VISReg: Variance-Invariance-Sketching Regularization for JEPA training
Abstract: Self-supervised learning methods prevent embedding collapse via modeling heuristics or explicit regularization of the embedding space. Among the latter, VICReg decomposes regularization into variance and covariance objectives, offering flexibility and interpretability. However, covariance captures only second-order statistics -- encouraging decorrelation but failing to enforce the full distributional shape needed for stable training. Sketching-based methods such as SIGReg address this by aligning embeddings to an isotropic Gaussian, but lack flexibility and suffer from vanishing gradients under collapse. We propose Variance-Invariance-Sketching Regularization (VISReg), which replaces covariance with a Sliced-Wasserstein-based sketching objective that enforces full distributional shape, while retaining a variance term for scale control. By decoupling scale and shape, VISReg combines VICReg's flexibility with the distributional rigor of sketching methods, providing robust gradients even under collapse. We show that VISReg scales linearly, outperforms existing regularization on low-quality datasets, and is resilient to long-tailed and low-rank regimes. Pre-trained on ImageNet-1K, VISReg achieves state-of-the-art performance on out-of-distribution datasets. Pre-trained on ImageNet-22K, it matches DINOv2's OOD performance despite the latter using 10x more data (LVD-142M). Project and code: https://haiyuwu.github.io/visreg.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “VISReg: Variance‑Invariance‑Sketching Regularization for JEPA training”
1) What is this paper about?
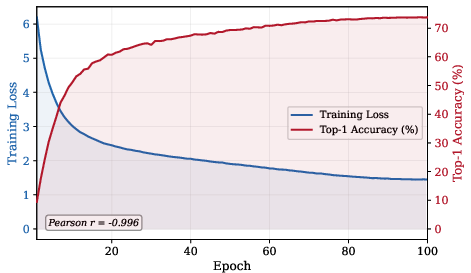
This paper is about teaching computers to learn from lots of images without needing people to label them. The authors introduce a new method called VISReg that helps a model learn stable, useful “features” from images. VISReg aims to work well without relying on special training tricks and to do better on new, different data it hasn’t seen before.
2) What questions are the researchers trying to answer?
- How can we stop a model from “collapsing” (predicting almost the same thing for every image) when training without labels?
- Can we guide the model to learn features that are not just “uncorrelated,” but have a healthy, well‑shaped spread in feature space?
- Can we make this guidance strong and reliable even if the model starts to collapse?
- Will this method scale to big models and big datasets without being too slow or memory‑hungry?
- Does this lead to features that transfer better to new tasks and unfamiliar types of images (out‑of‑distribution or OOD data)?
3) How does VISReg work? (Simple explanation with analogies)
Think of each image as a point in a high‑dimensional space, where the coordinates come from the model’s “embedding” (a compact summary of the image). Good learning means:
- Images that are actually the same thing (just different crops or lighting) should end up with similar points.
- The cloud of points for all images should be well‑spread and nicely shaped, not squashed into a line or a single clump.
VISReg uses three ideas to make this happen:
- Variance (keep things spread out): Imagine your class standing in a field. If everyone stands in exactly one spot, you learn nothing about where anyone is. VISReg’s variance rule encourages people to spread out so each “direction” in feature space isn’t flat. This helps prevent collapse.
- Invariance (match different views of the same thing): If we take two crops of the same image, the model should produce similar features for both. This teaches the model what’s important about an object, not just the exact crop or lighting.
- Shape regularization with “slices” (make the cloud look round and healthy):
- Shine a flashlight from many directions and look at the shadows (these are 1D projections or “slices”).
- For each shadow, sort the points and compare them to the shadow of a perfect bell‑curve (a normal distribution).
- Make the model adjust so all shadows look like bell‑curves. If all shadows look right, the whole 3D (or high‑D) shape is well‑formed.
This “shadow matching” uses a tool called Sliced Wasserstein Distance (SWD). It’s like measuring how far two sets of sorted numbers are from each other, which is fast and stable.
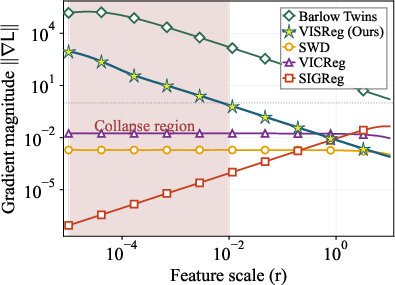
A key detail: VISReg separates “scale” (how big the cloud is) from “shape” (how the cloud looks). It controls scale with variance and shape with the sliced comparison, so the two don’t interfere. This gives strong, reliable training signals even when the model starts to collapse.
Why is this efficient?
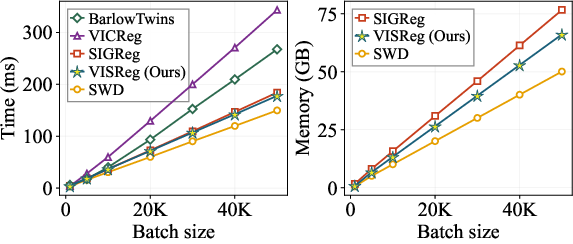
- Computing old methods’ correlations grows fast with the number of features (like checking every pair of directions). VISReg’s slicing compares many 1D shadows, which scales roughly linearly with batch size and feature dimension, so it’s friendlier for large models.
4) What did they find, and why does it matter?
The authors tested VISReg against popular methods like DINO, VICReg, and SIGReg on many tasks. Key takeaways:
- More stable training without “tricks”: Many powerful methods rely on extra “heuristics” (like special teacher models or momentum tricks) to avoid collapse. VISReg avoids those and stays stable using its variance + shape design.
- Better on unfamiliar data (OOD): VISReg often did best when tested on datasets different from the training data (like medical images or satellite photos). This means the features it learns are more general and useful in the real world.
- Strong on messy or imbalanced datasets: On “low‑quality” datasets—like long‑tailed ones with many rare classes (ImageNet‑LT) or low‑information images (Galaxy10)—VISReg stayed robust and performed better than alternatives.
- Competitive transfer learning: After fine‑tuning on new tasks, VISReg matched or beat strong baselines, even when those baselines had higher scores on simple “linear probe” tests. In practical terms, VISReg’s features helped real tasks more.
- Scales well and remains fast: Because the sliced method is efficient, VISReg is suitable for large models and large batches. It can also spread the “slices” across multiple GPUs, keeping runtime manageable.
- Not perfect at everything: On some dense prediction tasks (like segmentation), VISReg was good but didn’t top the very best methods. There’s still room to improve in that area.
Why it matters: These results suggest VISReg learns more broadly useful features with less reliance on fragile training tricks—good news for building strong “foundation models” that help across many domains.
5) What’s the impact of this research?
- More dependable self‑supervised learning: VISReg reduces the need for special, hard‑to‑tune training hacks, making training simpler and more explainable.
- Better generalization: Doing well on new, different data is critical for real applications—healthcare images, satellite views, scientific data, and more. VISReg shines here.
- Scalable and efficient: Its design fits big models and big batches without blowing up compute or memory, which is essential for modern AI.
- Practical guidance: The paper also shares hyperparameter tips and shows how to adjust the “shape” weight for tougher datasets.
- Future directions: Improving dense tasks like segmentation is a next step, but VISReg already provides a strong foundation.
In short, VISReg is like teaching a model to keep its feature space evenly spread and well‑shaped using simple, powerful checks from many directions—leading to stable learning and features that actually help on a wide range of real‑world tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future work.
- Formal theory of collapse avoidance: provide convergence guarantees or conditions under which VISReg provably prevents collapse (beyond empirical gradient plots), including analysis of the stationary points of the full VISReg objective.
- Sample complexity of sketching: derive bounds relating the number of slices K, embedding dimension D, batch size N, and desired approximation error for enforcing isotropy via SWD projections.
- Choice and scheduling of K: develop principled rules or adaptive schedules for K across training (and D), beyond the empirical “K > C·D” observation and the multi-GPU workaround.
- Sorting step differentiability and stability: analyze gradients through sorting (ties, non-smoothness), evaluate soft-sort/quantile approximations, and quantify their impact on stability and accuracy.
- Computational burden of sorting at scale: measure real wall-clock and memory costs on large N and K (beyond simulations), and explore approximate order statistics, bucketing, or partial sorting to reduce O(K·N log N).
- Effect of batch size on distribution matching: quantify statistical bias/variance of aligning to Gaussian quantiles with small N; assess cross-batch strategies (e.g., EMA of quantiles, queue) to stabilize the shape loss.
- Stop-gradient decoupling effects: provide theoretical and empirical analysis of how stop-gradient on std affects optimization dynamics, bias in scale/shape coupling, and final representation quality.
- Target prior choice: test non-Gaussian isotropic priors (e.g., Laplace, generalized Gaussian, elliptical heavy-tailed) to assess whether Gaussian is optimal for OOD and transfer performance.
- Adaptive or learned projection directions: compare random directions to orthonormal bases, spherical t-designs, quasi-Monte Carlo, or learned/max-sliced directions to improve coverage of the unit sphere with fewer K.
- Scheduling of scale vs shape weights: study curriculum or adaptive weighting between L_scale, L_shape, and L_center over training, rather than fixed λ values, to improve stability and generalization.
- Robustness under extreme collapse: analyze SWD gradients when per-dimension std approaches zero (epsilon handling), and characterize numerical stability and recovery dynamics rigorously.
- Interaction with LayerNorm and architectural choices: study how scale-shape decoupling interacts with LayerNorm, projector depth/width, and backbone normalization layers.
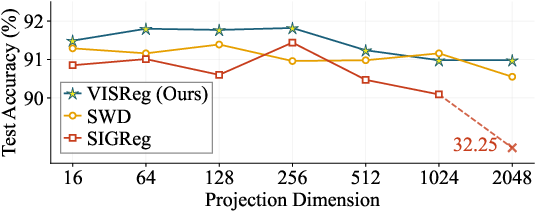
- Automatic selection of projection dimension: devise criteria or meta-learning strategies to choose projector dimensionality per downstream goal (in-domain vs OOD vs dense prediction), instead of manual tuning.
- Invariance loss design: compare the mean-of-globals MSE predictor to alternative JEPA predictors (e.g., teacher-student, predictive coding variants) and quantify trade-offs with VISReg regularization.
- Augmentation dependence: ablate augmentation policies and strengths to understand sensitivity, stability margins, and OOD consequences under weaker/stronger augmentations.
- Fairness of baselines and hyperparameter tuning: reproduce strong baselines with matched tuning budgets (e.g., DINO with extensive tuning on low-quality data) to isolate VISReg’s gains from under-tuned comparisons.
- Seed variability and reproducibility: report variance across random seeds (including random projections) and provide confidence intervals to assess robustness of conclusions.
- Broader OOD robustness: evaluate corruption robustness (ImageNet-C, ImageNet-R/S/A), spurious correlation benchmarks, adversarial robustness, and calibration under shift.
- Detection and dense tasks: extend evaluation to object detection/instance segmentation (e.g., COCO, LVIS) and more challenging dense tasks to pinpoint why a gap remains to MoCoV3/iBOT and how to reduce it.
- Multi-modal and non-vision domains: assess applicability to audio, text, graphs, molecules, and video, including domain-specific priors and projection strategies.
- Large-scale empirical scaling: provide real multi-node training measurements (not simulated) at high batch sizes and large D (e.g., ViT-H/G) to validate claimed linear scaling and memory efficiency.
- Communication and synchronization details: clarify how per-GPU slices are aggregated across devices for the loss, quantify communication overhead, and study trade-offs between local/global slice pooling.
- Long-tail and low-rank regimes: beyond increasing shape loss weight, investigate targeted strategies (e.g., class-conditional or instance-reweighted sketching) and analyze why shape weighting helps these regimes.
- Centering loss role: analyze when L_center helps or harms (e.g., with few-shot batches), and whether it’s redundant given centering in preprocessing; explore alternatives (e.g., whitening-free mean control).
- Interaction with heuristics: test whether combining VISReg with mild heuristics (EMA teacher, centering/sharpening) narrows in-domain gaps without losing OOD gains.
- Failure modes on multi-modal embeddings: study whether enforcing a Gaussian prior can oversmooth or distort intrinsically multi-modal feature distributions and how to preserve cluster structure.
- Generative guidance breadth: validate guidance benefits across diverse generators/diffusion backbones, datasets, and sampling regimes (CFG on/off), and ablate which VISReg features matter.
- Privacy and memorization: investigate whether stronger distributional shape matching reduces or exacerbates representation memorization and membership inference risk.
- Theoretical link to information content: connect VISReg objectives to information-theoretic quantities (e.g., MI bounds), clarifying how scale and shape constraints regulate information and redundancy.
- Runtime–accuracy trade-offs: systematically map Pareto fronts over K, D, batch size, and epochs to furnish practical recipes under resource constraints.
- Curriculum across data quality: design adaptive λ and K schedules driven by online estimates of rank/long-tail severity to automate handling of low-quality datasets.
Practical Applications
Immediate Applications
Below are concrete, deployable uses that organizations can adopt now, based on VISReg’s findings about robust, heuristic‑free self‑supervised training, superior OOD generalization, linear scaling, and robustness to low‑quality (long‑tailed/low‑rank) datasets.
- Sector: Software/ML Platforms — Application: Drop‑in replacement for covariance regularizers in SSL pipelines
- Tools/workflows: Integrate the provided PyTorch reference (visreg function) into existing JEPA/VICReg/Barlow Twins codebases; add per‑GPU sliced projections; adopt suggested defaults (λ≈0.9 on ImageNet‑scale; K≈4096 per GPU; 2 global + 6 local views).
- Assumptions/dependencies: ViT backbones supported out of the box; for other encoders, confirm stability; batch augmentation strategy similar to LeJEPA; ensure K is adequate for chosen projection dimension D (or distribute slices across GPUs).
- Sector: Healthcare (medical imaging) — Application: Label‑efficient pretraining with improved out‑of‑distribution (OOD) robustness
- Tools/workflows: Pretrain on unlabeled PACS archives; linear probe or fine‑tune for tasks like organ classification or chest X‑ray triage; exploit VISReg’s robustness to “low‑rank” images (large dark regions) and long‑tailed labels.
- Assumptions/dependencies: Institutional review/PHI compliance; clinical validation required; OOD gains demonstrated on medical benchmarks (e.g., OrganAMNIST) but task‑specific verification is needed; segmentation remains behind MoCoV3/iBOT.
- Sector: Remote Sensing/Energy/Utilities — Application: Unlabeled aerial/satellite imagery pretraining for asset mapping and anomaly detection
- Tools/workflows: Pretrain VISReg on historical, heterogeneous aerial data; deploy for land‑use classification (AID), vegetation monitoring, and infrastructure inspection with OOD domain shifts (seasonality, sensors).
- Assumptions/dependencies: Sufficient diversity in pretraining imagery; set higher shape‑loss weight on low‑quality or long‑tailed datasets; ensure compute for large tiles or use tiling strategies.
- Sector: Astronomy/Space — Application: Representation learning on telescope data with sparse labels
- Tools/workflows: Pretrain on archival sky surveys; apply linear probe/fine‑tuning for morphology classification (e.g., Galaxy10) and rare event discovery.
- Assumptions/dependencies: Image pre‑processing pipelines (denoising, normalization); validate on new instruments (domain shift).
- Sector: Manufacturing/Industrial Inspection — Application: Defect detection under long‑tailed distributions
- Tools/workflows: VISReg pretraining on unlabeled line imagery; fine‑tune small heads for few/rare classes; leverage stability on skewed datasets.
- Assumptions/dependencies: Camera consistency helps but not required; rare‑defect validation data needed; sensitivity to lighting and motion blur should be tested.
- Sector: Retail/E‑commerce — Application: Product categorization and attribute tagging across vendors/countries (OOD)
- Tools/workflows: Pretrain on mixed‑domain product images; fine‑tune small classifiers; deploy for cold‑start categories or marketplaces with skewed inventory.
- Assumptions/dependencies: Ensure augmentations don’t destroy fine attributes; multilingual/metadata alignment is separate.
- Sector: Robotics — Application: Robust perception pretraining for environment shifts (indoor/outdoor, lighting, clutter)
- Tools/workflows: Gather unlabeled robot egocentric streams; VISReg pretraining; fine‑tune detectors/segmentation; benefit from stable gradients (reduced collapse risk) without teacher‑student heuristics.
- Assumptions/dependencies: Real‑time inference unaffected; pretraining is offline; segmentation performance is adequate but not SOTA.
- Sector: Public Sector/Safety — Application: OOD‑aware computer vision for disaster response and infrastructure monitoring
- Tools/workflows: Pretrain on mixed aerial/body‑cam/CCTV streams; deploy linear probes for fast triage; monitor shifts via OOD metrics based on VISReg embeddings.
- Assumptions/dependencies: Privacy constraints; validate for fairness/coverage; domain‑specific robustness checks.
- Sector: Education/Academia — Application: Reproducible SSL baselines without EMA teachers and heavy heuristics
- Tools/workflows: Course labs using VISReg as a clean SSL reference; assignments testing λ, K, D trade‑offs; experiments on small datasets (ImageNette/Galaxy10).
- Assumptions/dependencies: GPU availability; slicing across multiple GPUs if D is large.
- Sector: Generative Modeling — Application: Better semantic guidance for training diffusion/transformer generators
- Tools/workflows: Replace DINO guidance with VISReg embeddings in iREPA‑style pipelines; modest gains in gFID/precision/recall already demonstrated.
- Assumptions/dependencies: Gains are incremental; task‑dependent tuning required; not a replacement for text guidance where semantics are linguistic.
- Sector: MLOps/Compute Efficiency — Application: Scale‑friendly SSL regularization with linear complexity
- Tools/workflows: Use VISReg to avoid O(D2) covariance cost; distribute slices across M GPUs to keep per‑GPU K small; monitor gradient norms to detect collapse.
- Assumptions/dependencies: Sorting cost O(K N log N) is manageable at target batch sizes; memory planning for K and D.
- Sector: Trust & Safety — Application: OOD content detection and robust embedding moderation
- Tools/workflows: Train VISReg backbone on diverse web imagery; build OOD detectors and similarity search robust to distribution shift.
- Assumptions/dependencies: Must curate sensitive content carefully; separate policy layers enforce safety decisions; performance audits across demographics/domains.
- Sector: Finance/RegTech — Application: Document image understanding across jurisdictions and templates
- Tools/workflows: Pretrain on unlabeled KYC/claims document scans; fine‑tune for form classification/field localization; benefit from OOD robustness to new layouts.
- Assumptions/dependencies: Data handling compliance; OCR/NLP integration for text extraction remains separate; verify on non‑Latin scripts.
Long-Term Applications
These opportunities likely require additional research, scaling, or validation beyond the paper’s scope.
- Sector: Autonomous Driving — Application: OOD‑robust perception from massive unlabeled dashcam video
- Tools/products: VISReg‑JEPA pretraining on fleet logs; rare scenario mining; improved Sim2Real transfer for corner cases.
- Assumptions/dependencies: Large‑scale video adaptation (temporal/multi‑view invariances); safety validation; multi‑sensor fusion.
- Sector: Multimodal AI — Application: Extending variance‑invariance‑sketching to audio, text, and cross‑modal embeddings
- Tools/products: VISReg‑style regularization in multimodal JEPA or CLIP‑like encoders; shape‑scale decoupling for modality‑specific noise.
- Assumptions/dependencies: Theory/implementations for non‑image modalities; task‑specific augmentations; careful projection‑dimension selection.
- Sector: Biomedical/Clinical AI — Application: Institution‑specific foundation models with fewer labels and stronger OOD
- Tools/products: Hospital‑scale VISReg pretraining with secure compute; rapid downstream customization (radiology, pathology).
- Assumptions/dependencies: Regulatory approval; rigorous external validation; bias/fairness audits; governance for continual updates.
- Sector: Edge/On‑device Learning — Application: Lightweight continual SSL on devices without teacher‑student overhead
- Tools/products: VISReg‑like regularizers optimized for mobile/embedded accelerators; periodic slice‑generation strategies.
- Assumptions/dependencies: Further optimization to reduce sorting and projection costs; energy constraints; privacy‑preserving updates.
- Sector: Robotics (Sim2Real) — Application: Regularization for transferring from simulated data to varied real environments
- Tools/products: VISReg pretraining on mixed sim and real streams; OOD‑aware policy learning.
- Assumptions/dependencies: Integration with control policies; handling temporal dynamics; compute for large‑scale sim data.
- Sector: Scientific Discovery — Application: SSL on microscopy, materials, climate, and particle physics data
- Tools/products: VISReg toolkits tailored to low‑rank scientific imagery; OOD‑robust representations for downstream hypothesis testing.
- Assumptions/dependencies: Domain‑specific augmentations; collaboration with scientists for label curation; benchmarking suites.
- Sector: Policy/Standards — Application: OOD evaluation frameworks and procurement standards for vision foundation models
- Tools/products: OOD performance checklists leveraging VISReg‑style regularization; guidance on decoupled scale/shape monitoring.
- Assumptions/dependencies: Community consensus on OOD benchmarks; transparent reporting; compatibility with regulatory regimes.
- Sector: Education/Workforce — Application: Curriculum and tooling for robust SSL at scale in public institutions
- Tools/products: Open curricula, AutoVISReg hyperparameter assistants (λ/K/D), multi‑GPU slice orchestration tooling.
- Assumptions/dependencies: Funding for shared compute; educator training; open datasets with broad licenses.
- Sector: Security/Anomaly Detection — Application: OOD‑centric embeddings for rare event/attack detection in imagery
- Tools/products: VISReg‑based embedding services powering visual anomaly dashboards; integration with SIEM/SOAR tooling.
- Assumptions/dependencies: Domain‑specific thresholds; adversarial robustness remains an open area.
- Sector: Platform Ecosystem — Application: Turnkey “OOD‑ready” foundation model services
- Tools/products: Cloud offerings that pretrain VISReg models on customer data; automated K/λ tuning; governance dashboards tracking collapse/shape alignment.
- Assumptions/dependencies: Managed data pipelines; privacy/SLA requirements; scaling to >100M images.
- Sector: Dense Prediction Excellence — Application: Closing the gap to MoCoV3/iBOT in segmentation/detection
- Tools/products: VISReg variants tailored to dense tasks (projection‑dim schedule, loss reweighting, local‑view strategies).
- Assumptions/dependencies: Further research on projection dimension vs. dense performance; benchmarking across COCO/ADE20K.
- Sector: Foundation‑Model Efficiency — Application: Less‑data pretraining with DINOv2‑level OOD performance
- Tools/products: “10×‑less‑data” pretraining playbooks; VISReg‑based active data selection to maximize OOD generality.
- Assumptions/dependencies: Validation that results generalize beyond reported datasets; scaling studies on proprietary corpora.
Notes on Feasibility and Dependencies (cross‑cutting)
- Compute/scaling: VISReg regularization scales as O(N D K); sorting adds O(K N log N). Keep K modest per GPU and distribute slices across GPUs to maintain throughput.
- Hyperparameters: Defaults are practical (e.g., λ≈0.9 for large datasets; λ≈0.6 for small datasets; projection dimension 256–512 depending on task). Increase shape‑loss weight for low‑quality/long‑tailed datasets.
- Backbones and tasks: Results shown on ViT‑B/L; other backbones may need tuning. For dense prediction, VISReg is competitive but not SOTA.
- Data/augmentations: Uses multi‑view crops (global/local). OOD gains rely on diverse unlabeled corpora; narrow domains may limit benefits.
- Governance: OOD robustness does not guarantee fairness, safety, or clinical efficacy; domain‑specific validation and monitoring remain necessary.
Glossary
- ADE20K: A benchmark dataset for semantic segmentation used to evaluate dense prediction. "linear segmentation on ADE20K"
- AID: Aerial Image Dataset used for scene classification and OOD evaluations. "AID has the aerial images."
- AU-ROC: Area Under the Receiver Operating Characteristic curve; a threshold-independent binary classification metric. "The metric is AU-ROC for ChestXRay"
- Barlow Twins: A self-supervised method that reduces redundancy by decorrelating representations via cross-correlation. "Barlow Twins~\cite{barlow-twins} minimizes redundancy in the cross-correlation matrix between twin networks."
- batch size invariance: A property where a method’s behavior is stable across different batch sizes. "maintain the batch size invariance"
- centering loss: A term that penalizes non-zero mean embeddings to stabilize training. "so we include a centering loss:"
- covariance regularization: A constraint that discourages correlated embedding dimensions by penalizing covariance structure. "covariance regularization captures only second-order statistics"
- cross-correlation matrix: A matrix of correlations between two sets of variables (e.g., twin network outputs) used to measure redundancy. "cross-correlation matrix between twin networks."
- decorrelation: The process of reducing correlation among features to increase information content. "encourages decorrelation"
- Embedding collapse: A failure mode where embeddings converge to a trivial constant or low-variance solution. "Embedding collapse prevention."
- EMA: Exponential Moving Average; a parameter-averaging heuristic to stabilize training. "e.g., EMA, frozen layers, teacher-student architectures"
- Epps-Pulley test: A normality test based on the empirical characteristic function, used for distributional alignment. "based on the Epps-Pulley test"
- hard-negative mining: Selecting particularly challenging negative samples to improve contrastive learning. "hard-negative mining"
- heuristic-free: Training without ad-hoc stabilizing tricks, relying instead on principled objectives. "heuristic-free self-supervised training"
- invariance objective: A loss encouraging consistency of representations across augmented views. "For the invariance objective, we follow LeJEPA"
- isotropic Gaussian: A spherical Gaussian prior with identical variance in all directions, often used as a target distribution. "isotropic Gaussian"
- JEPA (Joint-Embedding Predictive Architectures): Architectures that learn by predicting or aligning joint embeddings of multiple views. "Joint-Embedding Predictive Architectures"
- KL divergence: A measure of discrepancy between probability distributions used in probabilistic regularization. "KL divergence"
- linear probe: A protocol that trains a linear classifier on frozen embeddings to assess representation quality. "linear probe accuracy"
- linear segmentation: Evaluating segmentation by training a linear decoder on frozen features. "linear segmentation experiment"
- long-tailed: Refers to datasets where class frequencies follow a heavy-tailed distribution, challenging balanced learning. "long-tailed datasets"
- low-rank: Data or embeddings lying in a low-dimensional subspace, which can exacerbate collapse or overfitting. "low-rank"
- Maximum Mean Discrepancy (MMD): A kernel-based distance between distributions used for two-sample testing or regularization. "MMD"
- mIoU: Mean Intersection-over-Union; a standard metric for segmentation quality. "mIoU for ADE20K"
- momentum queue: A queue of past embeddings maintained with momentum to provide negatives at scale. "introduced a momentum queue"
- momentum-updated teacher: A teacher network updated as an EMA of the student to stabilize self-supervised training. "utilize a momentum-updated teacher"
- negative sampling: Selecting non-matching pairs as negatives in contrastive objectives. "eliminates the need for negative sampling entirely."
- online clustering: Clustering performed during training to assign targets or prototypes in self-supervision. "online clustering problem via the Sinkhorn-Knopp algorithm."
- optimal transport: A mathematical framework for measuring distances between probability distributions. "grounded in optimal transport"
- order statistic: The sorted values of samples, used in closed-form 1D Wasserstein computations. "order statistic"
- out-of-distribution (OOD): Data that differ from the training distribution, used to test generalization. "out-of-distribution (OOD)"
- predictor networks: Auxiliary networks used to predict target embeddings and break symmetry. "predictor networks"
- prototype-based learning: Methods that use learnable prototypes/centroids to organize and supervise representations. "prototype-based learning"
- quantile functions: Inverse CDFs used to compute 1D Wasserstein distances via quantile matching. "quantile functions"
- Radon transform: An integral transform over hyperplanes; used with Cramér–Wold ideas for distributional alignment. "The Radon transform~\cite{radon-transform}"
- Sinkhorn-Knopp algorithm: An iterative matrix-normalization algorithm used for entropy-regularized OT and clustering. "Sinkhorn-Knopp algorithm."
- Sliced Wasserstein Distance (SWD): A distributional distance computed by averaging 1D Wasserstein distances over random projections. "Sliced Wasserstein Distance (SWD)"
- stop-gradient: Operation that blocks gradient flow through a tensor to decouple objectives. "stop-gradient"
- teacher-student architectures: Asymmetric setups where a teacher guides a student, often with EMA updates. "teacher-student architectures"
- variance constraint: A penalty that keeps per-dimension variance near a target to control embedding scale. "a variance constraint"
- ViT-B/16: A Vision Transformer model variant with base size and 16-pixel patches. "ViT-B/16"
- Wasserstein distance: An optimal-transport-based metric between distributions; in 1D it has a quantile-based closed form. "2-Wasserstein distance"
- whitening: Transforming data to have zero mean and identity covariance to remove correlations. "performs whitening."
Collections
Sign up for free to add this paper to one or more collections.