Radial-VCReg: More Informative Representation Learning Through Radial Gaussianization
Abstract: Self-supervised learning aims to learn maximally informative representations, but explicit information maximization is hindered by the curse of dimensionality. Existing methods like VCReg address this by regularizing first and second-order feature statistics, which cannot fully achieve maximum entropy. We propose Radial-VCReg, which augments VCReg with a radial Gaussianization loss that aligns feature norms with the Chi distribution-a defining property of high-dimensional Gaussians. We prove that Radial-VCReg transforms a broader class of distributions towards normality compared to VCReg and show on synthetic and real-world datasets that it consistently improves performance by reducing higher-order dependencies and promoting more diverse and informative representations.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching computers to learn useful information from data without needing labels. The authors introduce a new method called Radial-VCReg. Its goal is to make the “features” a neural network learns more spread out and informative, so they work better for tasks like classifying images. It does this by nudging the lengths of feature vectors to behave like they would if they came from a normal (Gaussian) distribution.
Key Questions
The paper asks:
- How can we get a neural network’s learned features to carry as much useful information as possible without collapsing (becoming too similar)?
- Can we make these features behave more like a high-dimensional Gaussian, which naturally spreads information out as much as possible?
- Does focusing on the “lengths” of feature vectors help achieve this in a practical and stable way?
Methods and Approach
To understand the approach, here are a few simple ideas and analogies:
- Representations/features: When a neural network “looks” at an image, it produces a list of numbers (a feature vector) that captures what it sees. We use these features later for tasks like classification.
- Self-supervised learning: Instead of using labels (like “cat” or “dog”), the model learns by comparing different transformed versions of the same image and encouraging their features to be similar, while still keeping features across different images diverse.
- “Gaussian” and “entropy”: A Gaussian distribution spreads values out in a balanced way. Among all distributions with the same average and spread (mean and variance), Gaussian has the highest entropy. Think of entropy as how “spread out” or “unpredictable” something is. Higher entropy here means more diverse, informative features.
- Curse of dimensionality: In very high dimensions, exactly matching the full shape of a Gaussian is hard. So the authors focus on a simpler, more reliable property of Gaussians.
Here’s the key trick:
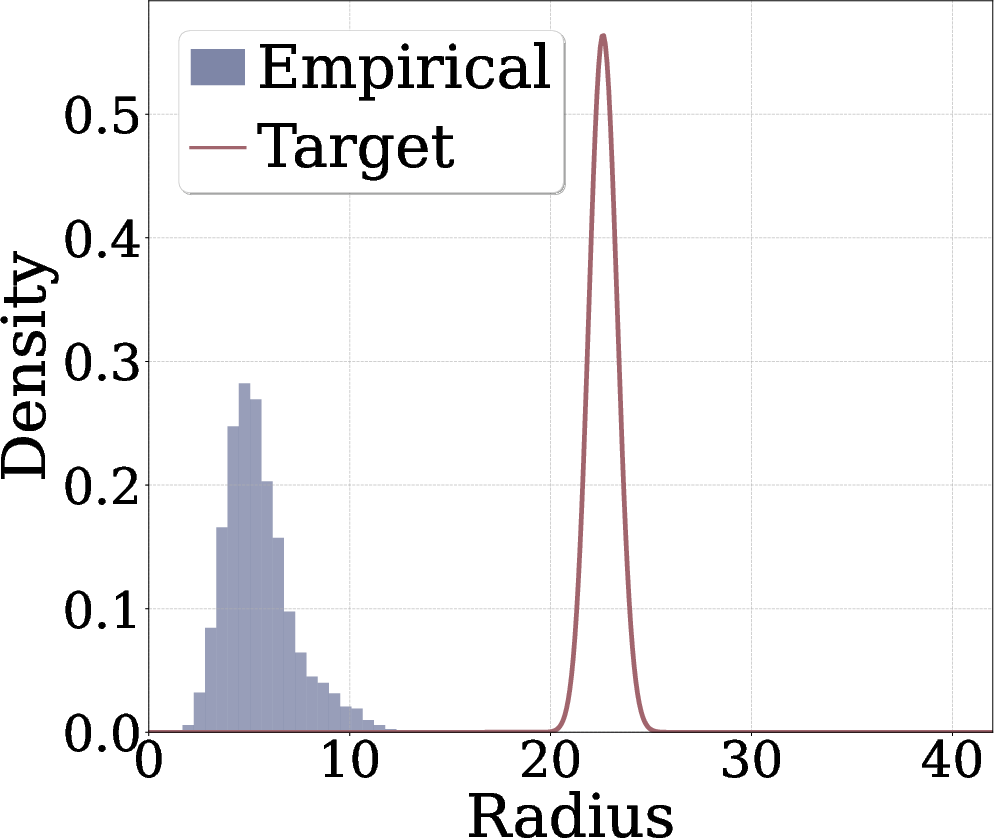
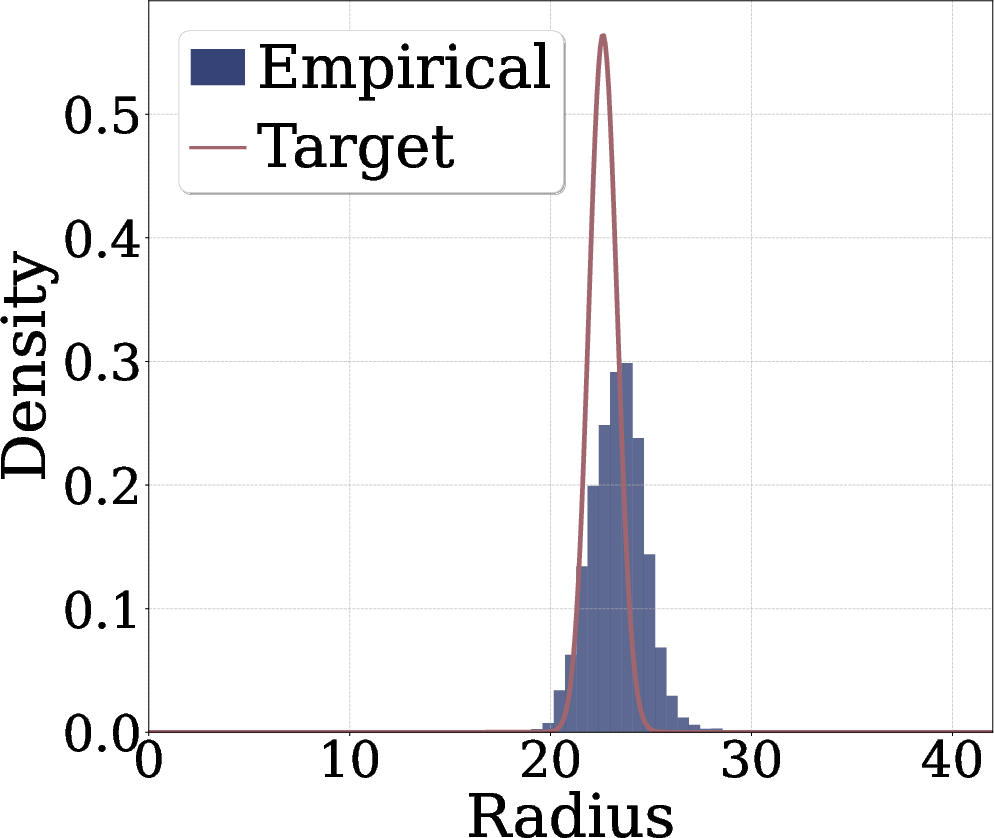
- In high dimensions, most Gaussian points have lengths (distances from the origin) that cluster around a specific value, like points on a thin shell. The distribution of these lengths follows something called a “Chi distribution.”
- Radial Gaussianization means: don’t try to match every detail of the full feature distribution; just make the lengths of the feature vectors follow that Chi shape. This is much simpler and more stable.
How they put it all together:
- VICReg: A popular self-supervised method trains features by:
- Invariance: features for two different versions of the same image should be similar.
- Variance: features should not collapse; they should spread out across the batch.
- Covariance: different feature components shouldn’t be overly correlated (redundant).
- Radial-VCReg: The authors add a new “radial” loss term that:
- Measures the current distribution of feature lengths.
- Encourages those lengths to match the Chi distribution expected from a high-dimensional Gaussian.
- Whitening: They also rely on “whitening,” which roughly means adjusting features so each dimension has similar scale and dimensions are uncorrelated. Think of it like stretching and squashing the shape so it’s evenly spread.
By combining VICReg with the radial term, Radial-VCReg pushes features to be both diverse (high entropy) and closer to a Gaussian, but in a practical, focused way.
Main Findings
The authors report results in two settings:
- Synthetic data (toy examples):
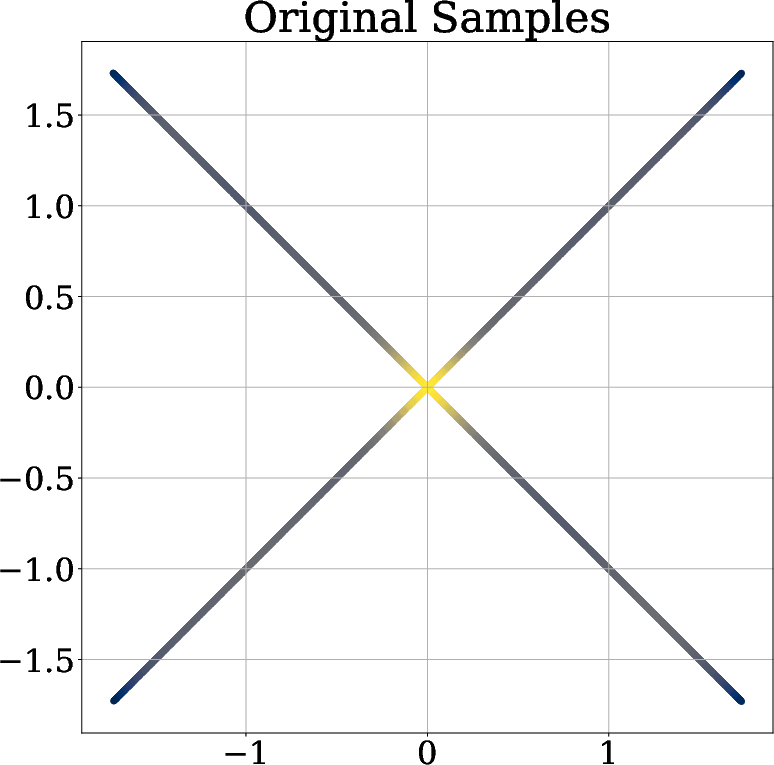
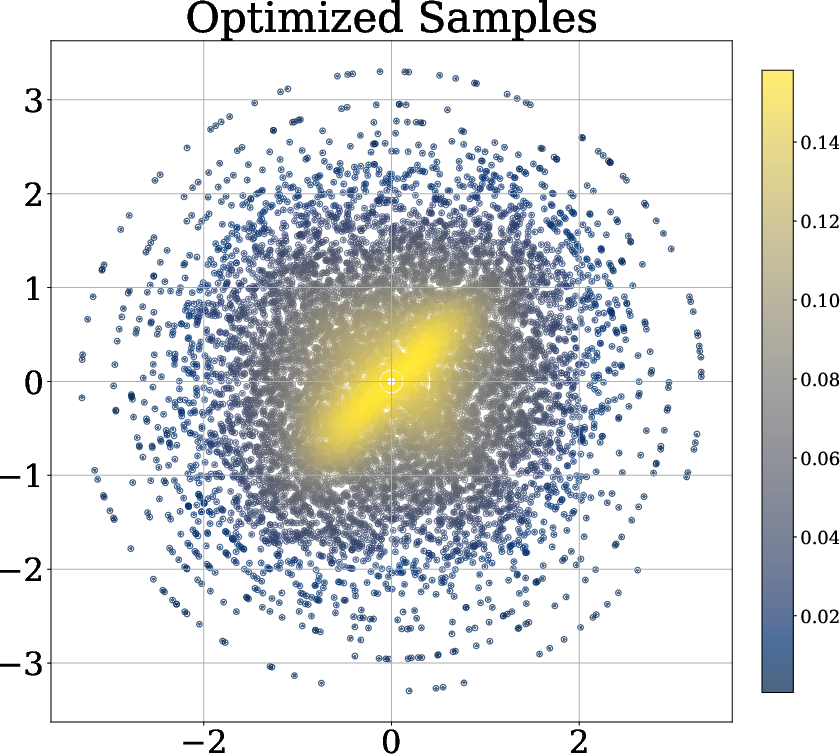
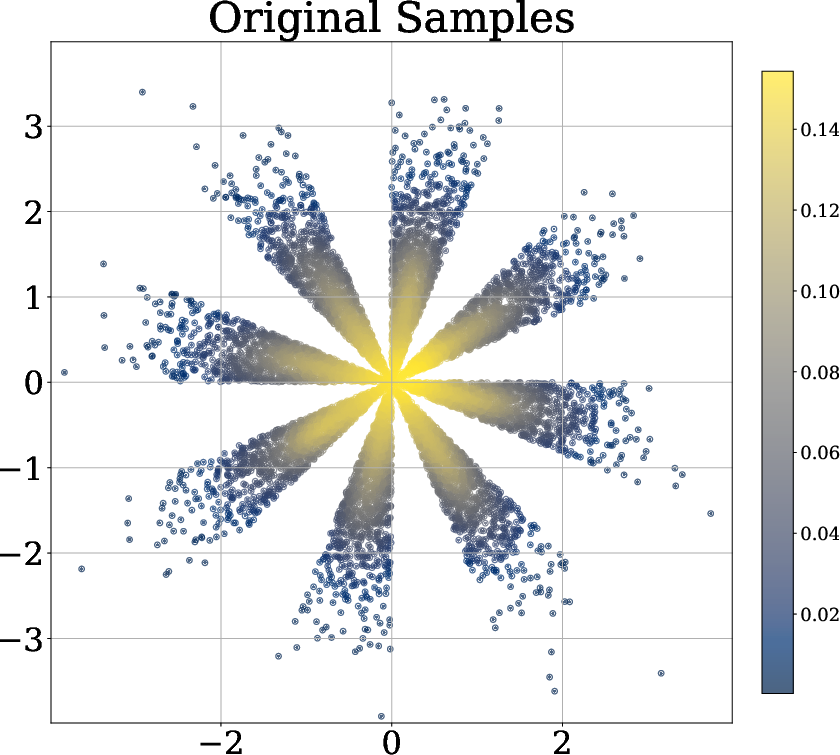
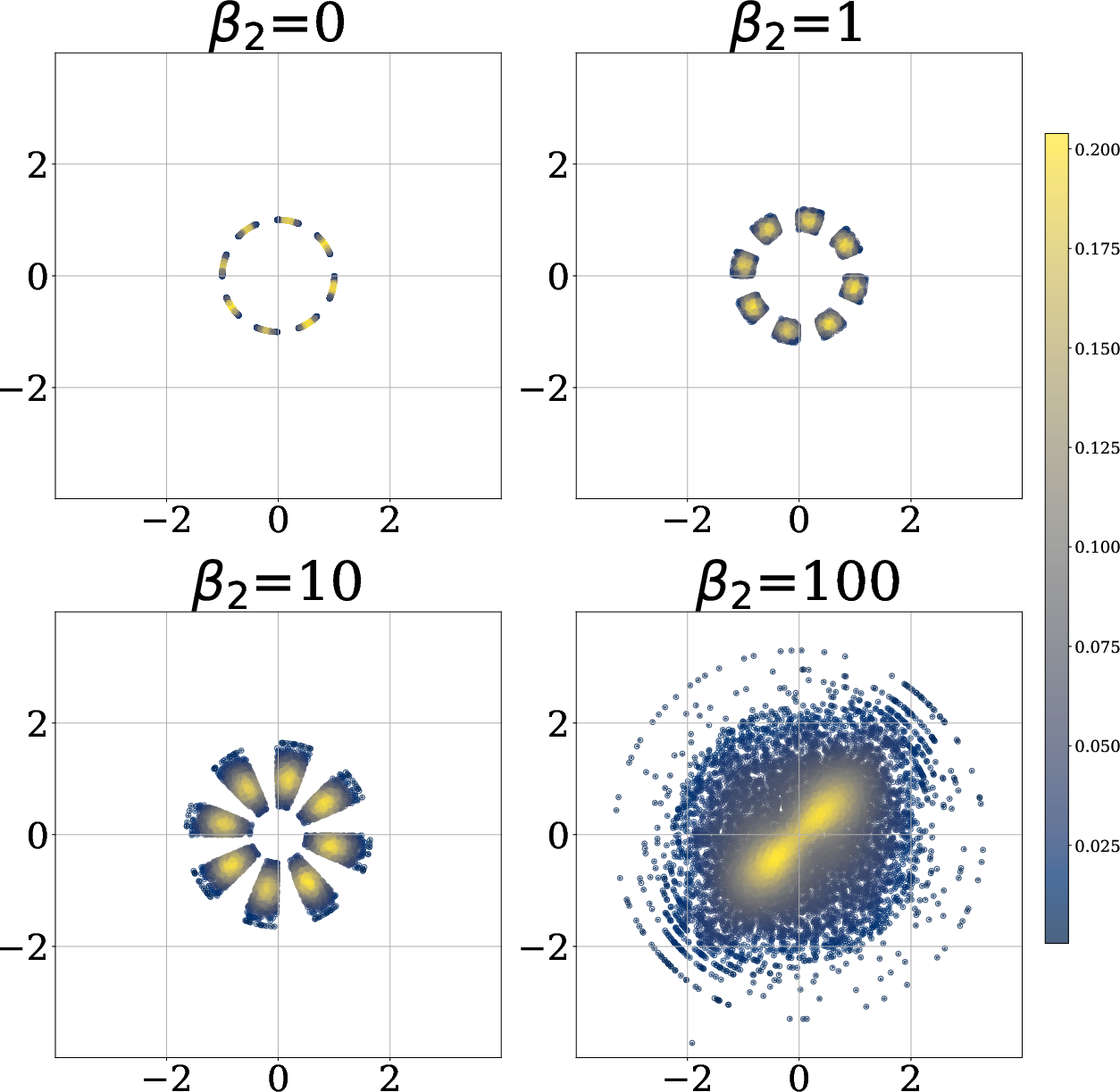
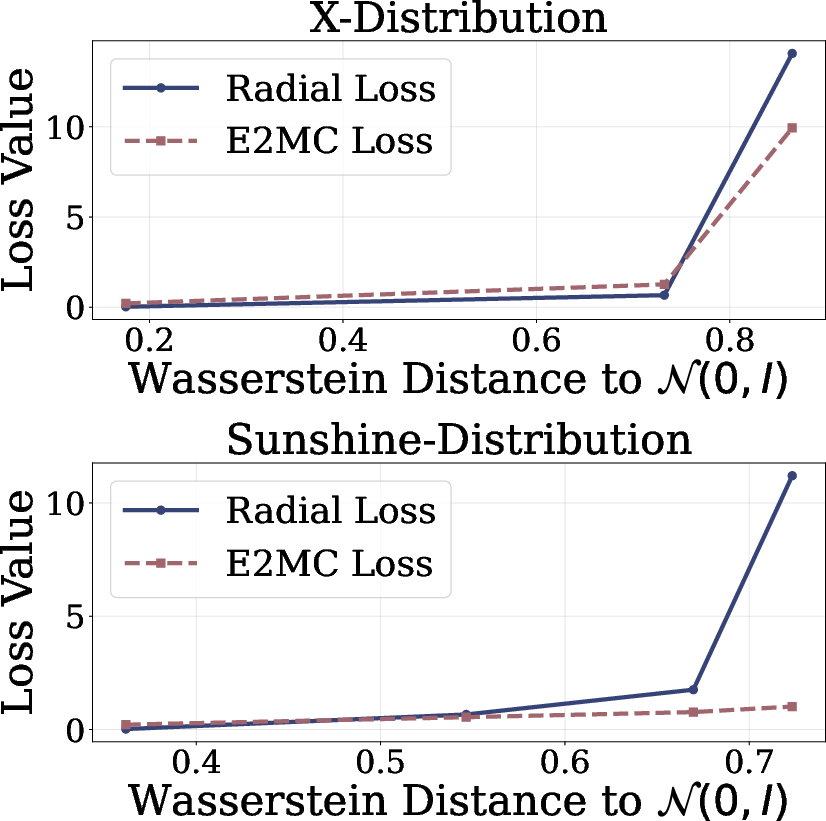
- They test distributions that have tricky shapes (like an “X” shape) that normal covariance-based methods struggle with.
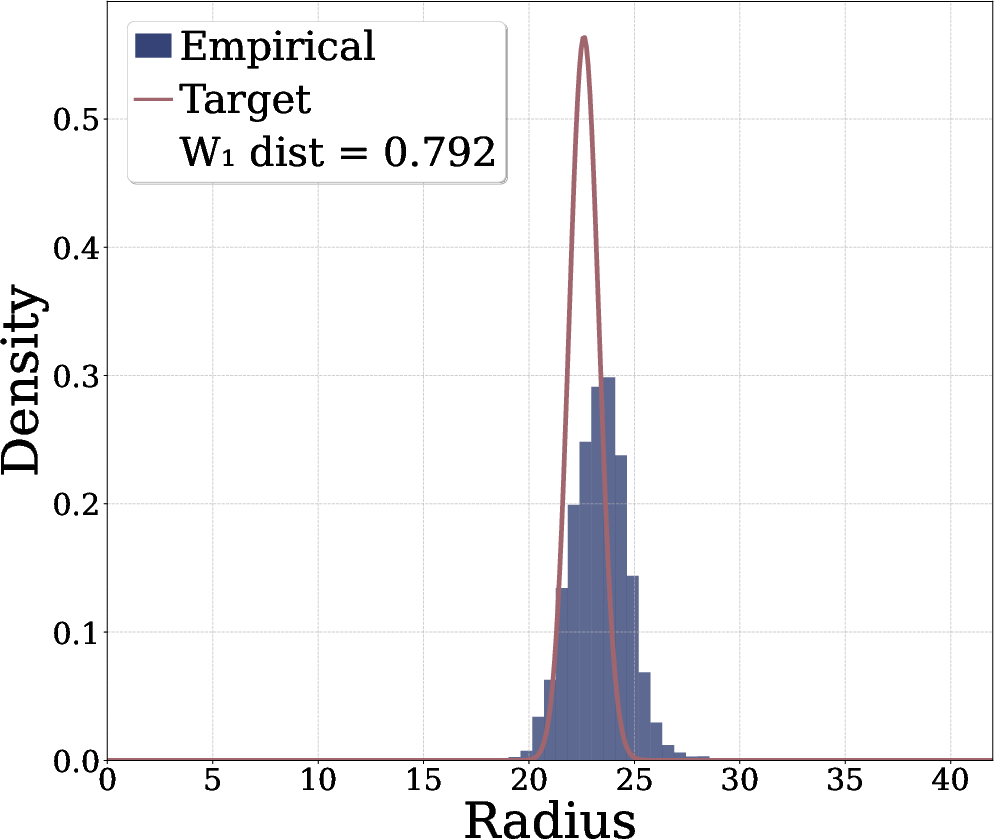
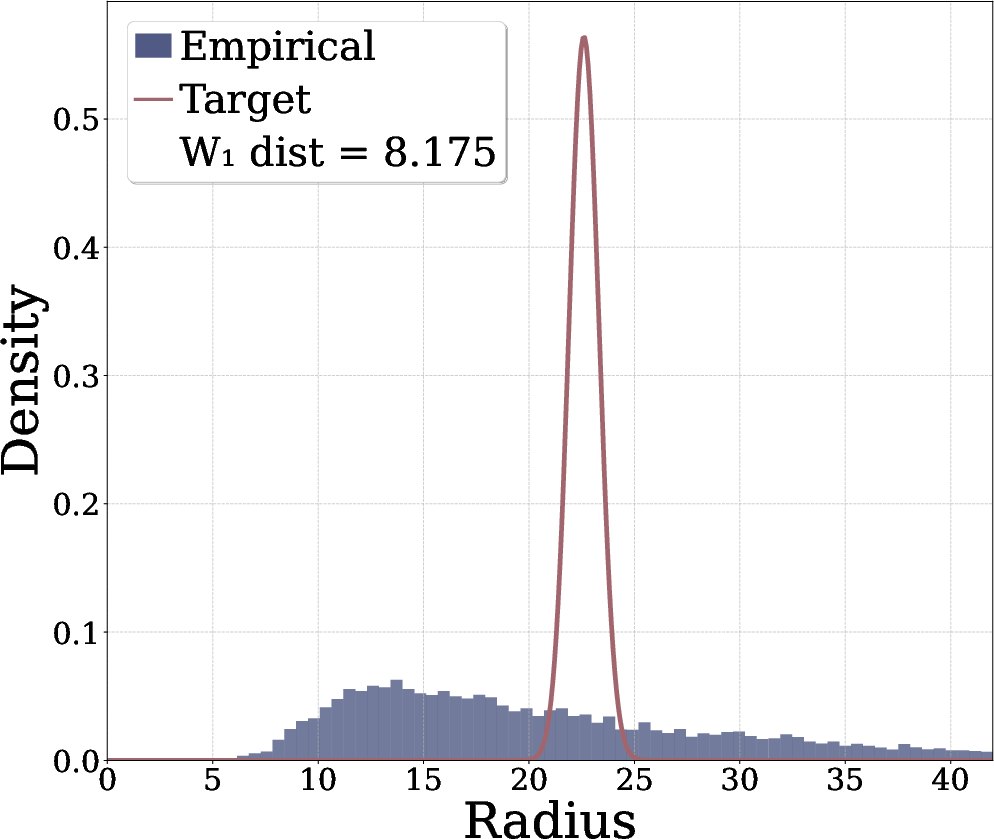
- Adding the radial term makes the learned samples look more spherical and closer to a true Gaussian.
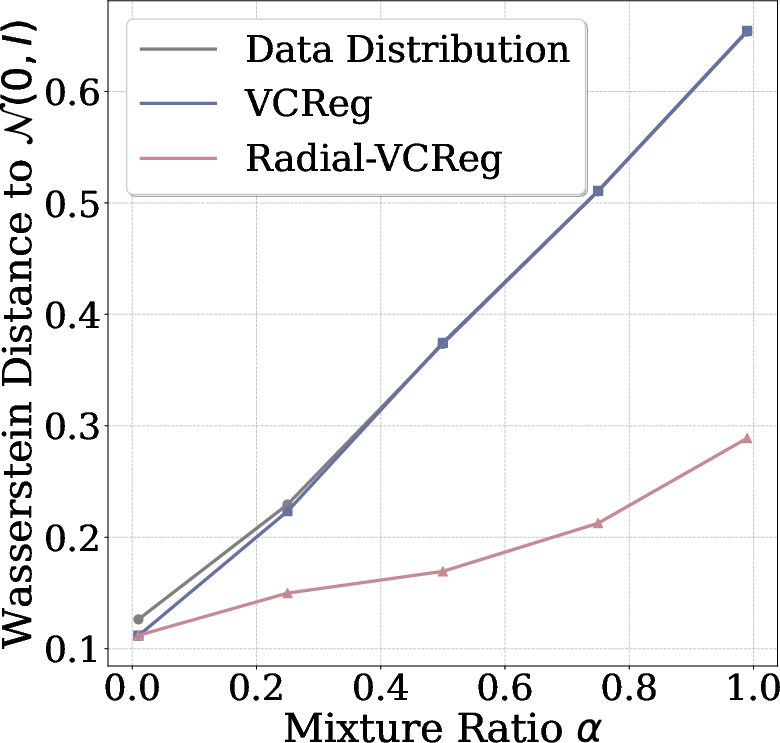
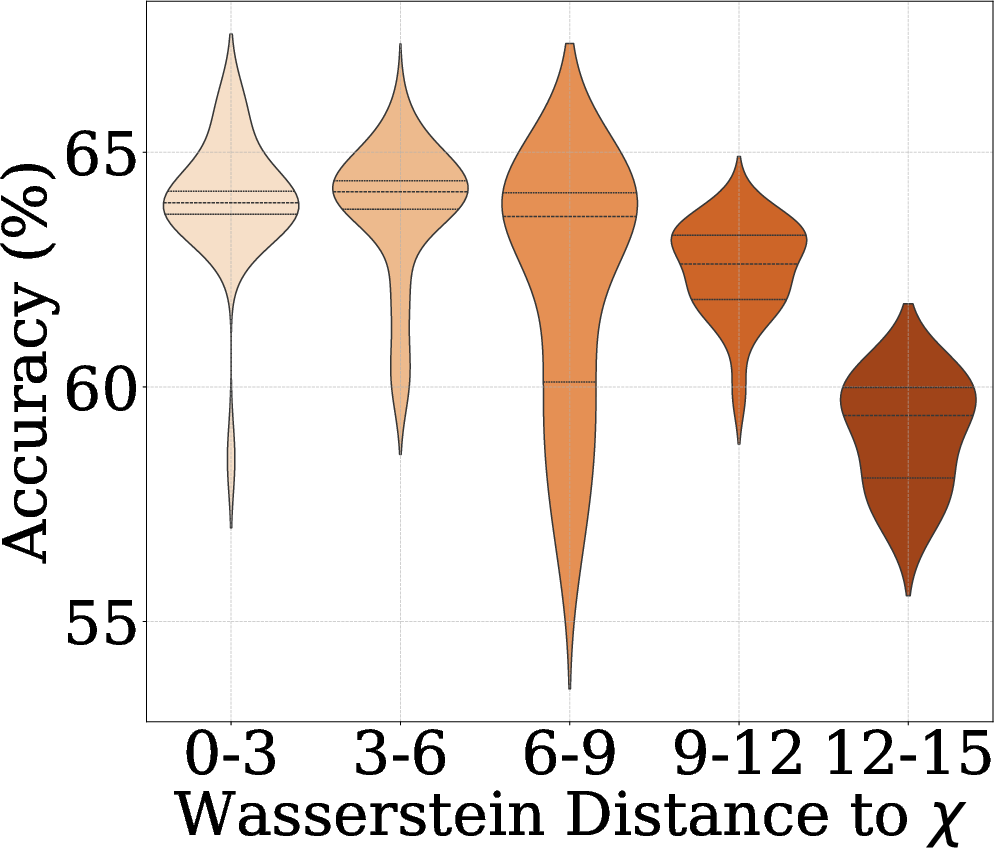
- They measure closeness to Gaussian using Wasserstein distance (a way to quantify how different two distributions are) and find the radial term consistently improves it.
- Real image datasets (CIFAR-100 and ImageNet-10):
- Radial-VCReg gives consistent improvements over VICReg, often around 1–2 percentage points in accuracy for linear probes (simple classifiers on top of the learned features).
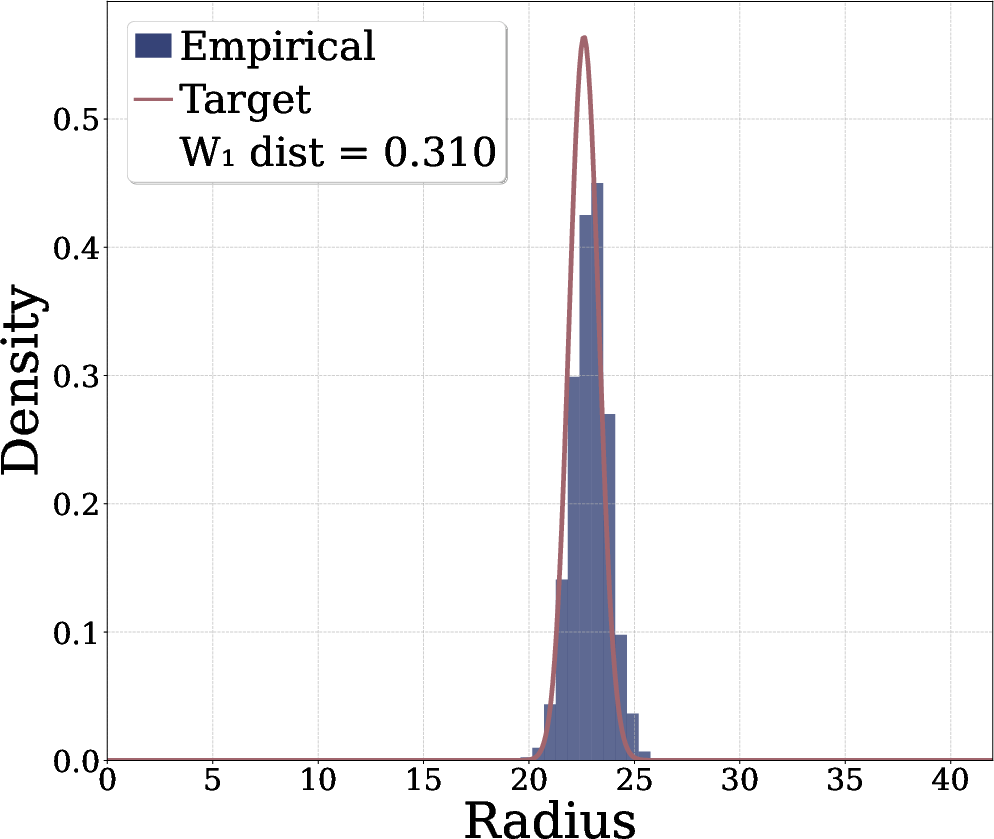
- The better the feature lengths match the Chi distribution, the higher the accuracy tends to be. In other words, when the “radial” shape is right, the features are more useful.
They also provide a theoretical result:
- Radial-VCReg can transform a broader class of feature distributions toward a normal (Gaussian) distribution than the standard VCReg approach. This means it’s more powerful in reducing subtle, higher-order dependencies that variance/covariance alone can’t fix.
Why This Matters
- More informative features: By focusing on the length distribution of features, Radial-VCReg helps the network avoid “feature collapse” and keeps representations rich and diverse.
- Practical Gaussianization: Matching the full high-dimensional Gaussian is hard, but matching the radial part is simpler and still very effective. This leads to better performance without making training overly complicated.
- Better foundations for self-supervised learning: Many tasks rely on good representations learned from unlabeled data. Improving the structure of those representations can boost accuracy across different models and datasets.
Implications and Impact
- Stronger self-supervised models: The method can be added to existing pipelines to improve the learned features, especially in settings with limited labels.
- Reduced hidden dependencies: By tackling higher-order patterns (not just simple linear correlations), it supports more robust and generalizable features.
- A clear direction: The research suggests that looking at simple, high-dimensional properties (like “radial” behavior) can meaningfully improve learning—guiding future work on representation shaping in neural networks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to guide follow-up research:
- Whitening vs. covariance regularization: Theoretical guarantees assume whitening (identity covariance), but VICReg’s covariance/variance terms do not enforce exact whitening. How do exact-whitening layers (e.g., ZCA/Batch-Whitening) change performance and the validity of the Gaussianity arguments?
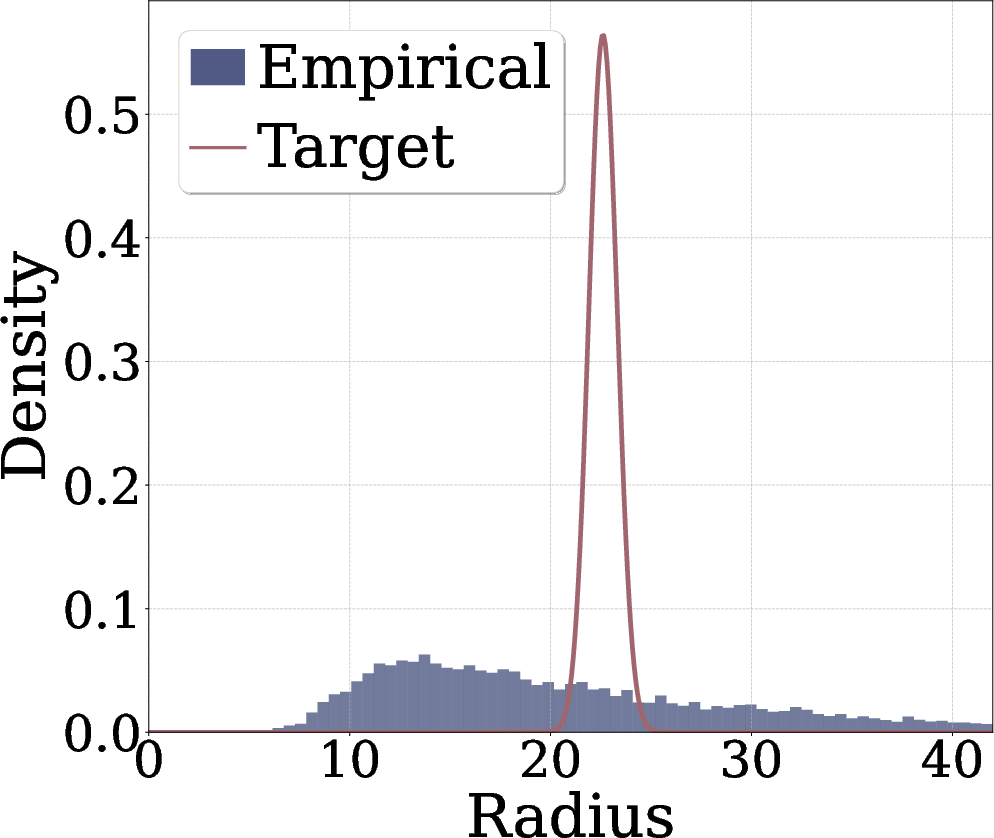
- Angular dependencies left unconstrained: The method only regularizes radii. For non-elliptically symmetric distributions (e.g., the sunshine distribution), angular structure persists. Can adding angular uniformization (e.g., spherical entropy maximization, von Mises–Fisher matching) close this gap?
- Conditions for success beyond ESD: Provide a precise characterization of non-ESD families for which radial Gaussianization provably reduces higher-order dependencies and improves downstream performance.
- Convergence guarantees with finite batches: Establish optimization/convergence rates for the stochastic KL (or W1) radial objective under mini-batch estimates; quantify the bias/variance introduced by batching, sorting, and SGD.
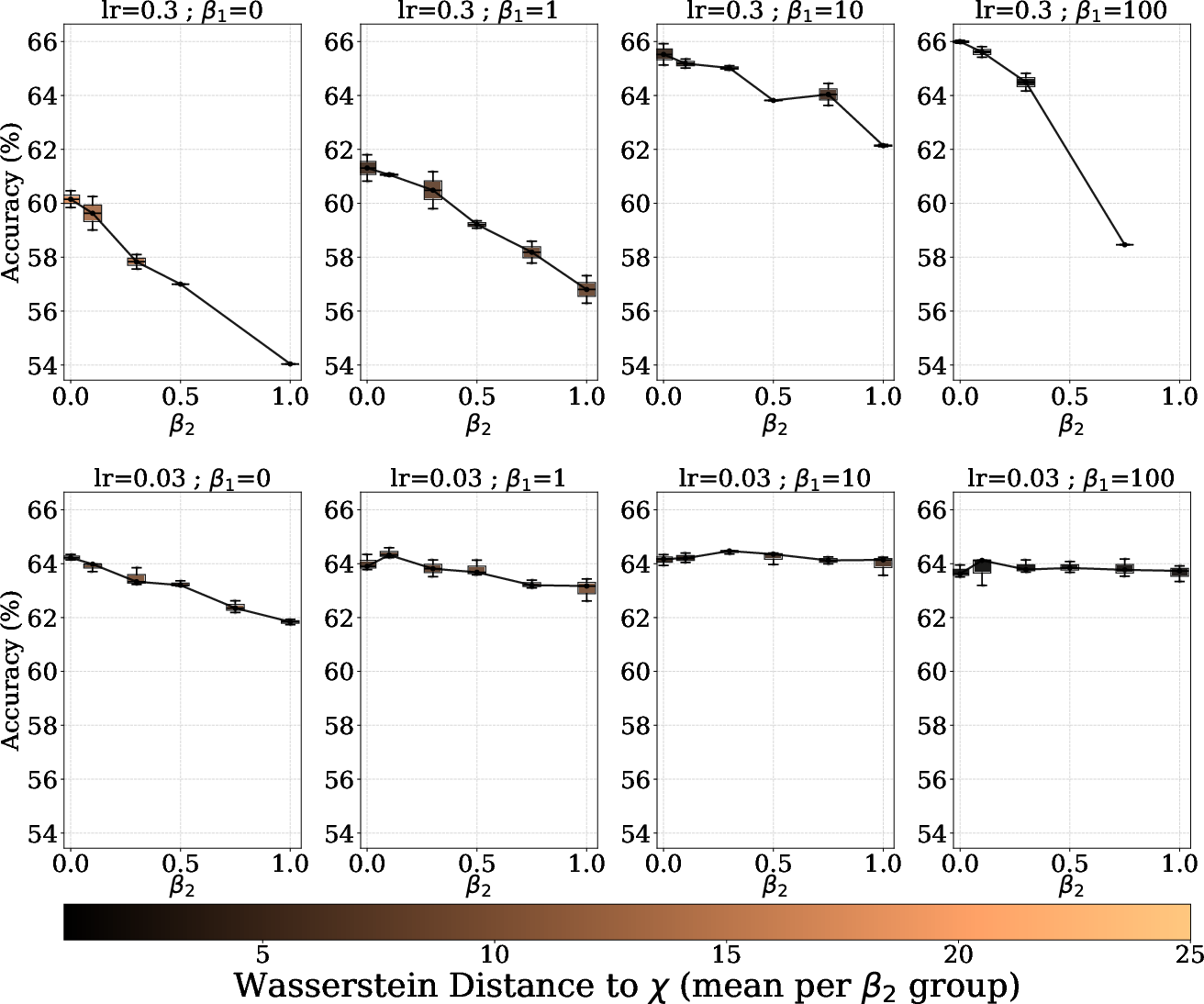
- Sensitivity to hyperparameters: Systematically map performance vs. β1, β2, m (m-spacing), and λ-weights; derive principled defaults (e.g., scaling laws with batch size and d_out) and schedules that stabilize training.
- Batch-size dependence: Both KL and W1 radial losses use order statistics; quantify how batch size K impacts estimator variance, gradient noise, and downstream accuracy; derive recommended K vs. d_out regimes.
- Numerical robustness of the log-radius term: Investigate stability when norms approach zero and propose robustified losses (e.g., log(||z||+ε), clipped gradients) with empirical guidance.
- Computational overhead: Measure and report time/memory costs of sorting and entropy estimation, especially at large batch sizes and feature dimensions; propose efficient, distributed implementations.
- Scaling to large pretraining: Validate on standard large-scale SSL benchmarks (e.g., ImageNet-1k, ImageNet-22k) and longer schedules; assess wall-clock trade-offs and gains vs. stronger baselines.
- Broader modality and domain coverage: Test on non-vision modalities (audio, text, time series) and non-natural images; assess domain shift generalization.
- Downstream task breadth: Evaluate beyond linear/MLP probes on classification—e.g., detection, segmentation, retrieval, kNN classification, few-shot transfer—to confirm representation usefulness.
- Interaction with invariance term: Theory focuses on VCReg (λ1=0), but practice uses VICReg. Analyze how the invariance loss interacts with radial constraints (conflicts, synergies) both theoretically and empirically.
- Combination with contrastive SSL: Explore integrating radial Gaussianization into contrastive frameworks (SimCLR, MoCo) and redundancy-reduction methods (Barlow Twins), with careful ablations.
- Choice of target radial distribution: Assess whether χ(d_out) is always appropriate; study heavy-tailed or sub-Gaussian elliptical targets and learned radial targets that better match data constraints.
- Measuring higher-order dependence: Provide multidimensional normality diagnostics (e.g., Mardia’s skewness/kurtosis, energy distance, kernel Stein discrepancy, ICA residual dependencies) to substantiate “reduced higher-order dependencies” beyond radius histograms.
- Mutual information validation: Directly estimate MI (or tight lower bounds) between views (e.g., MINE/InfoNCE variants) to test the InfoMax claim rather than relying on proxy arguments.
- Semi-collapse and anisotropy risks: Analyze whether matching to χ(d_out) can inadvertently “ring-cluster” features or suppress task-relevant anisotropy; identify regimes where radial pressure harms separability.
- Projector dimension effects: Gains appear larger at smaller d_out; investigate why improvements shrink at high d_out (e.g., 8192) and whether re-scaling or stronger angular regularization restores benefits.
- Robustness and OOD behavior: Test adversarial robustness, corruption robustness, and OOD detection/uncertainty—does spherical concentration of norms help or hurt?
- Alternative divergences and estimators: Compare KL and W1 against other 1D divergences (Cramér, energy, Sinkhorn-regularized OT) and other entropy estimators (kNN/Kozachenko–Leonenko); assess gradient smoothness and efficiency.
- Exact vs. approximate radial mapping: Proposition uses an exact CDF-based transform; training uses a surrogate loss. Can we design a differentiable, practical approximation to the exact transform and compare outcomes?
- Multi-view extensions: Evaluate whether imposing shared radial constraints across more than two augmented views improves consistency and stability.
- Interaction with normalization layers: Study how BatchNorm/LayerNorm in backbone and projector interact with the radial loss (e.g., norm dynamics, train–eval mismatch).
- Statistical significance and effect sizes: Some gains are modest; provide formal significance testing and effect sizes across many seeds and datasets.
- Guidance on m-spacing parameter m: Derive or empirically validate rules for choosing m as a function of batch size and distributional properties to minimize estimator bias/variance.
- Alternative probe protocols: Include fine-tuning and data-efficient fine-tuning to test whether benefits persist beyond linear/MLP probes.
- Comparison to E2MC at scale: Provide head-to-head comparisons with E2MC and related entropy-maximization methods on standard SSL suites, including ablations isolating radial vs. per-dimension entropy components.
- Augmentation interactions: Analyze how different augmentation families (e.g., strong color jitter, blur, crops) affect the learned radius distribution and the efficacy of the radial constraint.
Practical Applications
Practical Applications of Radial-VCReg
Below are actionable applications that stem from the paper’s findings and methods. Each item notes the relevant sector(s), plausible tools/products/workflows, and assumptions/dependencies that may affect feasibility.
Immediate Applications
These applications can be deployed now, leveraging the provided method and open-source code to improve representation learning pipelines.
- Self-supervised pretraining upgrade for vision models
- Sectors: healthcare, robotics, autonomous driving, e-commerce, content moderation, media
- Tools/workflows: add the radial Gaussianization loss to VICReg/VICReg-like training; adopt the provided PyTorch implementation; tune beta1, beta2, m-spacing; optionally use the Wasserstein-1 (W1) radial loss variant; leverage smaller projector dimensions (e.g., 512) for efficiency
- Assumptions/dependencies: unlabeled image data availability; adequate batch sizes for stable m-spacing/W1 estimates; standard augmentations; improvements demonstrated on CIFAR-100 and ImageNet-10—validate on your domain and scale
- Representation “health” monitoring via Chi-fit metrics
- Sectors: software/ML ops, industry/academia
- Tools/workflows: compute Wasserstein distance between feature radii and the chi distribution during training; track correlation between Chi-fit and validation accuracy; use for early stopping and hyperparameter selection
- Assumptions/dependencies: logging infrastructure; batch-size sensitivity of W1 estimator; correlation seen in experiments but may vary across tasks/modalities
- Collapse prevention and feature diversity diagnostics in non-contrastive SSL
- Sectors: software, robotics, edge AI
- Tools/workflows: integrate radial Gaussianization with covariance/variance regularization (VCReg); trigger alerts if Chi-fit degrades; run ablations to ensure InfoMax behavior
- Assumptions/dependencies: standard VICReg components (variance/covariance terms); monitoring overhead during training
- Resource-conscious pretraining with smaller projectors
- Sectors: mobile, edge computing, robotics
- Tools/workflows: use projector dimensions around 512 with Radial-VCReg to maintain or improve accuracy; deploy on hardware-constrained devices
- Assumptions/dependencies: model architecture compatibility (ResNet/ViT shown); validate on specific tasks and devices
- Improved downstream linear/MLP probes for classification and attribute prediction
- Sectors: media (face/attribute recognition), retail (product categorization), education (content OCR/labeling)
- Tools/workflows: pretrain with Radial-VCReg, then train lightweight probes; adopt the Chi-fit as a proxy for representation informativeness
- Assumptions/dependencies: downstream labels for probing; domain-specific generalization requires validation
- Unsupervised sensor and time-series pretraining (pilot use)
- Sectors: energy (predictive maintenance), industrial IoT
- Tools/workflows: apply radial Gaussianization to SSL embeddings from unlabeled sensor streams; monitor Chi-fit to avoid degenerate representations
- Assumptions/dependencies: adaptation of augmentation strategies beyond vision; empirical validation needed on time-series modalities
- Internal policy for model development: representation diversity checks
- Sectors: enterprise ML governance
- Tools/workflows: adopt “Chi-fit threshold” as an internal guideline for accepting SSL models; document training runs with Chi-match curves alongside accuracy
- Assumptions/dependencies: organizational buy-in; clarity that Chi-fit is a heuristic, not a formal guarantee of robustness or fairness
- Academic benchmarking and teaching
- Sectors: academia, education
- Tools/workflows: use synthetic distributions (X/sunshine) to illustrate higher-order dependencies and Gaussianization; compare VCReg vs. Radial-VCReg; create coursework/labs on InfoMax constraints
- Assumptions/dependencies: reproducibility using the released code; compute for experiments
Long-Term Applications
These require further research, larger-scale validation, or engineering for robust deployment.
- Foundation-model pretraining across modalities (vision, video, audio, text)
- Sectors: software, media, multimodal AI
- Tools/workflows: extend radial Gaussianization to large-scale SSL for video and vision-LLMs; integrate with whitening or redundancy-reduction objectives; build “Gaussianization-aware” training recipes
- Assumptions/dependencies: scalability to ImageNet-1K and beyond; modality-specific augmentations; stability of entropy/W1 estimators at massive batch scales
- Norm control in transformer embeddings and retrieval systems
- Sectors: search/recommendation, NLP, multimodal retrieval
- Tools/workflows: regulate embedding norms via chi alignment to reduce saturation or collapse; monitor Chi-fit to maintain representation diversity in index construction
- Assumptions/dependencies: adaptation to token/sequence embeddings; empirical impact on retrieval effectiveness needs study
- Continual and on-device SSL with collapse safeguards
- Sectors: robotics, edge AI, autonomous systems
- Tools/workflows: deploy Radial-VCReg as a guardrail in continual learning on unlabeled streams; use real-time Chi-fit metrics for safe learning under distribution shift
- Assumptions/dependencies: streaming estimators for entropy/W1; compute constraints on-device; robustness under nonstationary data
- Anomaly and drift detection via radius-distribution deviations
- Sectors: finance (market surveillance), cybersecurity, industrial monitoring
- Tools/workflows: treat chi-radius mismatches as unsupervised drift signals in embeddings; integrate into monitoring dashboards; trigger model retraining or data pipeline checks
- Assumptions/dependencies: calibration of thresholds; sensitivity/specificity evaluation to avoid false alarms; domain-specific validation
- Representation Health Dashboard product
- Sectors: MLOps tooling, enterprise ML platforms
- Tools/workflows: a dashboard that tracks Chi-fit, covariance health, and proxy InfoMax metrics; integrates with training pipelines (PyTorch/TensorFlow) and experiment tracking (Weights & Biases/MLflow)
- Assumptions/dependencies: engineering for differentiable sorting/m-spacing at scale; UI/UX for actionable insights; acceptance by ML teams
- Hardware-optimized kernels for radial losses
- Sectors: semiconductors, ML acceleration
- Tools/workflows: GPU kernels for m-spacing entropy estimator and differentiable sort; approximate W1 estimators tailored to large batches
- Assumptions/dependencies: demand from large-scale training; correctness and numerical stability; integration into major frameworks
- Theory and objectives beyond elliptically symmetric distributions
- Sectors: academia, research labs
- Tools/workflows: combine radial constraints with angular uniformity or higher-order moment regularizers; derive sufficiency conditions for broader Gaussianization; new diagnostics for non-ESD settings
- Assumptions/dependencies: mathematical development; empirical validation showing gains beyond current scope
- Data-centric augmentation search guided by Chi-fit
- Sectors: AutoML, computer vision
- Tools/workflows: use chi-radius alignment and covariance metrics to optimize augmentation policies that promote InfoMax; include Radial-VCReg weightings in hyperparameter search
- Assumptions/dependencies: reliable proxy behavior of Chi-fit across datasets; efficient search strategies; generalization beyond CIFAR/ImageNet subsets
- Clinical-grade SSL for medical imaging
- Sectors: healthcare
- Tools/workflows: pretrain models on large unlabeled radiology/pathology repositories; use Chi-fit as a training quality control; evaluate on diagnostic tasks
- Assumptions/dependencies: rigorous validation under regulatory standards; domain-specific augmentations; assessment of robustness and bias
- Governance and audit standards for representation diversity
- Sectors: policy, risk management
- Tools/workflows: propose non-binding standards that include distributional checks (Chi-fit, covariance health) in internal audit of SSL systems; complement performance and robustness tests
- Assumptions/dependencies: stakeholder consensus; clear communication that these are diagnostic—not fairness or safety guarantees; ongoing standardization efforts
Glossary
- Affine map: A function composed of a linear transformation followed by a translation. "we can write the random vector via the affine map $\mathbf{X}=\boldsymbol{\Sigma}^{1/2}T_{\text{VCReg}(\mathbf{X})+\boldsymbol{\mu}$"
- Beta-VAE: A variant of the variational autoencoder that scales the KL term by a factor to encourage disentanglement. "similar in spirit to the modification introduced in -VAE \citep{higgins2017beta}"
- Chi distribution: The distribution of the Euclidean norm of a -dimensional standard normal vector. "aligns feature norms with the Chi distribution—a defining property of high-dimensional Gaussians."
- Consistent estimator: An estimator that converges in probability to the true parameter as the sample size grows. "the radial Gaussianization loss is a consistent estimator of the true KullbackâLeibler divergence"
- Cumulative distribution function (CDF): A function giving the probability that a random variable is less than or equal to a given value. " is the CDF of the radial component of the whitened random vector, and is the inverse CDF"
- Curse of dimensionality: The phenomenon where high-dimensional spaces make statistical estimation and optimization difficult due to sparse data and exponential complexity. "explicit information maximization is hindered by the curse of dimensionality."
- Elliptically symmetric density (ESD): A family of distributions whose level sets are ellipsoids; after whitening they become spherically symmetric. "Enforcing this radial property with whitening provides sufficient conditions for Gaussianity if the underlying distribution is elliptically symmetric"
- Entropy: A measure of uncertainty or information content of a probability distribution. "The Gaussian distribution is the maximum entropy distribution for a given mean and variance"
- InfoMax principle: A representation learning principle that seeks to maximize mutual information between related variables or views. "Many methods are based on the InfoMax principle"
- Isotropic Gaussian: A Gaussian distribution with covariance proportional to the identity, having equal variance in all directions. "A -dimensional isotropic Gaussian concentrates on a thin shell of radius with an width"
- Kullback–Leibler divergence (KL divergence): A measure of how one probability distribution diverges from a reference distribution. "Our goal is to minimize the KullbackâLeibler divergence between $p_{\boldsymbol{\theta}(\|\mathbf{z}\|_2)$ and the Chi-distribution "
- Law of Large Numbers: A theorem stating that sample averages converge to the expected value as the sample size increases. "By the Law of Large Numbers, the cross-entropy estimator is consistent."
- m-spacing estimator: An entropy estimator based on spacings between ordered samples, known for consistency. "the m-spacing estimator is consistent"
- Mutual information: The amount of information shared between two random variables. "maximize mutual information between different views of the same input"
- Pushforward measure: The distribution obtained by mapping a random variable through a measurable function. "We denote the pushforward measure by $T_{\mathrm{VCReg}\#} P_{\mathbf{X}$ and $T_{\mathrm{Radial\text{-}VCReg}\#} P_{\mathbf{X}$."
- Radial Gaussianization: A transformation that aligns the distribution of feature norms (radii) with a target (Chi) distribution to encourage Gaussianity. "We propose the Radial Gaussianization loss"
- Representational collapse: A failure mode where a model maps diverse inputs to identical or trivial representations. "preventing representational collapse, where the model learns to map all inputs to a single, trivial point."
- Spherically symmetric density: A distribution whose density depends only on the radius, invariant under rotations. "If is a random vector in dimensions with a spherically symmetric density and the random variable follows the Chi distribution "
- VCReg: The VICReg objective without the invariance term (i.e., ), regularizing variance and covariance to reduce redundancy. "When , we call it VCReg."
- VICReg: A non-contrastive self-supervised method combining variance, invariance, and covariance losses to learn diverse, aligned representations. "VICReg \citep{bardes2022vicregvarianceinvariancecovarianceregularizationselfsupervised} is a non-contrastive self-supervised learning method that contains the variance, invariance, and covariance loss terms."
- Wasserstein-1: The first-order Wasserstein (Earth mover’s) distance; in 1D, equal to the average absolute difference of quantiles. "Wasserstein distance to the Chi distribution equal to $17.15$"
- Wasserstein distance: An optimal transport metric measuring the cost of moving probability mass to transform one distribution into another. "Wasserstein Distance between optimized samples and "
- Whitening: A linear transformation that makes data have zero mean and identity covariance, removing linear correlations. "Enforcing this radial property with whitening provides sufficient conditions for Gaussianity"
Collections
Sign up for free to add this paper to one or more collections.

