Generalized Discrete Diffusion from Snapshots
Abstract: We introduce Generalized Discrete Diffusion from Snapshots (GDDS), a unified framework for discrete diffusion modeling that supports arbitrary noising processes over large discrete state spaces. Our formulation encompasses all existing discrete diffusion approaches, while allowing significantly greater flexibility in the choice of corruption dynamics. The forward noising process relies on uniformization and enables fast arbitrary corruption. For the reverse process, we derive a simple evidence lower bound (ELBO) based on snapshot latents, instead of the entire noising path, that allows efficient training of standard generative modeling architectures with clear probabilistic interpretation. Our experiments on large-vocabulary discrete generation tasks suggest that the proposed framework outperforms existing discrete diffusion methods in terms of training efficiency and generation quality, and beats autoregressive models for the first time at this scale. We provide the code along with a blog post on the project page : \href{https://oussamazekri.fr/gdds}{https://oussamazekri.fr/gdds}.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Generalized Discrete Diffusion from Snapshots (GDDS) — A simple explanation
What is this paper about?
This paper introduces GDDS, a new way to train AI models that generate text (and other things made of discrete symbols, like words, characters, or graph nodes). It improves “discrete diffusion” models—a family of models that learn by repeatedly adding noise (messing things up) and then learning to remove that noise (cleaning things up). GDDS makes this process more flexible, faster, and easier to train, and it shows strong results on language tasks.
What questions are the researchers trying to answer?
In simple terms:
- Can we design a more flexible way to “mess up” text so the model learns better? (Instead of using only blunt tools like masking or random replacement.)
- Can we train diffusion models without tracking every tiny step of how the text was noised? (That’s slow and complicated.)
- Can this improved training make diffusion models as good as—or even better than—traditional autoregressive models that write text one token at a time?
How does GDDS work? (In everyday language)
Think of a sentence as a clean picture. Diffusion models first blur or smudge it (the “forward” process), then learn how to un-blur it (the “reverse” process).
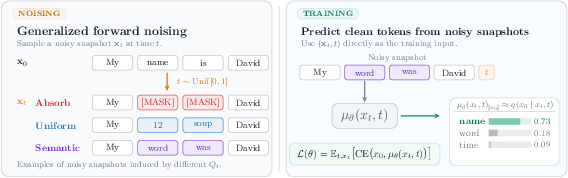
- Forward noising (adding noise):
- Past methods mostly used two blunt tools:
- Masking: replace words with [MASK].
- Uniform noise: replace a word with a random word from the vocabulary.
- GDDS lets you use many smarter ways to add noise. For example, it can replace a word with a similar word (“cat” → “kitten”) more often than a random one (“cat” → “volcano”). This uses the idea that some words are closer in meaning.
- Uniformization (simple idea): Instead of calculating complicated math to see exactly how a sentence looks after noise, GDDS turns the process into a series of easy, random steps:
- Randomly decide how many times to make a change.
- At each step, pick which word to change and what to change it to (using your chosen rule, like “prefer similar words”).
- This gives you the noised sentence quickly and exactly, without heavy calculations.
- Reverse denoising (cleaning up):
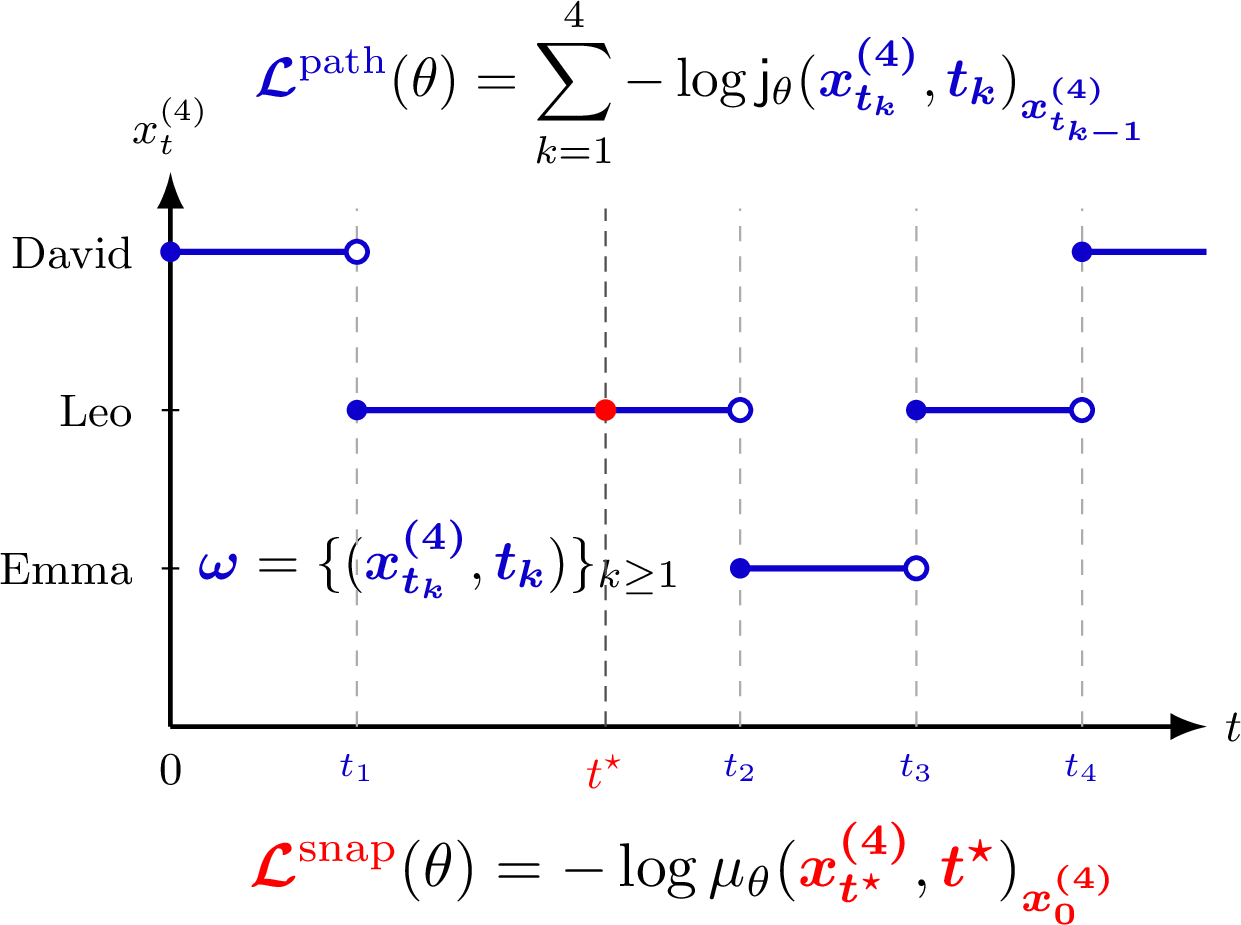
- Many older methods asked the model to both decide when to change a word and where to change it to, based on the entire noising history. That’s like asking it to remember every blob of paint that was added to the picture—not very training-friendly.
- GDDS introduces “snapshot” training: instead of tracking the entire noising path, the model just sees a single snapshot—a noised sentence at a random time—and learns to guess the original. It’s like giving the model one blurry photo and asking, “What did this look like before?”
- The training objective (called an ELBO in the paper) becomes a clear, simple “how good was your guess?” score the model can optimize efficiently.
- This snapshot approach fits neatly with standard Transformer architectures (the same family used in many LLMs).
What did they find, and why does it matter?
- Flexibility: GDDS is a general framework. It works with many kinds of noise, including “semantic” noise that prefers replacing a word with a similar one. This gives the model structure-aware practice—much closer to how language actually works.
- Efficiency: The uniformization trick makes the forward noising fast and exact, even for very large vocabularies (like the ones in modern LLMs).
- Better training and quality: Training only on snapshots (one noised view at a time) aligns the model’s task with what it predicts (the original text), making learning more stable and effective.
- Strong results:
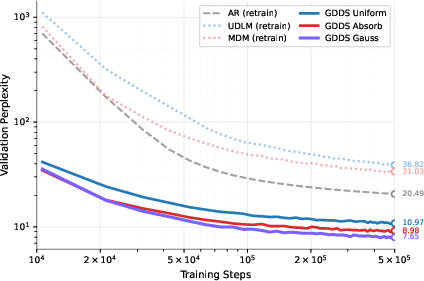
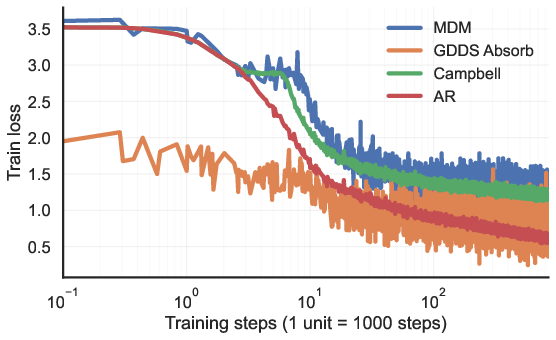
- On widely used language datasets (like Text8 and OpenWebText), GDDS outperforms previous discrete diffusion models.
- In some cases, it even beats autoregressive models (which traditionally dominate language tasks) using similar compute.
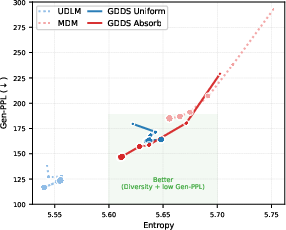
- Using semantic-informed noise (replace words with similar ones more often) leads to better generalization on new datasets (lower “perplexity,” which measures how confused the model is—lower is better).
Why is this important?
- Better training recipe: GDDS shows that training on single snapshots can be both simpler and more effective than tracking the entire noising path. That’s a big deal for scaling diffusion models to large vocabularies and long sequences.
- More realistic noise: Letting the noising process respect meaning (semantic similarity) makes the denoising task more natural and helps models generalize better—useful for real-world language tasks.
- Competitive generation: GDDS narrows the gap (and sometimes surpasses) autoregressive models, while allowing parallel generation (predicting all tokens at once), which can be faster at inference.
- Broader impact: Although the paper focuses on text, the ideas also apply to other discrete data like graphs, code, or molecules—anywhere you have symbols and rules.
In short
GDDS is a smarter, more flexible way to train diffusion models on words and other symbols. It speeds up the “messing up” phase, simplifies the “cleaning up” training, and uses more meaningful noise. The result is better performance and stronger generalization, opening the door to faster, high-quality generation in language and beyond.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Formal conditions for interpolating matrices: Precisely characterize when the proposed interpolating family is invertible and induces a valid CTMC for arbitrary and (beyond the footnoted assumptions), including sufficient and necessary conditions guaranteeing non-negativity and mass conservation in .
- Tightness and calibration of snapshot ELBO: Quantify how tight the snapshot-latent ELBO is relative to the true (intractable) log-likelihood and to the path-wise ELBO across general corruption processes. Provide general-purpose, model-class–dependent bounds on the NLL gap decomposition (IPG vs. CG), and diagnostics to assess bound looseness during training.
- Optimal time sampling and weighting: Investigate whether Uniform is an optimal sampling distribution over for snapshot training. Explore and justify alternative importance-weighting schemes over (or adaptive schedules) that minimize IPG or improve calibration.
- Reverse-time generation algorithm details: Specify and evaluate the full reverse-time sampling procedure under arbitrary noising (including how many denoising steps, schedules, and computational costs), and clarify how the snapshot denoiser is used during sampling (e.g., via Bayes rule or other mappings from to reverse transitions) with analysis of induced biases.
- Consistency guarantees: Establish theoretical conditions under which minimizing the snapshot ELBO yields a consistent estimator of the true posterior and leads to generative consistency (e.g., convergence to the data distribution as capacity/data grow).
- Non-shared exit rates in practice: The extension from shared to non-shared exit rates is stated (via thinning), but a concrete, efficient algorithm, its variance properties, and empirical trade-offs versus the shared-rate case are not provided.
- Uniformization efficiency at scale: Provide a detailed complexity analysis (expected number of jumps per token as a function of , sequence length, and -distribution), GPU/TPU implementation details (e.g., warp divergence due to variable-length paths), and comparisons with closed-form forward processes in training-time throughput.
- Reverse exit-rate usage at inference: For path-wise models, reverse-time simulation needs reverse exit rates . Clarify how these are computed or approximated in general CTMCs where is unknown, and assess the impact of estimation error on generation quality.
- Path-wise (Campbell) objective viability: The paper notes subpar performance with the Campbell estimator and two-stream architectures. Explore whether architectural choices, curriculum strategies, or alternative weightings can make path-wise training competitive.
- Schedule design: Provide principled methods to design or learn / schedules (forward exit rates and mixing rate) optimized for training stability, calibration, and sample quality; include ablations beyond the masked/uniform/semantic kernels.
- Semantic-informed kernel (SIK) design space: Systematically ablate and justify choices for embedding sources (static vs. learned vs. external), distance metrics (e.g., cosine vs. Euclidean), neighborhood size , time-dependent temperature , and mixing with uniform/absorb components.
- Forward-process nonstationarity: If the Gaussian SIK relies on token embeddings that are updated during training, the forward corruption process itself changes over time. Address whether embeddings are frozen, and analyze stability and convergence when the forward kernel evolves during training.
- KNN approximation bias: Quantify the approximation error introduced by KNN-based truncation of , whether the truncated kernel corresponds to any valid and , and its effect on the learned model and ELBO tightness.
- Stationary/limiting distribution of SIK: Prove that the chosen schedule ensures the desired limiting behavior (e.g., convergence to uniform) for the time-inhomogeneous , and analyze mixing properties and sensitivity to .
- Beyond independent token corruption: Explore forward processes that capture dependencies across tokens (syntax, grammar, copy/replace, or span-level operations), and develop uniformization-compatible algorithms for such structured noising.
- Scaling to larger models and contexts: Current results are on relatively small backbones and datasets. Validate whether gains persist (or improve) at LLM scale (billions of parameters), longer contexts, and larger corpora, including training cost and inference latency comparisons to AR.
- Extension to other discrete domains: Demonstrate GDDS on graphs, molecules, and other non-text discrete spaces, where constructing or accessing columns of (or defining local neighborhoods) may be far more challenging.
- Tightness diagnostics and improved bounds: Develop alternative bounds (e.g., multi-sample/importance-weighted snapshot ELBOs) and practical diagnostics to measure and tighten the likelihood bound during training.
- Generation quality and efficiency: Provide a thorough comparison of generation quality and speed versus AR models (e.g., throughput, latency, number of denoising steps), and analyze trade-offs in simultaneous versus iterative token updates for different noising choices.
- Robustness and rare tokens: Evaluate how semantic-informed kernels behave for rare or out-of-vocabulary tokens with few close neighbors, and propose robustification strategies (e.g., backoff to uniform, adaptive neighborhoods).
- Calibration measurement: Empirically quantify the claimed calibration improvements (e.g., ECE, Brier scores) and relate them to perplexity/NLL gains; assess how choice of forward kernel impacts calibration.
- Theoretical properties of reversibility: Analyze when the forward CTMC is reversible (or not), how non-reversibility impacts the reverse process estimation and sampling, and whether alternative parametrizations could exploit reversibility structures.
- Sensitivity to tokenization: Investigate the interaction between BPE tokenization and semantic kernels (e.g., subword units that break semantic neighborhoods), and whether alternative tokenizations yield better corruption and denoising.
- Fairness of comparisons: Ensure matched baselines in data, parameter counts (including embeddings), schedules, and optimizer settings; report sensitivity analyses to hyperparameters for AR vs. diffusion baselines to avoid confounding.
- Practical memory/computation budgets: Report memory footprints (e.g., storing neighbor graphs, time-dependent kernels), and the overhead of computing/sampling from non-homogeneous Poisson processes across long sequences and large vocabularies.
- Error bounds for Bayes-based reverse transitions: If generation relies on mapping the snapshot denoiser to reverse transitions (e.g., via Bayes’ rule), derive error bounds for the induced reverse dynamics and their effect on sample quality.
- Learned or adaptive kernels: Explore learning the forward kernel structure (under constraints to remain data-agnostic) or adapting it per token frequency/semantics to improve training efficiency and generalization without destabilizing the corruption process.
- Safety and control: Investigate whether semantic-informed noise introduces biases or undesirable behaviors, and whether controllable corruptions (e.g., topic/attribute-aware kernels) can enable safer or more controllable generation.
Practical Applications
Practical Applications of “Generalized Discrete Diffusion from Snapshots (GDDS)”
GDDS introduces a general and computationally efficient framework for discrete diffusion in large state spaces using: (i) arbitrary CTMC-based noising with uniformization for exact, fast corruption; (ii) a snapshot ELBO enabling scalable, standard architecture training; and (iii) semantically structured noising (e.g., Gaussian kernels over embeddings) that improves generalization and zero-shot transfer. Below are actionable applications, grouped by deployment horizon.
Immediate Applications
These can be prototyped and deployed with current tooling (e.g., PyTorch/Transformers) and the GDDS codebase.
- LLM pretraining and fine-tuning (Industry: software/AI; Academia)
- Use case: Replace or augment AR pretraining with GDDS snapshot training to improve training efficiency and zero-shot generalization on diverse corpora (e.g., OWT-scale).
- Tools/workflows:
- Integrate GDDS snapshot ELBO into a DDiT-style bidirectional Transformer training loop.
- Adopt uniformization-based noising (Algorithm 1/sequence-level variant) with column access to rate matrix.
- Plug in semantic-informed kernels (e.g., Gaussian KNN over token embeddings with k≈64).
- Assumptions/dependencies:
- Availability of token embeddings to build KNN/semantic kernels.
- Column access to rate matrix F_t or the ability to implement structured kernels (to avoid O(m2)).
- Snapshot training discards path information; performance relies on calibration improvements.
- Domain-robust NLP systems (Industry: enterprise NLP, customer support; Academia)
- Use case: Train models with semantically structured noising to enhance out-of-distribution (OOD) robustness across domains (e.g., legal, healthcare, finance) and improve zero-shot transfer.
- Tools/workflows:
- Build domain-specific kernels (e.g., cluster-aware, ontology-aware) that bias corruption to semantically proximal tokens.
- Evaluate with perplexity bounds and zero-shot metrics across target domain validation sets.
- Assumptions/dependencies:
- High-quality domain embeddings/lexicons or ontologies.
- Kernel hyperparameters (temperature schedule τ(t), KNN k) tuned for each domain.
- Faster parallel text generation pipelines (Industry: content platforms; Daily life: productivity)
- Use case: Deploy discrete diffusion generation to produce outputs in fewer sequential steps than AR decoding, especially for batch content creation (summaries, product descriptions, templated copy).
- Tools/workflows:
- Use GDDS-trained denoisers within standard diffusion sampling schemes (time schedules; parallel token updates).
- Couple with reranking/constraint decoding for quality control.
- Assumptions/dependencies:
- Production viability depends on reverse-time sampling speed and step count versus AR decoding; measure throughput/latency under target constraints.
- Data augmentation via structured discrete corruption (Industry: ML ops; Academia)
- Use case: Generate semantically plausible corruptions of labeled text to augment low-resource datasets (intent classification, NER, sentiment).
- Tools/workflows:
- Apply GDDS forward noising to create meaningful variants, then train task models on augmented corpora.
- Assumptions/dependencies:
- Corruption schedule must preserve label fidelity; requires validation or label-preserving rules for each task.
- Evaluation and calibration research (Academia)
- Use case: Study calibration–information trade-offs using the snapshot vs. path ELBO decomposition; quantify CG vs. IPG in practice.
- Tools/workflows:
- Implement both path-wise (Campbell estimator) and snapshot objectives for controlled ablations.
- Measure NLL gaps and calibration metrics across datasets.
- Assumptions/dependencies:
- Path models may require two-stream architectures; snapshot models are aligned with standard Transformers.
- Safer red-teaming and robustness testing (Industry: AI safety; Policy)
- Use case: Use structured noising to generate adversarial but semantically related inputs for stress testing LLMs (e.g., paraphrases near decision boundaries).
- Tools/workflows:
- Instantiate custom kernels to explore specific semantic neighborhoods (slang, dialects, sensitive terminology).
- Assumptions/dependencies:
- Clear safety policies for generated test data; curated evaluation suites.
- Educational and assistive tools (Daily life; Education)
- Use case: Improved autocomplete and tutoring feedback by leveraging bidirectional denoisers (better handling of mid-sequence edits).
- Tools/workflows:
- Fine-tune GDDS models on domain data (student essays, language learning corpora).
- Deploy on-device snapshot denoisers for low-latency editing assistance.
- Assumptions/dependencies:
- On-device inference depends on model size and optimized kernels; consider distillation/quantization.
Long-Term Applications
These require additional research, scaling, or engineering to meet production reliability, safety, and efficiency constraints.
- Full-stack diffusion LLMs replacing AR in production (Industry: software/AI)
- Use case: End-to-end discrete diffusion LLMs offering superior perplexity, generalization, and parallel decoding for broad tasks (chat, code, multimodal text).
- Tools/products:
- Production-grade GDDS library with hardware-optimized uniformization sampling and mixed-precision kernels.
- Cached token KNN graphs, dynamic scheduling of exit rates, and step-adaptive sampling policies.
- Assumptions/dependencies:
- Robustness under long-context settings; latency targets vs. AR; safety filters integrated with diffusion sampling.
- Code generation and software engineering assistants (Industry: software; Academia)
- Use case: Train code-specific kernels (syntax/AST-aware) to improve consistency, error rates, and refactoring tasks with parallel edits.
- Tools/workflows:
- CTMC kernels respecting grammar transitions or learned code neighborhoods (e.g., token, AST node, or CFG edge KNN).
- Snapshot training aligned with bidirectional context editing.
- Assumptions/dependencies:
- Reliable syntax- and semantics-aware kernels; evaluation on stringent unit-test suites; integration with IDEs.
- Healthcare and biomedical text generation/mining (Industry: healthcare; Policy)
- Use case: EHR summarization, clinical note normalization, literature triage using domain-aware kernels (UMLS/MeSH-driven).
- Tools/workflows:
- Ontology-informed noising to maintain clinical semantics during training; differential privacy add-ons where required.
- Assumptions/dependencies:
- Regulatory compliance (HIPAA/GDPR); high-stakes validation; domain expert oversight.
- Finance and law document modeling (Industry: finance/legal)
- Use case: Contract generation/editing and risk analysis with kernels tuned to legal/financial terminology taxonomies.
- Tools/workflows:
- Fine-tuned GDDS with sector-specific vocabularies; structured noising capturing clause-level semantics.
- Assumptions/dependencies:
- Auditability and traceability; compliance; domain-specific evaluation protocols.
- Molecular and materials discrete generation (Industry: pharma/materials; Academia)
- Use case: Generate molecules or polymers represented as discrete sequences/graphs using kernels encoding chemical similarity or reaction rules.
- Tools/workflows:
- Define F_t over tokens/fragments with chemistry-aware distances; use snapshot ELBO for scalable training.
- Assumptions/dependencies:
- Validity constraints (valency, synthesizability); oracle feedback loops (property predictors); mapping from graphs to tokenized sequences.
- Recommender systems and user sequence modeling (Industry: consumer tech)
- Use case: Model and generate discrete user action sequences with kernels reflecting item similarity (embedding- or knowledge graph–based).
- Tools/workflows:
- Uniformization-based corruption leveraging item neighborhood graphs; diffusion-based counterfactual sequence generation for evaluation.
- Assumptions/dependencies:
- Cold-start and drift handling; fairness constraints; privacy considerations.
- Robotics and planning over discrete state spaces (Industry: robotics; Energy)
- Use case: Plan or generate action sequences with CTMC kernels aligned to dynamics/constraints (e.g., grid switching schedules).
- Tools/workflows:
- Domain-informed F_t derived from transition models; denoising provides parallel updates to candidate plans.
- Assumptions/dependencies:
- Safety-critical verification; integration with continuous control layers; real-time constraints.
- Privacy-preserving and efficient training at scale (Policy; Industry)
- Use case: Combine snapshot training (reduced path storage) with privacy techniques (e.g., DP-SGD, synthetic data) to lower privacy risk and compute.
- Tools/workflows:
- Snapshot ELBO with privacy budgets; kernel designs that limit sensitive token exposure.
- Assumptions/dependencies:
- Formal privacy guarantees need to be proven for specific pipelines; measurable utility–privacy trade-offs.
- Standardization and evaluation policy (Policy; Academia/Industry consortia)
- Use case: Establish benchmarks and best practices for semantically structured noising, calibration metrics, and zero-shot transfer evaluation.
- Tools/workflows:
- Shared suites for OOD perplexity, calibration, and safety; documentation of kernel construction practices and assumptions.
- Assumptions/dependencies:
- Community consensus; reproducible pipelines; governance for sector-specific risks.
- Tooling ecosystem and MLOps support (Industry; Open-source)
- Use case: Mature libraries and services around GDDS (training, sampling, kernel builders, monitoring).
- Tools/products:
- KNN/KeOps-backed kernel builders; rate-matrix column stores; profiling/telemetry for diffusion steps; model hubs for GDDS checkpoints.
- Assumptions/dependencies:
- Sustained open-source/community support; hardware-aware optimizations; interoperability with existing Transformer stacks.
Cross-cutting Assumptions and Dependencies
- CTMC validity and invertibility: K_t must be invertible with appropriate conditions; rate matrix design must preserve non-negativity and mass conservation.
- Uniformization practicality: Shared exit rates simplify implementation; otherwise use Poisson thinning (more engineering overhead).
- Kernel quality: Performance hinges on the appropriateness of F_t (e.g., semantic distance, domain graphs); poor kernels can harm learning or bias outputs.
- Scalability: For large vocabularies, dense F is infeasible; rely on structured sparsity (KNN graphs) and GPU-efficient implementations.
- Architecture alignment: Snapshot ELBO aligns with bidirectional Transformers; path-wise objectives may require two-stream architectures and are less practical.
- Claims and benchmarks: Reported gains are under matched compute on Text8/OWT; replication in other domains requires careful retuning and evaluation.
- Safety/compliance: Sector deployments (healthcare, finance, law) require rigorous validation, governance, and compliance adherence.
Glossary
- Autoregressive (AR): A modeling paradigm that generates sequences by predicting each token conditioned on all previous tokens. "auto-regressive (AR) paradigm dominating language modeling"
- Bayes' rule: A fundamental rule in probability that relates conditional and marginal probabilities, used here to express reverse-time transitions in terms of posteriors. "via Bayes' rule as"
- BPE-tokenized (Byte Pair Encoding): A tokenization method that segments text into subword units by iteratively merging frequent symbol pairs. "BPE-tokenized models"
- Campbell estimator: An estimator derived by applying Campbell’s formula to sums over points of a Poisson process, used to rewrite a path-wise loss as a sum over jump events. "we introduce a path-wise Campbell estimator"
- Campbell's formula: A result that gives expectations of sums over points of a Poisson process, enabling conversion of integrals into sums. "It consists of applying Campbell's formula"
- categorical distribution: A discrete probability distribution over a finite set of categories (tokens). "the categorical distribution:"
- column-stochastic matrix: A matrix whose columns are probability distributions (each column sums to one and has nonnegative entries). "For a column-stochastic matrix"
- continuous-time Markov chain (CTMC): A stochastic process that transitions between discrete states in continuous time according to a rate matrix. "a continuous-time Markov chain (CTMC)"
- cross-entropy: A measure of discrepancy between two probability distributions, used as a training objective to match predicted and true transition kernels. "a weighted cross-entropy that matches the model reverse jump kernel"
- Evidence Lower Bound (ELBO): A variational objective that lower-bounds the log-likelihood, used to train generative models. "we derive a simple evidence lower bound (ELBO) based on snapshot latents"
- exit rates: In a CTMC, the rates at which the process leaves a given state. "are the (forward and reverse) exit rates"
- idempotent: A matrix property where applying the matrix twice equals applying it once (F2 = F), simplifying certain exponentials. "Since these matrices are idempotent"
- interpolating matrix: A convex combination of identity and a mixing matrix that specifies the corruption operator at time t. "its interpolating matrix as"
- jump kernels: In CTMCs, the conditional distributions over destination states upon leaving a state. "exit rates and jump kernels"
- jump-states parametrization: A parameterization of reverse CTMC dynamics that separately models when jumps occur (exit rates) and where they go (jump kernel). "the following jump-states parametrization:"
- Kolmogorov forward equation: A differential equation governing the time evolution of the state distribution under a CTMC. "the Kolmogorov forward equation:"
- Masked diffusion models (MDM): Discrete diffusion models that corrupt data by replacing tokens with a special mask token over time. "Masked diffusion models (MDM)"
- matrix exponential: The exponential of a matrix, here used to express solutions of linear ODEs for Markov transition operators. "matrix exponential "
- mean parametrization: Also called x0-parameterization; a denoiser predicts the posterior over clean tokens given a noised snapshot. "the mean parametrization (also known as -parametrization)"
- mixing matrix: A column-stochastic matrix that redistributes probability mass across tokens as noise increases. "mixing matrix "
- non-homogeneous Poisson process: A Poisson process with time-varying intensity, used to model jump times in uniformization. "be a non-homogeneous Poisson process"
- path-wise ELBO: An ELBO defined over entire corruption paths (sequences of jumps) rather than single snapshots. "Path-wise ELBO"
- Poisson thinning: A technique to simulate or decompose Poisson processes by selectively accepting events with certain probabilities. "through Poisson thinning"
- probability simplex: The set of all probability vectors over a finite set (nonnegative entries summing to one). "the probability simplex over ."
- rate matrix (infinitesimal generator): The matrix specifying instantaneous transition rates between states in a CTMC. "rate matrix (also called infinitesimal generator) "
- reverse-time model: The generative model that runs the diffusion process backward in time to denoise and reconstruct data. "into the reverse-time model"
- Semantic-Informed Kernel (SIK): A corruption kernel that uses semantic distances (e.g., in embedding space) to bias transitions toward semantically similar tokens. "Semantic-Informed Kernel (SIK)."
- snapshot ELBO: An ELBO based on single-time observations (snapshots) of the noised data rather than full paths. "Snapshot ELBO"
- snapshot latents: Latent variables comprising a noised token and its time, used for training via snapshot-based objectives. "based on snapshot latents"
- time-inhomogeneous: A system whose parameters (e.g., rate matrix) vary with time. "possibly time-inhomogeneous"
- time-ordering operator: An operator ensuring correct chronological ordering in exponentials of time-varying matrices. "time-ordering operator"
- time reversal: The transformation that expresses forward-time dynamics in reversed time, yielding reverse process equations. "The time reversal of this equation"
- uniformization: A technique to simulate CTMCs or compute matrix exponentials by embedding them in a Poisson process with randomized jumps. "based on uniformization."
- uniform-state diffusion models (USDMs): Discrete diffusion models that corrupt by replacing tokens with uniformly sampled tokens from the vocabulary. "uniform-state diffusion models (USDMs)"
Collections
Sign up for free to add this paper to one or more collections.