- The paper introduces a multi-consistency framework that enforces invariance to visual and linguistic perturbations, significantly boosting policy robustness.
- It leverages Instructional, Evolutionary, and Observational Consistencies through a dual-system architecture combining a pretrained VLM and a DiT-based action generator.
- Experimental results on LIBERO-Plus, RoboTwin 2.0, and tabletop manipulation tasks demonstrate significant performance gains, notably a 16.6% improvement under paraphrased instructions.
RoVLA: Advancing Robustness in Vision-Language-Action Policies via Multi-Consistency Constraints
Motivation and Problem Statement
Despite progress in Vision-Language-Action (VLA) models, their policies remain brittle under distribution shifts—specifically, under changes in visual observations and language instructions that are semantically equivalent but lexically diverse. Prior approaches have largely focused on data scaling, improved action generation, or post hoc adaptation, yet have seldom treated invariance to such perturbations as an explicit training objective. As illustrated, canonical VLA models frequently exploit superficial correlations in the training data rather than internalizing the fundamental task semantics required for robust generalization.
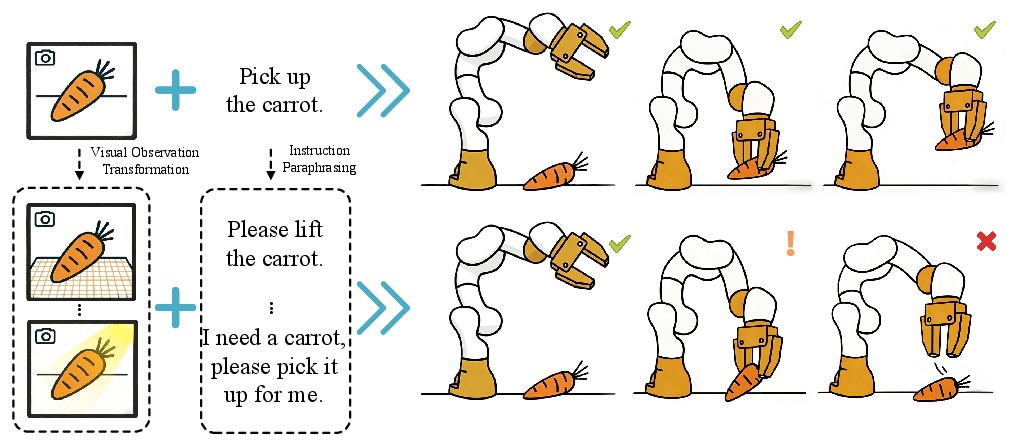
Figure 1: Existing VLA models often lack robustness under visual observation changes and paraphrased but semantically equivalent language instructions.
Methodology: RoVLA Framework
RoVLA addresses these deficiencies through explicit integration of three complementary consistency constraints during policy training: Instructional Consistency (IC), Evolutionary Consistency (EC), and Observational Consistency (OC). This approach utilizes a dual-system architecture comprising a high-level semantic extractor (based on a pretrained VLM) and a low-level continuous action generator (Diffusion Transformer, DiT), operating under a flow-matching action generation paradigm.
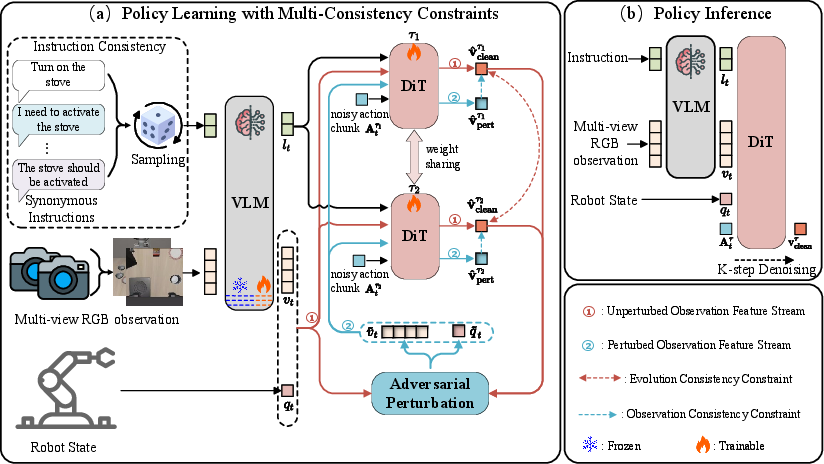
Figure 2: Overview of RoVLA’s architecture and multi-consistency training and inference protocol.
Instructional Consistency (IC)
IC enforces invariance to instruction reformulation. For each trajectory, RoVLA constructs a set of semantically equivalent paraphrases, generated using a strong LLM (Qwen3-8B), and uniformly samples instructions from this set during training. This implicitly regularizes the policy to ground actions in task intent instead of surface-level linguistic patterns, without requiring additional loss terms.
Evolutionary Consistency (EC)
EC promotes stability of action intent across the trajectory denoising process by enforcing pairwise similarity between predicted velocity fields at different flow-matching timesteps. This addresses policy drift and ensures smoother, more coherent generation of action sequences.
Observational Consistency (OC)
OC targets robustness against adversarial and naturally occurring perturbations in both visual and proprioceptive inputs. During training, RoVLA introduces targeted perturbations along directions that most disrupt EC (based on gradient signals), then constrains the model such that the velocity field predictions with perturbed and clean inputs remain consistent, using a stop-gradient operator to prevent mutual collapse.
The overall training objective combines these elements with scheduled weighting, ensuring that consistency constraints become more influential as action prediction stabilizes during training.
Experimental Evaluation
RoVLA is evaluated on LIBERO-Plus, RoboTwin 2.0, and a real-world tabletop manipulation suite based on Franka Research 3, with benchmarks designed to stress test invariance against visual, linguistic, and environmental perturbations.
LIBERO-Plus
RoVLA sets strong numerical benchmarks, achieving a zero-shot overall success rate of 74.3%, outperforming other VLA paradigms (e.g., OpenVLA-OFT: 69.6%, RIPT-VLA: 68.4%, π0-Fast: 61.6%). The most prominent margins are on language perturbations, where RoVLA attains 92.9% success under paraphrased instructions, exceeding the backbone by 16.6% and the strongest baseline by 13.4%. With exposure to perturbations during fine-tuning, RoVLA’s performance further increases to 82.0%—the best overall compared to all tested approaches.
RoboTwin 2.0
RoVLA delivers the best overall success rates in both Clean (48.2%) and Randomized (50.0%) settings, outperforming established baselines including those leveraging large-scale cross-embodiment pretraining. Its margins are most significant in settings demanding target grounding and spatial generalization under scene variation.

Figure 3: Qualitative rollouts from RoboTwin 2.0 showing RoVLA’s stable execution despite significant randomization in pose, layout, and appearance.
Real-World Tabletop Manipulation
RoVLA also surpasses strong baselines on five real-world manipulation tasks, achieving a 60% overall success rate versus 50% for GR00T-N1.6 (large-scale pretrained) and 38% for the backbone, with improvements evident on tasks requiring transfer from simulated to physical environments.

Figure 4: Real-world tabletop tasks used for end-to-end evaluation on manipulation, perception, and language understanding.
Ablation and Qualitative Results
Ablation studies confirm the orthogonal impact of each consistency constraint. IC provides the primary gain for language robustness, EC ensures action evolution stability, and OC imparts resilience to input perturbations. The synergy among these constraints yields the most balanced and robust policy. Qualitative results show visually stable behaviors under compounding perturbations, both in simulation (e.g., clutter, viewpoint, lighting, paraphrases) and in the real world.

Figure 5: Rollout examples on LIBERO-Plus under increased clutter, paraphrased instructions, lighting changes, blur, and viewpoint shifts—RoVLA actions remain stable.

Figure 6: Real-world rollout snapshots demonstrate RoVLA’s stable execution and adaptability under variable object configurations and failure-retry conditions.
Implications and Outlook
RoVLA demonstrates that explicit multi-consistency enforcement is an effective strategy for achieving robust, generalizable embodied VLA policies. By treating invariance to semantically-preserving transformations as a first-class objective, RoVLA policies can more reliably decouple task intent from confounding correlations across the perception-action pipeline.
On the practical front, this approach directly benefits real-world deployment of generalist robots operating in environments where surface-level visual or linguistic distributions are highly variable. Theoretically, the work encourages broader adoption of consistency-based objectives in multimodal policy learning, and suggests directions for augmenting robustness in policy architectures beyond data scaling and post hoc adaptation.
Several challenges remain—RoVLA exhibits limited improvements for tasks involving fine contact dynamics or intricate bimanual coordination. Effectively incorporating geometric/dynamics constraints and modeling fine-grained manipulation remains an important avenue for future work. Extensions could also consider optimizing consistency over temporally extended world models and composing inductive biases regarding spatial or causal structure.
Conclusion
RoVLA introduces a principled, multi-consistency constrained framework for robust vision-language-action learning, validated by comprehensive simulation and real-world benchmarks. Its consistently strong performance under diverse perturbations provides compelling evidence that explicit policy-level invariance constraints are essential for advancing the reliability and applicability of generalist VLA agents (2605.19678).

