- The paper introduces a hybrid blockwise sequence modeling framework that blends autoregressive and diffusion methods using mixture training and ARPC samplers.
- It demonstrates that informed predictor-corrector strategies, particularly ARPC, enhance GSM8K accuracy and reduce perplexity compared to conventional approaches.
- Empirical results show that smaller block sizes and shared KV caching boost parallel decoding efficiency while maintaining near-autoregressive performance.
BlockGen: Flexible Blockwise Sequence Modeling with Hybrid Samplers
Motivation and Background
BlockGen introduces a blockwise sequence modeling framework leveraging hybrid samplers to address limitations of autoregressive Transformers and discrete diffusion models in language modeling. Traditional AR Transformers are constrained by sequential token generation, resulting in suboptimal throughput and inability to exploit parallelism during inference. Causal attention restricts bidirectional context, adversely impacting performance on reasoning tasks. Discrete diffusion models, notably masked diffusion models (MDMs) and uniform-state diffusion models (USDMs), offer an alternative by iteratively refining noisy sequences and allowing multiple token updates per denoising step.
Recent findings indicate USDMs can surpass MDMs in downstream task performance, despite higher validation perplexity (2606.02241). However, prior work focused mainly on full-sequence diffusion and uninformed corrector strategies, leaving two questions unresolved: (1) does the USDM advantage persist in block-by-block generation, and (2) does informed predictor-corrector sampling alter the masked-vs-uniform paradigm ranking when revising unlikely tokens based on model-internal signals or AR predictions?
BlockGen Model Architecture
BlockGen generalizes blockwise diffusion modeling by training over a mixture of block sizes, supporting both uniform and masked diffusion priors within each block. The mixture parameterization enables interpolation between AR and pure diffusion in sequence modeling. By training a single denoiser backbone accepting block size as an explicit input, BlockGen maintains compatibility across blockwise and AR modes while sharing KV cache during inference for efficient block-parallel decoding.
This architectural flexibility allows BlockGen to instantiate AR-informed predictor-corrector (ARPC) samplers, which dynamically combine AR and diffusion mode predictions during inference. ARPC leverages AR log-likelihoods as a direct scoring signal to selectively re-noise tokens, enabling correction of low-confidence or erroneous predictions without auxiliary verifiers or additional training overhead.
Hybrid Samplers: ARPC and EIPC
Two classes of block-level predictor-correctors are examined: Entropy-Informed Predictor-Corrector (EIPC) and AR-Informed Predictor-Corrector (ARPC). EIPC deploys the per-token entropy of blockwise diffusion predictions as a signal for targeted correction. ARPC leverages an extra inference pass in AR mode to score token-level likelihoods, guiding noise injection to low-probability tokens in the proposal. This relies critically on the BlockGen mixture training regime; the same denoiser backbone is trained with AR and diffusion block sizes, enabling seamless AR verification.
Empirical evaluation reveals ARPC outperforms EIPC across most NFE budgets, both with masked and uniform priors. ARPC narrows the gap between blockwise diffusion and fully autoregressive generation, especially as NFE increases (Figure 1).
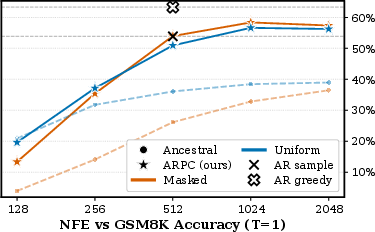
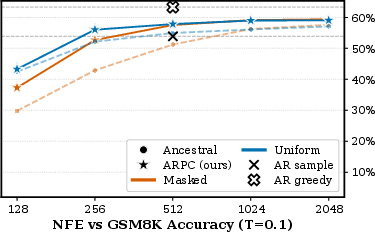
Figure 2: GSM8K accuracy with block size 16 as a function of NFE, demonstrating BlockGen's blockwise diffusion performance and ARPC convergence toward AR sampling.
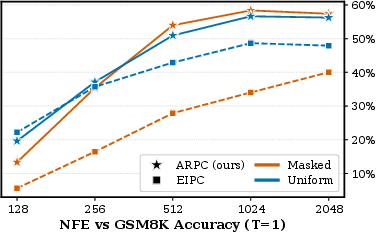
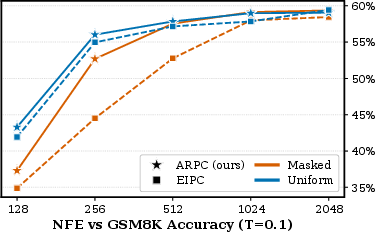
Figure 1: ARPC versus EIPC on GSM8K; ARPC consistently exceeds EIPC, validating the mixture training and AR-based scoring utility.
Empirical Results and Numerical Analysis
Mathematical Reasoning Benchmarks
BlockGen was trained on TinyGSM (≈11.8M synthetic GSM8K-style word problems) and evaluated on GSM8K. Under blockwise ancestral sampling, USDMs outperform MDMs at low NFE, consistent with full-sequence diffusion trends. However, ARPC narrows and reverses this gap at high NFE—masked diffusion achieves slightly higher accuracy than uniform under ARPC, with both converging toward AR's performance frontier (Figure 2, Figure 1). The block size setting is crucial: block size 16 systematically outperforms 32 at matched NFE (Figure 3, Figure 4). Strong numerical results show BlockGen (masked, uniform mixture weights) achieves 17.5 validation PPL on OpenWebText versus 16.7 for AR and 21.6 for best single-block BDM.
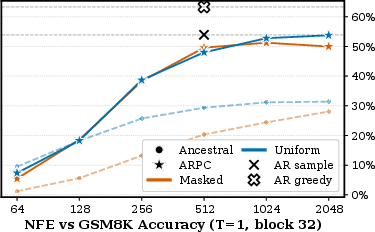
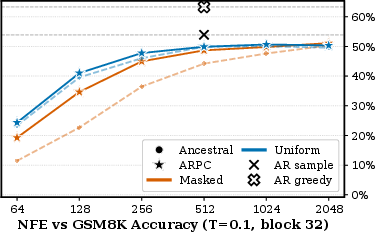
Figure 3: GSM8K accuracy with block size 32 as a function of NFE; smaller block sizes yield better accuracy under ARPC.
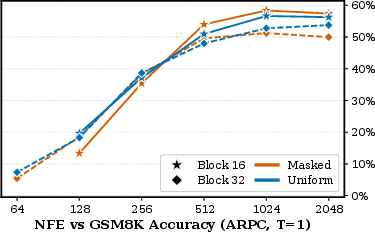
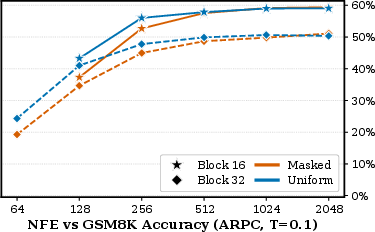
Figure 4: ARPC GSM8K accuracy at block sizes 16 vs 32, confirming block size 16's superiority.
Language Modeling and Perplexity Frontiers
On OpenWebText, BlockGen closes the perplexity gap to AR modeling (masked diffusion 19.1 vs AR 16.7), outperforming single-block BDMs (21.6). BlockGen's stratified block-size mixture training is a key element in achieving tightly interpolated likelihood bounds. In sample quality evaluation, ARPC enhances generative perplexity versus blockwise ancestral and EIPC samplers. Masked diffusion under ARPC performs better at high NFE, while uniform diffusion excels in the few-step regime (Figure 5). Yet, fully autoregressive generation retains the lowest generative PPL, reinforcing its status as the likelihood-optimal baseline.
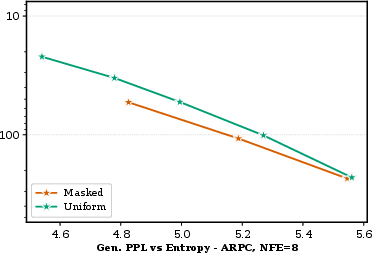
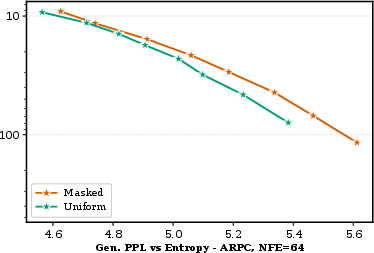
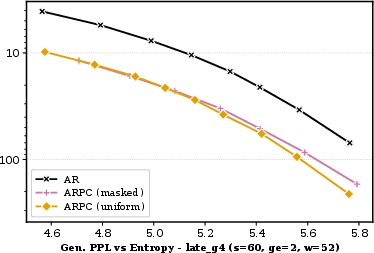
Figure 5: Sample quality on OpenWebText; ARPC frontier shows masked diffusion catching AR, uniform diffused leads at low NFE.
Attention Patterns and KV Caching
BlockGen leverages block-causal attention, permitting bidirectional context within each block and causal attention across blocks. This enables efficient block-level KV caching, reducing inference latency compared to full-sequence models, and allowing high-throughput parallel decoding. Modifications to standard block diffusion attention allow the reuse of KV cache across multiple block sizes (Figure 6).
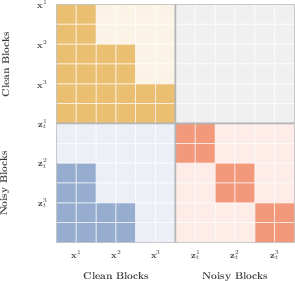
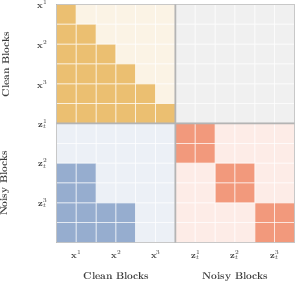
Figure 6: Standard block diffusion attention; KV cache enables efficient blockwise decoding with flexibility across block sizes.
Implications, Limitations, and Future Directions
BlockGen demonstrates that blockwise sequence modeling, equipped with mixture training and ARPC sampling, can achieve near-AR performance in validation perplexity and downstream tasks. The paradigm shift—masked diffusion outperforming uniform at high NFE under informed correctors—points to nuanced tradeoffs between self-correction and fixed tokenization, mediated by the corrector design and inference schedule. Practical implications are significant: BlockGen's architecture supports efficient parallel generation with competitive accuracy, promising reduced latency for LLM deployment in interactive systems.
Limitations include scale; experiments were completed with 170M-parameter backbones and do not fully extrapolate to LLM regimes. Training cost is non-trivial due to processing doubled sequence lengths for parallel context/noisy block prediction. BlockGen's empirical claims are regime-sensitive: ARPC does not surpass AR generative PPL in the practical low-temperature range under any tested corrector schedule at high NFE per block. The masked-vs-uniform regime shift reported is a conditional phenomenon, not a universal ordering.
Conclusion
BlockGen formalizes a blockwise sequence modeling framework with mixture block-size training, agnostic to intra-block paradigms (masked or uniform diffusion). It seamlessly integrates hybrid sampling strategies (ARPC, EIPC), bridging blockwise diffusion and AR verification to achieve substantial improvements in validation likelihood and generative perplexity. BlockGen empowers efficient block-parallel decoding with flexible attention and KV caching, brings blockwise diffusion close to AR quality, and reveals strong numerical trends: ARPC boosts GSM8K accuracy and narrows likelihood gaps; the masked-vs-uniform ranking depends critically on informed sampling schedules and test-time compute. The theoretical and practical implications merit further exploration, especially at larger scales and in highly interactive LLM deployments.