VLA-GSE: Boosting Parameter-Efficient Fine-Tuning in VLA with Generalized and Specialized Experts
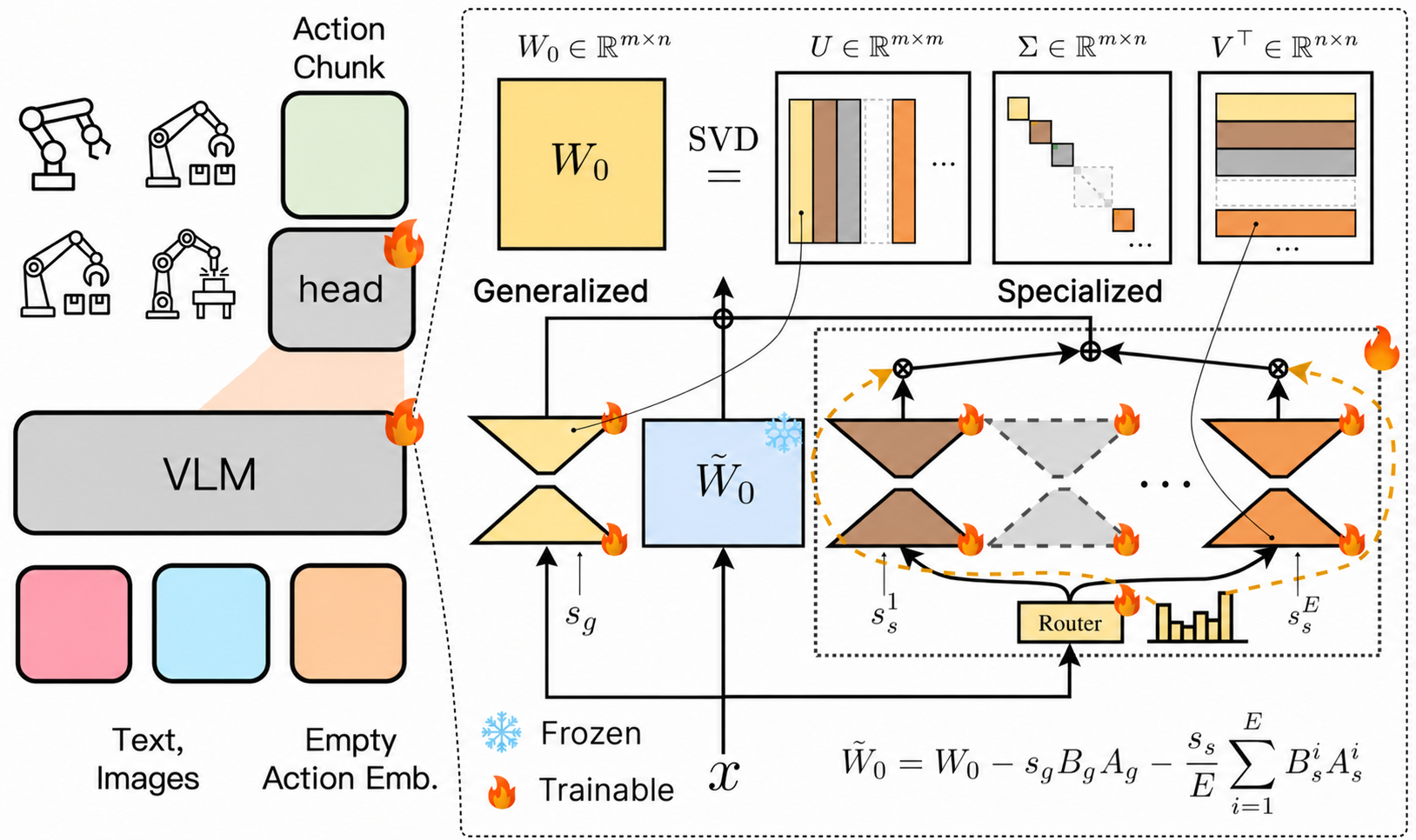
Abstract: Vision-language-action (VLA) models inherit rich visual-semantic priors from pre-trained vision-language backbones, but adapting them to robotic control remains challenging. Full fine-tuning (FFT) is prone to overfitting on downstream robotic data and catastrophic forgetting of pretrained vision-language capabilities. Parameter-efficient fine-tuning (PEFT) better preserves pre-trained knowledge, yet existing PEFT methods still struggle to adapt effectively to robot control tasks. To address this gap, we propose VLA-GSE, a parameter-efficient VLA fine-tuning framework that improves control adaptation while retaining PEFT's knowledge preservation advantage. Specifically, VLA-GSE (Generalized and Specialized Experts) is initialized by spectrally decomposing the frozen backbone, assigning leading singular components to generalized experts (shared experts) and disjoint residual components to specialized experts (routed experts). This decomposition improves adaptation capacity under a fixed trainable-parameter budget. Under a comparable parameter budget, VLA-GSE updates only 2.51% of the full model parameters and consistently outperforms strong FFT and PEFT baselines. It achieves 81.2% average zero-shot success on LIBERO-Plus, preserves pre-trained VLM capability comparably to LoRA on multimodal understanding benchmarks, and improves real-world manipulation success under multiple distribution shifts. Code is available at: https://github.com/YuhuaJiang2002/VLA-GSE


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching robots to understand pictures and language and then act, without having to retrain every part of a huge model. The authors build a smarter, lighter way to fine‑tune a big vision–LLM (a model that looks at images and reads instructions) so it can control a robot’s actions. Their method aims to learn good robot skills quickly, keep what the model already knows, and avoid overfitting (getting too stuck on the training examples).
What questions did the researchers ask?
- Can we fine‑tune a robot’s brain using only a small part of its millions of settings, and still get great performance?
- Can we make this small update powerful enough to handle precise control tasks, while not forgetting the model’s original vision‑and‑language knowledge?
- Is there a clever way to split the update into “general” skills and “special” skills so the robot adapts better?
How did they do it?
The team starts with a pre‑trained vision–LLM (VLM), then adds a small, trainable “attachment” instead of changing all the original weights. Think of the base model as a huge library you don’t want to rearrange, and the attachment as a small set of new shelves you can customize.
Splitting knowledge into “experts” with SVD
- SVD, in simple terms, is a way to break a big matrix (a table of numbers representing model weights) into key parts, sorted from “most important” patterns to “less important” ones. Imagine sorting a pile of LEGO pieces by how often they’re used.
- The method creates two kinds of small trainable modules:
- A generalized expert: always on. It’s built from the most important patterns. Think of it as a head coach that handles common skills every task needs.
- Multiple specialized experts: used only when needed. Each one covers a specific slice of the remaining patterns. Think of them as specialist coaches (like a passing coach, defense coach, etc.) you call in for certain plays.
Choosing which specialists to use (routing)
- A tiny “router” looks at the current input (the image and instruction) and picks the top few specialized experts to use. This is like a coordinator deciding which specialist coaches should advise on the next move.
- To prevent the router from picking the same specialists all the time, the authors add a small “load‑balancing” penalty that encourages fair use of all specialists.
Keeping training fair and stable (gradient and scale balancing)
- Problem: the specialists start with different “loudness” because their SVD slices have different strengths. If some are too loud, they learn too fast; if too quiet, they barely learn.
- Fix: the method adjusts each specialist’s scaling (like turning volume knobs) so their learning signals are balanced. This helps every expert train properly instead of letting a few dominate.
Not drifting away from the starting model
- Their attachment adds a small change to the base model at the start. To keep behavior stable on day one, they subtract an equal “counterweight” from the frozen base so that, on average, the overall model still behaves like the original before training. This preserves the model’s prior vision–language skills while the new parts learn robot control.
Training setup in plain terms
- They only train about 2.51% of the full model’s parameters. That’s like updating a few pages instead of rewriting an entire book.
- The action head (the part that outputs the robot’s moves) is fully trained, but the big backbone VLM mostly stays frozen; only the small expert modules get updated inside it.
What did they find?
Here are the main results the authors report:
- Better robot performance with tiny updates: With only 2.51% of parameters updated, their method (VLA‑GSE) beats both full fine‑tuning and other small‑update methods on a tough simulator benchmark called LIBERO‑Plus, reaching 81.2% average zero‑shot success. That means it handles new test conditions well without extra training on them.
- Keeps vision–language skills: On general multimodal tests (like answering questions about images), their method preserves the pre‑trained model’s abilities about as well as the popular LoRA method. In contrast, full fine‑tuning often forgets these skills.
- Works on real robots under change: In real‑world tests with different lighting, wording of instructions, object layouts, and backgrounds, their method achieved 82.5% success on average—higher than several strong baselines.
Why this matters: You get the best of both worlds—strong robot control and preserved understanding—without retraining a massive model.
Why does this matter?
- Efficiency: Training only a small part of the model saves memory, time, and compute, which is important for labs and companies without huge resources.
- Reliability: The robot keeps its general visual and language understanding, making it more dependable in everyday situations.
- Robustness: The method handles “distribution shifts” (changes in lighting, backgrounds, clutter, or phrasing of instructions) better, which is crucial for the messy real world.
- Reusability: The idea of mixing a shared “general” expert with routed “specialists,” plus balancing their training and keeping the starting point stable, could help other models and tasks beyond robotics.
In short, the paper shows a practical way to adapt big vision–LLMs into strong, stable robot controllers by adding a smart, small, and well‑balanced team of “experts” instead of rewriting the whole brain.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Backbone generality: The method is only demonstrated on Qwen3-VL-4B-Instruct; it remains unclear how VLA-GSE transfers to other VLM backbones (e.g., LLaVA/InternVL/Gemma-3, larger/smaller scales) and whether the gains persist with different visual encoders, tokenizer designs, or cross-modal connectors.
- Layer/module coverage: The paper does not specify precisely which VLM modules receive GSE (e.g., attention projections, MLPs, cross-attention, visual adapters); the impact of selectively applying GSE to different layer types or depths is unstudied.
- Compute and latency overhead: While parameter count is reported, the FLOPs, memory bandwidth, and real-time latency overhead introduced by per-token routing (Top-k MoE), large numbers of experts, and SVD initialization are not quantified; trade-offs versus LoRA and FFT under deployment constraints remain unknown.
- SVD practicality at scale: Full SVD per weight for many layers may be expensive for larger backbones; the paper does not evaluate approximate or incremental SVD variants, their accuracy–efficiency trade-offs, or sensitivity of performance to SVD approximation errors.
- Top-k gating design space: The effects of varying number of experts E, per-expert rank d, top-k, router hidden size/architecture, temperature/noise, and balancing loss weight α are only minimally explored; no systematic sensitivity analysis is provided.
- Routing stability and collapse: Although a load-balancing loss is used, there is no quantitative analysis of expert utilization (e.g., entropy, Gini coefficients over tokens/tasks), collapse dynamics over training, or how routing behaves under severe OOD inputs.
- Theoretical assumptions unverified: Theorem conditions (balanced routing, approximate isotropy of second-moment projections) are not empirically validated; measuring per-expert gradient second moments and testing whether the trace-inverse scaling actually equalizes optimization scales is left open.
- Backbone weight adjustment ablation: The expectation-based backbone weight adjustment is theoretically motivated but not isolated experimentally; its effect on early training dynamics, convergence speed, and knowledge retention versus a no-adjustment baseline remains unknown.
- Non-zero perturbation at initialization: Beyond expectation alignment, the immediate sample-wise deviation from
W0at init may affect initial performance and stability; the paper does not quantify early-step behavior, loss spikes, or mitigation strategies beyond the adjustment. - Generalized vs. specialized expert semantics: The paper does not analyze what capabilities the generalized expert versus specialized experts actually capture (e.g., task-, modality-, or perturbation-specific behavior); no routing maps, token-level specialization, or instruction/vision-conditioned specialization diagnostics are provided.
- Modality-aware routing: Inputs include heterogeneous token types (vision/text), yet the router is a simple linear map over input
x; whether modality-specific routers or separate gating per modality improves retention/adaptation remains unexplored. - Interaction with action heads: Only an OpenVLA-OFT-style MLP action head is evaluated; compatibility with alternative action heads (e.g., diffusion, flow matching, autoregressive token policies) and the trade-off between backbone PEFT and action-head capacity are not studied.
- Data efficiency and scaling laws: The paper lacks analysis of performance as a function of demonstration count, task diversity, or training duration; few-shot adaptation behavior and overfitting/underfitting regimes for GSE versus LoRA/FFT are unknown.
- Continual and lifelong learning: Although specialized experts suggest a natural fit for incremental domains, VLA-GSE is not evaluated for continual learning (e.g., expert growth/pruning, task-specific routing, forgetting across sequences of tasks).
- Robustness breadth: Robustness is evaluated on LIBERO-Plus perturbations and four real-world shift types; other critical shifts (camera viewpoint extremes, actuation delays, dynamic distractors, sensor failures, motion blur, domain jumps like new robot embodiments) remain untested.
- Real-world external validity: Real-robot experiments cover one platform, four tabletop tasks, and 60 trials per task; no statistical significance testing, failure mode taxonomy, or scaling to multi-robot, multi-site settings is provided.
- Fairness of parameter budgets: Although parameter counts are matched, equivalence in effective capacity and compute is not demonstrated; baseline PEFT methods may benefit from alternative layer targeting, ranks, or hybrid adapters—these fairness dimensions are not examined.
- Comparison breadth: Baselines focus on LoRA and MoE-LoRA variants; other PEFT strategies (e.g., Adapters, IA3, Prefix/Prompt tuning, L2-SP/EWC regularized FFT, AdapterFusion, Compacter) are not compared, so relative merit remains ambiguous.
- Temporal reasoning and memory: The tasks and architecture do not probe long-horizon temporal credit assignment or memory; how routing decisions behave over time and whether experts specialize for temporal sub-skills remains open.
- Failure analyses: The paper provides qualitative attention maps but no systematic error analysis (e.g., where/when GSE fails, sensitivity to ambiguous language, cluttered scenes, or near-duplicate object categories).
- Safety and stability: No discussion of safety-critical failure handling, outlier routing behavior, or worst-case latency spikes caused by MoE selection; requirements for real-time robotic control under strict deadlines are not addressed.
- Hyperparameter transferability: The chosen settings (e.g.,
s_g=2, trace-inverse scaling base, α=0.01, E=8, Top-2) are fixed; guidelines for selecting these in new domains/backbones and their robustness to mismatch are missing. - Multi-task and cross-domain generalization: While LIBERO-Plus mixes suites, scalability to broader multi-task regimes (e.g., Open X-Embodiment, DROID, real kitchen/tool-use datasets) and how routing scales with task diversity are not explored.
- Expert budget allocation across layers: The method uses a fixed number of experts/layer; adaptive per-layer expert allocation based on spectral energy or gradient signals could be beneficial but is uninvestigated.
- Token vs. sample routing granularity: The load-balancing loss mentions “tokens,” but the empirical implications of per-token vs. per-sample routing (and mixed strategies) on control performance and memory/compute costs are not analyzed.
- Interplay with multimodal understanding: While general VLM benchmarks are reported, the causal mechanisms by which GSE preserves VLM competence (e.g., per-module perturbation norms, representational similarity to
W0) are not measured; calibration and hallucination behavior post-finetuning remain unassessed. - Open-source reproducibility details: Key implementation specifics (exact layer list, SVD computation scheme, gating differentiability for Top-k, gradient clipping, router temperature) are not fully detailed in the main text, limiting reproducibility and diagnosis of potential edge cases.
Practical Applications
Practical Applications of VLA-GSE
Below are actionable, real-world applications derived from the paper’s findings, methods, and innovations. Each item names relevant sectors, potential tools/products/workflows, and key assumptions or dependencies affecting feasibility.
Immediate Applications
- Rapid adaptation of existing VLM-based robot policies to new tasks with limited data
- Sectors: Robotics (industrial, service, logistics, retail), Healthcare (hospital logistics), Smart home
- Tools/products/workflows: “GSE adapters” for Qwen/Gemma/other VLM backbones; training pipelines that insert GSE blocks into existing OpenVLA/OFT-based stacks; few-shot data collection and PEFT training with gradient-scale balancing and backbone adjustment
- Assumptions/dependencies: Availability of a compatible pre-trained VLM; modest task-specific demonstrations; ability to run SVD for backbone weights and integrate top-k routing
- Over-the-air (OTA) skill updates for deployed robot fleets with small patch sizes
- Sectors: Robotics (field service, warehouse), Software (MLOps)
- Tools/products/workflows: OTA distribution of only GSE parameters (~2.51% updates) instead of full models; staged rollout and rollback; fleet-wide A/B testing
- Assumptions/dependencies: Secure update mechanism; versioning and compatibility checks; on-device routing inference support
- Robustness upgrades for robots operating under real-world shifts
- Sectors: Retail (store-floor robots), Hospitality, Facilities management
- Tools/products/workflows: Fine-tuning workflows focused on lighting/background/language paraphrase robustness; load-balancing router diagnostics to avoid expert collapse; regression tests with LIBERO-Plus-style OOD scenarios
- Assumptions/dependencies: Access to representative shift data; monitoring tools for expert utilization and routing stability
- Preserving general VLM capabilities while adding control skills
- Sectors: Human-robot interaction (HRI), Education (lab teaching robots), Software (multimodal assistants with actuation)
- Tools/products/workflows: Joint evaluation suites that combine manipulation tasks with OCR/VQA; acceptance criteria that require minimal degradation on multimodal understanding (comparable to LoRA)
- Assumptions/dependencies: Benchmarks and pipelines to test both control and vision-language competence; proper scaling of GSE components
- Cost- and energy-efficient training for new robotic behaviors
- Sectors: Energy/sustainability, Finance (TCO optimization), Robotics
- Tools/products/workflows: PEFT training dashboards that report GPU-hours/emissions; policy in procurement to prioritize parameter-efficient fine-tuning; automated selection of generalized vs. specialized expert capacity
- Assumptions/dependencies: Accurate cost/energy tracking in MLOps stack; internal buy-in to prioritize PEFT over full fine-tuning
- Vendor-agnostic adapter libraries for VLM-to-VLA transfer
- Sectors: Software (ML frameworks), Robotics platform providers
- Tools/products/workflows: PyTorch/Transformers plugins for GSE blocks; router/top-k gating modules; SVD-based initializers; export/import of GSE weights across backbones
- Assumptions/dependencies: Open-source code integration; clear APIs for different transformer architectures; maintenance across model versions
- Rapid customization in hospitals and labs with privacy constraints
- Sectors: Healthcare, Academia
- Tools/products/workflows: On-premise PEFT training using small, private datasets; local SVD init and training; deployment of only GSE weights without sharing base VLM
- Assumptions/dependencies: Sufficient on-prem compute for PEFT; data governance and access controls
- Benchmarking and teaching materials for embodied AI and PEFT
- Sectors: Academia, Education
- Tools/products/workflows: Course labs demonstrating catastrophic forgetting vs. PEFT vs. GSE; reproducible LIBERO-Plus pipelines; ablation kits (turn off SVD init, gradient balancing, generalized/specialized experts)
- Assumptions/dependencies: Access to datasets/simulators; reproducible seeds and logging
Long-Term Applications
- Continual, on-device learning for home and service robots without catastrophic forgetting
- Sectors: Smart home, Hospitality, Elder care
- Tools/products/workflows: Background GSE updates from ongoing user interactions; skill routers that specialize to household layouts/custom objects; privacy-preserving on-device training
- Assumptions/dependencies: Stable, long-horizon training under safety constraints; robust routing under non-stationary data; edge accelerators supporting PEFT updates
- Fleet-wide “skill marketplaces” with plug-and-play routed experts
- Sectors: Robotics platforms, Software marketplaces
- Tools/products/workflows: Distributable specialized expert packs for common skills (e.g., pouring, sorting, instrument handling); automatic router calibration on deployment
- Assumptions/dependencies: Standardized GSE packaging formats; cross-backbone compatibility; licensing and IP frameworks
- Cross-domain embodied agents (AR/VR, surgical assistance, micro-assembly) leveraging generalized-specialized decomposition
- Sectors: Healthcare (assistance/training), Manufacturing (precision assembly), Education (virtual labs), Entertainment (AR/VR)
- Tools/products/workflows: Domain-specific specialized experts (e.g., fine motor control in microsurgery simulators); mixed-reality instruction-to-action pipelines using preserved VLM knowledge
- Assumptions/dependencies: High-fidelity simulators and datasets; safety and regulatory approvals for high-stakes settings
- Unified multimodal assistants that can both understand documents and act in the physical world
- Sectors: Enterprise automation, Logistics, Facilities management
- Tools/products/workflows: Systems that keep OCR/VQA performance stable while learning new manipulation procedures; workflows chaining perception (document/label reading) with action (picking/placing)
- Assumptions/dependencies: Tight integration of perception and control evaluation; robust failure handling across chained tasks
- Standardized policy and compliance frameworks emphasizing efficient, low-forgetting updates for embodied AI
- Sectors: Policy/regulation, Public sector
- Tools/products/workflows: Procurement and compliance checklists requiring parameter-efficient updates and knowledge retention tests; carbon budget policies favoring PEFT over full re-training
- Assumptions/dependencies: Broad stakeholder consensus; benchmark standards (e.g., LIBERO-Plus extensions) as regulatory references
- PEFT-as-a-service for robotics (managed training and monitoring)
- Sectors: Cloud/Edge providers, Robotics integrators
- Tools/products/workflows: Managed pipelines for SVD init, gradient scale balancing, routing load balancing, backbone adjustment; dashboards for expert utilization and drift detection
- Assumptions/dependencies: Secure data transfer; SLA for low-latency updates; integration with diverse robot SDKs
- Safety-certified adaptation workflows for embodied AI
- Sectors: Healthcare, Industrial robotics, Defense
- Tools/products/workflows: Verified GSE update boundaries; formal tests showing expected-weight preservation at initialization; gated releases with human-in-the-loop review of expert routing behavior
- Assumptions/dependencies: Formal verification methods adapted to MoE/PEFT; labeling of unsafe states and recovery policies
- Extension to broader agent modalities (mobile manipulation, aerial, legged robots, autonomous vehicles)
- Sectors: Mobility, Warehousing, Inspection
- Tools/products/workflows: Specialized experts for locomotion and navigation; hierarchical routers for perception, planning, and control layers
- Assumptions/dependencies: Task-specific data and interfaces; validation under dynamic and safety-critical conditions; scalability beyond manipulator-centric tasks
Notes on Feasibility and Dependencies
- Data availability: Although parameter-efficient, VLA-GSE still needs task-relevant demonstrations; performance may vary with dataset quality and diversity.
- Compute and integration: SVD-based initialization and MoE routing add engineering complexity; stable training assumes proper scaling and load balancing.
- Generalization scope: Reported gains are strongest for tabletop manipulation and the tested distribution shifts (lighting, background, language, layout); transfer to other modalities (locomotion, aerial) requires adaptation and validation.
- Backbone compatibility: Results were shown with Qwen3-VL-4B-Instruct and an OpenVLA-OFT-style action head; applying to other backbones and architectures may need tuning.
- Safety and compliance: In safety-critical sectors, formal validation and monitoring of routing behavior and update magnitudes are necessary before deployment.
These applications leverage the core contributions of VLA-GSE—SVD-based generalized/specialized experts, expert-wise gradient scale balancing, and backbone weight adjustment—to deliver stronger control adaptation under a small trainable-parameter budget while retaining vision-language capabilities.
Glossary
- Action head: The module that maps encoded multimodal features to robot action outputs in a VLA. "an OpenVLA-OFT-style action head is used to generate robot actions"
- Affordance (manipulation affordance): Task-relevant physical property that indicates how an object can be manipulated (e.g., graspable edges). "captures the manipulation affordance required for grasping"
- Auxiliary load-balancing loss: A regularizer encouraging balanced use of experts in routed architectures to avoid expert collapse. "we introduce an auxiliary load-balancing loss to encourage balanced expert utilization across GSE blocks."
- Backbone weight adjustment: A mechanism that offsets the initial low-rank perturbation so the expected effective weight matches the pre-trained backbone. "We address this with a backbone weight adjustment mechanism that preserves the backbone-equivalent weight in expectation."
- Catastrophic forgetting: Degradation of pre-trained capabilities when fine-tuning on new data. "degrades pre-trained vision-language competence through catastrophic forgetting"
- Decoupled learning rates: Using different learning rates for distinct parameter groups to stabilize training. "we apply decoupled learning rates: the learning rate for the GSE parameters in VLM is set to "
- Distribution shift: Changes between training and test conditions (e.g., lighting, background) that challenge generalization. "improves real-world manipulation success under multiple distribution shifts."
- Embodied policies: Control policies that act in physical environments conditioned on vision and language inputs. "pre-trained vision-LLMs (VLMs) are adapted into embodied policies"
- Equivalent weight: The input-dependent effective weight combining frozen backbone and expert contributions in a GSE block. "Let denote the input-dependent equivalent weight of the GSE block."
- Expert-wise gradient scale balancing: A technique that rescales experts to equalize their gradient magnitudes for stable optimization. "We address this with expert-wise gradient scale balancing"
- Frozen backbone: Keeping pre-trained model parameters fixed during adaptation to preserve prior knowledge. "we learn a structured low-rank update while keeping most backbone parameters frozen."
- Frobenius norm: A matrix norm (square root of sum of squared entries) used to measure gradient magnitude. "the expected squared Frobenius norms of its localized gradients"
- Generalized and Specialized Experts (GSE): The proposed PEFT framework combining an always-on generalized expert with routed specialized experts. "VLA-GSE (Generalized and Specialized Experts) is initialized by spectrally decomposing the frozen backbone,"
- Generalized expert: An always-active expert initialized from leading singular components to capture shared adaptation. "We allocate the largest singular values to the generalized expert."
- Long-horizon manipulation: Robotic tasks requiring extended multi-step action sequences and planning. "enabling substantial progress in long-horizon manipulation and boarder generalization"
- Low-rank adaptation (LoRA): A PEFT method that adds trainable low-rank updates to frozen weights. "Parameter-efficient fine-tuning (PEFT), such as low-rank adaptation (LoRA), is more stable in preserving pre-trained capability"
- Low-rank perturbation: A low-rank change applied to a weight matrix that alters it by a small subspace update. "VLA-GSE induces a non-zero low-rank perturbation at initialization"
- Multimodal priors: Pre-trained cross-modal knowledge (vision-language) that guides downstream learning. "By inheriting strong multimodal priors from foundation VLMs"
- OpenVLA-OFT: An architectural style in VLA models emphasizing efficient inference with OFT design choices. "such as OpenVLA-OFT-style designs"
- Parallel decoding: Generating outputs concurrently to speed up inference. "further improve inference efficiency via parallel decoding."
- Parameter-efficient fine-tuning (PEFT): Fine-tuning approaches that update a small fraction of parameters to preserve pre-trained knowledge. "Parameter-efficient fine-tuning (PEFT) better preserves pre-trained knowledge"
- Router: The module that computes scores to select which experts process an input. "a router maps the input to routing logits "
- Routing logits: Unnormalized scores produced by the router indicating expert preference. "a router maps the input to routing logits "
- Routing weights: Normalized weights (via softmax over selected experts) that determine each expert’s contribution. "The routing weights are explicitly defined by applying a softmax function exclusively over the selected top- logits:"
- Specialized expert: An input-routed expert initialized from residual spectral components for task-specific adaptation. "specialized experts (routed experts)"
- Spectral decomposition: Decomposing a matrix according to its singular spectrum (e.g., via SVD) to allocate components. "VLA-GSE is built from a spectral decomposition of the frozen backbone"
- Spectral initialization: Initializing experts from specific segments of the singular spectrum. "spectral initialization induces large singular-value imbalance across specialized experts"
- Spectral magnitude: The size of singular values indicating energy in corresponding spectral components. "normalizes each expert’s scale based on the spectral magnitude of its assigned segment"
- SVD (Singular Value Decomposition): Matrix factorization into singular vectors and values used for expert initialization. "We initialize VLA-GSE from the SVD of the frozen pre-trained weight matrix"
- Singular components: Singular vectors and their associated contributions derived from SVD. "assigning leading singular components to generalized experts"
- Singular values: The non-negative scalars on the diagonal of Σ in SVD indicating component strength. "Sorting singular values in descending order"
- Top-2 gating strategy: Selecting the two highest-scoring experts for each input during routing. "utilizing a Top-$2$ gating strategy."
- Top-k gating: Selecting the k highest-scoring experts for each input during routing. "the dynamically selected top- specialized experts."
- Trace-inverse scaling rule: Scaling experts inversely proportional to the trace of their assigned spectrum to equalize gradients. "Theorem~\ref{thm:scaling_factor} shows that the trace-inverse scaling rule in Eq.~\eqref{eq:trace_inverse_scaling_main} is justified"
- Zero-shot success: Performance on tasks without additional task-specific fine-tuning. "It achieves 81.2% average zero-shot success on LIBERO-Plus"
Collections
Sign up for free to add this paper to one or more collections.

