- The paper introduces a reinforcement learning framework that synthesizes multi-hop QA with tiered distractors from search trajectories.
- It employs an entity-level rubric reward that scores intermediate reasoning steps, mitigating reward hacking in long-context tasks.
- Empirical results show state-of-the-art improvements across benchmarks, demonstrating both practical and theoretical advances in RL for LLMs.
LongTraceRL: A Reinforcement Learning Framework for Long-Context Reasoning via Search Agent Trajectories and Rubric Rewards
Motivation and Problem Setting
The capacity for consistent long-context reasoning is critical for scaling LLMs in domains such as open-domain QA, retrieval-augmented reasoning, and agentic multi-turn interaction. However, LLMs routinely fail to locate and synthesize salient information when confronted with extensive distractors, especially under realistic settings where confusability is high. Prior RL approaches predominantly use synthetic distractors (random or embedding-based), and train on reward signals that only evaluate correctness of the final answer, bypassing supervision at intermediate reasoning stages. This results in models prone to reward hacking and brittle retrieval behavior.

Figure 1: Prior long-context RL methods inadequately supervise reasoning paths and fail to challenge models with realistic distractors compared to LongTraceRL, which combines agent-derived tiered distractors and entity-level process rewards.
LongTraceRL Framework
Data Construction Pipeline
LongTraceRL advances training data quality by generating complex multi-hop QA from curated knowledge graphs and constructing distractors from search agent trajectories. Multi-hop questions are synthesized via controlled random walks on the Wikipedia hyperlink graph, producing chains of up to 8 reasoning hops. Each QA sample includes: the question text, a unique target answer, and a list of gold entities at each reasoning step.
To assemble challenging context, an autonomous search agent attempts each question, recording its query, document open, and citation actions. Documents are partitioned into:
- Tier-1 (high confusability): Read but not cited documents, highly relevant and plausible as distractors.
- Tier-2 (low confusability): Search results never opened, lower relevance.
The context for each sample is assembled via a traj-tiered protocol: gold passages are prioritized, followed by Tier-1, and then Tier-2 distractors, shuffled to avoid positional bias.
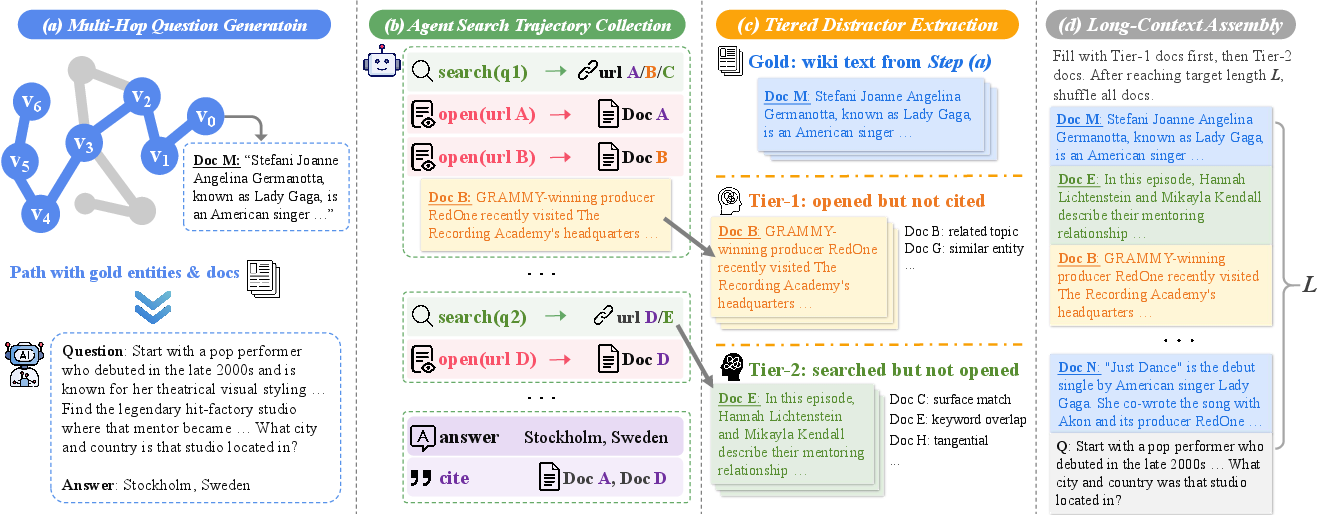
Figure 2: End-to-end pipeline for LongTraceRL data construction: multi-hop path generation, search agent trajectory extraction, tiered distractor assembly.
Reward Design and RL Objective
LongTraceRL proposes a rubric reward for fine-grained process-level supervision. Instead of binary outcome reward, responses are scored according to recall of gold entities along the reasoning chain. This entity-level rubric reward is granted only if the final answer is correct (positive-only strategy), effectively penalizing shortcutting and preventing reward gaming via irrelevant entity enumeration.
The RL step employs GRPO, normalizing rubric scores across rollout groups and combining them with outcome reward using a hyperparameter α for trade-off modulation.
Empirical Evaluation
Experiments are conducted on three reasoning LLMs (Qwen3-4B-Thinking, DeepSeek-R1-0528-Qwen3-8B, Qwen3-30B-A3B-Thinking) and five long-context benchmarks encompassing diverse reasoning tasks (AA-LCR, MRCR, FRAMES, LongBench v2, LongReason). Compared to several baselines (DocQA, LoongRL, LongRLVR), LongTraceRL delivers:
- Consistent SOTA results across scales: Qwen3-4B-Thinking achieves +5.7 average points over base, surpasses LongRLVR by +2.5 (59.0 vs. 56.5).
- Especially strong gains on AA-LCR: +8.6 absolute improvement.
- Rubric reward is the dominant driver: ablating it nearly erases performance gains.
- Performance is robust across distractor strategies, with traj-tiered outperforming random and naive search distractors by >3 points.
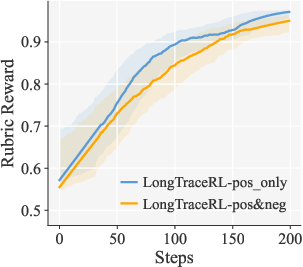
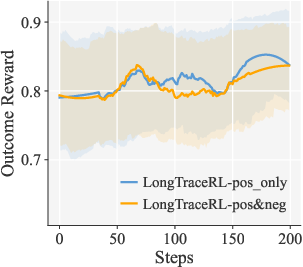
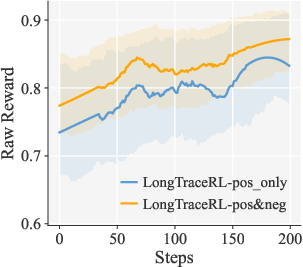
Figure 3: Rubric, outcome, and combined reward dynamics for different reward strategies. Positive-only rubric reward yields superior learning signal without reward hacking.
Ablations and Analysis
- Rubric Weight α: Optimal at α=0.3. Excessive rubric emphasis (α=0.5) results in entity-mention shortcuts with degraded reasoning quality.
- Distractor Source: Tiered, trajectory-based distractors achieve maximal overlap with gold entities (~50% macro average), far exceeding random and search-based distractors (~1--15%), and directly correlate with downstream accuracy.
- Reward Strategy: Positive-only rubric rewards prevent reward leakage to incorrect responses, avoiding gradient dilution and entity enumeration bias found in content-negative rewards.
Practical and Theoretical Implications
Practically, LongTraceRL provides a robust recipe for scalable long-context RL: multi-hop QA synthesis leveraging knowledge graphs, guided trajectory-based distractor assembly, and entity-level rubric rewards for process supervision. This addresses both the challenge of reward sparsity and confusability in training data, enabling LLMs to generalize to real-world long-context scenarios with high distractor density.
Theoretically, LongTraceRL demonstrates that verifiable process rewards grounded in reasoning chain entities produce non-trivial improvements, and that positive-only reward allocation is essential to preserve signal integrity in RL for multi-hop reasoning. The approach is likely extensible to agentic RL settings and tool-augmented LLMs, with implications for scaling and alignment in retrieval-augmented contexts.
Future Directions
Key avenues for exploration include diversification of knowledge sources beyond Wikipedia (introducing financial/legal/code graphs), analysis of agent capability on distractor quality, and extension to multi-agent collaboration or competition in structured long-context environments. Further, integration of rubric rewards in end-to-end agentic RL pipelines may enable more interpretable and verifiable reasoning in autonomous LLM systems.
Conclusion
LongTraceRL establishes a principled RL framework for long-context reasoning, synthesizing challenging QA and distractor paradigms from real agent trajectories, and enforcing sound reasoning via entity-level rubric rewards. Empirical gains are validated across benchmarks and architectures, demonstrating robustness and efficacy in promoting comprehensive, evidence-grounded reasoning in LLMs (2605.31584).