See Less, Specify More: Visual Evidence Budgets for Generalizable VLAs
Abstract: Generalization remains a central bottleneck for vision-language-action (VLA) models: under distractors, appearance shifts, and semantically similar tasks, the policy must often infer local execution details from coarse instructions while also deciding which parts of the image matter for control. We present S2 (See Less, Specify More), a framework for improving VLA generalization by training the executor under a cleaner interface. Specify More preserves the original instruction as a stable high-level goal while relabeling each trajectory into refined trajectory- and subtask-level language that disambiguates the current execution mode. Unlike native attention, See Less imposes an explicit visual evidence budget, training the executor to act from task-sufficient evidence rather than unconstrained visual context, without any region or mask annotation. This interface lets the executor follow detailed guidance without relying on distracting visual patches or resolving avoidable ambiguity on its own, and it remains compatible with off-the-shelf VLM planners through in-context learning. Across our main evaluation settings, S2 improves overall generalization metrics by changing the executor's learning problem: coarse instructions induce avoidable supervision aliasing, goal-preserving local guidance outperforms instruction replacement in our main ablations, and explicit evidence budgeting reduces dependence on broad visual context beyond efficiency considerations. Across eight real-robot tasks on TX-G2 (an AgiBot G2-compatible variant) and HSR, S2 raises mean subtask success from 54.2% to 79.0% over pi0.5. Together, these results suggest that VLA generalization improves when the executor is trained to act from informative local guidance and task-sufficient visual evidence, rather than recovering both from weak supervision.










Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching robots to follow instructions better in the real world. The authors focus on a kind of robot brain that uses vision (seeing), language (reading instructions), and action (moving) together—often called a VLA model. Their main idea, called S2 (See Less, Specify More), is simple:
- Specify More: give the robot clearer, step-by-step guidance about what to do right now.
- See Less: show the robot only the parts of the camera view that matter for the current step.
By doing both, the robot stops getting confused by distractions (like extra objects) and vague instructions. It learns to act based on the right clues and clearer directions.
What questions did the researchers ask?
The paper explores three easy-to-understand questions:
- Do vague instructions (like “put the cup on the table”) make robots guess too much about the exact moves they should take?
- If we add helpful details to the instructions, is it better to replace the original goal entirely, or keep the original goal and add focused step-by-step hints?
- Can we train the robot to pay attention only to the small parts of the image that matter, even without telling it exactly which pixels are important?
How did they do it?
Think of the robot team as having two roles:
- A planner (like a coach) that reads the high-level goal and gives local, step-by-step guidance.
- An executor (like a driver) that actually moves the robot arm(s) and completes the task.
S2 improves the “conversation” between the coach and the driver:
- Specify More: clearer, local instructions
- Instead of only using a broad goal (for example, “place the mug in the rack”), the system adds precise substeps that match what the demonstration shows (like “grasp the mug by the handle from the right” then “place it on the top left slot”).
- Importantly, the original goal is kept. The robot sees both the main goal and the current detailed step. This keeps the task identity clear while removing ambiguity about “how” to execute the current phase.
- See Less: limit visual clutter with a “visual evidence budget”
- The robot’s camera sees a lot, but only a small portion is relevant (like the mug handle, the rack slot, or the gripper’s contact area).
- The authors set a “budget,” which is like saying: “You can only pay attention to a small fraction of the image—choose wisely.”
- The robot learns for itself which parts of the image help it succeed (no human-drawn boxes or masks). It figures this out during training by noticing which visual bits actually lead to good actions.
Technical idea in everyday words:
- Picture the robot’s camera view as a poster made of many tiles.
- The robot gets a limit on how many tiles it can focus on (the “budget”).
- While learning, it tries different choices. If it still completes the step successfully, those chosen tiles were probably the right evidence. Over time, it learns to highlight the tiles that matter—like the target object, the contact point, or the destination spot—and to ignore the rest.
Training and deployment:
- During training, the robot learns under this cleaner interface: high-level goal + current subtask + limited, focused vision.
- At test time, an off-the-shelf LLM (the “coach”) generates the local step-by-step hints, and the robot (the “driver”) executes them with its learned focus.
What did they find, and why does it matter?
Main results, explained simply:
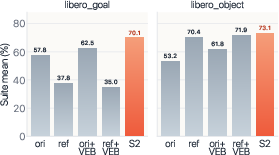
- Clearer steps beat vague goals: Robots trained with both the original goal and precise, local instructions performed better than those given only vague goals or only replacement instructions. Keeping the main goal while adding detailed steps avoids confusion and preserves the true task.
- Seeing less can be better: Limiting what the robot attends to made it more robust to clutter, distractions, and changes in appearance. It stopped relying on unhelpful background details that don’t generalize.
- Strong gains across tasks: On eight real-robot tasks (using TX-G2 and HSR robots), the average success on subtasks jumped from about 54% to 79%. That’s a big improvement for practical, real-world manipulation.
- Works with common planners: The approach doesn’t lock you into a specific “coach” model. Different off-the-shelf language planners still worked well, suggesting the method is flexible.
Why it matters:
- Real homes and workplaces are messy and unpredictable. Robots that only succeed in clean lab setups aren’t very useful.
- Teaching robots to follow clear steps and focus on the right visual clues makes them more reliable in the wild.
What’s the bigger impact?
- Better generalization: Robots become less sensitive to small changes—like different object colors, extra items on the table, or slight camera shifts.
- Safer and simpler training: The robot learns what to focus on without extra labels or human-drawn regions, reducing the need for time-consuming annotations.
- Modular design: You can swap in different planners (LLMs acting as coaches) without retraining the executor from scratch, making systems easier to upgrade.
- Path to real-world helpers: As robots get better at ignoring distractions and following precise guidance, they become more trustworthy for everyday chores—like sorting laundry, placing dishes, or handling groceries.
Key terms in plain language
- VLA model: A robot system that connects what it sees (vision), what it’s told (language), and what it does (action).
- Planner-executor split: The “coach” decides the steps; the “driver” executes them smoothly.
- Specify More: Add precise, right-now instructions to make the current step unambiguous, while keeping the original goal.
- See Less (visual evidence budget): Give the robot a limit on how much of the image it can rely on, so it learns to focus on the truly important bits.
In short, the paper shows that robots do better when they receive clearer step-by-step guidance and are trained to pay attention only to the important parts of what they see. This combination makes them more reliable and adaptable in real-world settings.
Knowledge Gaps
The paper leaves the following concrete gaps, limitations, and open questions for future work:
- Planner error handling and detection: the executor assumes subtask guidance is correct; no mechanism exists to detect, reject, or recover from incorrect or stale planner outputs. Evaluate sensitivity to planner mistakes and develop verification/replanning loops.
- Subtask boundary noise: training uses hard, frame-aligned subtask spans; boundary errors become supervision noise. Explore soft/latent alignment (e.g., HMMs, CTC-style losses) or boundary-uncertainty modeling.
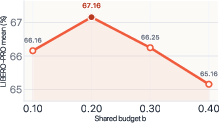
- Fixed, global evidence budgets: budgets ρb, ρw are constant across tasks, subtasks, and time. Investigate adaptive or learned budgets conditioned on task, subtask, scene complexity, or model uncertainty.
- Mean-based budget regularizer: penalizing only the mean gate value can be satisfied by diffuse low gates. Compare to top-K constraints, L1 sparsity, hard-concrete gates, differentiable token selection, or KL-to-target-sparsity objectives.
- Temporal evidence selection: masks are per-frame; temporal sufficiency is not modeled. Study spatiotemporal evidence budgeting over video tokens and memory-aware gates.
- Cross-modal budgeting: only visual tokens are gated; proprioception and other sensors are untouched. Test cross-modal evidence budgeting and its impact on robustness.
- Interpretability and causal validation: mask quality is shown qualitatively; no causal tests. Perform counterfactual patch swaps, targeted occlusions, and do-interventions to quantify causal alignment of selected evidence.
- Efficiency and compute: gating does not reduce compute (tokens are scaled, not pruned). Measure latency/throughput, and explore compute-aware token pruning that preserves performance.
- Planner diversity and robustness: only two planners (Kimi K2.5, GPT-5.4 nano) are evaluated. Systematically test a broader set of planners and styles, and quantify sensitivity to verbosity, formatting, and error rates.
- Reliability of VLM relabeling: the QC process, error rates, and inter-rater agreement for trajectory/subtask relabeling are unspecified. Quantify relabeling noise and release audit tools or gold subsets.
- Phase-vocabulary rigidity: a fixed approach/engage/execute/disengage/transit schema may not fit all tasks. Explore learned subtask grammars and adaptive granularity without hand-fixed phases.
- Safety considerations: evidence budgeting could suppress safety-critical cues (e.g., human hands). Add “always-keep” channels or safety priors, and evaluate in human-in-the-loop scenarios.
- Failure mode taxonomy: beyond aggregate metrics, the paper lacks detailed failure categorization. Provide per-perturbation error analyses to target the next set of interface or gating changes.
- Cross-embodiment and sensor setups: results are on TX-G2 and HSR with base/wrist RGB. Test broader embodiments, camera placements, depth/TiF sensors, and sim-to-real transfer.
- Sample efficiency: it is unclear if S2 reduces demonstration requirements. Run learning-curve studies to measure data efficiency gains from the interface.
- RL fine-tuning: only supervised flow-matching is used. Investigate RL/offline RL to optimize gates and actions jointly under success/reward signals.
- Robustness benchmarks: clutter and perturbations are demonstrated but not standardized. Build systematic robustness suites (lighting, distractors, moving obstacles, camera shifts) with quantitative mask/effectiveness metrics.
- Planner–executor co-adaptation: the interface is fixed; no co-training is attempted. Study iterative alignment (schema constraints, self-check prompts, feedback tokens) to reduce mismatches.
- Uncertainty and confidence use: gate scores and instruction-following uncertainty are not calibrated or used. Calibrate them and trigger replans, higher budgets, or sensor shifts when confidence is low.
- Quantitative mask evaluation: no metricized mask quality is provided. Annotate a small subset with relevance labels or use weak labels to compute precision/recall/IoU vs. ground-truth-relevant regions.
- Selective perception baselines: comparisons to token-selection/pruning methods (TokenLearner, DynamicViT, ToMe) or object-centric baselines are missing. Add apples-to-apples ablations.
- End-to-end performance: main results emphasize subtask success; full E2E success, time-to-completion, and compounding-error analyses are deferred. Report and analyze them centrally.
- Compute/memory footprint: additional gate heads and dual-path losses may add overhead. Provide detailed training/inference cost profiling and scaling behavior.
- Theoretical underpinnings: claims about reduced spurious correlations lack formal analysis. Develop information-theoretic or generalization bounds for evidence budgeting under distribution shift.
- Gate placement/design: only single-layer, token-wise gates are studied. Evaluate gating at different layers, multi-layer gating, channel-wise gates, and per-attention-head gating.
- Budget scheduling: the temperature and annealing schedules are heuristic. Study schedule sensitivity, curriculum strategies, and constrained optimization enforcing exact budgets.
- Noise in refined instructions: robustness to mis-specified or contradictory s_i is untested. Train with synthetic noise and evaluate recovery strategies (e.g., instruction smoothing or majority voting).
- Bimanual decisions: arm selection improvements are observed but not formalized. Introduce explicit arm-selection tokens or planner-side commitments and measure their effect.
- Conflict resolution in language: behavior when g and s_i disagree is unspecified. Define conflict-resolution policies (e.g., prioritize g, request replan) and evaluate outcomes.
- Long-horizon scaling: cadence for refreshing s_i, memory limits, and drift over many subtasks are not studied. Analyze instruction update frequency, memory mechanisms, and cumulative error.
- Reproducibility and release: clarity on releasing code, relabeled language, masks, and prompts is missing. Provide artifacts and scripts to reproduce relabeling, training, and evaluation.
Practical Applications
Immediate Applications
Below are specific, deployable ways to use the paper’s “See Less, Specify More (S2)” framework today, grounded in the paper’s real-robot results (TX-G2, HSR) and benchmark gains. Each bullet links to sectors, outlines plausible tools/workflows, and notes key dependencies or assumptions.
- Manufacturing and assembly robotics — Robust pick-and-place, kitting, and light assembly under clutter and appearance shifts by pairing a high-level VLM planner with an S2-trained executor that follows goal-preserving local guidance and learned visual evidence budgets (VEB).
- Tools/Workflows: S2 fine-tuning wrapper for existing VLAs (e.g., pi0.5/OpenVLA), trajectory/subtask relabeling pipeline, planner prompt templates, budget-tuning and mask visualization.
- Dependencies/Assumptions: Dual-view cameras (base+wrist) or comparable perception; a competent off-the-shelf VLM planner for local instruction generation; task-specific prompting; basic robot safety protocols.
- Warehouse and logistics automation — Bin picking, sorting, and packing with improved generalization to new SKUs and shelf layouts by shrinking executor ambiguity (disambiguated subtasks) and suppressing irrelevant visual cues (evidence budgeting).
- Tools/Workflows: “Planner shim” that converts WMS tasks into refined subtask prompts; quick in-context planner updates for new product lines; VEB dashboards for QA.
- Dependencies/Assumptions: Clean subtask taxonomies; reliable subtask timing/alignment; planner accuracy for local guidance; periodic relabeling of demos on new SKUs.
- Service and home-assist robots — More reliable household tasks (e.g., decluttering, dish/basket sorting, putting away items) under heavy distractors, leveraging S2’s improved subtask success and clutter robustness.
- Tools/Workflows: Mobile manipulator with S2 executor; phone app to set high-level goals; in-context prompts to generate subtasks; on-device gate heads for VEB.
- Dependencies/Assumptions: Safety in proximity to humans/pets; privacy safeguards; basic home scanning or initial keyframe capture for planner grounding.
- Hospital operations and logistics — Fetch-deliver, restocking, and room prep where task identity is preserved (hygiene-critical) and local guidance removes ambiguity (route, hand choice, placement strategy) while VEB limits reliance on irrelevant scene factors.
- Tools/Workflows: “Nurse-assist” mode mapping clinical orders to subtask prompts; S2 executor tuned to hospital carts/shelves; evidence-mask auditing for safety QA.
- Dependencies/Assumptions: Institutional approvals; sterilization workflows; predictable subtask vocabularies; planner that avoids hallucinating unsupported clinical steps.
- Bimanual manipulation — Tasks requiring arm selection or handoff (e.g., basket sorting, folding) benefit from S2’s goal-preserving local guidance and VEB to focus on contact-local cues and destination context.
- Tools/Workflows: Bimanual S2 training on TX-G2-like platforms; per-view budgets for wrist/base cameras; relabeling that encodes which arm executes each subtask.
- Dependencies/Assumptions: High-quality demonstrations with clear arm usage; tuned budget hyperparameters; synchronized end-effector sensing.
- Field robotics (agriculture, outdoor maintenance) — Harvesting, pruning, or pick-and-place in visually variable environments by reducing executor’s dependence on nuisance appearance and emphasizing task-sufficient evidence.
- Tools/Workflows: Seasonal re-prompting of planner; lightweight gate heads for edge inference; small-budget VEB to mitigate background variation.
- Dependencies/Assumptions: Weather-resistant sensors; sufficient initial demos; periodic planner validation in novel scenes.
- Retail restocking and store operations — Shelf-facing manipulation amid dense distractors; VEB helps ignore signage/branding while following subtask-level instructions (e.g., exact placement region).
- Tools/Workflows: Subtask schema aligned with planogram; evidence mask visualizer for compliance audits; rapid planner prompt updates for promotions.
- Dependencies/Assumptions: Consistent shelf geometry; reliable image capture of target zones; minimal planner errors.
- Software and GUI automation (RPA) — Apply the “See Less” and “Specify More” ideas to screen-based agents: refine coarse goals into step-level actions and gate visual tokens to relevant UI regions to improve robustness across themes/skins.
- Tools/Workflows: Screenshot token-gating module; stepwise prompts that preserve task identity; UI element-focused evidence budgets.
- Dependencies/Assumptions: Adapt VEB to GUI tokens; sufficient labeled demonstrations; reliable OCR/UI detection; data privacy compliance.
- Academic research and robotics education — Better datasets and benchmarks via automatic goal-preserving trajectory/subtask relabeling; ablation studies on generalization vs. visual budgeting; reproducible planner-executor modularity.
- Tools/Workflows: Open-source relabeling scripts; shared prompt libraries; gate schedules and budget sweeps; evaluation on LIBERO/CALVIN/LIBERO-PRO.
- Dependencies/Assumptions: Access to an off-the-shelf VLM; compute for fine-tuning; careful QC of relabeled language to avoid drift.
- Policy debugging, QA, and interpretability — Use learned evidence masks to audit what the robot “looked at” when acting, improving troubleshooting and safety case documentation.
- Tools/Workflows: “Evidence budget dashboard” showing mask overlays vs. native attention; failure replay filtered by subtask.
- Dependencies/Assumptions: Logging infrastructure; human-in-the-loop diagnostics; governance processes for incident review.
- Edge deployment efficiency (secondary benefit) — Although VEB’s intent is robustness, learned token suppression can reduce effective vision compute in some pipelines without bespoke token-pruning logic.
- Tools/Workflows: Token throughput monitors; budget-aware batching; fallback to ungated path if performance drops.
- Dependencies/Assumptions: Budget carefully tuned per scene/view; performance guardrails; on-device profiling.
- Cross-planner interoperability — Standardize on S2’s goal-preserving local language interface so different planners (e.g., Kimi K2.5 vs. GPT-5.4 nano) can be swapped without retraining the executor.
- Tools/Workflows: “Planner adapters” that normalize subtask schema; regression tests across planners; prompt-versioning.
- Dependencies/Assumptions: Stable subtask taxonomy; consistent in-context examples; interface governance to prevent drift.
Long-Term Applications
These applications require additional research, scaling, or standardization—e.g., broader datasets, stronger safety cases, or productization of S2 tooling and interfaces.
- Cross-embodiment generalist executors — Train large, backbone-agnostic S2 executors across many robots and domains, improving out-of-distribution generalization via standardized interfaces.
- Tools/Products: Multi-robot datasets with trajectory/subtask relabels; S2 APIs; cloud-scale training.
- Dependencies/Assumptions: Significant data/compute; shared subtask vocabularies across embodiments; robust planner generalization.
- Regulatory and standards frameworks — Define interface and interpretability standards for task-identity preservation and visual evidence budgets in safety-critical robotics.
- Tools/Products: Compliance test suites; “VEB audit” certification; standardized mask logging formats.
- Dependencies/Assumptions: Industry and regulator consensus; evidence that budgets correlate with risk reduction.
- Autonomy with “no-code” task setup — Factory and warehouse lines configured via language + local guidance (planner) with S2 executors, minimizing reprogramming for new SKUs or fixtures.
- Tools/Products: Task setup studios; schema-driven prompt packs; rapid relabeling wizards.
- Dependencies/Assumptions: High planner reliability; robust subtask alignment under layout changes; fallback supervisors.
- Surgical and interventional robotics microtasks — Use S2-like interfaces (tight task identity and conservative evidence budgets) for primitives such as passing tools, suture handling, or supply handoffs.
- Tools/Products: Domain-trained VLM planners with surgical lexicons; validated VEB tuned for sterile fields; sim-to-real pipelines.
- Dependencies/Assumptions: Extensive clinical validation; liability and safety frameworks; high-fidelity perception.
- Assistive home-care robots for long-horizon chores — Reliable laundry/kitchen workflows where planners produce ordered subtask sequences and VEB sustains focus despite clutter and interruptions.
- Tools/Products: Home-user demonstration capture with automatic relabeling; customization UIs; privacy-first on-device inference.
- Dependencies/Assumptions: Household diversity in objects/layouts; robust failure recovery; social acceptability.
- Multi-robot teams — Shared subtask language and budgeted perception to coordinate division of labor (e.g., mobile + manipulator) via a common planner.
- Tools/Products: Inter-robot planning protocols; cross-agent subtask taxonomies; evidence-sharing policies.
- Dependencies/Assumptions: Reliable communication; time synchronization; conflict resolution mechanisms.
- AR-guided human-robot collaboration — Human operators provide disambiguating local guidance in AR that plugs into the S2 interface; VEB locks onto operator-indicated ROIs for safer collaboration.
- Tools/Products: AR UIs that emit structured subtask instructions; ROI-to-gate integration; mixed-reality validation tools.
- Dependencies/Assumptions: Accurate calibration; low-latency tracking; ergonomic UX.
- Extreme environments (space, nuclear, subsea) — Robust manipulation under severe shifts using planners for detailed guidance and strict evidence budgets to avoid spurious correlations.
- Tools/Products: Hardened sensors; long-range planner links; verified mask behavior under harsh conditions.
- Dependencies/Assumptions: Limited bandwidth/latency constraints; small data regimes; extensive simulation.
- Education and workforce development — Curricula and capstone projects built on modular planner-executor designs with relabeling and VEB as first-class concepts.
- Tools/Products: Teaching kits; standardized datasets with subtask spans; cloud notebooks demonstrating budget sweeps.
- Dependencies/Assumptions: Open tooling and licenses; institutional adoption.
- Enterprise software agents for complex workflows — Extend S2 concepts to document- and screen-heavy tasks (finance back-office, IT ops), using local step prompts and “evidence budgets” over UI/text regions for reliability and auditability.
- Tools/Products: Enterprise agent SDKs with gating over screenshots/PDF tokens; compliance logs of “what evidence was used.”
- Dependencies/Assumptions: Robust UI detection; privacy/security controls; domain-tuned planners.
- Tooling ecosystem and standards — “S2-compliant” planner-executor SDKs, mask visualizers, budget tuners, dataset relabelers, and benchmarking suites analogous to LIBERO-PRO for real-world sites.
- Tools/Products: Open standards for subtask schemas and mask telemetry; plug-ins for major VLA backbones.
- Dependencies/Assumptions: Community buy-in; maintenance and versioning.
- Formal verification of behaviors — Use explicit subtask specs and bounded evidence to verify slices of behavior and derive safety envelopes.
- Tools/Products: Subtask-level model-checking; counterexample-guided mask audits; certifiable execution traces.
- Dependencies/Assumptions: Formal models capturing planner-executor dynamics; tractable abstractions for continuous control.
Cross-cutting assumptions that impact feasibility
- Planner reliability is a bottleneck: the S2 executor follows the subtask it’s given and does not “undo” planner errors; planner quality and in-context prompting are critical.
- Data and relabeling quality matter: trajectory/subtask relabeling must preserve task identity while disambiguating execution modes; boundary noise can degrade supervision.
- Perception setup: Most results assume at least two camera views (base and wrist) plus proprioception; other setups may need adaptation.
- Hyperparameter sensitivity: Visual evidence budgets (e.g., ~0.2 in paper) and gate schedules require tuning per task/view; mis-tuning can hurt performance.
- Backbone agnosticism is claimed but demonstrated with pi0.5; porting to other VLAs should be possible but may require engineering.
- Safety and compliance: Sectors like healthcare and manufacturing may require rigorous validation and audit trails (which S2’s masks can support, but processes must be built).
Glossary
- Action horizon: the number of future actions the policy predicts or considers in a chunk. "and is the action horizon."
- Action multimodality: the presence of multiple valid ways to perform a task, leading to diverse action trajectories for the same instruction. "this burden mismatch appears as avoidable ambiguity and apparent action multimodality."
- Annealed soft-gating schedule: a training schedule that gradually sharpens gating decisions by lowering the gating temperature over time. "an annealed soft-gating schedule that keeps the gate smoother early in training before sharpening later."
- Appearance shift: changes in visual appearance (e.g., lighting, textures) between training and deployment that can harm performance. "under distractors, appearance shift, embodiment-specific noise, and tight inference constraints."
- Base view: a camera viewpoint providing broader scene context, often mounted on the robot base. "the base and wrist views."
- Bimanual: involving or requiring two arms or manipulators. "Because TX-G2 is bimanual, the policy must also infer which arm should execute the current behavior."
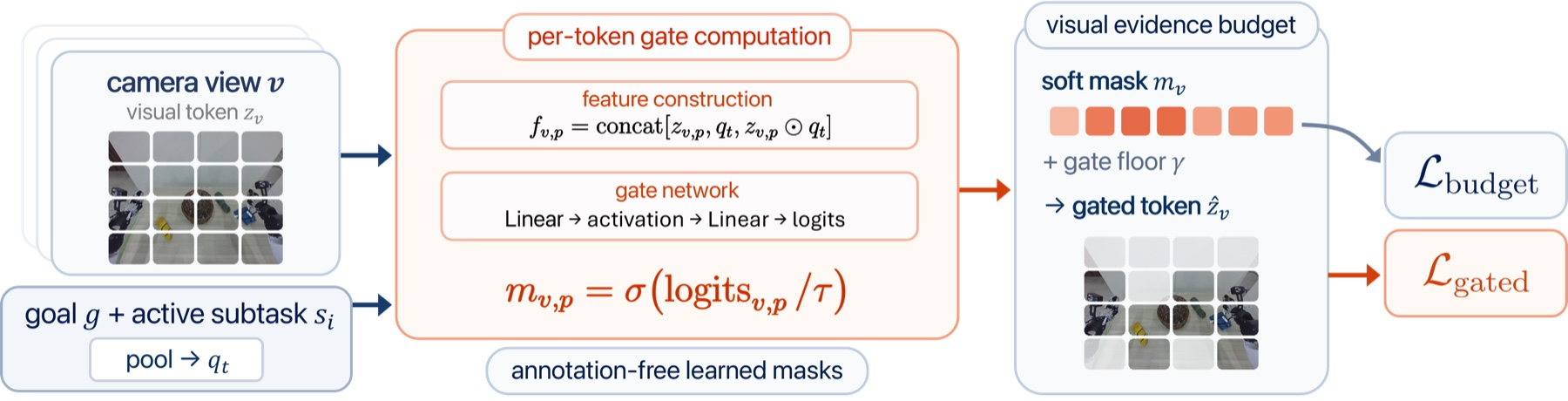
- Budget regularizer: a loss term that penalizes deviations from a target amount of retained visual evidence. "then trains the gated representation with a task loss and a budget regularizer, without any region, box, or mask annotation."
- Contact dynamics: physical interactions during contact (e.g., friction, compliance) that affect execution outcomes. "arising from embodiment, contact dynamics, or control noise."
- Control objective: the task-driven training signal used to learn actions, guiding what visual evidence is sufficient. "the executor learns directly from the control objective which evidence is sufficient for successful execution under the current subtask."
- Distribution shift: a mismatch between training and test data distributions that can degrade generalization. "benchmarks such as LIBERO and CALVIN still expose brittle generalization under distribution shift"
- Distractors: task-irrelevant objects or features in the scene that can mislead perception or control. "under distractors, appearance shifts, and semantically similar tasks"
- Elementwise product: a feature interaction computed by multiplying corresponding elements of two vectors. "the pooled language summary, and their elementwise product."
- End-effector: the tool or gripper at the end of a robot arm that interacts with objects. "behavior-relevant object, end-effector, and destination context"
- Evidence bottleneck: an architectural constraint limiting the amount of visual evidence available to the policy to encourage focus on task-relevant cues. "introduces an explicit, control-grounded evidence bottleneck"
- Flow-matching objective: a training objective that learns a velocity field to transform noise into target actions over a synthetic time variable. "the policy predicts an action chunk using a flow-matching objective."
- Gate collapse: a failure mode where gating shuts off most inputs or keeps all inputs uniformly, preventing meaningful selection. "Early gate collapse or trivial all-keep behavior is avoided"
- Gate floor: a minimum gating value ensuring tokens retain a small residual contribution even when largely suppressed. "We then apply a nonzero gate floor via"
- Gate head: a lightweight network that outputs token-wise keep/suppress values for visual evidence. "These masks are produced by lightweight learned gate heads inside the executor."
- Gating network: the model component that computes gating logits or scores for tokens, often conditioned on language and vision. "where is a small learned gating network for that view."
- In-context learning: a method where a model adapts behavior based on examples or instructions in the prompt without gradient updates. "remains compatible with off-the-shelf VLM planners through in-context learning."
- Inference constraints: resource or latency limits during deployment that restrict model complexity or throughput. "tight inference constraints."
- Latent planner-to-policy interfaces: internal or hidden representations that connect planning modules to policies without explicit symbolic commands. "reasoning-augmented architectures, latent planner-to-policy interfaces, or RL post-training"
- Low-level continuous actions: fine-grained control signals (e.g., velocities, torques) output at high frequency for robot actuators. "output precise low-level continuous actions"
- Native attention: the standard attention mechanism of the backbone network before any additional gating or budgeting is applied. "Unlike native attention, See Less imposes an explicit visual evidence budget"
- Nuisance dependence: reliance on task-irrelevant visual correlations that can hurt robustness under shift. "this bottleneck is introduced not for efficiency but to reduce nuisance dependence and improve generalization"
- Object-centric methods: approaches that represent or reason about scenes in terms of discrete objects to improve control and robustness. "attention-based and object-centric methods improve robustness"
- Off-the-shelf VLM: a pretrained vision-LLM used without task-specific fine-tuning for planning or guidance. "remains compatible with off-the-shelf VLM planners"
- Out-of-distribution (OOD): data points that differ significantly from the training distribution (e.g., novel placements). "8 near-ID and 2 OOD placements"
- Planner-executor: a modular architecture splitting high-level decision-making (planner) from low-level control (executor). "S2 defines the executor-conditioning interface in a modular planner-executor VLA system."
- Proprioceptive state: internal robot measurements such as joint positions or velocities. " denotes proprioceptive state."
- Region proposals: candidate spatial regions (e.g., boxes) hypothesized to contain relevant content, often used in detection pipelines. "without external region proposals, mask or box annotations"
- Robustness: the ability of a model to maintain performance under perturbations or shifts. "provides complementary robustness gains"
- Saliency map: a visualization or estimate of input regions deemed important by a model. "rather than a generic saliency map."
- Soft keep value: a continuous gate (between 0 and 1) indicating how much of a token’s information to retain. "predicts a soft keep value"
- State-specific local guidance: context-dependent instructions tailored to the current scene state for disambiguating execution. "rewrites the same high-level instruction into state-specific local guidance"
- Subtask: a phase or segment of a larger task with its own localized instruction and time span. "Each subtask is intended to be directly executable by the low-level policy"
- Supervision aliasing: ambiguity where the same supervision signal corresponds to multiple valid behaviors, confusing learning. "coarse instructions induce avoidable supervision aliasing"
- Temperature-scaled sigmoid gating: applying a sigmoid with a temperature parameter to control gate sharpness. "followed by temperature-scaled sigmoid gating"
- Token pruning: removing a subset of tokens to reduce redundancy or computation while preserving performance. "token pruning to reduce redundancy or improve efficiency"
- Token selection: choosing a subset of tokens deemed most informative for the task. "token selection and token pruning"
- Trajectory-level instruction: an instruction that describes how a specific demonstration solves the task. "a refined trajectory-level instruction"
- Visual evidence budget: an explicit limit on how much visual information the policy can retain, encouraging focus on essentials. "See Less imposes an explicit visual evidence budget"
- Visual evidence budgeting: the process of learning and enforcing constraints on retained visual information during control. "explicit visual evidence budgeting provides complementary robustness gains"
- Visual evidence masks: token- or patch-wise weights that modulate how much visual information passes to the policy. "introduce task-conditioned visual evidence masks and "
- Visual tokens: discrete embeddings representing image patches or regions within a transformer pipeline. "over image patches or visual tokens in the base and wrist views"
- Vision-language-action (VLA): models that map visual observations and language instructions to actions. "Vision-language-action (VLA) models have recently shown strong promise for robot manipulation"
- Vision-LLM (VLM): models that jointly process images and text, often used for high-level planning or instruction refinement. "Modern vision-LLMs (VLMs) are stronger at open-ended instruction interpretation"
- Visuomotor learning: learning policies that map visual inputs to motor outputs for control. "exploiting locality in visuomotor learning"
- Velocity field: a learned vector field over a time variable that guides noisy action states toward targets in flow matching. "the backbone predicts a velocity field"
- Wrist view: a camera viewpoint near the end-effector capturing contact-local details. "the wrist view often captures contact-local detail"
- Embodiment-specific noise: variability arising from a robot’s hardware properties and actuation that affects control reliability. "embodiment-specific noise"
Collections
Sign up for free to add this paper to one or more collections.

