- The paper introduces a formal probabilistic framework (VJE) that replaces deterministic joint embeddings with calibrated uncertainty estimates.
- It decouples directional and radial embedding errors using polar factorization and heavy-tailed Student-t likelihoods for robust learning.
- It demonstrates competitive discriminative performance and enhanced anomaly detection through normalized likelihood-based training.
Motivation and Context
Variational Joint Embedding (VJE) introduces a principled probabilistic framework for self-supervised representation learning, departing from conventional deterministic joint embedding approaches. Existing methods in the non-contrastive paradigm, such as SimSiam, BYOL, VICReg, and Barlow Twins, focus on learning representations by enforcing alignment between paired views, employing architectural heuristics to avoid representational collapse and sidestepping the need for negative examples. However, these methods produce deterministic, point embeddings and lack calibrated uncertainty and normalized probabilistic semantics in latent space, limiting their applicability in uncertainty-aware domains such as anomaly detection, medical imaging, and reinforcement learning.
Variational inference, represented by VAEs, establishes distributional semantics by modeling latent variables as posterior distributions, but relies heavily on pixel-level reconstruction, which is suboptimal when downstream tasks depend on abstract, non-pixel semantic factors. Attempts to merge variational approaches with self-supervised architectures have been hindered by incoherent probabilistic interpretations and constrained uncertainty representations. VJE addresses these limitations by constructing a latent-variable model directly in representation space and optimizing a symmetric conditional evidence lower bound (ELBO) on paired embeddings, establishing normalized likelihood-based learning for self-supervised embeddings.
Model Architecture and Objective
VJE consists of a shared encoder fθ that maps two stochastically augmented views (x1, x2) to feature embeddings (z1, z2). An inference network (gϕ) parameterizes a diagonal Gaussian variational posterior qi(s)=N(μi,diag(σi2)) for each view, leveraging amortized inference in place of conventional predictor networks. The posterior variance vector σi2 is tied to the directional likelihood scale, ensuring that feature-wise uncertainty is shared coherently across both regularization and likelihood evaluation.
Residuals between embeddings are decomposed via polar factorization: directional and radial discrepancies are evaluated independently with heavy-tailed Student-t likelihoods. The directional channel utilizes extrinsic whitening in RD to enable anisotropic weighting, while the radial component is parameterized as a norm-difference, decoupling scale from angular alignment. KL regularization toward a standard Gaussian prior maintains geometric coherence, explicitly anchoring the latent space.
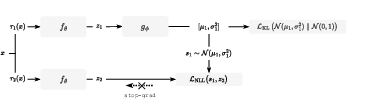
Figure 1: The asymmetric forward pass for VJE, illustrating encoder, inference network, posterior sampling, and evaluation of directional and radial Student-t likelihoods with the target branch detached to enforce fixed-observation semantics.
The training objective maximizes a symmetric conditional ELBO across paired directions, combining directional and radial negative log-likelihoods with the KL penalty:
L=LNLL+βLKL,
where LNLL integrates the directional and radial Student-t terms, and β tunes the strength of KL regularization.
Theoretical Contributions
VJE’s architecture is motivated by two main design principles:
- Normalized Likelihood-based Training: Unlike energy-based objectives (e.g., squared-error or cosine losses), VJE defines a tractable, normalized probabilistic model in representation space. This enables density-based scoring and explicit uncertainty quantification.
- Decoupled Directional and Radial Errors: By separating embedding residuals into angular and norm discrepancies via polar factorization, VJE prevents norm-induced instabilities and ensures robust learning under heavy-tailed distributions.
To stabilize optimization and avoid unbounded gradients for large residuals (a typical failure of Gaussian likelihoods), VJE employs Student-t likelihoods:
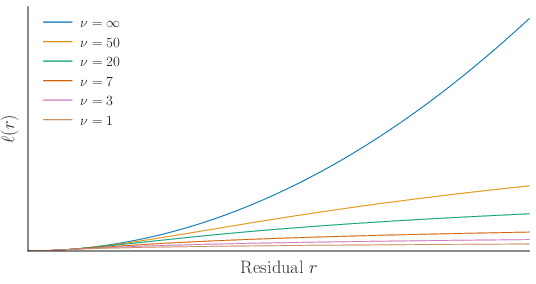
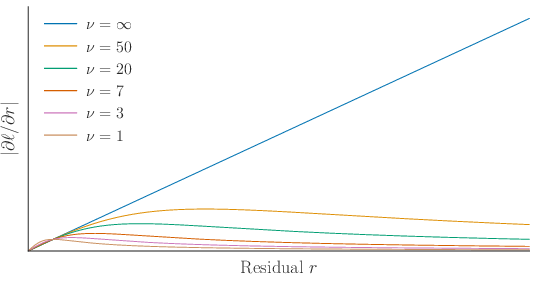
Figure 2: Negative log-likelihood and gradient magnitude for Student-t versus Gaussian residuals, showing bounded influence and robustness to outliers for heavy-tailed Student-t likelihoods.
Feature-wise uncertainty is parameterized directly through the posterior variance vector and directional likelihood whitening, introducing anisotropy without auxiliary projection heads or batch-based regularizers. The analytic KL divergence imposes geometric anchoring and prevents degenerate solutions.
Empirical Results
VJE achieves competitive discriminative performance relative to established non-contrastive baselines across both large-scale and low-data regimes:
- ImageNet-1K (ResNet-50): VJE attains 65.6% top-1 accuracy under linear probe evaluation, matching SimCLR and BYOL, trailing SimSiam and VICReg by a modest margin while providing probabilistic semantics.
- CIFAR-10 (ResNet-18): VJE achieves 89.98% k-NN accuracy and 92.1% linear probe accuracy on the encoder output, outperforming VICReg and matching SimSiam.
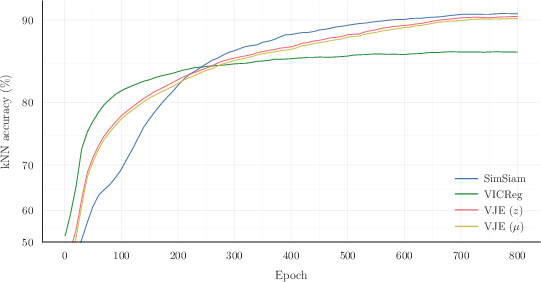
Figure 3: k-NN accuracy trajectories during CIFAR-10 training for SimSiam, VICReg, and VJE, with VJE showing stable convergence and close alignment between encoder output and posterior mean representations.
Ablation studies reveal that the full objective (directional + radial Student-t likelihood, KL penalty) is essential for non-degenerate, anisotropic posterior variance and strong discriminative capacity. Removal of the KL regularizer or either likelihood component leads to collapsed or isotropic posteriors and severe degradation in accuracy.
Probabilistic Semantics and Anomaly Detection
VJE’s normalized probabilistic modelling enables density-based scoring for anomaly detection tasks. In one-class CIFAR-10 anomaly detection (10 splits), VJE (joint Student-t likelihood score, β=1.0, ν=0.5) attains an average AUROC of $0.903$—outperforming generic self-supervised anomaly detectors and demonstrating the utility of likelihood-based uncertainty. Attempts to use Gaussian likelihoods caused posterior collapse and loss of discriminative power, confirming the necessity of heavy-tailed robustness.
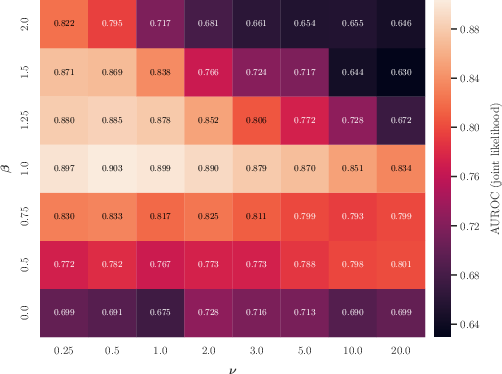
Figure 4: CIFAR-10 one-class detection: class-averaged AUROC across β×ν hyperparameter grid, showing optimal performance concentrated at moderate KL weighting and small degrees of freedom (heavy tails).
The posterior variance and entropy correlate strongly with anomaly detection performance, but joint-likelihood scoring is consistently most effective.
Implications and Future Directions
VJE advances self-supervised learning by providing a normalized, probabilistic formulation that decouples semantic structure from pixel-level reconstruction and enables calibrated uncertainty quantification in representation space. Practically, it offers principled likelihood-based mechanisms for tasks such as anomaly detection without relying on heuristic stabilizations. Theoretically, it distinguishes normalized conditional modelling from standard energy-based objectives and recovers common pointwise loss architectures as limiting cases. This formalism clarifies the geometric and probabilistic semantics of embedding space.
While VJE is modality-agnostic and robust across datasets, a gap exists to deterministic baselines on high-resolution domains under linear probing, suggesting a trade-off between sharpness and uncertainty modelling. Future work should explore extensions to hierarchical or patch-based probabilistic architectures for spatial uncertainty, investigate alternative normalized likelihood families, and generalize VJE’s principles to mixed-modal signals.
Conclusion
Variational Joint Embedding establishes a rigorous probabilistic foundation for non-contrastive self-supervised learning, synthesizing joint embedding and variational inference in a reconstruction-free, non-contrastive paradigm. Through instance-conditioned posteriors, decoupled likelihoods, and analytic geometric regularization, VJE achieves competitive discriminative performance and calibrated density estimation. The approach’s implications extend to uncertainty-sensitive applications, anomaly detection, and theoretical unification of embedding objectives, providing a robust framework for future developments in probabilistic representation learning (2602.05639).