Uniform Diffusion Models Revisited: Leave-One-Out Denoiser and Absorbing State Reformulation
Abstract: Discrete diffusion models are often trained through clean-data prediction, but the prediction can be used in different ways to define the reverse dynamics. In Masked Diffusion Models (MDM) these choices largely coincide, whereas in Uniform Diffusion Models (UDM) they do not. We show that the standard plug-in bridge parameterization for UDM is not optimized by the denoising posterior, but by a leave-one-out posterior that predicts each clean token without using its own noisy observation. This identifies a mismatch between the plug-in ELBO and the usual cross-entropy denoising objective. We characterize the leave-one-out target and derive exact conversions between the denoiser, the leave-one-out posterior, and the score. These conversions allow us to disentangle parameterization and training objective. Our results also lead to inference improvements without any additional training through an informed predictor-corrector sampler and improved temperature sampling based on the leave-one-out predictor. We further introduce an absorbing-state reformulation of uniform diffusion that preserves the UDM joint law while decomposing it into masked-diffusion-like sampling operations, with simpler denoising posteriors, carry-over unmasking, and a natural remasking mechanism. On language modeling, leave-one-out parameterizations consistently improve UDM generation, while the absorbing construction matches or surpasses masked diffusion. These results suggest that the empirical gap between masked and uniform diffusion is driven less by the choice of marginals themselves than by parameterization and sampling design. The code and models can be found at https://github.com/samsongourevitch/rev_udm.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper studies a family of AI models called discrete diffusion models that generate text (and other things made of tokens, like words or Sudoku digits). It focuses on a version called Uniform Diffusion Models (UDM), where during training each token in a sequence is randomly replaced by a uniformly chosen token from the vocabulary.
The authors discover that a very common way people build and train UDMs is actually aiming at the “wrong” target—and they show what the right target should be, how to convert between the two, and how to use this insight to make generation better without extra training. They also show a new way to look at UDMs that makes them behave more like another popular approach called Masked Diffusion Models (MDM), which often work better in practice.
The big questions the paper asks
- When we train a UDM with a popular setup, what exactly is the model learning to predict?
- Is there a mismatch between the usual training goal and the usual loss we optimize?
- Can we translate between different ways of predicting so we can mix and match training and sampling tricks?
- Can we reformulate UDMs so they inherit the practical advantages of masked diffusion models?
Key ideas in everyday language
- Two flavors of “noise”:
- Masked Diffusion (MDM): Replace tokens with a special [MASK] symbol. It’s obvious which tokens are corrupted.
- Uniform Diffusion (UDM): Replace tokens with random tokens from the vocabulary. It’s not obvious which tokens are corrupted.
- Two ways to predict the clean tokens:
- Denoiser: “Given the whole noisy sentence, what was the original clean token here?” It’s allowed to look at the noisy token in that spot.
- Leave-One-Out (LOO): “Guess the clean token at this spot without looking at the noisy token at this spot—only look at the other positions.” Think of a crossword: you guess a missing letter by looking at surrounding letters, not the smudged character itself.
- A popular “plug-in” trick: The model predicts clean tokens, and we plug those predictions into a fixed formula that tells us how to step backward from more noise to less noise. That works fine in MDM. But in UDM, the authors show the best possible prediction for this plug-in trick is the LOO prediction—not the standard denoiser.
What the researchers did (methods and approach)
- Mathematical analysis:
- They analyze the standard training objective (called ELBO) used with the plug-in parameterization in UDMs.
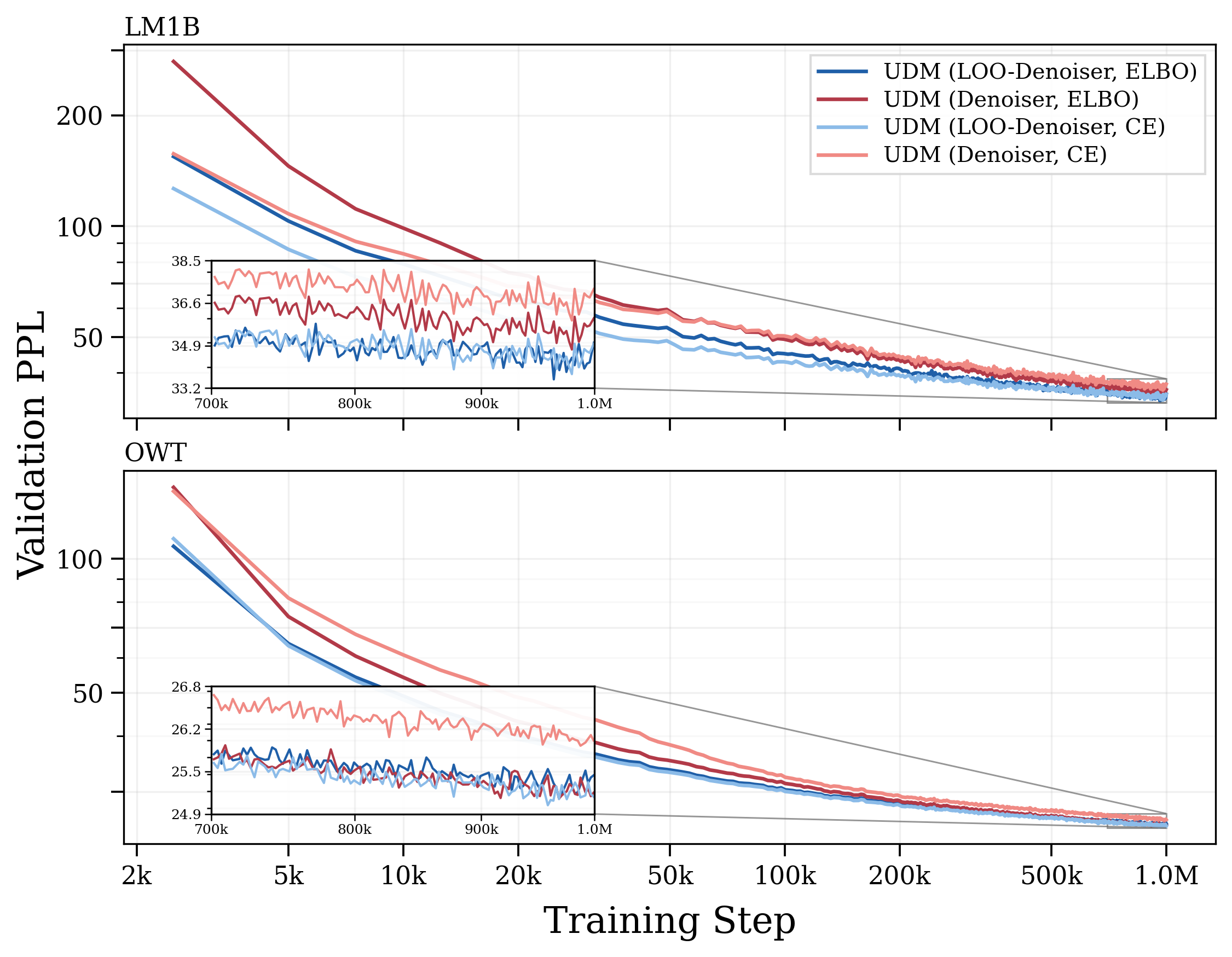
- They prove that, for UDMs, the plug-in ELBO is optimized by the leave-one-out posterior (the LOO predictor), not by the usual denoiser. In MDM, these two coincide, which is why the mismatch wasn’t obvious there.
- Conversion formulas:
- They derive exact formulas to convert between three “languages” of prediction:
- The denoiser (guess the clean token using all the noisy info),
- The leave-one-out predictor (guess without the local noisy token),
- The score (a way to measure how to nudge one token to another).
- These conversions let you train in one form (e.g., denoiser with standard cross-entropy) and use another at sampling time (e.g., LOO), without retraining.
- Better sampling without extra training:
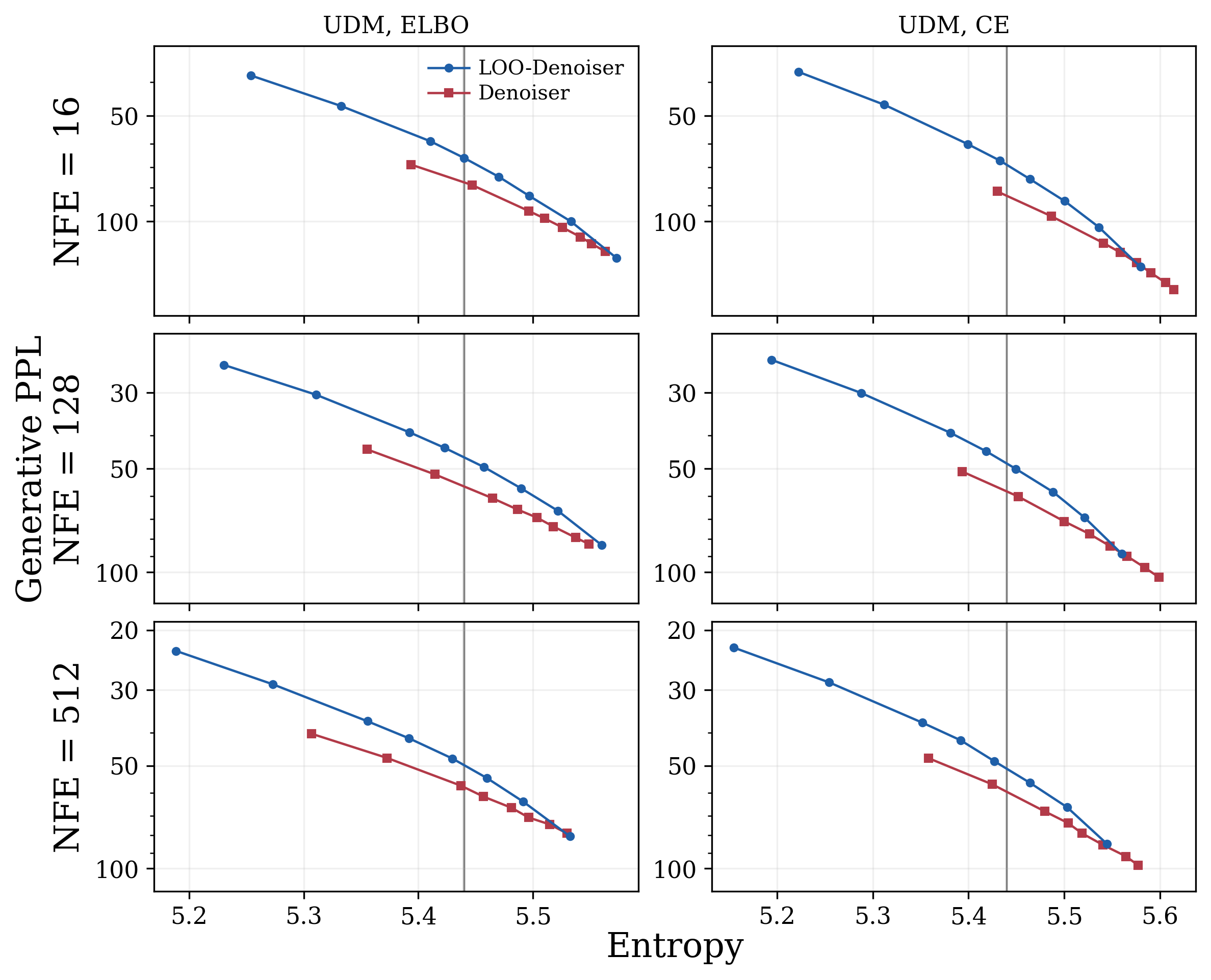
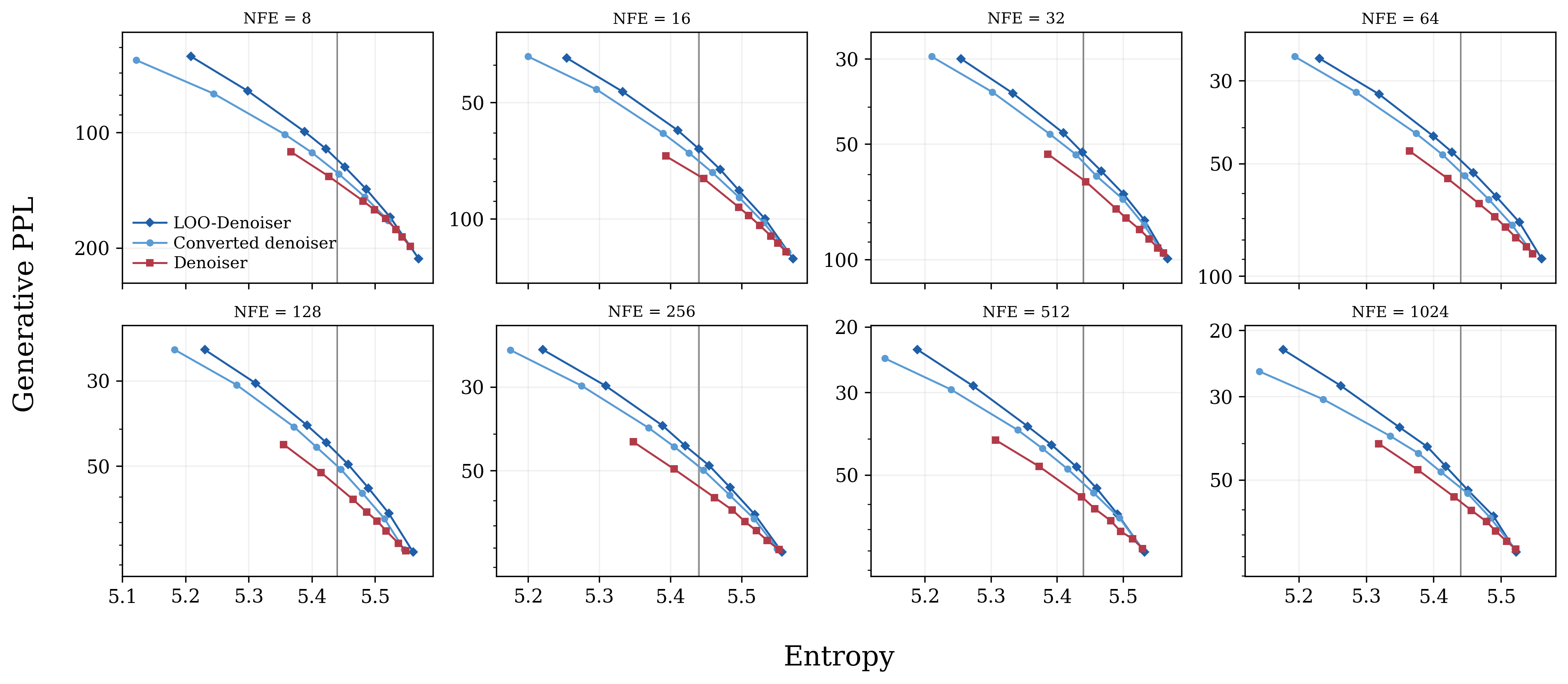
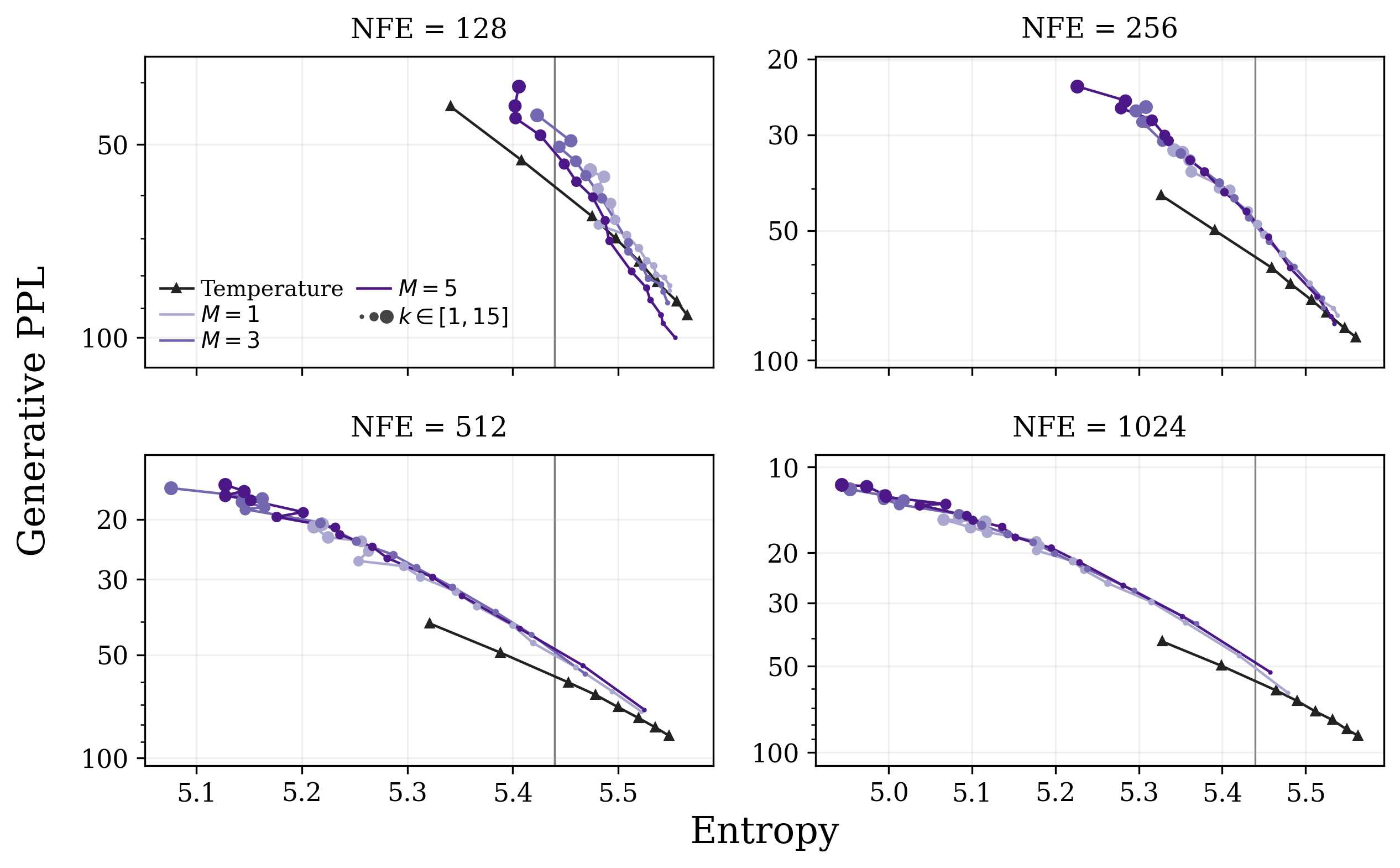
- Predictor-corrector sampler: A two-step sampling loop. “Predictor” moves you along the reverse diffusion; “corrector” cleans up by resampling individual tokens in a principled way. They show how to build a corrector using the LOO predictor that you can obtain from any trained denoiser via their conversion.
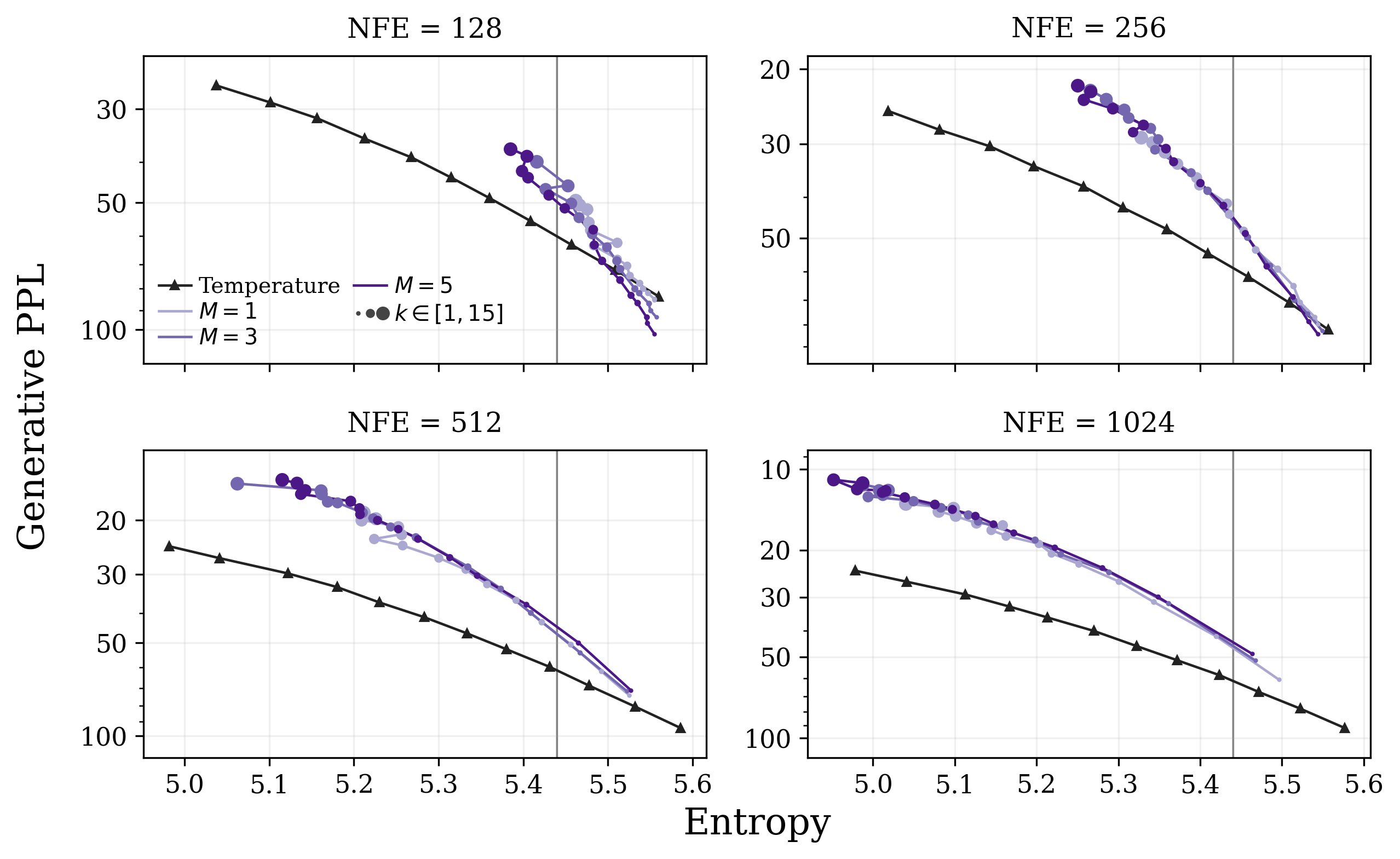
- Temperature/top-p tweaks: They show you get better results when you apply temperature or top-p filtering to the LOO predictions (not to the raw denoiser).
- Absorbing-state reformulation:
- They introduce a new view of UDMs where each position secretly has its own “absorbing” token it tends to become (chosen uniformly at random). Under this view, UDM can be decomposed into masked-diffusion-like steps with simpler posteriors and a natural “remasking” step.
- They present two constructions (AUDM and MUDM) that preserve the original UDM process but let you reuse masked-diffusion tricks.
- Experiments:
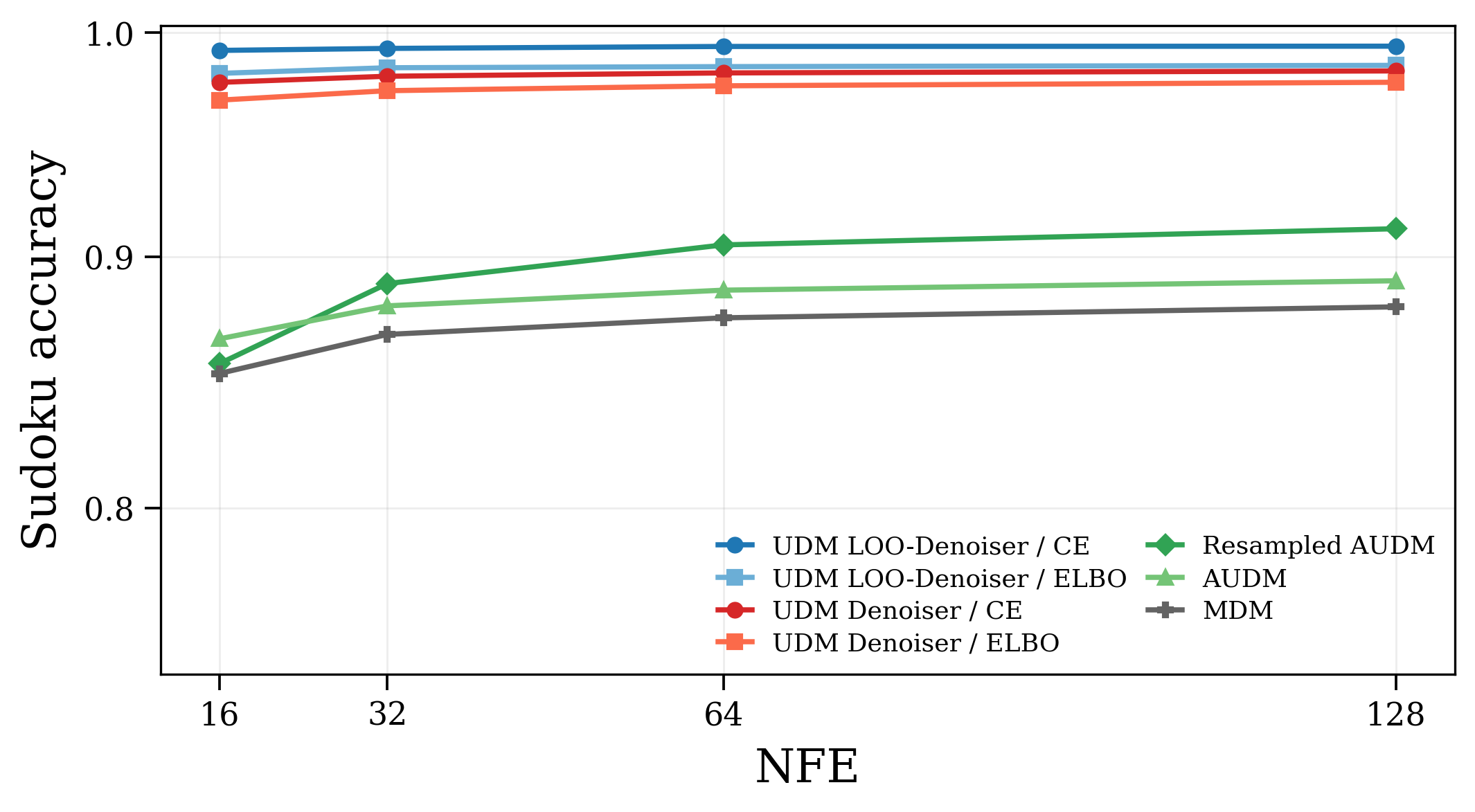
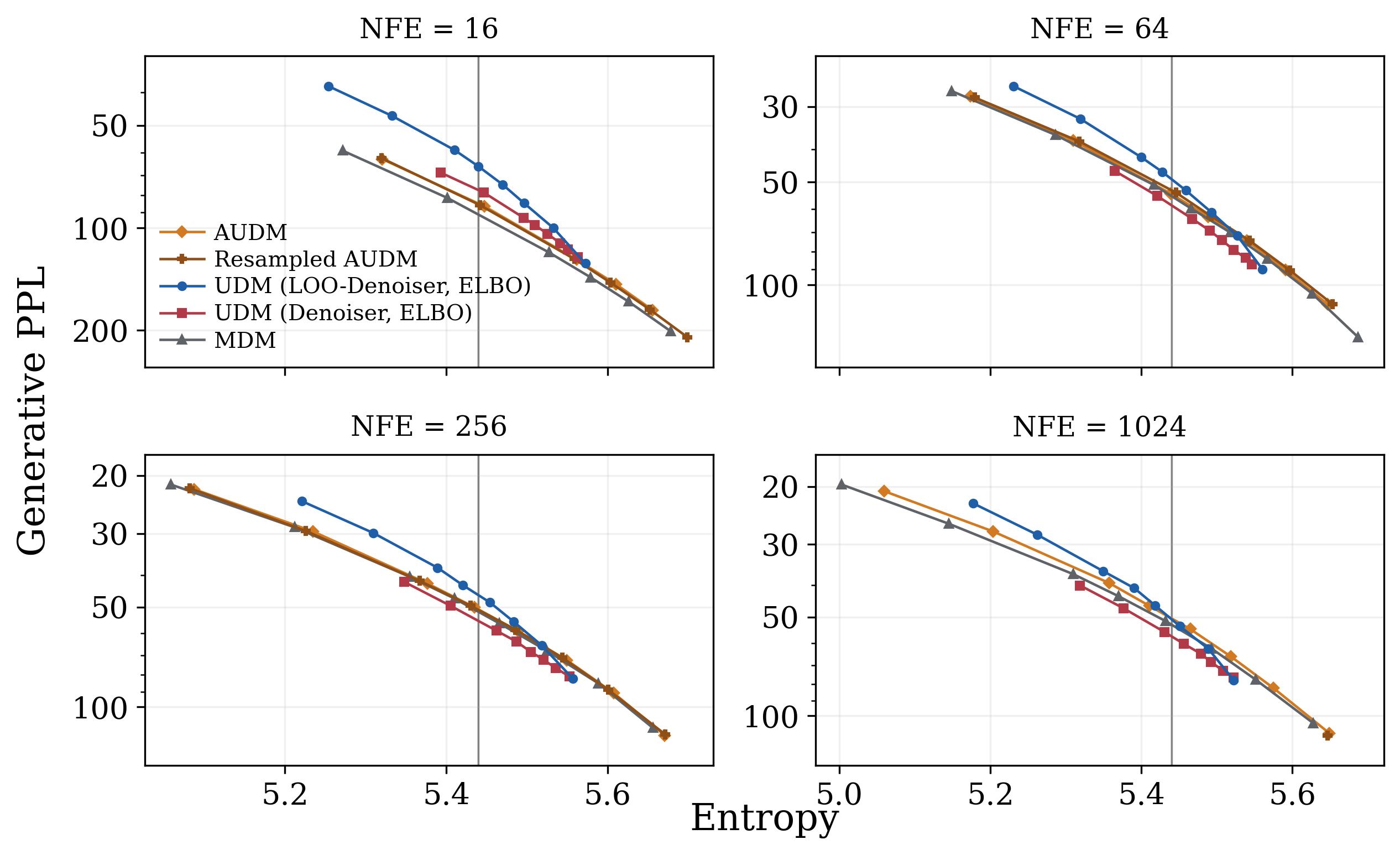
- They test on large-scale language modeling and on Sudoku.
- They compare denoiser vs LOO parameterizations, plug-in vs other parameterizations, with and without the new samplers.
Main findings and why they matter
- The target is different in UDM: With the popular plug-in setup, the best possible model predicts leave-one-out probabilities, not the standard denoiser. That explains why some UDM training recipes feel mismatched.
- Conversions make life easy: Because they can translate between denoiser, LOO, and score, you can:
- Train with standard cross-entropy as a denoiser,
- Convert to LOO at test time,
- Use a better sampler and better temperature/top-p application,
- All without retraining an auxiliary model.
- Better generation quality: Across settings, directly parameterizing or using the leave-one-out predictor gives consistently better text generation for UDM.
- Absorbing-state view narrows the gap: The absorbing-state reformulation (AUDM/MUDM) matches or beats masked diffusion in perplexity and sample quality, suggesting the usual gap between UDM and MDM isn’t about the noise type itself, but about parameterization and sampling choices.
- Practical tip: Apply temperature/top-p to the LOO predictions, not to the raw denoiser, for an easy quality boost without extra training.
What this could change (impact and implications)
- Better discrete diffusion models: Developers can build stronger UDM-based text generators by aiming at the leave-one-out target (or converting to it) and using the improved sampling strategies.
- Unifying recipes: The conversion formulas let teams mix their favorite training losses with the best-performing sampling pipelines, reducing engineering overhead.
- Bridging UDM and MDM: The absorbing-state perspective shows UDM can inherit MDM’s practical advantages, pointing to a unified toolkit for discrete diffusion.
- Faster progress with fewer resources: Because many improvements come from smarter sampling and parameterization—rather than bigger models or more training—this work could make high-quality diffusion-based LLMs more accessible.
If you want to dive deeper or try the code and models, the authors provide them here: https://github.com/samsongourevitch/rev_udm
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and avenues for future work that arise from the paper’s analysis and constructions.
- Dependence on bridge extensions: The optimality of the plug-in ELBO at the leave-one-out (LOO) posterior relies on a specific non-affine bridge extension that satisfies the simplex-Bayes property (Assumption A). It remains unclear how different valid bridge completions affect the optimal target, optimization, and empirical performance, and whether a principled selection criterion exists.
- Beyond UDM/MDM corruption processes: The derivations and exact denoiser↔LOO↔score conversions hinge on UDM’s strictly positive forward transitions. Extensions to other discrete corruptions (e.g., non-uniform marginals, structured or position-coupled noise) are not developed—what is the correct target for plug-in parameterizations and are similarly simple conversions available?
- MDM conversions: For MDM, $\fw{t0}{x_0^\ell}{x_t^\ell}$ can be zero (e.g., ), breaking the invertibility used in UDM. It remains open whether alternative formulations can recover a LOO-like quantity from a denoiser or score in MDM, or whether new objectives/parameterizations are required.
- Enforcing LOO invariance: The LOO target must be invariant to at position . The paper notes Hollow Transformers enforce this structurally but perform worse in practice. There is no proposed regularizer or architecture that enforces (or penalizes violations of) this invariance while retaining the performance of standard attention—designing such mechanisms is an open problem.
- Stability and conditioning of conversions: The denoiser↔LOO mapping in UDM introduces time- and -dependent logit shifts (e.g., ). The numerical conditioning, error amplification, and calibration properties of these conversions—especially for extreme or very large vocabularies—are not analyzed.
- Optimal noise schedules for LOO: The effect of the noise schedule on the statistical and optimization behavior of LOO parameterizations (e.g., bias/variance of gradients, calibration, or the extent of dependence on ) is not theoretically or empirically characterized; joint schedule–model optimization remains open.
- Predictor–corrector (PC) theory with heuristics: The Gibbs corrector based on LOO preserves only for sequential updates; the paper uses margin-based, parallel updates for efficiency. The stationary distribution, bias, and mixing-time properties of this heuristic PC (and its dependence on thresholds or batch size) are unstudied.
- When and how to apply sampling heuristics: Applying temperature or top- to the LOO predictor improves quality empirically, but the induced distribution is no longer the trained model. There is no analysis of how these modifications distort likelihoods, affect calibration, or how to schedule temperature/top- over .
- Coupling parameterization choice and objective: While the paper disentangles parameterization and training losses (e.g., training a LOO predictor via cross-entropy), a systematic comparison of optimization landscapes (e.g., curvature, convergence rates, generalization) across objective/parameterization pairs is missing.
- AUDM objective properties: The continuous-time AUDM NELBO involves expectations over with indicator-weighted terms. The variance of gradient estimators, optimization stability, and the relationship of this objective to standard cross-entropy or to MDM ELBOs (beyond formal resemblance) are not analyzed.
- Time dependence in AUDM: Unlike MDM, the noise-conditioned (absorbing-state) denoiser remains time-dependent. Strategies to mitigate this (e.g., reparameterizations, reweightings, or alternative noise priors over ) and the implications for reusing MDM-trained denoisers are not developed.
- Resampling correctness under approximation: Algorithm 1 (AUDM with resampling) provably preserves the exact UDM joint when exact posteriors/bridges are used. In practice, learned approximations are used. There is no bound or analysis of how approximation errors in and bridges propagate through resampling and how they affect the induced joint distribution.
- Computational trade-offs: The cost/benefit of LOO parameterization and PC correctors at scale (large , long sequences) is not quantified—e.g., wall-clock trade-offs versus autoregressive baselines or MDM, memory overheads, and the marginal utility of additional corrector steps.
- Non-factorized forward processes: The entire analysis assumes token-wise independent forward transitions. Many discrete domains exhibit structured corruption (e.g., permutations, grammatical constraints). Extending LOO targets, conversions, and PC schemes to such settings remains open.
- Robustness and generalization: The empirical claims are focused on language (and Sudoku). It remains unclear how the LOO and absorbing-state constructions transfer to other modalities (e.g., images with VQ tokens, protein sequences), to variable-length sequences, or to extreme vocabulary sizes.
- Experimental ablations and scaling laws: The paper argues the masked–uniform gap is driven by parameterization/sampling rather than marginals, but systematic ablations across , , compute budgets, and architectures are not reported here. Rigorous scaling-law analyses and fairness controls (e.g., identical capacity, training schedules) are needed.
- Interaction with rate-matrix parameterizations: The paper discusses three parameterizations (score, denoiser, plug-in/bridge). A precise prescription for mapping LOO predictors to rate matrices in CTMC-style reverse processes (including stability and identifiability) is not provided.
- Global optimality vs practical optimization: Uniqueness of the ELBO minimizer is shown for UDM in function space, but the landscape under neural parameterization (spurious minima, sensitivity to initialization) and the generalization gap between training -discretizations and continuous-time targets remain unstudied.
- Choice of absorbing-state prior: AUDM assumes . It remains unexplored whether non-uniform or learned priors over (e.g., frequency-weighted or context-dependent) could improve optimization, calibration, or sample quality while preserving desirable properties.
- Formalization of MUDM: The “Masked Uniform Diffusion” (MUDM) construction is introduced but not fully specified in the presented text (training objective, inference mechanics, guarantees, and empirical evaluation). A complete formal treatment and comparison to AUDM/MDM/UDM is needed.
- Regularizers for LOO invariance: The paper proposes sensitivity-to- as a diagnostic but does not propose a concrete regularizer or training constraint to enforce LOO invariance without the drawbacks of Hollow attention, nor evaluate its effect on performance.
Practical Applications
Overview
The paper revisits discrete Uniform Diffusion Models (UDMs) and shows that:
- The commonly used bridge plug-in parameterization is optimized by a leave-one-out (LOO) posterior, not the standard denoising posterior.
- Exact conversions exist between denoiser, LOO posterior, and concrete score for UDMs.
- These conversions enable better training and inference (e.g., informed predictor-corrector and improved top‑p/temperature sampling) without extra training.
- An absorbing-state reformulation (AUDM) and a masked-uniform variant (MUDM) preserve the UDM joint law while enabling masked-diffusion-like operations (carry-over unmasking and natural remasking), simplifying inference.
- Empirical gains are shown in language modeling and a Sudoku task.
Below are practical, real-world applications derived from the paper’s findings. Each bullet includes sectors and key dependencies or assumptions.
Immediate Applications
The following can be deployed now with existing discrete diffusion codebases and UDM checkpoints.
- Plug-and-play informed predictor-corrector for UDMs
- What: Add a Gibbs-style corrector based on the LOO posterior (computed from a trained denoiser via the paper’s conversion) between reverse steps; improves sample quality at no extra training cost.
- Sectors: Software/AI (language modeling, code generation), Content tools (document editing/infill), Gaming (level/text asset generation).
- Tools/workflows:
- Compute LOO probabilities from any UDM denoiser using the provided conversion.
- Insert a margin-based, parallelizable corrector step (as in the paper) into existing samplers.
- Dependencies/assumptions:
- Uniform diffusion forward process with known schedule and strictly positive transition probabilities.
- Conversion relies on UDM positivity (not generally available for MDM).
- Better decoding via top‑p/temperature applied to the LOO predictor
- What: Apply temperature scaling or nucleus sampling to LOO probabilities (not to the raw denoiser) to reduce degeneracy and improve diversity.
- Sectors: Software/AI, Creative tools (story generation, dialogue systems).
- Tools/workflows: Drop-in change to decoding pipeline; no retraining needed.
- Dependencies/assumptions:
- Availability of LOO probabilities (via conversion or direct LOO parameterization).
- Swap training target to LOO with standard cross-entropy
- What: Use cross-entropy to train a model whose underlying prediction parameterizes the LOO posterior (converted to a denoiser for the loss), aligning the target with the plug-in NELBO optimum for UDMs.
- Sectors: AI/ML R&D, Foundation model training.
- Tools/workflows:
- Implement the paper’s denoiser↔LOO conversion in the training loop (simple logit adjustment).
- Optionally add architectural or regularization biases to promote LOO invariance.
- Dependencies/assumptions:
- UDM schedule; stable training setup; data tokenization.
- Model diagnostics via LOO invariance testing
- What: Use the LOO structural property (each position’s prediction should be invariant to its own noisy token) as a diagnostic to detect suboptimal training or overreliance on self-token.
- Sectors: Model monitoring, Responsible AI, QA pipelines.
- Tools/workflows:
- After training, convert to LOO and measure sensitivity to the local input token per position as a health metric.
- Dependencies/assumptions:
- Ability to compute LOO from a trained denoiser; applies cleanly in UDM.
- Absorbing-State UDM (AUDM) sampler: reuse MDM-style operations
- What: Reformulate UDM as a mixture of absorbing-state processes to enable MDM-like carry-over (positions that are unambiguous are copied) and a natural remasking mechanism, simplifying inference while preserving UDM joint law.
- Sectors: Software/AI (faster and simpler inference), Production ML systems with mixed masked/uniform code paths.
- Tools/workflows:
- Implement the “Remasked AUDM sampler” (noise resampling + bridge + denoiser steps).
- Reuse MDM infrastructure and kernels with minimal changes.
- Dependencies/assumptions:
- Correct implementation of the resampling distribution to preserve UDM joint law.
- Availability of a UDM-compatible denoiser or LOO predictor.
- Masked-to-Uniform portability (MUDM-style wrapper)
- What: Reuse existing masked-diffusion denoisers within a UDM framework by conditioning on latent transition times/absorbing states (as outlined in the paper), enabling teams to leverage prior MDM investments.
- Sectors: AI/ML engineering, Model serving platforms, Libraries.
- Tools/workflows:
- Introduce a wrapper that maps masked-diffusion denoiser outputs into UDM-consistent transitions.
- Dependencies/assumptions:
- Correct latent conditioning; alignment of schedules; careful implementation to match UDM joint law.
- Improved text infilling and document editing
- What: Use LOO-based correctors and AUDM carry-over to perform parallel, constraint-aware updates for infilling/rewriting (positions with high certainty carry over; ambiguous positions are updated).
- Sectors: Productivity software, IDEs (code infill), Publishing.
- Tools/workflows:
- Integrate LOO corrector with UI-level infill controls (e.g., mask spans, target style).
- Dependencies/assumptions:
- Tokenized discrete domain; reliable LOO estimates.
- Enhanced discrete CSP solvers (e.g., Sudoku)
- What: Apply LOO-informed correctors to structured problems; improves feasibility and convergence without extra training.
- Sectors: Operations research (prototyping), Education (teaching constraint reasoning), Games.
- Tools/workflows:
- Encode CSPs as token sequences; run informed Gibbs correctors at each time.
- Dependencies/assumptions:
- Problem-specific tokenization and constraint checks; realistic schedules.
- Fairer benchmarking between MDM and UDM
- What: Use the absorbing-state construction and parameterization disentanglement to conduct apples-to-apples comparisons and ablations (marginals vs parameterization vs sampler).
- Sectors: Academia, Research teams, Standards bodies (evaluation guidelines).
- Tools/workflows:
- Shared pipelines that toggle the same sampler/parameterization across marginals.
- Dependencies/assumptions:
- Comparable compute and data; careful experimental design.
Long-Term Applications
These require further scaling, research, or engineering before broad production deployment.
- Production-grade UDM-based LLMs
- What: Replace or complement autoregressive LLMs with high-quality UDMs leveraging LOO-targeted training and predictor-correctors for speed/quality trade-offs.
- Sectors: Conversational AI, Search, Assistants, Code assistants.
- Tools/products:
- Discrete diffusion LMs with parallel token updates and dynamic compute controls.
- Dependencies/assumptions:
- Large-scale training stability; inference kernels optimized for parallel updates; strong pretraining corpora.
- General-purpose discrete solvers via LOO Gibbs engines
- What: Build iterative solvers for planning/optimization (routing, scheduling, program synthesis) using LOO-informed conditional updates and constraint-aware correctors.
- Sectors: Logistics, Robotics planning, Dev tools (autofix/repair), Finance (portfolio constraints).
- Tools/workflows:
- Integrate hard/soft constraints into corrector selection; margin-based parallel updates.
- Dependencies/assumptions:
- Robust constraint encoding; convergence diagnostics; safety/verification layers.
- Unified masked–uniform pipelines for multimodal token generators
- What: Apply AUDM/MUDM to tokenized audio, image, and video models to combine masked-diffusion ergonomics with UDM marginals.
- Sectors: Media generation, A/V editing, Creative suites.
- Tools/products:
- Shared denoiser modules with switchable marginals; modular samplers per domain.
- Dependencies/assumptions:
- High-quality tokenizers (e.g., VQ tokenizers); domain-specific schedules and bridges.
- Energy- and latency-optimized inference on edge devices
- What: Leverage parallel token updates and informed correctors to reduce the number of reverse steps while maintaining quality, lowering latency and energy.
- Sectors: Mobile AI, Embedded systems, On-device assistants.
- Tools/workflows:
- Kernel fusion for corrector steps; adaptive step-count policies.
- Dependencies/assumptions:
- Hardware-aware implementations; efficient categorical sampling; memory-bound optimizations.
- Reliability and governance via LOO-based auditing
- What: Use LOO invariance as an interpretability and robustness signal (detect self-token leakage, spurious shortcuts) for model audits, compliance, and safety checks.
- Sectors: Policy/Compliance, Healthcare, Finance.
- Tools/products:
- “LOO Sensitivity” dashboards; pre-deployment checks; drift detectors in monitoring.
- Dependencies/assumptions:
- Calibrated thresholds; domain-specific baselines; integration with A/B safety tests.
- Architectures enforcing LOO invariance (Hollow Transformers)
- What: Develop and stabilize architectures that enforce no self-attention to the same position to “hard-code” LOO invariance.
- Sectors: Research, High-performance training teams.
- Tools/workflows:
- Position-wise masking in attention; specialized regularizers; hybrid attention schemes.
- Dependencies/assumptions:
- Training stability and effectiveness in large-scale settings; empirical trade-offs vs standard attention.
- Curriculum and data-centric training via remasking schedules
- What: Use AUDM’s natural remasking to design curricula that control difficulty (e.g., vary the fraction of ambiguous positions) during training and fine-tuning.
- Sectors: Education-tech (tutored generation), Model training platforms.
- Tools/workflows:
- Dynamic noise/absorbing schedules; difficulty-aware sampling.
- Dependencies/assumptions:
- Task-specific curricula; robust schedule tuning.
- AutoML and interchangeability of parameterizations
- What: Automate swapping among denoiser/LOO/score parameterizations at train and inference time based on metrics and hardware, using the paper’s exact conversions.
- Sectors: MLOps, AutoML frameworks, Model hubs.
- Tools/workflows:
- Pipelines that choose targets (ELBO vs CE), samplers (predictor-corrector variants), and decoding policies.
- Dependencies/assumptions:
- Reliable meta-metrics; standardized APIs for conversions; reproducible schedules.
Notes on Feasibility and Dependencies
- The exact conversions between denoiser, LOO posterior, and score rely on UDM’s strictly positive forward transitions; they generally do not hold for MDM without extra assumptions.
- Predictor-corrector correctness depends on using the conditional distributions that preserve the marginal; margin-based heuristics improve practicality but are heuristic.
- Absorbing-state resampling recovers the UDM joint law only if the resampling distribution is correctly implemented; engineering rigor is required for production.
- Reported gains are on language modeling and Sudoku; porting to other discrete domains (e.g., code, protein sequences, tokenized images/audio) requires domain-specific validation.
- Real-world gains hinge on efficient categorical sampling, parallelization, and schedule tuning; hardware-aware optimizations are recommended.
Glossary
- Absorbing sequence: A per-position latent sequence of tokens used as absorbing values in an auxiliary formulation of uniform diffusion. "latent absorbing sequence"
- Absorbing State Uniform Diffusion Model (AUDM): A construction that conditions uniform diffusion on per-position absorbing tokens to obtain masked-diffusion-like structure. "Absorbing State Uniform Diffusion Model (AUDM)"
- Absorbing-state denoiser: A denoiser conditioned on the absorbing sequence in the AUDM formulation. "first sampling from an absorbing-state denoiser, then the uniform bridge"
- Absorbing-state diffusion: A process where each coordinate can be absorbed into a fixed token and remain there. "each coordinate evolves as an absorbing-state diffusion"
- Absorbing-state reformulation: Rewriting uniform diffusion as a process with per-position absorbing states without changing its joint law. "an absorbing-state reformulation of uniform diffusion"
- Auxiliary noise variable: An extra random variable, independent across positions, introduced to condition and simplify the diffusion process. "be an auxiliary noise variable"
- Bayes' formula: The rule relating forward and reverse probabilities, used here to define bridges only on supported pairs. "the bridge is determined by the Bayes' formula only on pairs"
- Bridge: The conditional distribution of an intermediate state given endpoints (clean and noisy states) in a diffusion process. "We refer to this quantity, which is central to the paper, as the bridge."
- Bridge plug-in parameterization: A reverse-time parameterization that plugs a network’s clean-token prediction directly into the bridge. "the bridge plug-in parameterization"
- Carry-over structure: The property that certain tokens are deterministically carried over across steps in masked-like processes. "the masked-diffusion carry-over structure"
- Carry-over unmasking: A sampling mechanism where already-determined tokens persist across steps while others are unmasked. "carry-over unmasking"
- Categorical distribution: A discrete distribution over a finite set; used to model token choices. "denote by the categorical distribution with parameter "
- Concrete score: The ratio of probabilities for neighboring states (Hamming distance 1), providing a score-like parameterization for discrete diffusion. "the concrete score \cite{campbell2022continuous, lou2024discrete}"
- Cross-entropy: A training objective measuring the log-loss of predicted token distributions against ground truth. "the usual cross-entropy denoising objective"
- Denoiser: A model predicting the clean data tokens from noisy observations in diffusion. "a denoiser, where the network assigns probabilities to possible clean "
- Denoising posterior: The posterior distribution of clean tokens given noisy observations. "with $\pdata{0 t}{x_t}{\cdot}$ the denoising posterior"
- Dirac mass: A degenerate distribution concentrated at a single token. "the denoiser is the Dirac mass at "
- ELBO: Evidence Lower BOund; a variational objective used to train diffusion models. "the plug-in ELBO"
- Expected NELBO: The expectation of the negative ELBO over data, used as a training loss. "minimizing the expected NELBO"
- Factorized transitions: Transition kernels that decompose across token positions, enabling parallel updates. "the factorized transitions of the joint law on the augmented states"
- Gibbs updates: Iterative conditional resampling steps that preserve a target distribution. "iterating the corresponding Gibbs updates gives a corrector kernel"
- Hollow Transformer: An architecture whose output at position ℓ cannot attend to the input at position ℓ, enforcing leave-one-out structure. "with a Hollow Transformer"
- Inductive bias: Structural assumptions in model design that reflect process properties and can aid learning. "does not exploit the inductive bias associated with the forward process"
- Jensen's inequality: A convexity-based inequality used to derive an ELBO-style upper bound. "Applying Jensen's inequality"
- Joint law: The full distribution over trajectories or multiple variables (e.g., states across time). "preserves the UDM joint law"
- Leave-one-out posterior: The posterior for a token conditioned on all noisy tokens except its own, central to the optimal plug-in parameterization. "leave-one-out posterior"
- Marginalization parameterization: A reverse-time parameterization that marginalizes over the denoising posterior through the bridge. "The marginalization parameterization"
- Markov process: A stochastic process where the future depends only on the present state, not the past history. "We consider a Markov process "
- Masked Diffusion Models (MDM): Discrete diffusion models that corrupt tokens to a special mask symbol. "In Masked Diffusion Models (MDM)"
- Masked Uniform Diffusion Model (MUDM): An absorbing-state construction that matches UDM joint law while reusing masked-diffusion parameterizations. "Masked Uniform Diffusion Model (MUDM)"
- Mixture (of transitions): A convex combination over latent variables, here expressing UDM forward transitions as mixtures over absorbing states. "is a mixture of absorbing-state transitions"
- Monotone noise schedule: A time-dependent function controlling corruption intensity that decreases from 1 to ~0. "is a monotone noise schedule"
- Noise-conditioned denoiser: A denoiser that conditions on the latent absorbing sequence, remaining explicitly time-dependent. "the noise-conditioned denoiser remains explicitly time-dependent"
- One-coordinate conditional: The conditional distribution of a single token given all others at a time step. "gives access to the one-coordinate conditional of $\pdata{t}{}{}$"
- One-hot vector: A vector with a single 1 and zeros elsewhere, representing a single categorical choice. "which is not necessarily a one-hot vector"
- Perplexity: An evaluation metric for LLMs related to average log-likelihood. "motivated by their better perplexity at large vocabulary size"
- Predictor-corrector sampler: A two-stage sampler combining a predictive reverse step with corrective MCMC-style updates. "an informed predictor-corrector sampler"
- Probability simplex: The set of nonnegative vectors summing to 1, parameterizing categorical distributions. "we write for the probability simplex"
- Rate matrix: A generator for continuous-time Markov chains; here parameterized by a learned score. "a score parameterizing a rate matrix"
- Reference distribution: The simple prior distribution at the terminal time that is transported to data by reverse dynamics. "transporting a reference distribution"
- Remasking mechanism: A mechanism that reintroduces ambiguity or masking during sampling to aid generation. "a natural remasking mechanism"
- Resampling: Redrawing latent variables (e.g., absorbing states) during reverse-time sampling to match a target joint law. "resampling the absorbing-state"
- Reverse-chain law: The joint distribution of states along the reverse-time Markov chain in diffusion models. "UDM reverse-chain law"
- Reverse dynamics: The time-reversed stochastic transitions used for generation from the prior to data. "define the reverse dynamics"
- Reverse transitions: The conditional distributions used to move backward in time during generation. "approximate the reverse transitions"
- Temperature sampling: A heuristic that scales logits or distributions to control randomness during sampling. "improved temperature sampling"
- Top-: Nucleus sampling that restricts sampling to the smallest mass of tokens whose cumulative probability exceeds p. "top-"
- Uniform Diffusion Models (UDM): Discrete diffusion models where corruption replaces tokens with uniformly sampled tokens. "Uniform Diffusion Models (UDM)"
- Zero-remasking property: A constraint in masked diffusion that prevents remasking of already unmasked tokens during training. "the zero-remasking property"
Collections
Sign up for free to add this paper to one or more collections.