Parallax: Parameterized Local Linear Attention for Language Modeling
Abstract: LLMs have become the central paradigm in artificial intelligence, yet the core computational primitive of attention has remained structurally unchanged. Local Linear Attention (LLA) is an attention mechanism derived from nonparametric statistics in the test-time regression framework. In contrast to prior research on efficient attention variants, LLA upgrades the local constant estimate in softmax attention to a local linear estimate, yielding provably superior bias-variance tradeoffs for associative memory. However, LLA has not been scaled in LLM pretraining due to computational and numerical stability concerns. We introduce Parallax, a parameterized Local Linear Attention that is scalable for LLMs. Parallax eliminates the numerical solver in LLA and learns an extra query-like projector that probes the KV covariance. We place Parallax within a family of attention mechanisms connected by the bandwidth, the probe construction and the affine structure. We propose a hardware-aware algorithm that increases the arithmetic intensity over FlashAttention, shifting attention into a more compute bound regime. Our prototype decode kernel matches or outperforms FlashAttention 2/3 across diverse batch sizes and context lengths. We pretrain Parallax at 0.6B and 1.7B scales and find consistent perplexity improvements throughout pretraining with gains that transfer to downstream benchmarks. The advantage persists under both parameter-matched and compute-matched controls, demonstrating a Pareto improvement. We perform careful pretraining ablations and identify a novel phenomenon whereby Muon unlocks the capacity of Parallax. To our knowledge, this is the first empirical demonstration of strong architecture-optimizer codesign for attention mechanisms in the architecture research literature.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way for LLMs to “pay attention” to the right parts of text more accurately and efficiently. The method is called Parallax. It improves how models look up information from their “memory” while staying fast and practical to train and run.
Imagine you’re answering a homework question by flipping through your notes. Regular attention in LLMs is like scanning all pages and averaging the most relevant lines. Parallax adds a smart correction that better understands the pattern around the lines you’re looking at, so the final answer is closer to what you actually need.
What questions did the researchers ask?
The paper focuses on simple, practical questions:
- Can we make attention more accurate at retrieving the right information from context, without making the model too slow or unstable?
- Can we take an advanced idea called Local Linear Attention (which is theoretically better) and make it work at the scale of real LLMs?
- Can we design the math and the software so it runs fast on modern GPUs?
- Does the choice of optimizer (the “training rule” for updating weights) matter for this new attention?
How does their method work?
Here is the approach in everyday terms.
- Attention basics
- In a model’s attention, keys and values are like your notes: keys say where to look; values hold the content. A query is the question.
- Standard “softmax” attention finds a weighted average of values, giving more weight to keys that match the query.
- What is Local Linear Attention (LLA)?
- Softmax attention assumes the answer near your query is “flat” (a local constant). LLA improves this by fitting a tiny straight line near the query (a local linear model) using nearby keys and values.
- This reduces errors, especially near the “edges” of what the model is focusing on. In statistics, this is known to reduce bias and improve the prediction.
- Problem: the exact math for LLA needs solving a small system of equations for every query token, which is costly and can be unstable on big models and low-precision hardware.
- What is Parallax?
- Parallax keeps the good idea (a smart local correction) but removes the slow equation-solver.
- It learns an extra “probe” vector (think of it as a second pair of eyes) from the current input. This probe looks at how keys and values vary together (their covariance—like noticing that when one thing goes up, the other tends to go up too).
- The final output = regular softmax attention − a learned correction using this covariance and the probe.
- In short: softmax gives a first draft; the probe-plus-covariance writes a better second draft.
- A hardware-friendly algorithm
- The authors design a streaming algorithm that reuses data as it flows, similar to FlashAttention (a popular fast attention method).
- They compute two things at once (the main attention and the correction) while reading the keys/values only once. This boosts “arithmetic intensity” (more math per byte of data moved), which is great for modern GPUs.
- They built a custom decoding kernel (the part used when generating text) that matches or beats FlashAttention 2/3 in speed in many settings.
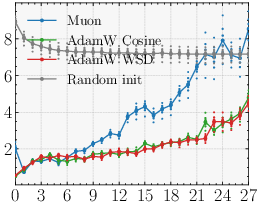
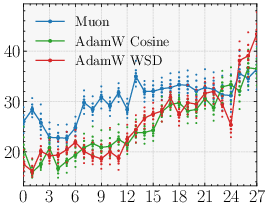
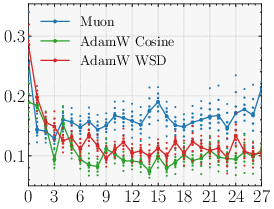
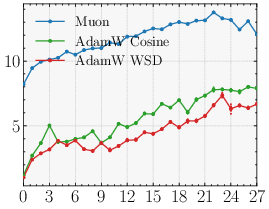
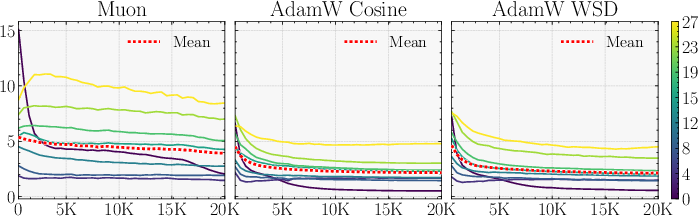
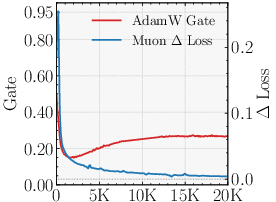
- Why the optimizer matters (Muon vs AdamW)
- An optimizer is a training rule that decides how to adjust model weights after each batch.
- Parallax relies on the learned probe being strong and well-aligned with the correction it needs to make.
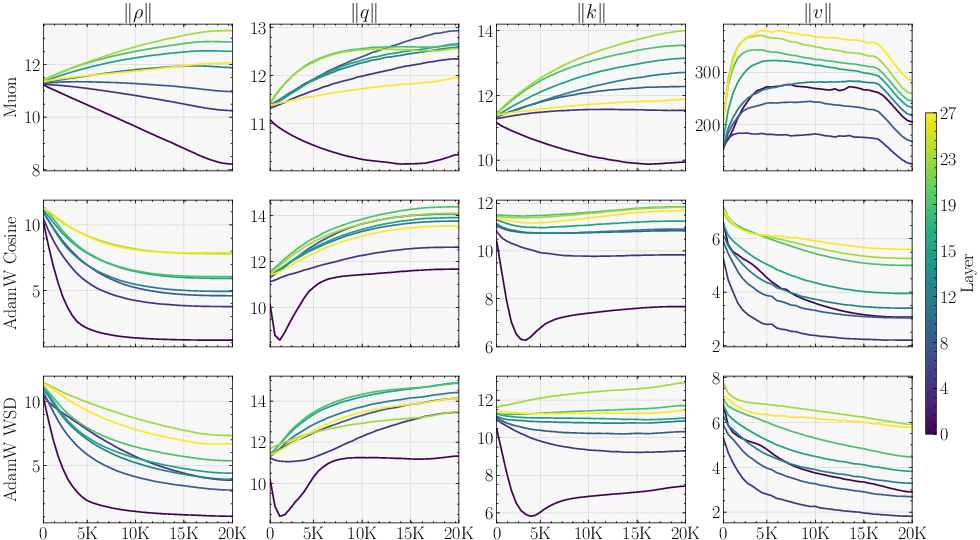
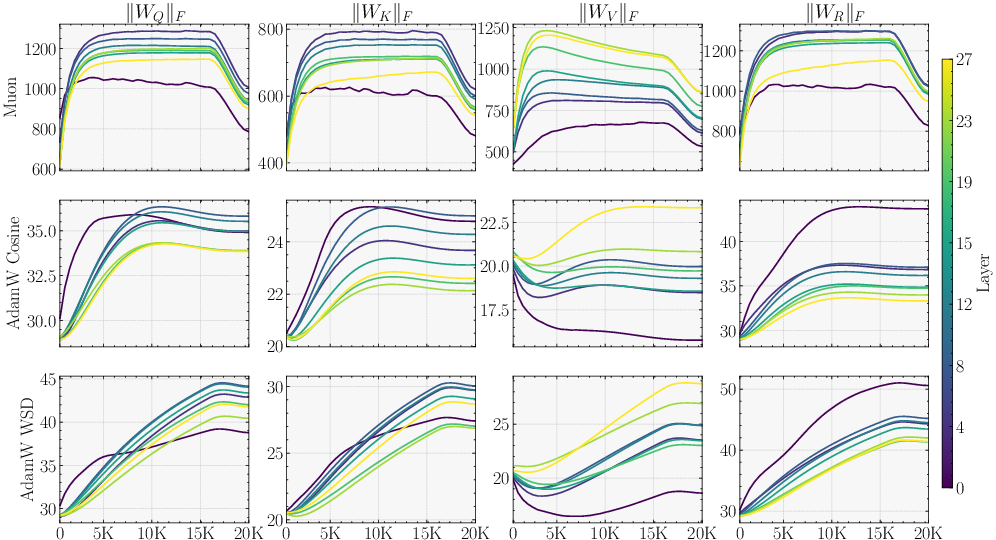
- The Muon optimizer encourages updates with good conditioning (roughly: balanced, stable steps), which helps the probe be useful. With AdamW, the probe sometimes ends up weaker, and the benefit shrinks.
Helpful analogies for technical terms:
- Covariance: how two things “move together” (e.g., when study time goes up, grades often go up; they have positive covariance).
- Bandwidth (in this context): how wide a neighborhood counts as “nearby” around the query.
- Arithmetic intensity: how much thinking you do per byte you read from memory.
What did they find?
Here are the main results, simplified:
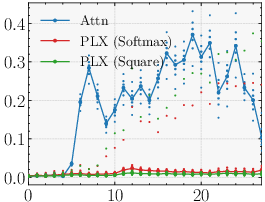
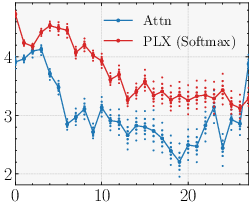
- Better recall on synthetic tests: On a benchmark that checks whether models can remember and pull the right information from context (like copying or recalling), Parallax consistently does better than standard attention and several efficient alternatives.
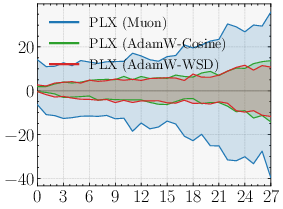
- Real LLM training wins: They pre-trained models of about 0.6B and 1.7B parameters. Parallax got lower perplexity (a standard measure of language modeling quality; lower is better) and improved scores on downstream tasks. The gains held steady during training.
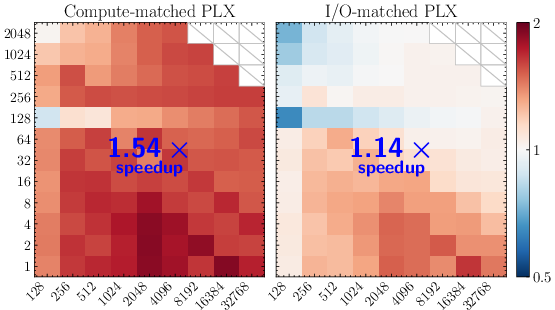
- Not just more parameters or more compute: They ran careful control experiments:
- Parameter-matched control: Adding the same number of extra parameters to a regular Transformer did not close the gap.
- Compute-matched control: Reducing Parallax’s per-layer compute to match a Transformer still kept most of the gains.
- This shows the improvement comes from the mechanism itself, not simply from size or extra work.
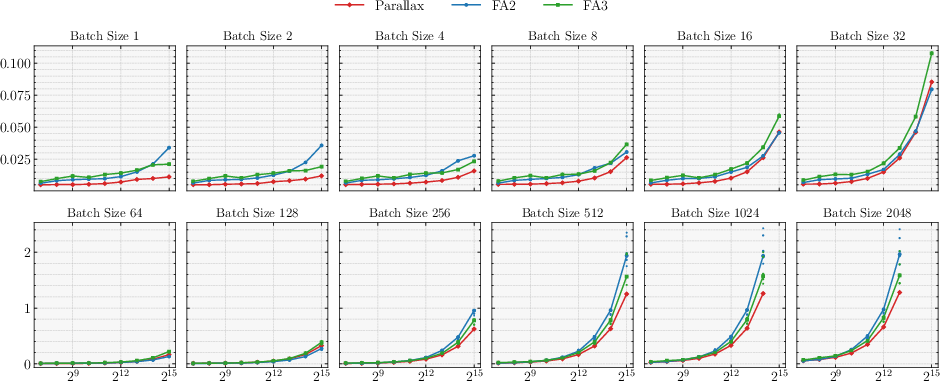
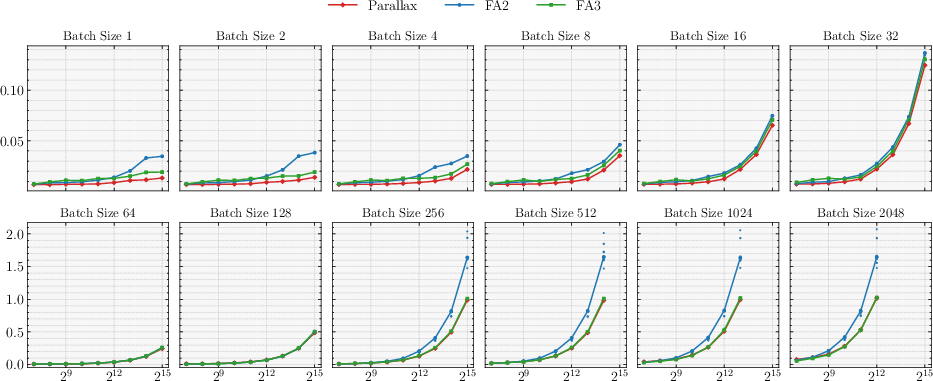
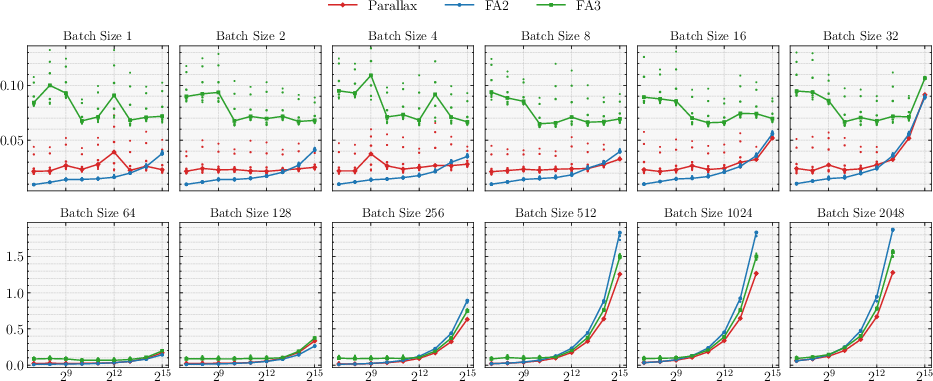
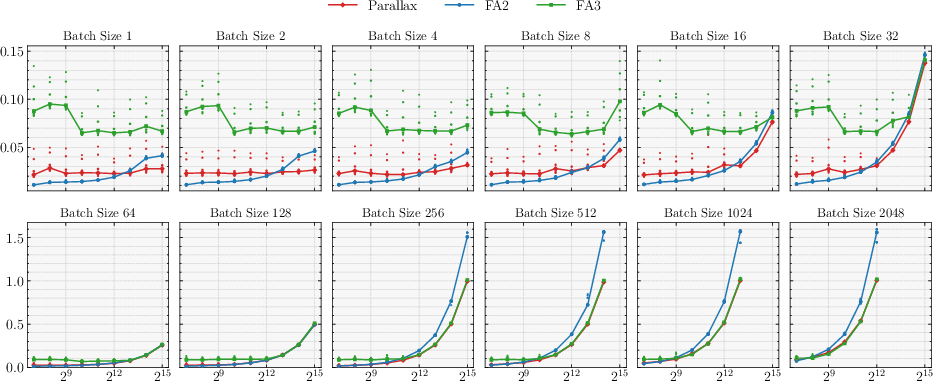
- Fast decoding: Their custom Parallax kernel for text generation matched or outperformed FlashAttention 2/3 across many batch sizes and context lengths on modern GPUs.
- Optimizer matters: With Muon, Parallax’s advantage is clear and consistent. With AdamW, the benefit is smaller or sometimes disappears. This is an example of “optimizer–architecture co-design”: the training rule and the layer design support each other.
Why does it matter?
- Stronger memory and accuracy: Parallax helps models recall and use relevant information in long contexts more reliably, which is critical for tasks like long documents, code, and multi-step reasoning.
- Practical at scale: It avoids unstable equation solves, works in low-precision formats, and comes with a fast kernel. That makes it suitable for large-scale pretraining and real-world deployment.
- Efficient and flexible: It keeps the spirit of better local modeling (like LLA) while fitting neatly into modern attention pipelines. Its design also shows how to increase GPU efficiency by doing more useful math per memory read.
- A blueprint for future designs: The paper places Parallax within a family of attention methods and shows that pairing the right optimizer (Muon) with the right layer can unlock extra performance. This insight could guide future improvements in both architecture and training methods.
In short, Parallax is a smarter attention mechanism that improves accuracy, stays fast, and demonstrates how careful engineering and training choices can make advanced ideas practical for today’s LLMs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what the paper leaves uncertain or unexplored, framed as concrete directions future work could pursue:
- Theoretical guarantees for Parallax vs. LLA
- Under what conditions does a learned linear probe approximate the exact LLA solution ? Can we bound the excess error introduced by parameterizing and by setting ? Provide bias–variance or risk bounds for Parallax analogous to those in Theorem 1 for LLA.
- Boundary amplification removal
- Setting stabilizes training but discards a theoretically motivated boundary correction. Can one design a stable, learnable, or bounded surrogate for (e.g., clamped, normalized, or regularized variants) that preserves gains without numerical pathologies? Empirically characterize failure modes near boundary queries.
- Probe design space
- The probe is a single linear map . Would multiple probes, non-linear probes (e.g., MLPs), low-rank or gated probes, or per-head/per-layer adaptive probes better approximate and improve performance? How does probe capacity trade off with stability and compute?
- Positional encoding choices for the probe
- Only RoPE on is explored. How do alternative position encodings (ALiBi, T5-style RPE, YaRN/NTK-aware scaling, learned rotary) affect Parallax’s long-context extrapolation and stability? What is the best way to inject position into the covariance branch?
- Optimizer–architecture dependency
- The gains largely materialize under Muon and shrink under AdamW. What optimizer properties (e.g., spectral-norm geometry, conditioning of updates) are causally responsible? Can we design optimizer variants or regularizers that explicitly improve probe alignment and norm (e.g., spectral penalties, orthogonality constraints) to make Parallax optimizer-agnostic?
- Alignment metrics and training objectives
- The paper hints at metrics such as correction-to-output ratio, KV correlation, probe–covariance alignment. Can these be turned into training signals (auxiliary losses or curriculum) to encourage alignment with ? Provide quantitative evidence that improving such metrics yields consistent downstream gains.
- Scaling laws and frontier-scale validation
- Results are at 0.6B and 1.7B. Do the perplexity and downstream gains persist or grow at 7B–70B+ scales, and what are the scaling exponents vs. Transformer baselines under fixed compute budgets?
- Long-context capability on real tasks
- Beyond synthetic MAD and microbenchmarks, evaluate on long-context retrieval and reasoning suites (e.g., RULER, L-Eval, Needle-in-a-Haystack, long-document QA, long-code tasks) to validate the local-linear correction’s practical benefits at 32k–>100k tokens.
- Breadth of downstream evaluations
- Assess on instruction tuning, SFT/RLHF, math (GSM8K/MATH), code (HumanEval/MBPP), and multilingual benchmarks to test whether Parallax’s gains transfer beyond zero-shot MC tasks and English web pretraining.
- Comparisons to stronger baselines
- Include MLA/GQA variants tuned for I/O efficiency, recent SSMs (e.g., Mamba-2/3), Retention/RetNet, and hybrid attention–SSM architectures under matched compute/params to situate Parallax among the most competitive alternatives.
- Training-time efficiency and backward kernels
- The paper optimizes decode but does not provide fused backward kernels or end-to-end training throughput measurements. Quantify training wall-clock, memory, and energy vs. FlashAttention under real pipelines (including optimizer cost for Muon). Provide training-side kernels and memory analyses for the additional states (O2/d2) and gradients.
- Hardware portability and generality
- The decode kernel relies on NVIDIA Hopper WGMMA and CuTeDSL. How does Parallax perform on A100, AMD (ROCm), and TPU architectures? Are the arithmetic intensity benefits preserved without Hopper-specific instructions? Provide portability strategies and benchmarks.
- Inference at scale beyond microbenchmarks
- Report end-to-end latency/throughput in serving setups (e.g., TGI) with KV cache, batching, and paged attention. Analyze memory footprint, cache bandwidth, and throughput when mixing Parallax with standard KV-caching strategies.
- Numerical precision and quantization
- The method is profiled at BF16; training/inference behavior under FP8, 8-bit/4-bit quantization, and quantization-aware training remains unknown. Are covariance terms more sensitive to low precision than standard attention? Provide ablations and calibration strategies.
- Robustness and reproducibility
- Sensitivity to seeds, hyperparameters (head dimension, number of heads, init/scale, learning rate schedules, weight decay), and data curricula is not reported. Provide variance estimates, ablation sweeps, and robust defaults.
- Architectural integration breadth
- Evaluate Parallax in encoder-only (e.g., BERT-style), encoder–decoder (cross-attention), and multimodal settings. How does the covariance correction behave in cross-attention where K/V come from a different modality/source?
- Compatibility with sparsity and memory optimizations
- Interactions with block-sparse/dynamic sparse attention, sliding-window or dilated patterns, MLA/KV-sharing, and KV-cache compression remain unstudied. Can the covariance branch exploit or preserve sparsity to reduce compute?
- Interplay with MoE and hybrid mixers
- Assess Parallax within MoE architectures or combined with SSM layers. Does the covariance correction complement expert routing or recurrent states? What is the best layer placement strategy?
- Regularization and stability mechanisms
- Investigate whether additional normalization, clipping, or shrinkage on the covariance term (e.g., center/scale constraints, spectral norm bounds, shrinkage estimators of ΣKV) improve stability and generalization.
- Interpretability of the learned probe
- Analyze what learns across layers/heads: alignment with principal directions of KV covariance, dependence on token types/positions, and evolution during training. Can this inform better inductive biases or diagnostics?
- Data and domain generalization
- Pretraining is on Ultra-FineWeb. Test robustness on diverse mixtures (e.g., mixtures of books/code/math/scientific text), multilingual corpora, and domain-shifted evaluations to quantify generality.
- Energy and cost accounting
- The arithmetic intensity is higher and Muon adds optimizer compute. Provide comprehensive energy-per-token and cost-per-quality metrics (train and inference) to substantiate the claimed Pareto improvements in practical deployments.
- Safety and memorization
- Since covariance corrections may change how models aggregate contextual evidence, study effects on memorization, privacy leakage, and calibration (e.g., tendency to over- or under-aggregate at boundaries) relative to softmax attention.
- Formal connection to test-time regression with parametric probes
- Extend the test-time regression framework to characterize parametric probes: when does end-to-end training with recover or approximate the local linear solution, and how does optimizer geometry (Muon vs. AdamW) modulate this convergence?
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage Parallax’s parameterized local linear attention, its hardware‑aware streaming algorithm, and the observed optimizer–architecture co‑design with Muon.
- Drop‑in attention layer to improve LLM quality and long‑context recall (Software, Cloud, Enterprise AI)
- What: Replace softmax attention with Parallax in decoder‑only Transformers to reduce perplexity and improve in‑context retrieval/memory on long inputs.
- Where: General chatbots, code assistants, document question answering, long‑form summarization, retrieval‑augmented generation (RAG) pipelines.
- Tools/workflows: Parallax attention module in PyTorch/xFormers; integrate with inference servers (vLLM, TensorRT‑LLM, Triton); RoPE applied to R‑projections; parameter/compute‑matched A/B testing.
- Assumptions/dependencies: Best gains observed when trained with the Muon optimizer; RoPE on R improves results; quality and speed benefits are largest on Hopper‑class GPUs (H100/H200); AdamW yields smaller gains.
- Faster decode on Hopper GPUs via higher arithmetic intensity (Cloud inference, MLOps, Cost optimization)
- What: Use the Parallax CuTeDSL decode kernel to shift attention into a more compute‑bound regime and match/outperform FlashAttention 2/3 latency on H200.
- Where: High‑throughput online inference, batch decoding, streaming assistants.
- Tools/workflows: I/O‑matched or compute‑matched deployment; exploit fused QK and RK paths and shared KV stream; persistent kernels and in‑kernel reductions.
- Assumptions/dependencies: Hopper WGMMA/Tensor Cores; BF16/FP16 support; kernel maturity on non‑NVIDIA hardware may lag.
- Higher quality per parameter for smaller models (Software, Startups/SaaS, Cloud)
- What: Train 0.6B–1.7B LLMs with Parallax to reach better perplexity and downstream scores than parameter‑matched Transformers.
- Where: Cost‑sensitive deployments, startups seeking smaller yet capable models.
- Tools/workflows: Pretraining/fine‑tuning pipelines with Muon; compute/parameter‑matched baselines for fair evaluation; RoPE on R.
- Assumptions/dependencies: Access to pretraining data; Muon optimizer; training stability and hyperparameter tuning.
- Better RAG and long‑document analytics (Healthcare, Legal, Finance, Education)
- What: Improve recall of in‑context facts, yielding more faithful long‑document Q&A and summarization.
- Where: EHR summarization, guideline retrieval (Healthcare); contract review and e‑discovery (Legal); earnings call/10‑K analyses (Finance); textbook/lecture tutoring (Education).
- Tools/workflows: Swap attention module in fine‑tuned models; fewer retrieval hops or larger context windows with improved recall; evaluation with LAMBADA/WikiText and task‑specific benchmarks.
- Assumptions/dependencies: Gains are strongest on recall‑oriented tasks; domain‑specific evaluation still required for regulated environments.
- Multimodal and long‑horizon sequence modeling (Media, Vision‑Language, Analytics)
- What: Apply Parallax in transformer backbones for VLMs, video captioning, and other long‑context multimodal tasks.
- Where: Video summarization, lecture video assistants, long‑horizon analytics.
- Tools/workflows: Replace attention in multimodal stacks; retrain with Muon; maintain RoPE/positional schemes for R where applicable.
- Assumptions/dependencies: Additional tuning and evaluation for modality alignment; kernel support on target hardware.
- Agent memory and tool‑use reliability (Agents, Workflow automation)
- What: Use improved associative memory to reduce forgetting in multi‑step agents and tool chains (e.g., chain‑of‑thought, tool‑former‑style use).
- Where: Customer support agents, coding copilots, research assistants.
- Tools/workflows: Long‑context inference with Parallax; analyze covariance‑driven corrections for memory diagnostics.
- Assumptions/dependencies: Agent stacks may require re‑tuning prompts and memory buffers.
- Academic research and teaching (Academia)
- What: Study attention as test‑time regression; teach bias–variance trade‑offs and associative memory using Parallax/LLA; reproduce MAD‑Benchmark results.
- Where: ML courses, attention mechanism research, optimizer–architecture co‑design studies.
- Tools/workflows: Open‑source code; MAD‑Benchmark and long‑context recall tasks; ablations on Muon vs AdamW.
- Assumptions/dependencies: Access to GPUs for experiments; familiarity with Muon or alternatives.
- MLOps evaluation playbook (Platform teams)
- What: Standardize A/B procedures to test Parallax vs. Transformer baselines under parameter‑ and compute‑matched settings; monitor recall metrics.
- Where: Internal benchmarking and model governance.
- Tools/workflows: Automated experiment orchestration; telemetry on perplexity, recall, latency, and cost; rollout gates tied to recall KPIs.
- Assumptions/dependencies: CI/CD for model training and evaluation; kernel support on production hardware.
Long‑Term Applications
These opportunities require further research, engineering, validation, or ecosystem support before broad deployment.
- Frontier‑scale pretraining and instruction tuning (Foundation model labs, Cloud)
- What: Apply Parallax to 70B+ models with extended contexts; evaluate Pareto gains at scale.
- Tools/workflows: Distributed Muon variants (e.g., Moonlight/Dion) to reduce communication; optimizer‑architecture co‑design pipelines.
- Assumptions/dependencies: Stable distributed Muon, memory/comms budgets, full‑stack training support.
- Specialized hardware and compiler support (Semiconductors, Systems)
- What: Design fused Parallax attention blocks (joint QK/RK and PV ops) in ASICs/NPUs; compiler passes that co‑schedule the two branches.
- Tools/workflows: Kernel fusion in CUDA/Triton; TVM/XLA backends; hardware micro‑architectures favoring higher arithmetic intensity.
- Assumptions/dependencies: Silicon design cycles; cross‑vendor standardization; ROI validated by production workloads.
- Low‑precision and edge/mobile deployment (Consumer devices, Edge AI)
- What: Extend Parallax to INT8/FP8/4‑bit quantization; adapt kernels for mobile NPUs where memory bandwidth is scarce.
- Tools/workflows: Quantization‑aware training; calibration sets for R‑projections; kernel re‑implementation on non‑Hopper hardware.
- Assumptions/dependencies: Numerical stability with very low precision; mobile SDK support; thermal/power budgets.
- Safety‑critical and regulated domains (Healthcare, Aviation, Law/Gov)
- What: Leverage improved recall to reduce omissions in critical summarization/decision support.
- Tools/workflows: Prospective clinical/operational trials; calibration and uncertainty estimation; audit tools exposing covariance corrections.
- Assumptions/dependencies: Domain‑specific validation, oversight, and compliance; human‑in‑the‑loop workflows.
- Memory‑aware agents and planning in robotics (Robotics, Autonomous systems)
- What: Use covariance‑based probes to interface with long‑horizon memory and plan over extended sequences.
- Tools/workflows: Hybrid Parallax–SSM stacks; policy distillation with memory diagnostics; sim‑to‑real transfer studies.
- Assumptions/dependencies: Algorithmic advances for grounding memory in sensorimotor tasks; real‑time constraints.
- Sustainability and policy guidance (Policy, Sustainability)
- What: Establish reporting standards for arithmetic intensity and HBM traffic to benchmark energy efficiency of attention variants.
- Tools/workflows: Power/throughput instrumentation; lifecycle analysis that differentiates compute‑ vs I/O‑bound regimes.
- Assumptions/dependencies: Access to accurate power telemetry; community consensus on metrics.
- Generalization to other modalities and SSM hybrids (Time‑series, IoT, Finance)
- What: Combine Parallax with SSMs for robust long‑horizon forecasting and event recall in streams (e.g., telemetry, markets).
- Tools/workflows: Architectural search for hybrid mixers; streaming inference stacks with mixed recurrence/attention.
- Assumptions/dependencies: Benchmarks and datasets; stability of hybrids at scale.
- Optimizer–architecture co‑design frameworks (ML tooling)
- What: Build automated systems that select/update optimizers (Muon‑family) and attention mechanisms jointly based on training signals.
- Tools/workflows: Meta‑optimization services; curvature/conditioning diagnostics; plug‑ins for PyTorch/JAX.
- Assumptions/dependencies: Robustness of Muon‑like methods across tasks; overhead from curvature estimation.
- Data‑center scheduling tuned for compute‑bound attention (Cloud infrastructure)
- What: Job schedulers that exploit Parallax’s compute‑heavy profile to improve GPU utilization and thermal efficiency.
- Tools/workflows: Mixed workload packing (compute‑ vs I/O‑bound); runtime adaptation of head dimensions for throughput targets.
- Assumptions/dependencies: Accurate workload characterization; heterogeneous cluster support.
- Hallucination mitigation via improved retrieval fidelity (Applications, Safety)
- What: Explore whether better in‑context recall reduces hallucinations in long‑document tasks and RAG.
- Tools/workflows: New evaluation suites linking recall to factuality; retrieval budget vs accuracy trade‑off studies.
- Assumptions/dependencies: Causal link between recall and factuality is not guaranteed; requires rigorous measurement.
Cross‑cutting assumptions and dependencies
- Optimizer dependence: The paper shows Parallax’s gains are strongest with Muon; under AdamW, improvements are smaller or may vanish. Production adoption may need Muon‑family optimizers or improved AdamW regimes.
- Positional encoding on R: Applying RoPE to the R‑probe vectors consistently helped; this should be enabled by default.
- Hardware: The current decode speedups are validated on NVIDIA Hopper (H100/H200). Other accelerators may need custom kernels to realize similar benefits.
- Precision and stability: BF16/FP16 are supported; future INT8/FP8/4‑bit deployments need additional research.
- Workload fit: Gains are largest on recall‑oriented and long‑context tasks; compression/memorization tasks may see smaller benefits. Evaluation should match target use cases.
Glossary
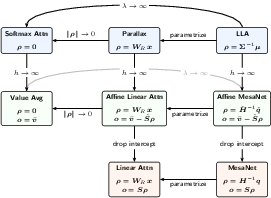
- Affine Linear Attention: A linear-attention variant with an intercept term that uses uniform running averages and a learnable probe to produce an affine readout. "We refer to the corresponding attention mechanisms as Value Averaging, Affine Linear Attention and Affine MesaNet."
- Affine MesaNet: A MesaNet variant with an intercept term that solves for an optimal probe, corresponding to an affine ridge-regression readout. "We refer to the corresponding attention mechanisms as Value Averaging, Affine Linear Attention and Affine MesaNet."
- Arithmetic intensity: The ratio of FLOPs to memory traffic (bytes), indicating whether a kernel is compute- or bandwidth-bound. "We propose a hardware-aware algorithm that increases the arithmetic intensity over FlashAttention, shifting attention into a more compute bound regime."
- Associative memory: The model’s capacity to recall and bind relevant information from past context to current queries. "yielding provably superior bias-variance tradeoffs for associative memory."
- Bandwidth (kernel): The scale parameter h controlling smoothness/weight spread in kernel-based estimators. "wide bandwidth limit "
- Bias–variance tradeoff: The balance between estimation bias and variance that governs prediction error. "yielding provably superior bias-variance tradeoffs for associative memory."
- Boundary bias: Systematic estimation error near domain boundaries typical in nonparametric methods. "Softmax Attention suffers from the boundary bias, which can be resolved by upgrading its constant function class to linear function class."
- Conjugate gradient (CG): An iterative algorithm for solving large symmetric positive-definite linear systems. "the exact LLA forward requires solving a linear system for every query with a parallel conjugate gradient (CG) solver."
- Compute bound: A regime where runtime is limited by arithmetic throughput rather than memory bandwidth. "shifting attention into a more compute bound regime."
- Covariance (KV covariance): Second-order cross-moment capturing how keys and values co-vary under attention weights. "learns an extra query-like projector that probes the KV covariance."
- DeltaNet: A family of linear attention models that update states via delta rules for efficiency. "Linear Attention such as DeltaNet \citep{yang2025gateddeltanetworksimproving,yang2025parallelizinglineartransformersdelta,kimiteam2025kimilinearexpressiveefficient},"
- FlashAttention: A hardware-aware exact softmax attention algorithm that optimizes memory traffic and tiling. "FlashAttention~\citep{dao2022flashattentionfastmemoryefficientexact,dao2023flashattention2fasterattentionbetter,shah2024flashattention3} explores hardware-aware algorithm innovations, while keeping the underlying mechanism unchanged."
- Frobenius norm: Matrix norm equal to the square root of the sum of squared entries. "For a matrix , we denote the Frobenius norm,"
- GEMM: General Matrix–Matrix Multiplication; a core high-performance linear algebra primitive. "This approach has the added benefit of exploiting fast GEMM subroutines on GPUs, making Muon hardware-aligned and feasible to use at scale."
- Gated DeltaNet (GDN): A gated variant of DeltaNet that modulates updates for improved expressiveness. "We compare Parallax against the Softmax Attention (Attn, Transformer), Mamba, Gated DeltaNet (GDN), MesaNet (Mesa) and Kimi DeltaAttention (KDA)~\citep{kimiteam2025kimilinearexpressiveefficient}."
- GQA: Grouped-Query Attention; an attention variant that shares key/value projections across groups of queries. "Transformer adds the same number of parameters to the Transformer baseline by increasing the query head count in GQA."
- Hadamard product: Elementwise product of two matrices of the same shape. "use to denote the Hadamard product between matrices."
- High-bandwidth memory (HBM): GPU memory technology providing very high data throughput. "defined as the ratio of floating point operations (FLOPs) to high-bandwidth memory (HBM) traffic in bytes."
- Householder products: Products of Householder reflections used to impose structure in linear models. "Householder products~\citep{siems2025deltaproductimprovingstatetrackinglinear}."
- Integrated mean squared error (IMSE): Expected squared error integrated over the input domain. "denote the integrated mean squared error, then"
- Kernel (in nonparametric regression): A weighting function defining local neighborhoods around a query. "with kernel ."
- Local Linear Attention (LLA): An attention mechanism that fits a local linear model around each query under kernel weights. "Local Linear Attention (LLA) is an attention mechanism derived from nonparametric statistics in the test-time regression framework."
- Mahalanobis distance: Distance metric weighted by inverse covariance; measures how far a point is from a distribution’s center. "quantifies the Mahalanobis distance from the query to the key center under ."
- Mamba: A state space model architecture for sequence modeling with long-horizon recall. "State Space Models (SSMs) such as Mamba \citep{gu2024mambalineartimesequencemodeling} maintain constant-size recurrent states and achieve subquadratic complexity."
- MesaNet: A parametric attention-like mechanism that performs ridge regression over accumulated key/value statistics. "MesaNet \citep{vonoswald2025mesanetsequencemodelinglocally} chooses and solves the optimal ridge regression,"
- Muon optimizer: An optimizer that updates weights via the polar factor of the momentum buffer, aligning with spectral geometry. "Muon is a novel optimizer for matrix parameters in the hidden layers."
- Nadaraya–Watson estimator: A local constant kernel regression estimator averaging labels with kernel weights. "It employs the Nadaraya-Watson (NW) estimator \citep{Nadaraya1964,Watson1964,Bierens1988} with kernel ."
- Newton–Schulz iterations: Iterative polynomial method to approximate matrix functions (e.g., polar factor) without SVD. "In practice, is approximated by Newton--Schulz iterations with precisely tuned matrix polynomials."
- Operator norm: Matrix norm induced by vector 2-norm (spectral norm); controls steepest descent geometry in Muon. "\citet{bernstein2024oldoptimizernewnorm} interpret the Muon update as steepest descent under the operator norm , which for matrices coincides with the spectral norm."
- OLS regression: Ordinary least squares linear regression estimating coefficients by minimizing squared error. "This template is the empirical OLS regression of on {with intercept} $\barv_i$, evaluated at the query."
- Pareto improvement: A setting where one objective improves without worsening another (e.g., accuracy vs. compute). "The advantage persists under both parameter-matched and compute-matched controls, demonstrating a Pareto improvement."
- Polar factor: The unitary (or orthogonal) factor in a matrix’s polar decomposition, used in Muon updates. "forms the polar factor , which is the nearest semi-orthogonal matrix in the Frobenius norm"
- Ridge regularization: L2 penalty on model weights to stabilize estimation and control variance. "and ridge regularization ."
- RMSNorm: Root-mean-square layer normalization variant used in transformers. "applies RMSNorm~\citep{10.5555/3454287.3455397} to and vectors"
- RoPE (Rotary Positional Embedding): A positional encoding method that rotates query/key vectors to encode relative positions. "We additionally ablate the effect of applying RoPE~\citep{su2024roformer} to $$ in Parallax."</li> <li><strong>Semi-orthogonal matrix</strong>: A matrix whose columns (or rows) are orthonormal; arises in Muon’s polar-factor update. "the nearest semi-orthogonal matrix in the Frobenius norm"</li> <li><strong>Spectral collapse</strong>: Degeneration where a matrix’s effective rank shrinks, harming expressivity. "matrices trained with AdamW, can exhibit spectral collapse \citet{arefin2026learning} whereby their effective rank shrinks rapidly over training."</li> <li><strong>Spectral norm</strong>: The largest singular value of a matrix (operator 2-norm). "we denote $\|\bm X\|_2$ the spectral norm"</li> <li><strong>Stable rank</strong>: A smooth rank surrogate defined as squared Frobenius norm divided by squared spectral norm. "We use $srank(\bm X)\bm X\|\bm X\|_F^2 / \|\bm X\|_2^2$."</li> <li><strong>State Space Models (SSMs)</strong>: Sequence models parameterizing linear recurrences for long-context processing. "State Space Models (SSMs) such as Mamba~\citep{gu2024mambalineartimesequencemodeling,dao2024transformersssmsgeneralizedmodels,lahoti2026mamba3} aim to parameterize linear recurrences with structured matrices for long-horizon recall"</li> <li><strong>Test-time regression framework</strong>: A viewpoint interpreting attention as solving a regression problem over in-context key–value pairs. "The test-time regression framework~\citep{wang2025testtimeregressionunifyingframework} interprets the attention mechanism as a regression solver over the KV pairs $\mathcal D_i = \{(k_j, v_j)\}_{j\le i}$."
- Tensor core (TC): Specialized GPU units for fast matrix multiplications with fused-precision support. "Hopper's tensor core (TC) matmul instructions (WGMMA) operate on tiles of minimum size 64 rows by construction,"
- Value Averaging: A degenerate attention mechanism that outputs the (weighted) average of values as the intercept. "We refer to the corresponding attention mechanisms as Value Averaging, Affine Linear Attention and Affine MesaNet."
- WGMMA: Warp-Grouped Matrix Multiply-Accumulate; Hopper tensor core instruction for tiled matmuls. "tensor core (TC) matmul instructions (WGMMA) operate on tiles of minimum size 64 rows by construction,"
Collections
Sign up for free to add this paper to one or more collections.