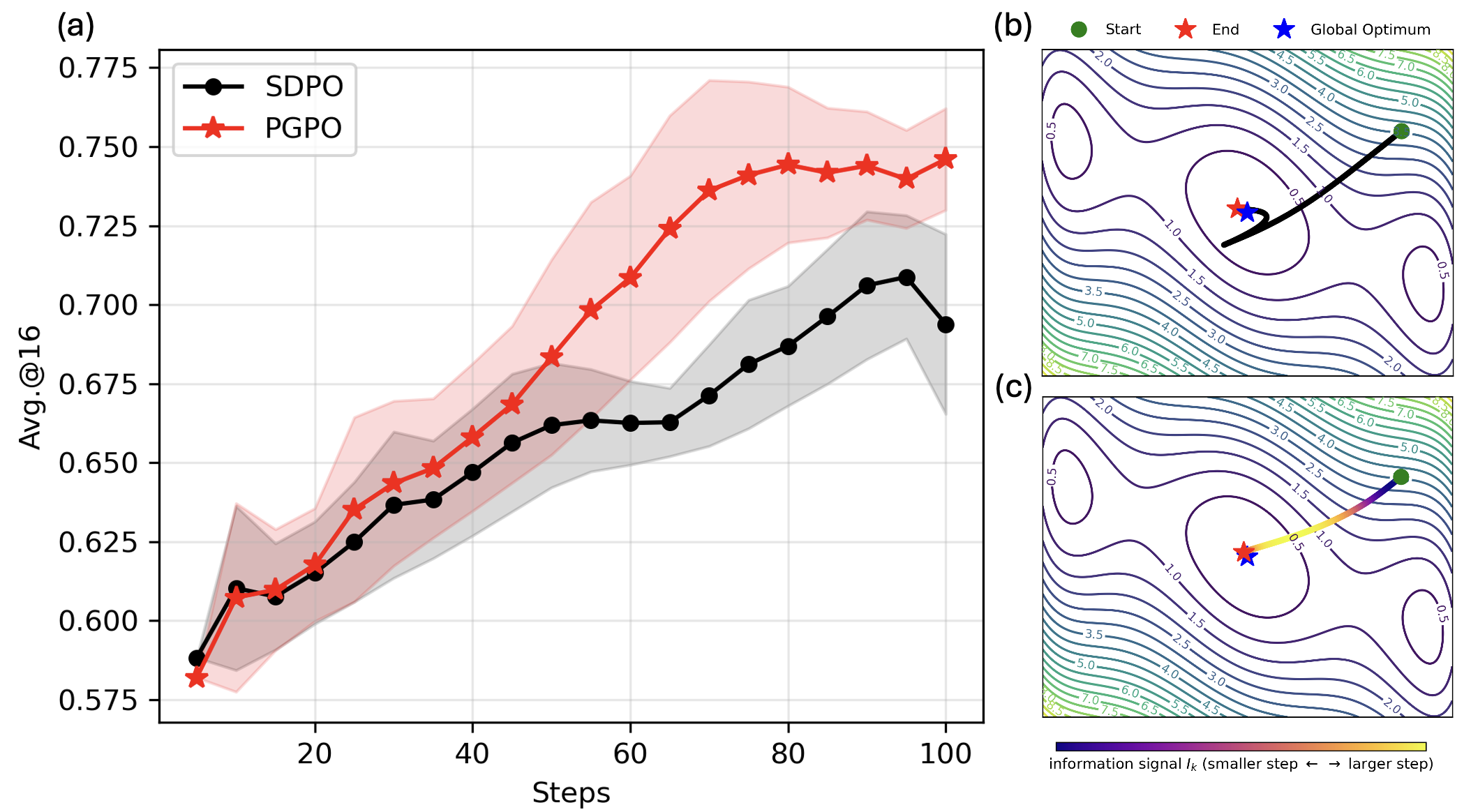
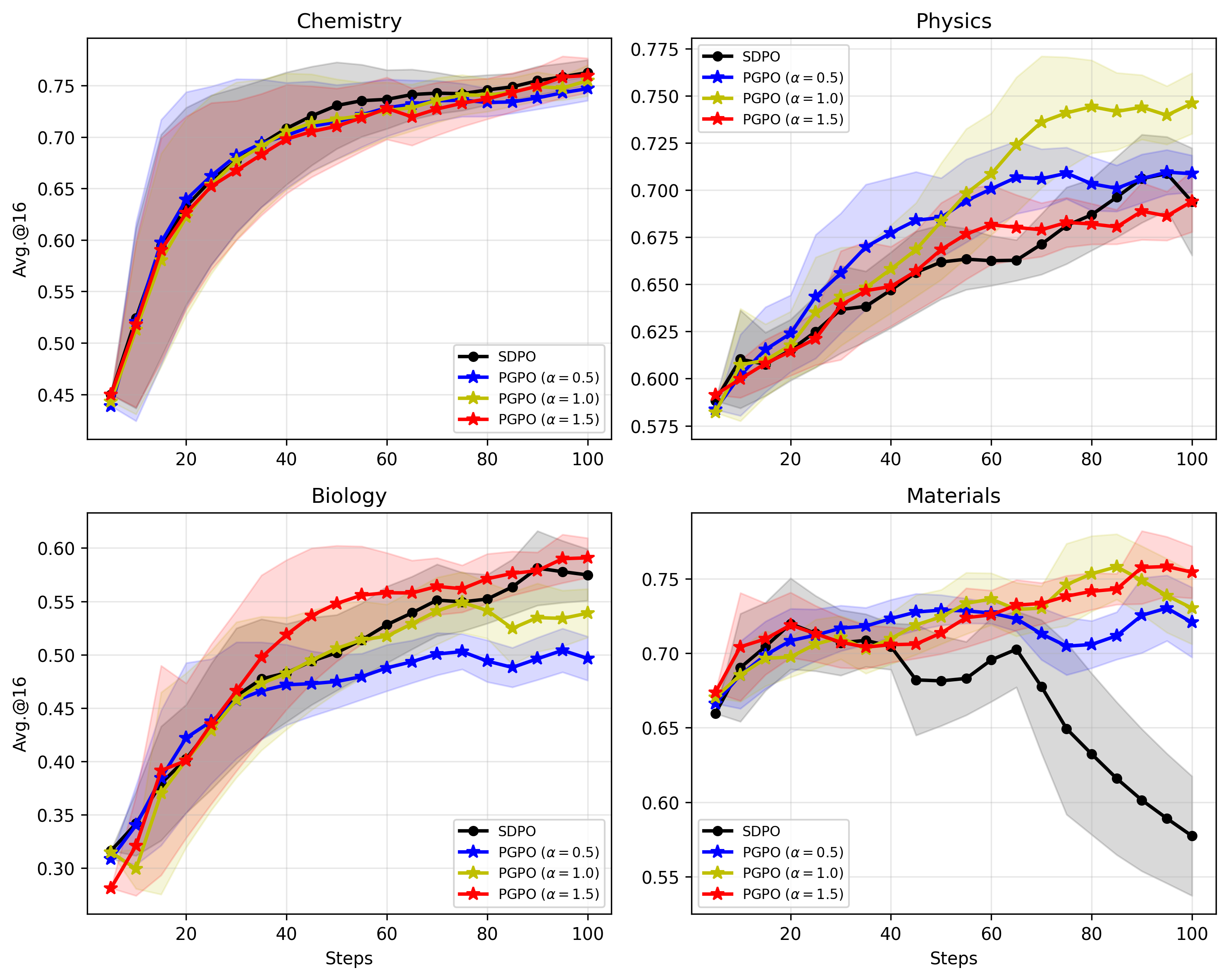
PGPO demonstrates robust improvements over SDPO across multiple domains of the Science-QA dataset. Gains of +3.45 (Chemistry) and +4.51 (Materials Science) in avg@16 metric signal substantial practical benefits, with a smaller improvement in Physics (+0.51) and a minor drop in Biology (-0.37), highlighting domain-specific sensitivity.
The rationale behind PGPO’s improvements is illustrated in the paper by contrasting uniform step sizes of SDPO versus information-modulated steps in PGPO. As experiments show, PGPO consistently stabilizes the final stages of training, mitigating collapse observed in SDPO, particularly in challenging tasks.
Figure 1: PGPO achieves superior avg@16 performance in Physics compared to SDPO; subfigures illustrate the difference between uniform and information-guided step scaling.
A comprehensive ablation reveals the sensitivity of PGPO to the Ik1 parameter, with domain performance varying such that optimal Ik2 is domain-dependent. This suggests the need for finer-grained and possibly per-token modulation in future work.
Figure 2: Ablation study of PGPO versus SDPO across Chemistry, Physics, Biology, and Materials, evidencing PGPO's domain-dependent performance advantages.
Practical and Theoretical Implications
PGPO addresses the fundamental challenge of credit assignment in self-distilled optimization, enabling more reliable post-training for LLMs without the need for external teacher models. The physical intuition of viscosity-guided adaptation aligns with broader trends in adaptive optimization, connecting stochastic process theory with domain-specific signal reliability.
Practically, PGPO provides a template for integrating information-theoretic uncertainty measures into step-size adaptation, offering paths toward greater training stability, especially in settings with highly variable feedback signal quality.
Theoretically, PGPO reinforces the SDE-based analysis of adaptive optimization algorithms, showing that careful drift modulation preserves weak-approximation guarantees and does not violate foundational convergence results.
Future Directions
Future work may explore token-level or sequence-level signal modulation, adaptive schedules for the sensitivity parameter Ik3, and automatic tuning mechanisms. Extending the approach to other self-improving paradigms and integrating environmental reward anchoring represents additional directions.
Performance variations in Biology suggest that signal informativeness may require domain-specialized calibration, potentially leveraging more granular uncertainty estimation.
Conclusion
Physics-Guided Policy Optimization (PGPO) introduces an information-modulated viscosity framework for step-size adaptation in self-distilled policy optimization, enhancing stability and performance in LLM post-training. Empirical evidence supports PGPO’s superiority over SDPO across several scientific reasoning domains. The formulation is theoretically grounded and practically efficient, providing a principled pathway toward more reliable credit assignment and stable iterative self-improvement in large-scale LLMs.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.