LoongRL:Reinforcement Learning for Advanced Reasoning over Long Contexts
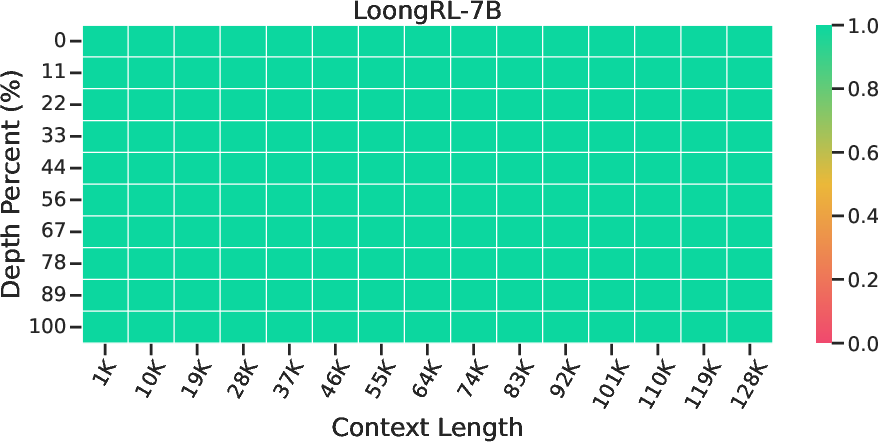
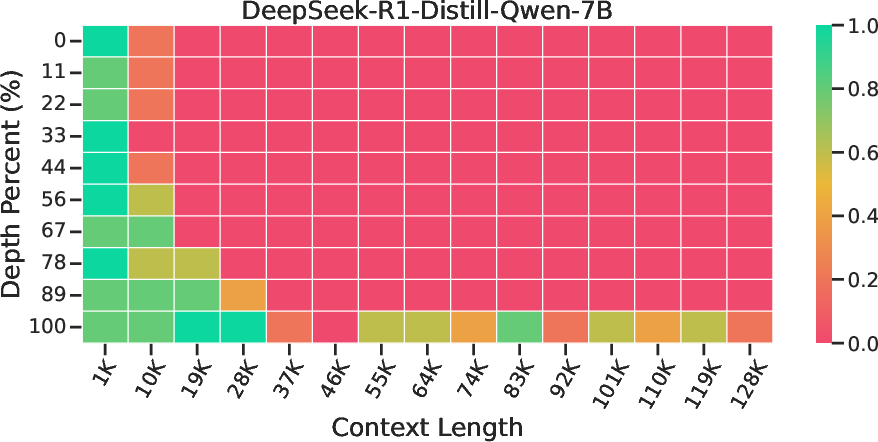
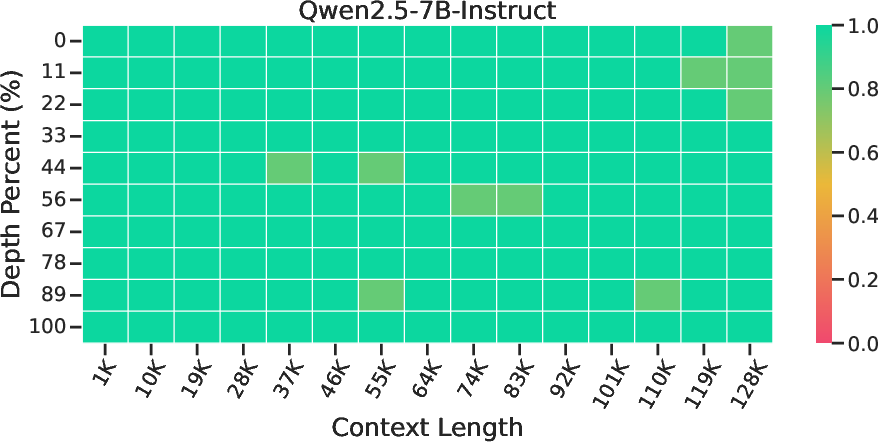
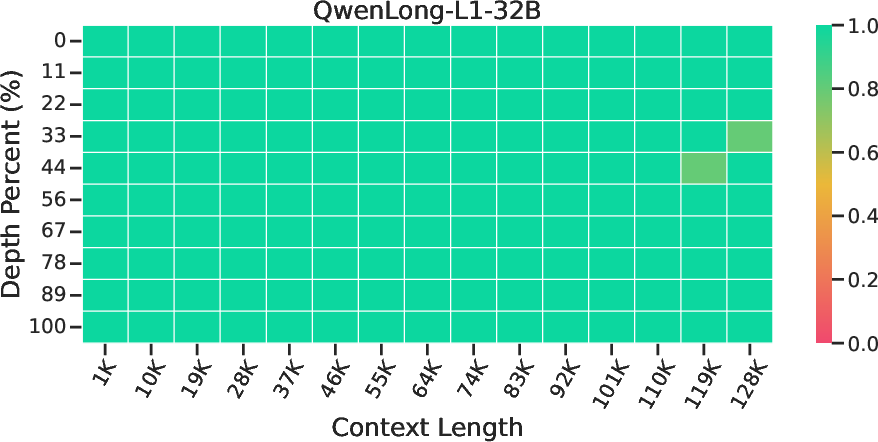
Abstract: Reasoning over long contexts is essential for LLMs. While reinforcement learning (RL) enhances short-context reasoning by inducing "Aha" moments in chain-of-thought, the advanced thinking patterns required for long-context reasoning remain largely unexplored, and high-difficulty RL data are scarce. In this paper, we introduce LoongRL, a data-driven RL method for advanced long-context reasoning. Central to LoongRL is KeyChain, a synthesis approach that transforms short multi-hop QA into high-difficulty long-context tasks by inserting UUID chains that hide the true question among large collections of distracting documents. Solving these tasks requires the model to trace the correct chain step-by-step, identify the true question, retrieve relevant facts and reason over them to answer correctly. RL training on KeyChain data induces an emergent plan-retrieve-reason-recheck reasoning pattern that generalizes far beyond training length. Models trained at 16K effectively solve 128K tasks without prohibitive full-length RL rollout costs. On Qwen2.5-7B and 14B, LoongRL substantially improves long-context multi-hop QA accuracy by +23.5% and +21.1% absolute gains. The resulting LoongRL-14B reaches a score of 74.2, rivaling much larger frontier models such as o3-mini (74.5) and DeepSeek-R1 (74.9). It also improves long-context retrieval, passes all 128K needle-in-a-haystack stress tests, and preserves short-context reasoning capabilities.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces LoongRL, a way to train AI LLMs to think better when reading and solving problems that involve very long texts. The authors focus on teaching models not just to find information in huge documents, but to plan, retrieve facts, reason carefully, and double-check their answers—especially for tricky, multi-step questions that can’t be solved by simple searching.
Goals and Questions
The researchers wanted to solve three main problems:
- How can we teach models to reason over very long inputs (like 16,000 to 128,000 tokens) instead of just “finding” things?
- How can we create challenging, trustworthy training data that forces real reasoning and can be graded automatically?
- Can we train at shorter lengths (like 16K tokens) but still get strong performance on much longer contexts (up to 128K), without spending huge amounts of computing power?
How They Did It
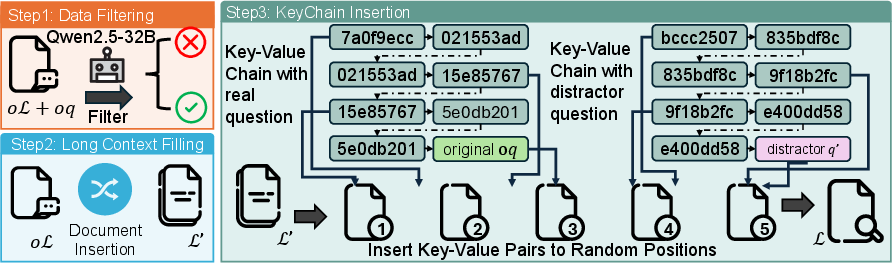
A clever data setup: KeyChain
Imagine you’re in a giant library full of books—some are helpful, most are distracting. The real question you need to answer is hidden like a secret puzzle inside the library. The paper creates this kind of puzzle using something called KeyChain:
- They start with normal multi-step question-answer pairs from real datasets (like HotpotQA, MuSiQue, and 2WikiMultiHopQA).
- They extend the text to be very long by adding many extra, unrelated documents. This makes it hard to find the right facts.
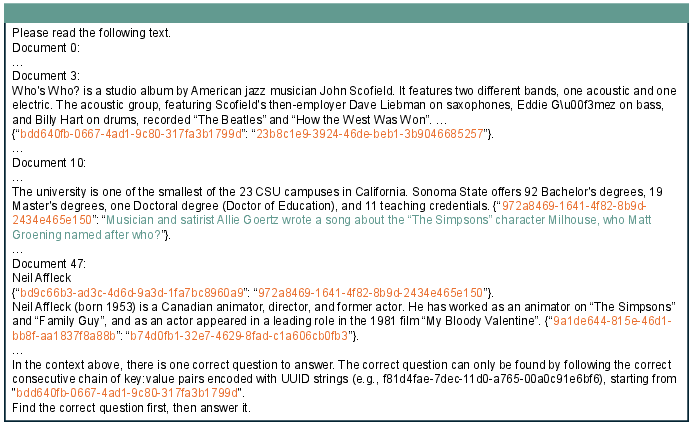
- Then they hide the real question behind a chain of “keys” and “values” that look like long random ID codes (UUIDs). Following the correct chain leads you to the true question; following other chains leads to fake, distracting questions.
This makes the task much harder: the model has to first trace the correct chain in order, then find the information it needs in the long text, and finally reason step-by-step to answer.
How the training works: Reinforcement learning (RL)
Reinforcement learning is like teaching by trial and reward:
- The model tries to solve a problem multiple times.
- If it gives a correct final answer, it gets a reward; if not, no reward.
- Over time, it learns strategies that earn more rewards.
They use a method called GRPO (Group Relative Policy Optimization). In simple terms, the model makes a group of attempts and the training focuses on improving the better ones relative to the group.
To grade answers reliably (without using another judging AI), they use a rule-based check:
- The model must put its final answer inside a special box like this: \boxed{...}
- They then check if the final answer contains the correct answer as a substring, or vice versa. This “two-way substring exact match” allows small formatting differences while still being strict enough to avoid cheating.
Training recipe and curriculum
They mix different kinds of tasks so the model learns broadly:
- Hard KeyChain tasks for deep long-context reasoning.
- Medium-difficulty multi-hop questions to build confidence and stability.
- Long-context “needle-in-a-haystack” retrieval tasks, so the model stays good at finding facts in big texts.
- Short math problems to keep general reasoning skills sharp.
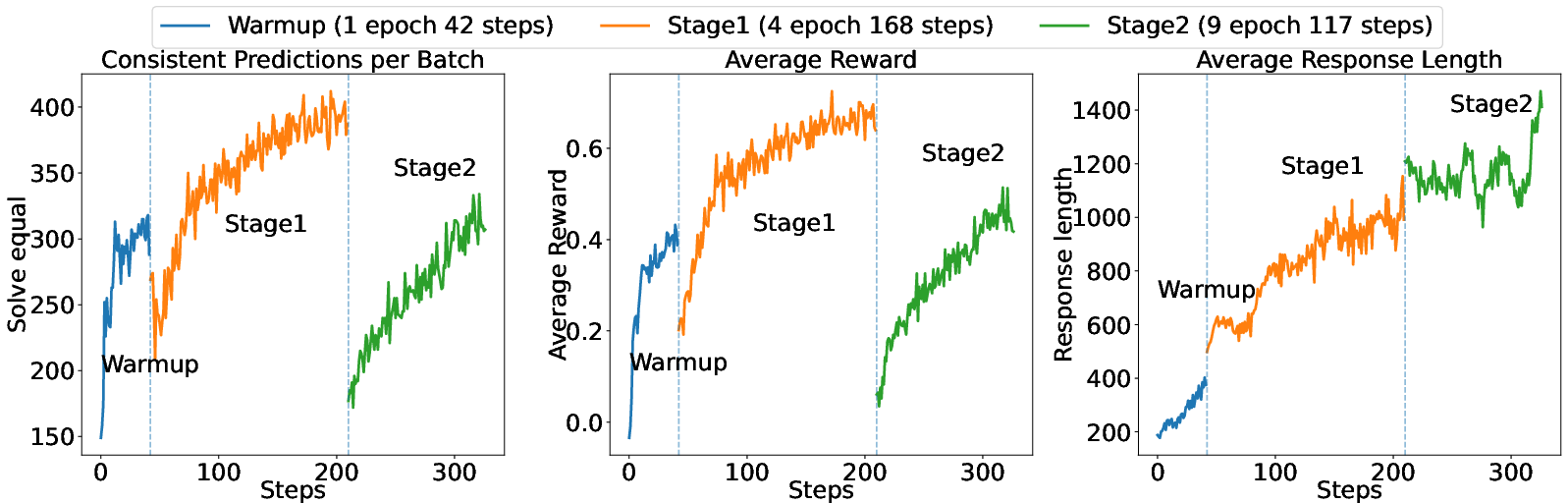
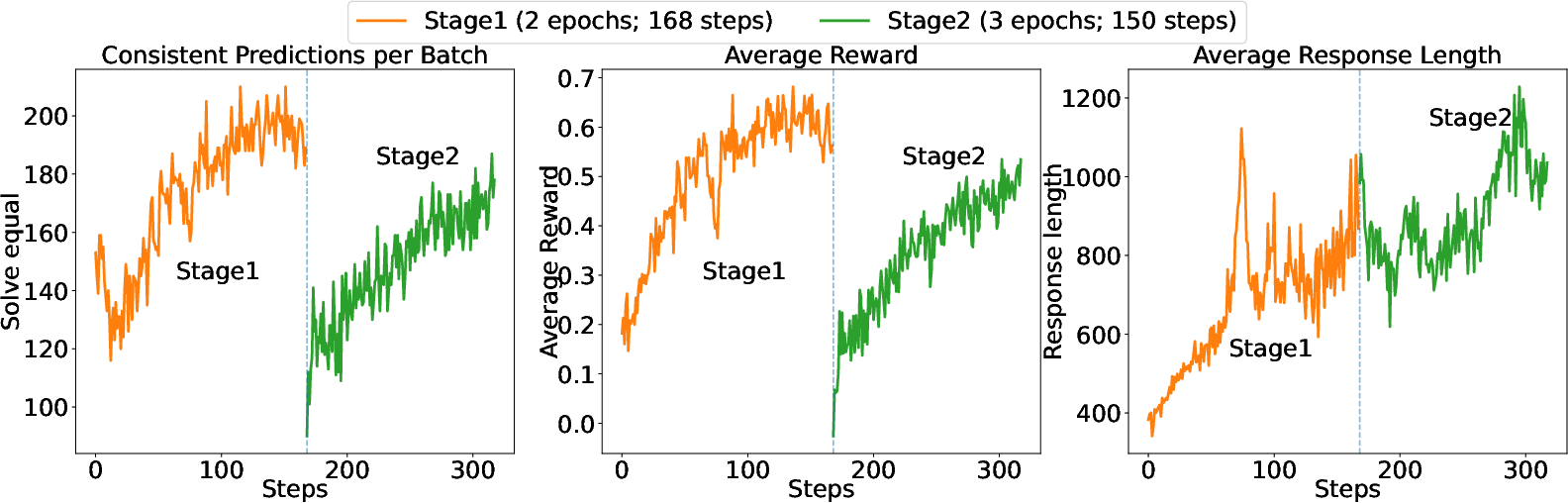
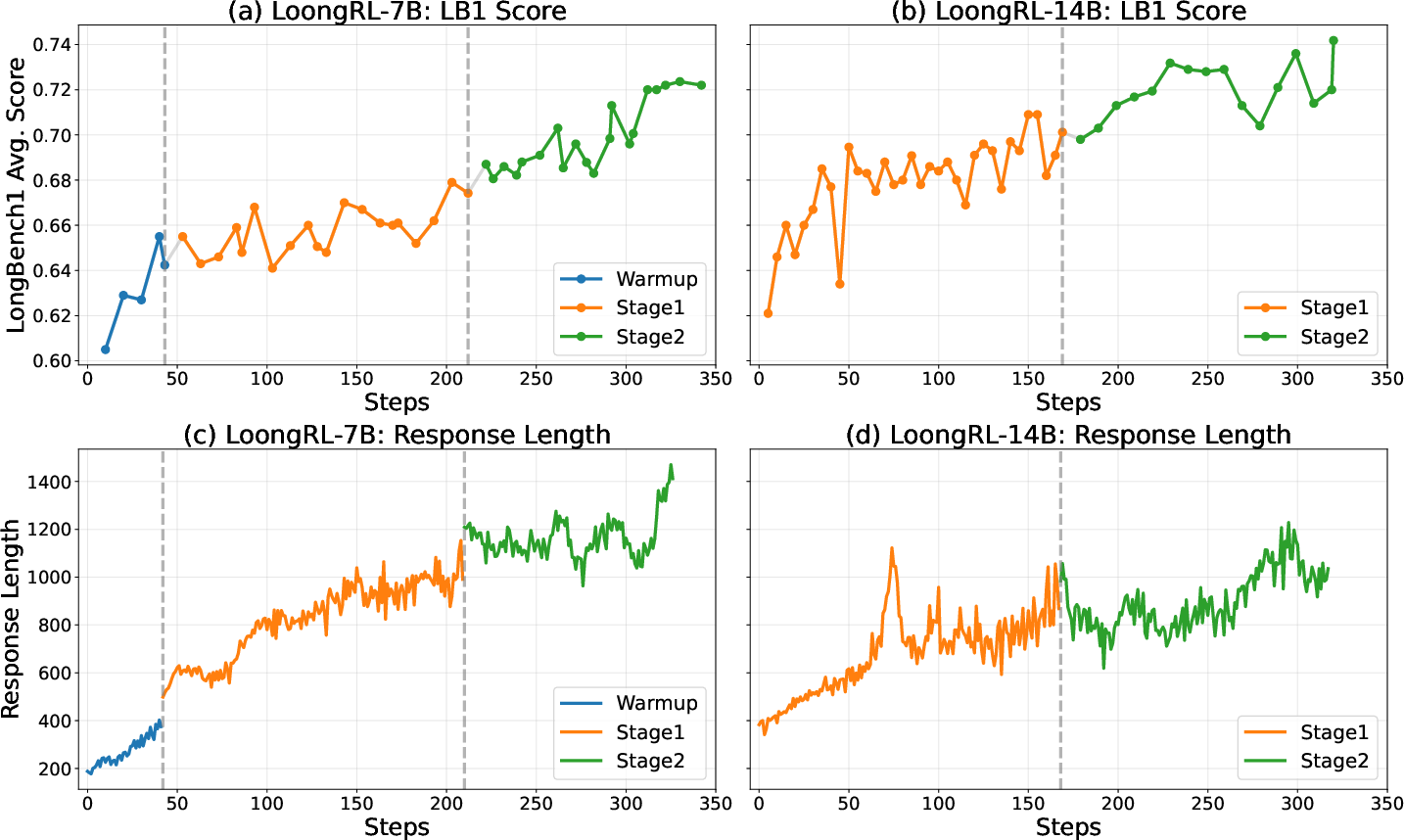
They train in stages:
- Warm-up on easier data (for smaller models) so training doesn’t crash.
- Introduce KeyChain data to push the model toward structured thinking.
- Focus on the hardest remaining problems, so the model keeps improving where it matters most.
Main Findings
The authors report several important results:
- The model learned a clear thinking pattern they describe as “plan → retrieve → reason → recheck.” In everyday terms: make a plan, find the right text, think through it, and double-check before answering.
- This pattern generalizes surprisingly well: models trained with 16K tokens could effectively handle tasks up to 128K tokens, avoiding the huge cost of training directly at full length.
- Big accuracy gains on long-context multi-hop QA:
- On a 7B model: about +23.5 percentage points.
- On a 14B model: about +21.1 percentage points.
- The 14B model reached a score of 74.2 on a long-context benchmark, close to much larger, top-tier models like o3-mini (74.5) and DeepSeek-R1 (74.9).
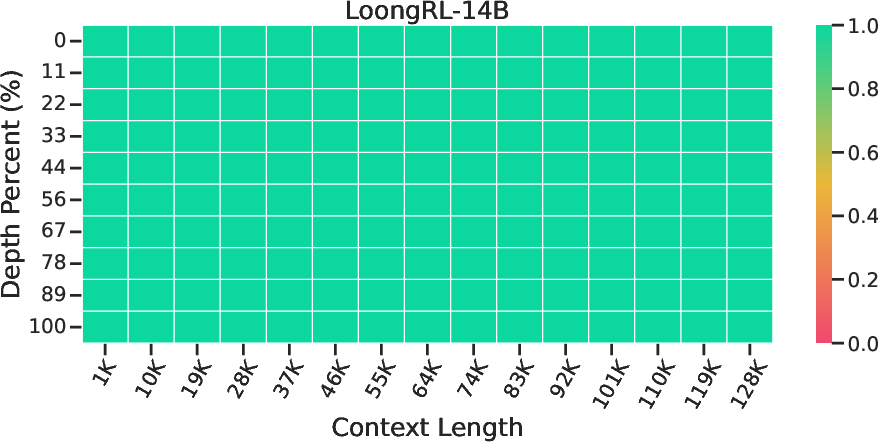
- Strong long-context retrieval:
- Passed all “needle-in-a-haystack” stress tests, meaning it could find tiny pieces of information hidden deep in huge documents.
- It kept its short-context reasoning skills:
- Performance on general tasks like MMLU and math stayed stable or even improved slightly.
Why This Matters
Many real-life tasks involve very long documents—think legal contracts, research papers, or big codebases. It’s not enough for an AI to just search; it has to:
- Plan what to look for,
- Follow clues in order,
- Pull together facts from different places,
- And check its work before answering.
LoongRL shows that with smart training data (KeyChain) and efficient reinforcement learning, smaller models can develop these advanced skills and compete with much larger ones. It also shows we can train at shorter lengths and still get strong performance on much longer inputs, which saves time and computing resources.
This approach could make AI more reliable and useful for tasks that need careful reading and reasoning across long documents—helping students, researchers, lawyers, engineers, and many others.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of unresolved issues and concrete research directions the paper leaves open.
- Realism of KeyChain tasks: Assess whether UUID-based chain-tracing reflects real long-context workloads (e.g., legal cross-references, multi-document scientific synthesis) where the “true question” is not explicitly anchored or serially encoded.
- Reliance on explicit markers: Quantify how much performance gains depend on the presence of distinctive UUID tokens. Create KeyChain variants without explicit markers (implicit pointers, natural cross-references) and test transfer.
- Chain topology and robustness: Explore non-linear chains (branching, loops), variable hop depths, missing/corrupted links, and multi-origin/multi-destination chains to evaluate robustness of the learned reasoning pattern.
- Distractor difficulty: Replace random distractors with semantically similar, adversarial, contradictory, or near-duplicate passages to stress reasoning over subtle distinctions rather than lexical noise.
- Answer verifier reliability: Measure false positives/negatives of two-way substring exact match (e.g., “12” vs “112”, “USA” vs “United States”, unit/format variants). Develop rule-based normalizers (tokenization, stemming, unit conversion, alias dictionaries) or semantic verifiers that retain verifiability while reducing reward hacking.
- Reward hacking analysis: Systematically audit whether outcome-only, binary rewards coupled with boxed-answer formatting incentivize superficial extraction or formatting tricks instead of genuine plan–retrieve–reason behavior.
- Process-level rewards: Compare outcome-only rewards to process supervision (intermediate rewards for correctly following chains, citing evidence spans, consistency checks) to improve stability and steer the emergent pattern more explicitly.
- Quantifying the emergent pattern: Move beyond qualitative evidence by operationalizing “plan–retrieve–reason–recheck” (e.g., tagging steps, measuring plan frequency/structure, recheck rates, citation usage) and correlate these with success across tasks.
- Inference efficiency trade-offs: Characterize accuracy vs response-length curves, latency, and token cost. Investigate length-aware decoding, budget-constrained planning, or compressive planning to retain gains without 10K-token outputs.
- Generalization limits beyond 128K: Test at 256K, 512K, and 1M+ tokens (e.g., with LongRoPE2), identify failure modes and scaling breakpoints, and study whether short-length RL continues to transfer at extreme context scales.
- Domain and multilingual coverage: Evaluate on real, domain-specific long contexts (legal filings, scientific corpora, codebases, logs) and non-English tasks; adapt KeyChain to multilingual settings and measure cross-lingual generalization.
- Integration with tools/RAG: Study how LoongRL interacts with external retrieval tools (search indices, code execution, citation graphs). Compare “long-context only” vs “RAG+long-context” setups for complex multi-hop tasks.
- Data contamination checks: Perform rigorous contamination analysis to ensure training/evaluation datasets (HotpotQA, MuSiQue, 2WikiMultiHopQA, PG19) were not memorized by base models; construct held-out or fresh splits to validate gains.
- Safety, calibration, and grounding: Evaluate whether LoongRL affects truthfulness, calibration, and hallucination rates. Add evidence-citation requirements and verifiers that check grounding (span references) to reduce unsupported claims.
- Compute/reporting transparency: Provide full training compute budgets (GPU-hours, tokens processed per rollout, memory footprints), enabling reproducible cost–performance comparisons and scaling-law analysis for LoongRL.
- Hyperparameter sensitivity and RL baselines: Probe sensitivity to KL weight, group size, temperature/top-p, and curriculum schedule; compare GRPO to PPO, REINFORCE, DPO/SPPO, and entropy-regularized variants to quantify algorithmic choices.
- Data-mix design: Systematically vary mixture ratios and sizes (KeyChain vs standard QA vs retrieval vs math/code) and study their interference/synergies on long-context reasoning, retrieval, and short-context capabilities.
- Direct long-length RL vs short-length transfer: Quantify the incremental benefits and costs of training directly at longer contexts (e.g., 60K/128K) versus transferring from 16K; explore truncated rollouts, segment-level RL, or memory-augmented RL to reduce costs.
- Formatting dependence: Measure performance when boxed-answer formatting and explicit instructions are removed at inference; assess robustness to different prompting styles and output constraints.
- Expanded evaluation metrics: Clarify evaluation protocols (pass@1 vs official task metrics) and add pass@k, F1/EM, and citation correctness metrics; release per-task error analyses to guide targeted improvements.
- Failure-mode taxonomy: Decompose post-training errors into chain-tracing vs reasoning vs retrieval vs formatting categories; develop targeted interventions (e.g., chain-following hints, retrieval calibration, reasoning verification).
- Larger-scale models/context windows: Test LoongRL on larger backbones (32B, 70B+) and with million-token context windows; examine whether gains persist or amplify with model size and longer contexts.
- Multi-modal long-context reasoning: Extend LoongRL to documents with tables, code blocks, charts, images, and structured graphs; redesign KeyChain for multi-modal cross-references and verify pattern transfer.
- Attention/representation analysis: Instrument attention heads and retrieval patterns to confirm improved focus on relevant spans over long contexts; contrast pre/post RL attention distributions and citation alignment.
- Robustness to noisy inputs: Stress-test with typos, OCR noise, truncated passages, corrupted UUIDs, or shuffled sections to determine resilience and required pre-processing or noise-aware training.
Glossary
- Advantage: In policy-gradient RL, a signal estimating how much better an action is compared to a baseline at a time step. "The estimated advantage is computed from a group of rewards"
- Chain-of-Thought (CoT): A prompting/training technique where the model generates explicit step-by-step reasoning before answering. "chain of thoughts (CoT)"
- Cosine decay: A learning-rate schedule that decreases the rate following a cosine curve over training steps. "with cosine decay"
- DeepSeek-R1: A frontier reasoning LLM trained via reinforcement learning, used as a strong baseline in this work. "DeepSeek-R1 (74.9)"
- Entropy loss term: An auxiliary term used in RL or sequence modeling to increase output entropy and encourage exploration. "entropy loss term"
- Exact match: A strict evaluation or verification criterion requiring the predicted answer string to match the gold answer exactly. "Compared to strict exact match"
- Gradient clipping: A stabilization technique that limits the norm or value of gradients to prevent exploding updates. "gradient clipping at $1.0$"
- Group Relative Policy Optimization (GRPO): A policy-optimization algorithm that compares rewards within a sampled group of rollouts to compute normalized advantages and update the policy. "Group Relative Policy Optimization (GRPO)"
- IFEval: An instruction-following evaluation benchmark that measures adherence to prompts and constraints. "the instruction-following benchmark IFEval"
- Importance sampling ratio: The likelihood ratio between the current and old policies used for off-policy correction in policy-gradient updates. "clipping range of importance sampling ratio"
- KL penalty: A regularization term that penalizes divergence between the current policy and a reference policy to prevent excessive drift. "A small KL penalty "
- LLM-as-a-judge: An evaluation or reward-setting paradigm where a separate LLM grades the quality/correctness of outputs. "LLM-as-a-judge"
- LongBench v1: A benchmark suite for evaluating long-context reasoning across multiple tasks and lengths. "LongBench v1"
- LongBench v2: An updated long-context reasoning benchmark that supports even longer inputs (up to 128K). "LongBench v2"
- Needle in a Haystack: A stress test measuring a model’s ability to retrieve a small “needle” fact from a very long text. "Needle in a Haystack"
- pass@1: The probability that the first sampled solution is correct; commonly used when multiple samples could be drawn. "pass@1 accuracy"
- Plan–retrieve–reason–recheck: An emergent structured thinking loop where the model plans, retrieves evidence, reasons over it, and re-checks before finalizing. "planâretrieveâreasonârecheck"
- R1-distilled models: Models trained via distillation from R1-style reasoning traces to enhance step-by-step reasoning. "R1-distilled models"
- RULER: A long-context retrieval benchmark assessing performance across increasing input lengths and retrieval difficulty. "RULER"
- Temperature: A sampling parameter that controls output randomness; higher values yield more diverse generations. "temperature $0.6$"
- Top-p: Nucleus sampling that restricts token choices to the smallest set whose cumulative probability exceeds p. "top-"
- Two-way substring exact match: A lenient verifier that accepts answers if either the prediction contains the gold answer or vice versa. "two-way substring exact match"
- UUID: A Universally Unique Identifier; here, 32-character hexadecimal keys used to encode chains and hide questions. "UUID strings"
- UUID chains: Sequences of key–value pairs using UUIDs, forming a path the model must trace to uncover the true question. "inserting UUID chains"
- Verifiable rewards: Rule-based, programmatically checkable reward signals that reduce ambiguity and reward hacking in RL. "verifiable rewards"
- Warm-up: An initial training stage on easier data to stabilize optimization before introducing harder tasks. "Warm-up."
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s findings, methods, and innovations (KeyChain data synthesis, GRPO-based RL with rule-based rewards, and the emergent plan–retrieve–reason–recheck pattern), mapped to sectors and accompanied by potential tools/workflows and key dependencies.
- Enterprise document intelligence (legal, compliance, procurement)
- Sector: Software, LegalTech, Finance, Policy
- What: Long-contract and policy brief analysis that traces references across thousands of tokens, retrieves relevant clauses, reasons over conflicting provisions, and rechecks conclusions.
- Tools/workflows: “Audit-Ready Reasoning Assistant” built on LoongRL-14B; a workflow that auto-generates an explicit plan, retrieves evidence snippets, reasons over them, and outputs a boxed final answer plus an audit trail.
- Assumptions/dependencies: Access to a 128K-context LLM or equivalent; clean document ingestion; legal teams validate outputs; domain prompts/templates tuned to local policy/legal corpora.
- Advanced enterprise search and RAG with reliability guarantees
- Sector: Software, Knowledge Management
- What: Replace “jump-to-answer” retrieval with plan–retrieve–reason–recheck loops for intranet and data lake QA, greatly improving accuracy on long repositories.
- Tools/workflows: A “LongDoc QA Service” that integrates LoongRL models with RAG; structured retrieval steps and rechecking to pass needle-in-a-haystack tests.
- Assumptions/dependencies: High-quality chunking/indexing; latency budgets that tolerate structured multi-step retrieval; confidentiality controls.
- Codebase understanding and debugging across large repositories
- Sector: Software, DevTools
- What: Analyze multi-file dependencies, trace long code paths, retrieve relevant modules, reason about bugs, and recheck with evidence.
- Tools/workflows: “Codebase Navigator” assistant using plan–retrieve–reason–recheck; integrates with IDEs/CI; produces evidence-linked suggestions.
- Assumptions/dependencies: Good repository indexing and symbol resolution; prompt patterns for code reasoning; guardrails for hallucinations.
- Finance and research analysis (10-K/10-Q, earnings calls, market reports)
- Sector: Finance
- What: Multi-hop reasoning across long filings to answer specific questions (e.g., cross-referencing risk factors and financial notes).
- Tools/workflows: “Analyst Copilot” that traces internal references, retrieves facts, reasons, and rechecks; boxed outputs to support verification pipelines.
- Assumptions/dependencies: Up-to-date filings; domain-specific templates; human-in-the-loop review for material decisions.
- Healthcare evidence synthesis and guideline compliance checks
- Sector: Healthcare
- What: Read long clinical guidelines and EHR summaries, retrieve patient-relevant facts, reason about compliance and care pathways, and recheck recommendations.
- Tools/workflows: “Clinical Guideline QA” workflow with explicit evidence citations; outputs are structured and auditable.
- Assumptions/dependencies: De-identified data access and HIPAA compliance; tuned medical prompts; clinician validation.
- Academic literature review and multi-hop citation tracing
- Sector: Academia
- What: Systematically trace multi-hop citations across papers, retrieve key findings, reason about methodological consistency, and recheck claims.
- Tools/workflows: “Research Copilot” for literature matrices; automatic plan generation, targeted retrieval, and verified summarization.
- Assumptions/dependencies: Access to full texts; correct metadata/citation linking; domain-specific verifiers for non-exact answers.
- Government and policy analysis (legislation, FOIA, regulatory guidance)
- Sector: Public Policy
- What: Analyze long bills/regulations, trace definitions across sections, retrieve relevant precedent, reason about compliance impacts, and recheck.
- Tools/workflows: “Regulatory Bill Analyzer” with audit trails; supports submission-ready summaries.
- Assumptions/dependencies: Up-to-date statute repositories; stakeholder review; transparent logging for accountability.
- Customer support and operations log mining
- Sector: Software, Operations
- What: Retrieve signals from long logs/tickets, reason about root causes, and recheck prior evidence before finalizing action recommendations.
- Tools/workflows: “Ops Reasoner” integrated with ticketing systems; stepwise retrieval and boxed conclusion.
- Assumptions/dependencies: Log normalization and access; latency constraints; alignment with escalation processes.
- Verifiable QA evaluation pipelines
- Sector: ML Engineering, Quality Assurance
- What: Adopt two-way substring exact match to score free-form QA reliably without an LLM-as-a-judge; mitigate reward hacking in production QA evaluation.
- Tools/workflows: Plug-in verifier for internal benchmarks and reinforcement training; boxed-answer templates.
- Assumptions/dependencies: Ground-truth answers available as substrings; edge cases handled for formatting/units.
- Efficient long-context RL training on internal corpora
- Sector: ML Engineering
- What: Use KeyChain synthesis to convert local multi-hop QA into high-difficulty long-context RL tasks; train at ~16K tokens to generalize to 128K.
- Tools/workflows: “KeyChain Builder” and GRPO training recipes; balanced data mixing to preserve short-context skills.
- Assumptions/dependencies: Seed multi-hop QA with verifiable answers; compute for GRPO; careful data curation to avoid leakage.
Long-Term Applications
These applications are feasible with further research, scaling, domain adaptation, and/or tooling maturity.
- Autonomous long-context reasoning agents for enterprise knowledge
- Sector: Software, Knowledge Management
- What: Agents that continuously ingest and reason over large, evolving corpora (policies, code, reports), creating durable plan–retrieve–reason–recheck audit trails.
- Tools/workflows: Persistent “Knowledge Steward” systems; continuous RL fine-tuning with KeyChain-like tasks from new data.
- Assumptions/dependencies: Persistent data ingestion pipelines; robust monitoring; organizational acceptance of agent outputs and audit trails.
- Certification-grade auditability for AI reasoning in regulated domains
- Sector: Policy, Healthcare, Finance, Legal
- What: Standardize plan–retrieve–reason–recheck traces as compliance artifacts; align with governance frameworks for explainability and risk.
- Tools/workflows: “AI Reasoning Audit SDK” and policy templates; certifiable trace outputs.
- Assumptions/dependencies: Regulator-approved formats; third-party audits; formal guarantees for retrieval provenance.
- Domain-specific KeyChain variants (e.g., RefChain using citations instead of UUIDs)
- Sector: Academia, LegalTech, Finance
- What: Replace synthetic UUID chains with natural domain linking (citations, clause references), increasing realism and transfer to production corpora.
- Tools/workflows: “RefChain Synthesizer” for literature/legal datasets; domain verifiers beyond substring match (e.g., semantic entailment).
- Assumptions/dependencies: Robust entity/link extraction; verifiable ground-truth answers in rich domains; scalable synthesis.
- Cross-modal long-context reasoning (text + code + tables + audio transcripts)
- Sector: Education, Media, Software
- What: Unified reasoning over long multimodal inputs (lecture transcripts + textbook + code examples), with structured retrieval and rechecking.
- Tools/workflows: Multimodal RAG+LoongRL; cross-modal verifiers; curriculum RL spanning modalities.
- Assumptions/dependencies: Multimodal encoders with large context; task-specific verifiers; data alignment across modalities.
- Million-token scale reasoning via short-length RL generalization
- Sector: ML Systems
- What: Combine LoongRL’s length generalization with context-scaling techniques (e.g., LongRoPE/LongRoPE2) to enable million-token reasoning without full-length RL rollouts.
- Tools/workflows: “Length-Generalized RL” pipelines; synthetic tasks designed to generalize patterns to ultra-long contexts.
- Assumptions/dependencies: Robust positional encodings; memory-efficient inference; stability across extreme lengths.
- Enterprise “verifiable RL” programs for internal LLMs
- Sector: ML Engineering, Governance
- What: Institutionalize reinforcement learning with verifiable rewards across departments (support, legal, finance), using KeyChain-style data.
- Tools/workflows: Centralized RL ops; standardized reward verifiers; shared training assets.
- Assumptions/dependencies: Organization-wide data access agreements; compute budgets; cross-team MLOps maturity.
- Education: textbook-scale adaptive tutors with explicit evidence chains
- Sector: Education
- What: Tutors that read entire textbooks and curricula, trace evidence across chapters, reason and recheck before answering student queries.
- Tools/workflows: “Evidence-Linked Tutor” with plan–retrieve–reason–recheck outputs; classroom dashboards.
- Assumptions/dependencies: Licensed content; pedagogy-aligned prompts; evaluation rubrics for open-ended answers.
- Safety-critical decision support with retrieval provenance
- Sector: Healthcare, Aviation, Energy
- What: Systems that surface evidence chains for recommendations, enabling human operators to inspect provenance and model reasoning.
- Tools/workflows: Provenance UI; strict verifiers and escalation protocols; post-hoc audits.
- Assumptions/dependencies: High-stakes validation; fail-safe designs; domain regulation and certification.
- Knowledge graph construction and maintenance from long corpora
- Sector: Data Platforms
- What: Agents that iteratively retrieve facts, reason about relationships, recheck, and update graphs; track confidence and provenance.
- Tools/workflows: “Reasoned KG Builder” that logs the plan/retrieval/evidence for each node/edge.
- Assumptions/dependencies: Accurate entity resolution at scale; conflict resolution policies; graph QA verifiers beyond exact match.
Collections
Sign up for free to add this paper to one or more collections.

