- The paper introduces a novel layer-aware attention reduction method that leverages sensitivity analysis to decide which transformer layers retain full attention, linearize, or are pruned.
- It employs a hybrid approach combining softmax, sliding-window, and attention-free layers, reducing inference complexity by up to 68% while keeping model accuracy high.
- A lightweight distillation healing phase using LoRA efficiently restores performance, demonstrating subquadratic complexity and enhanced scalability on benchmarks.
LayerBoost: Layer-Aware Attention Reduction for Efficient LLMs
Overview and Motivation
LayerBoost introduces a principled approach to attention reduction in pretrained transformers, targeting the quadratic complexity of softmax attention that impedes scalability in inference, especially in long-context and high-concurrency scenarios. The technique departs from prior uniform or random layer modification routines—prone to substantial performance degradation—by leveraging systematic layer sensitivity analysis to select which transformer layers should retain, linearize, or remove attention mechanisms. This yields a hybrid architecture composed of softmax, sliding-window, and attention-free layers, substantially reducing computational cost while preserving pretrained model quality. The subsequent healing phase employs lightweight distillation and parameter-efficient adaptation via LoRA, enabling rapid recovery with minimal training tokens.
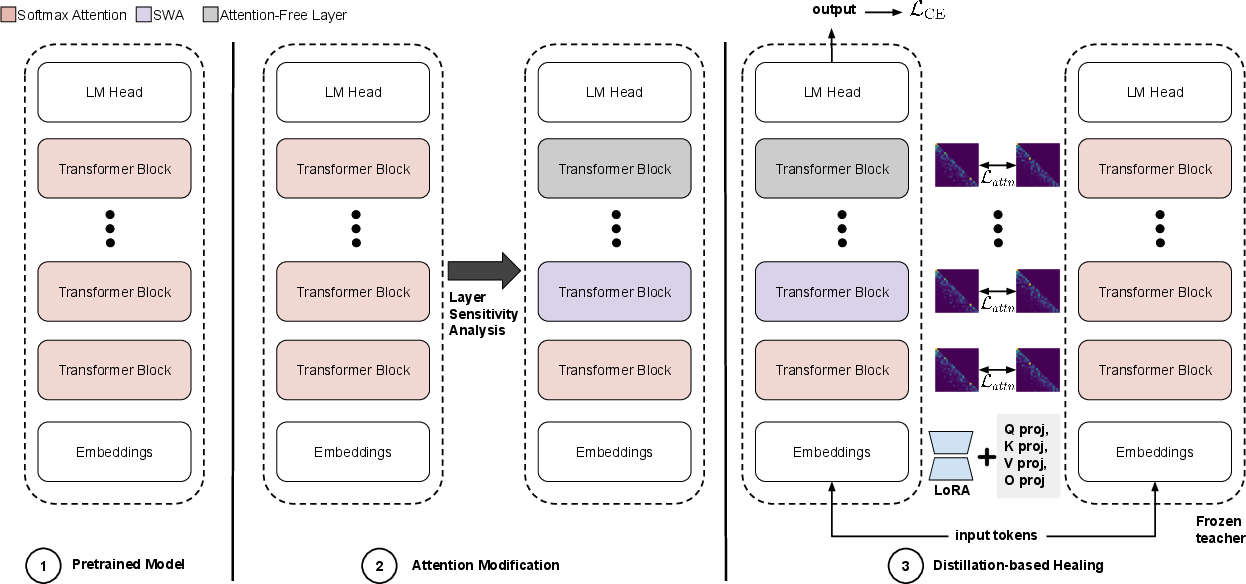
Figure 1: Overview of LayerBoost, highlighting sensitivity-driven attention modification and parameter-efficient healing via LoRA.
Layer Sensitivity Analysis and Hybrid Attention Design
A core innovation is empirical sensitivity estimation across layers, quantified by temporarily replacing each layer's attention with an identity function and measuring downstream benchmark degradations. Sensitivity scores are highly non-uniform: only a minority of layers are critical for global token interaction, while the rest tolerate linearization or pruning. This insight underpins a budget-constrained configuration algorithm that optimally selects layers for full attention retention, sliding-window attention (SWA, window size w=64), and removal.
The hybrid architecture typically retains ∼33% layers with softmax attention, linearizes ∼53% with SWA, and prunes ∼14%, inducing subquadratic inference complexity. Selection is guided by performance drops on PIQA, WinoGrande, ARC-Easy, and ARC-Challenge, ensuring that only layers with significant contribution to accuracy retain full attention.
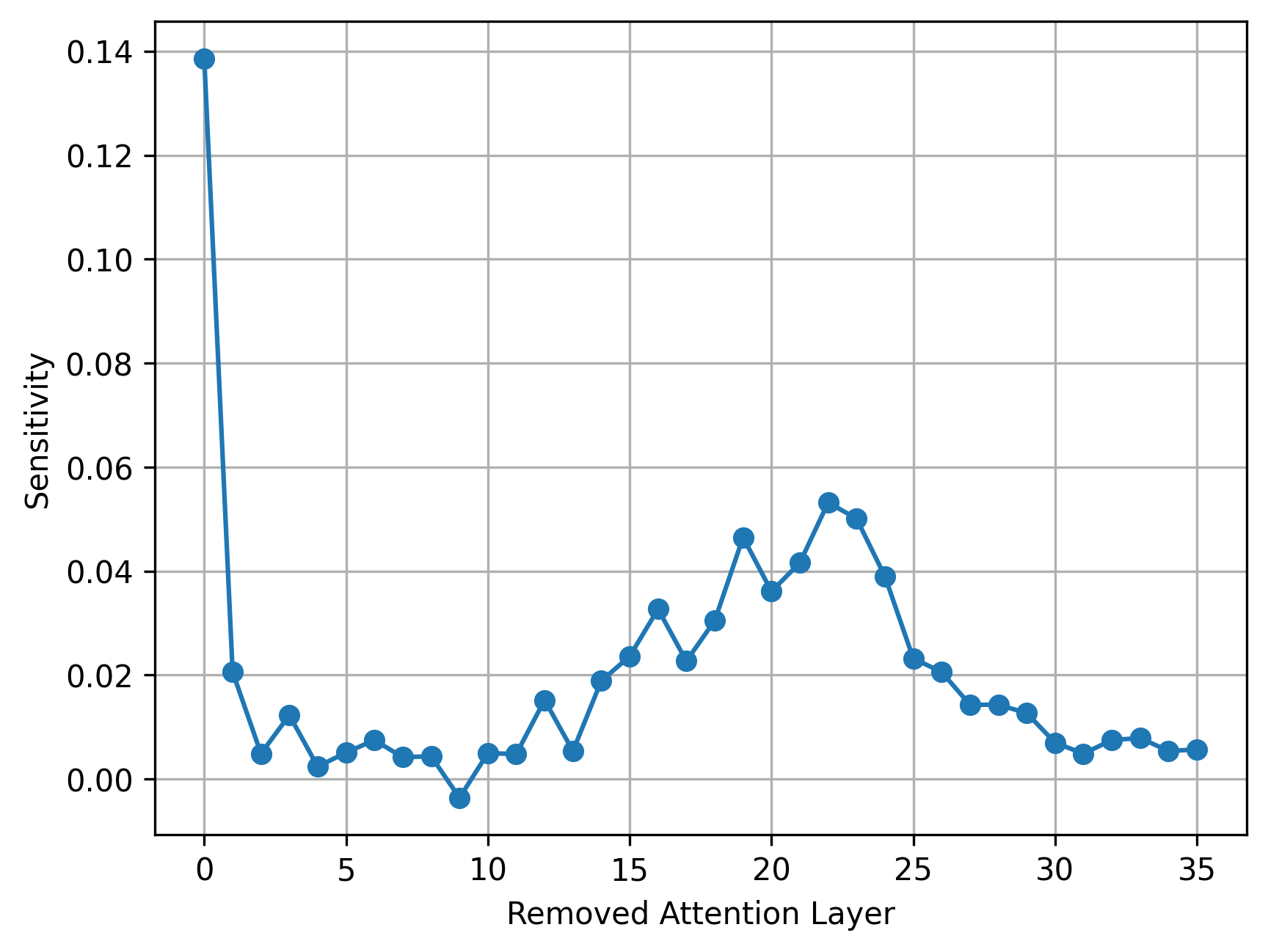
Figure 2: Layer sensitivity pattern, showing performance drops when attention is removed from individual layers.
Distillation-Based Healing and Efficient Adaptation
Architectural disturbance from attention reduction necessitates performance recovery. LayerBoost adopts knowledge distillation from the original model using a mix of token-level cross-entropy and attention-alignment KL divergence losses. Only the query, key, value, and output matrices are updated using LoRA, freezing the rest—enabling rapid recovery with a token budget as low as 10M–40M (orders-of-magnitude less than full retraining). Attention-level distillation, especially in high-sensitivity layers, is essential for restoring relational structure.
LayerBoost delivers high throughput gains (up to 68%), lower TTFT, and superior scalability at high concurrency, as demonstrated in realistic serving workloads using vLLM on A10 GPUs. Compared against state-of-the-art linearization and hybridization methods (SUPRA, LoLCATs, Liger-GLA, Mamba2-Llama), LayerBoost achieves the smallest accuracy drop (−1.52 points vs. −4.3 for the next best), particularly retaining performance on complex benchmarks such as MMLU.
Figure 3: Efficiency vs. performance trade-off: LayerBoost attains top-right positions, indicating optimal throughput and accuracy at high concurrency levels.
Memory footprint and decoding latency experiments further highlight LayerBoost's advantage: the hybrid model remains below 24GB across sequence lengths up to 8K tokens, where quadratic attention models exhibit out-of-memory failures.
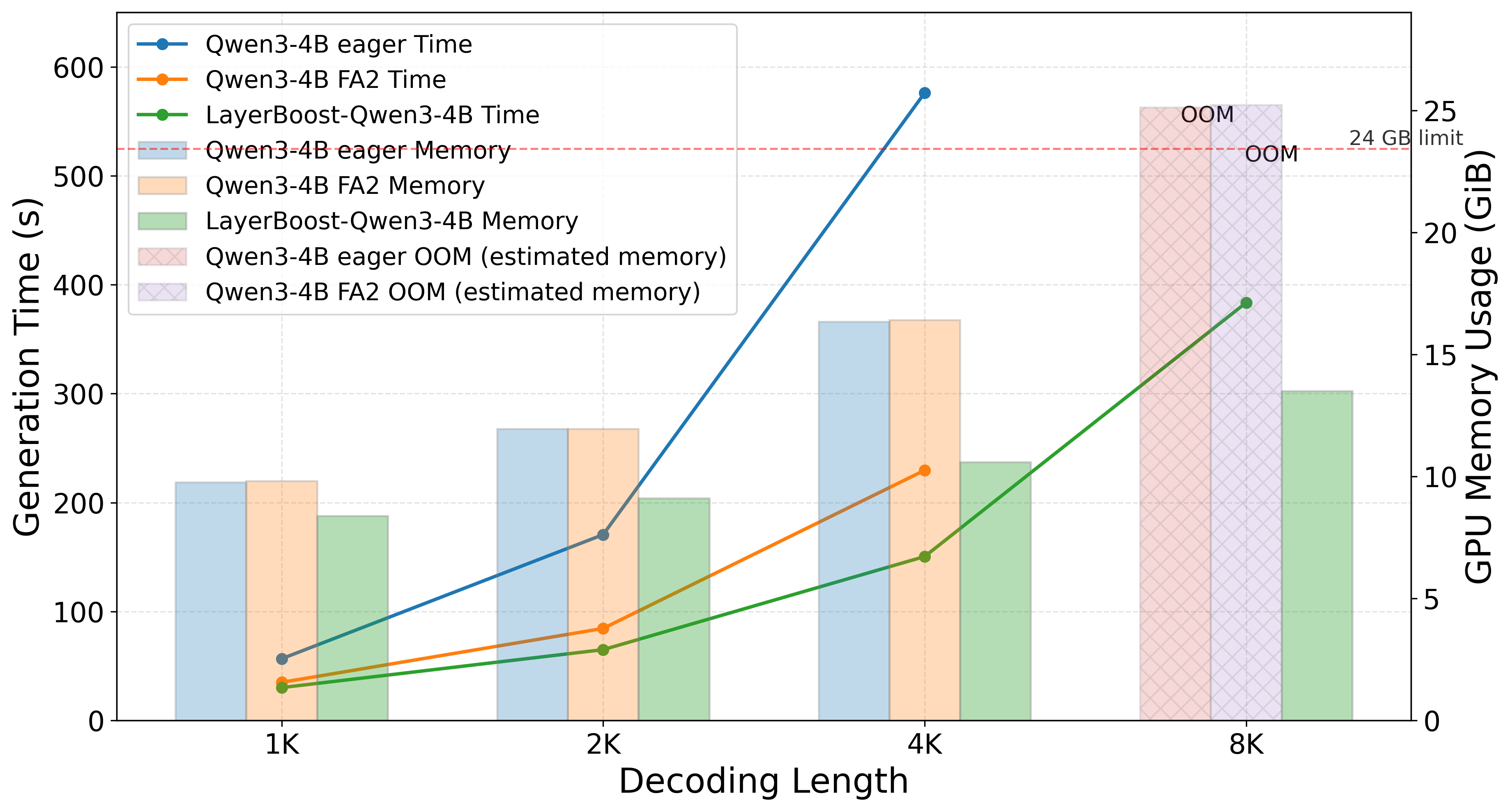
Figure 4: LayerBoost's decoding latency and memory usage across sequence lengths, showcasing scalability beyond baseline quadratic transformers.
Ablation Study and Component Analysis
Ablation studies confirm that sensitivity-guided layer selection and attention-level distillation are crucial: uniform layer reduction leads to substantial degradations particularly on challenging benchmarks (e.g., ARC-Challenge, MMLU), and excluding attention distillation impairs restoration of relational information. The healing phase achieves robust performance with minimal tokens; gains plateau beyond 40M, indicating efficiency of the initialization.
Practical and Theoretical Implications
LayerBoost demonstrates that attention reduction grounded in empirical layer sensitivity enables efficient adaptation of pretrained transformers without wholesale retraining. It implies that subquadratic architectures can be constructed from existing models with minimal incremental computational cost while maintaining quality, significantly lowering the barrier for hardware-constrained and large-scale deployment.
Theoretically, the results suggest a non-uniform representational role among transformer layers, opening avenues for sparse/hierarchical attention mechanisms and automated architecture search conditioned on sensitivity priors. Future developments may focus on scaling LayerBoost to larger models, extending sensitivity analysis to new modalities and domains, and formalizing structured sweep algorithms for optimal layer assignment.
Conclusion
LayerBoost establishes a layer-aware methodology for attention reduction in pretrained LLMs, yielding hybrid transformer architectures that deliver substantial inference efficiency improvements with minimal performance loss. Through sensitivity-driven selection and lightweight healing, it outperforms uniform/hybrid linearization approaches, offering a practical and sustainable path for efficient LLM deployment. This paradigm encourages future research into structured architectural adaptation and sensitivity-informed model design for scalable AI systems.

