- The paper introduces a rigorous evaluation framework examining the lifecycle of agent skills from experience generation to consumption.
- The paper demonstrates that extractor-target compatibility and experience pool composition drive skill utility, with 75% positive and 25% negative transfer rates.
- The paper validates a meta-skill guided rubric that improves downstream performance gains (+1.55pp) and enhances judge accuracy from 46.4% to 73.8%.
Systematic Analysis of Model-Generated Agent Skills: Experience, Extraction, and Consumption
Problem Motivation and Study Design
Structured skill reuse is a central mechanism in contemporary LLM-based language agents, enabling fast adaptation and experience transfer. The proliferation of domain-level, model-generated skills promises scalable and automated distillation of recurring procedures, but systematic evaluation across the entire lifecycle—experience generation, skill extraction, skill consumption—remains lacking. This study constructs a utility-grounded evaluation framework to rigorously probe whether model-generated skills actually deliver downstream utility, when and why negative transfer arises, and what factors at each lifecycle stage govern skill quality.
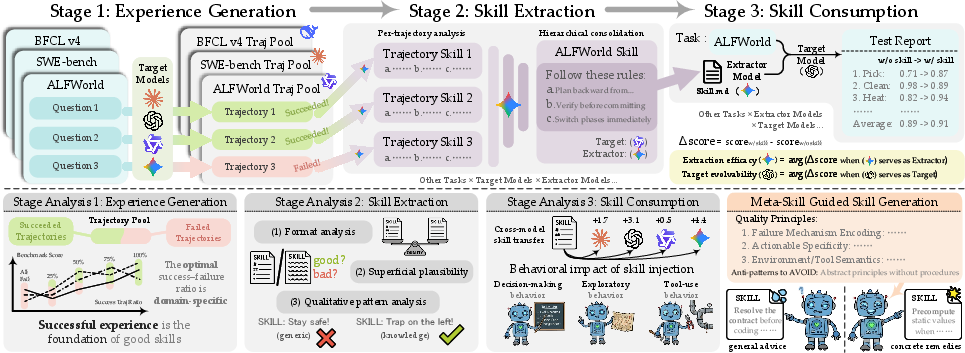
Figure 1: The study evaluates the trajectory-to-skill lifecycle across experience generation, skill extraction, and skill consumption.
Experimental Protocol and Evaluation Metrics
The evaluation pipeline is instantiated across five agentic domains (ALFWorld, SpreadsheetBench, SWE-bench-Verified, SEAL-0, BFCL-v4) with six state-of-the-art LLMs as targets and five as extractors. Each target generates an experience pool from domain tasks, an extractor distills a consolidated domain-level skill, and the skill is supplied to the same target for evaluation on held-out tasks. Downstream performance gain (delta relative to no-skill baseline) is the principal metric, with Extraction Efficacy (EE) and Target Evolvability (TE) summarizing extractor- and target-side effects. This approach enables controlled isolation of extraction vs. consumption phases and high-fidelity measurement of skill transfer.
Across domains, model-generated skills are generally beneficial, with positive transfer in approximately 75% of extractor-target pairings. However, non-trivial negative transfer occurs in 25% of cases, with domain-dependent fragility (e.g., 47% negative in ALFWorld vs. 13% in spreadsheet/coding domains). Numerical results show substantial target-dependence: e.g., GPT-5.4 benefits uniformly on ALFWorld (TE=+4.93), while lighter Gemini/Qwen variants exhibit negative TE. Extractor quality is not predicted by baseline task skill or model scale; e.g., Gemini-3.1-Flash-Lite outperforms GPT-5.4 as an extractor in SpreadsheetBench despite weaker task execution. Thus, skill utility is driven by nuanced extractor-target compatibility, not mere model strength.
Lifecycle Dissection: Drivers of Skill Utility
Experience Generation
Manipulating success/failure ratios in experience pools reveals domain-specific optimal mixes: SpreadsheetBench benefits from success-heavy pools, ALFWorld from failure-rich ones, but all-failure pools degrade utility universally. This indicates successful trajectories provide positive procedural signals essential for transferable skills, but domain-specific failure modes can offer critical information in environments with high constraint complexity.
Neither skill format nor textual plausibility correlates with downstream utility. Across 151 pairwise skill comparisons, LLM judges based on text alone fail to predict performance (46.4% accuracy, comparable to random), and accuracy drops further on high-gap pairs. Instead, actionable specificity and encoding of concrete failure mechanisms are primary determinants, as qualitative analysis shows high-utility skills consistently enumerate executable remedies for domain-specific failure types.
Skill Consumption
Skill-induced gains vary sharply even with identical skill text injected into different targets. Consumption reshapes the target's default policy: in SpreadsheetBench, GPT-5.4 is steered toward evaluator-aligned computation and verification, while Qwen3.5-9B moves toward workbook-native workflows, gaining structure but losing robustness. Skill consumption is bounded by inherent target abilities and the structure of their experience-induced strategies.
Contrastive analysis across high-gap skill pairs produces a validated 3-dimension rubric: Failure Mechanism Encoding, Actionable Specificity, and High-Risk Action Blacklist. Inserting this rubric as meta-skill prior into extraction prompts consistently improves downstream skill utility in all tested domains and models—raising judge accuracy in pairwise ranking from 46.4% to 73.8% and providing average performance gains of +1.55 pp, contrasted with a naive plausibility rubric which degrades utility (−0.59 pp).
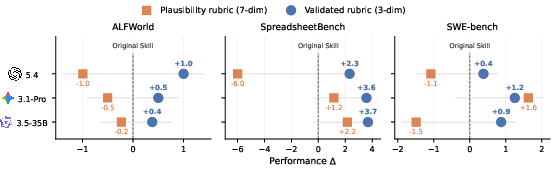
Figure 2: Meta-skill guidance consistently improves the downstream utility of generated skills; naive plausibility guidance fails.
Theoretical and Practical Implications
The study establishes that skill generation from raw agent trajectories exhibits substantial variance and non-trivial risk of negative transfer. Extractor-target compatibility, experience pool composition, and the actionable content of skills are primary drivers, while neither model scale nor textual fluency predicts utility. The validated rubric offers a plug-in, deployment-realistic mechanism to systematically improve skill extraction, paving the way for principled screening and construction of skill libraries.
Practically, these findings enable practitioners to avoid silent degradation from poorly generated skills, screen out plausible but ineffective artifacts, and reliably scale skill extraction systems. Theoretically, they motivate future research on skill selection, composition, and safety at library scale, as well as deeper formalization of compatibility spaces across extractor-target pairs.
Conclusion
This systematic, utility-grounded study moves model-generated skill extraction from intuition-driven practice to principled discipline. It rigorously characterizes the sources of variance and negative transfer, provides validated criteria for actionable improvement, and informs both evaluation and extraction in agentic systems. The resulting framework and meta-skill prior will accelerate reliable agent evolution as skill libraries proliferate and agent harnesses scale.

