- The paper finds that skill document availability increases LLM agent pass rates by 26.7-36.0% for GPT-5.5 and 18.0-26.0% for DeepSeek V4-Flash.
- The study uses a controlled setup with six distinct skill-delivery conditions to isolate the effects of skill availability from presentation granularity.
- The results indicate that while detailed skill presentation has marginal benefits, providing any curated procedural guidance markedly enhances agent performance.
Controlled Evaluation of Skill Availability and Presentation Granularity in LLM Agents
Introduction
This study systematically analyzes the impact of skill-document availability and the granularity with which procedural skills are presented to LLM-based agents in the context of the SkillsBench benchmark suite. Employing a controlled subset of 30 domain-diverse, oracle-validated tasks, the paper evaluates two advanced models (GPT-5.5 and DeepSeek V4-Flash) across six skill-delivery variants, meticulously separating the effect of having skill knowledge from the effect of its presentation structure. The methodological rigor—including controlled rewrites, protocol locks, and comprehensive hash validation—ensures high reproducibility and interpretability of results (2605.31408).
Experimental Design and Protocol Integrity
To disambiguate the confounding between skill availability and presentation granularity, the authors operationalize six distinct conditions: no skill, original curated skills, high-abstraction (principles/invariants), medium-abstraction (with and without one worked example), and low-abstraction (checklist-style) presentations. Each variant adheres to strict content-control measures involving content ledgers and triple-auditing (structure, style, ledger coverage), confining any residual variation to salience, length, or other minor pragmatic features.
Evaluation protocols feature fixed benchmarks, frozen random seeds, and controlled model-specific settings, preventing post-hoc hyperparameter or inference-budget tweaks. Five independent trials are aggregated per task-condition-model cell, with outcomes primarily assessed via deterministic verifiers returning binary or fractional rewards.
Impact of Skill Availability
The most statistically robust outcome concerns the availability of skill documents per se: the presence of task-relevant skill files led to +26.7 to +36.0 percentage point increases in task-mean pass rates for GPT-5.5 and +18.0 to +26.0 for DeepSeek V4-Flash, compared to the no-skill baseline. All confidence intervals for these improvements are above zero, supporting the claim that providing targeted procedural guidance at inference time yields substantial improvement in LLM agent competence on systematically challenging, oracle-validated tasks.
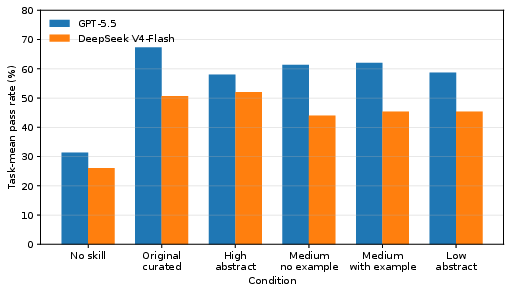
Figure 1: Task-mean pass rates by model and condition, demonstrating strong improvements from all skill-availability conditions relative to the no-skill baseline.
Original curated skills serve as the strongest baseline among the skillful variants. Rewritten variants—whether high, medium, or low in abstraction—yield slightly lower average performance for GPT-5.5, though confidence intervals on inter-variant deltas cross zero, indicating that specific pragmatics in the original skills (order, emphasis, naming, cues) could be nontrivial and not fully captured by controlled rewriting.
Presentation Granularity: Abstraction Level and Worked Examples
The primary research hypothesis—whether the abstraction level of skill presentation or the inclusion of a single worked example in procedural guidance impacts agent performance—yields only small, model-dependent, and statistically uncertain effects. The task-paired difference between low-abstraction (checklist) and high-abstraction (principle-based) presentations is +0.7 percentage points for GPT-5.5 and −6.7 for DeepSeek V4-Flash, with both 95% bootstrap confidence intervals overlapping zero. These results reject any strong claim of a consistent performance benefit for more concrete or more abstract presentations under the tested conditions.
For worked examples, adding a single concrete demonstration to medium-abstraction guidance produces slightly positive but still statistically non-robust effects: +0.7 (GPT-5.5) and +1.3 (DeepSeek V4-Flash) percentage points, again with confidence intervals crossing zero.
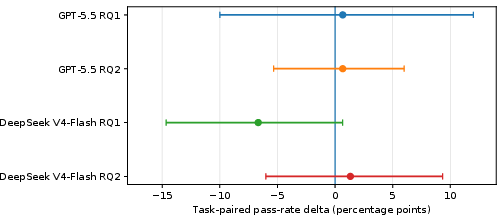
Figure 2: Primary task-paired presentation contrasts with 95\% bootstrap confidence intervals, affirming that differences in abstraction level and the presence of a worked example are minor and often indistinguishable from noise.
Secondary analyses using mean (fractional) rewards corroborate the binary findings: no secondary metric reveals stable, substantial differences among skill presentation variants.
Operational Controls and Threats to Validity
The rigorous protocol includes pre- and post-execution hash validation of every file involved, deterministic schedule freezing, concurrency controls, transport-path amendments, and explicit failure-category annotation. This approach minimizes infrastructural confounding and ensures replicability. Nevertheless, certain threats remain: the 30-task subset, while domain-balanced and oracle-validated, is not representative of the entire SkillsBench distribution and has limited resolution for detecting differences below approximately $8-16$ percentage points (given realized variance).
Content rewrites, despite triple audit, cannot guarantee preservation of all pragmatic cues (ordering, salience, or contextually salient phrasing) present in the original curated skills. Model configurations are not compute-matched, so cross-model contrasts are primarily descriptive.
Implications and Future Directions
The central empirical finding—that skill document availability provides a robust benefit while the structural granularity of skill presentation yields small or uncertain effects—has several implications:
- Skill Infusion: Equipping agents with any form of curated, task-relevant procedural guidance is much more impactful than finetuning the stylistic or abstract/concrete nature of the presentation.
- Pragmatic Skill Engineering: Fine-grained rewrites, such as shifting from principle-oriented to checklist-oriented styles, do not reliably improve or degrade agent performance at current LLM capability levels under typical reasoning settings.
- Worked Example Scope: The practically negligible effect of a single worked example indicates that more extensive experimentation—systematically varying example quantity, length, and similarity—will be required before best practices can be articulated for demonstration-based skill packaging in agents.
- Protocol Replicability: The detailed operational amendments and release of full row-level data, manifests, and scripts establish this study as a replicable reference for further investigations into skill delivery, prompting, and tool-use regimen.
- Model-Dependent Sensitivities: The absence of consistent advantages for any abstraction level or example condition, despite positive skill availability effects, suggests that future research should explore adaptive skill presentation—tuned to both agent architecture and the specific reasoning mode.
Conclusion
This controlled, protocol-rich study demonstrates that providing LLM agents with skill documents substantially enhances success on a diverse, challenging agent-benchmark subset, while controlled manipulations of skill document presentation granularity yield only marginal, inconsistent improvements. The findings support a restrained but actionable design implication: the inclusion of curated, task-relevant procedural guidance is more important than presentation style, at least for current agent architectures and reasoning protocols. Further research on skill authorship strategies and the generalizability of these findings to broader agent suites and real-world deployments is warranted.