- The paper introduces VisualMem, a benchmark and hybrid architecture that fuses structured visual and textual memory to capture personalized explicit and implicit evidence.
- It employs a deferred commitment mechanism that postpones image interpretation until enough conversational context is available to accurately resolve entity ownership and implicit facts.
- Empirical results show VisualMem achieving an overall accuracy of 84.1%, significantly outperforming text-only methods on both explicit entity and implicit fact retrieval.
Personal Visual Memory from Explicit and Implicit Evidence: An Expert Analysis
Motivation and Problem Definition
Long-term personalized memory for AI agents has predominantly focused on textual data, even as user experience becomes increasingly multimodal. Current benchmarks and memory systems typically either ignore image turns or reduce them to generic captions, thereby discarding critical, user-specific visual context. This text-centric paradigm is fundamentally inadequate for scenarios where visually grounded, personalized facts—such as ownership of a recurring object or implicit lifestyle details inferred from visual cues—are non-redundant with textual memory.
"Personal Visual Memory from Explicit and Implicit Evidence" (2605.28806) addresses this limitation with two principal contributions: (1) a synthetic benchmark explicitly targeting visually grounded personal memory in both explicit (recurring entity identity) and implicit (latent user fact) scenarios; and (2) VisualMem, a hybrid visual-text architecture integrating structured visual memory with standard text-based memory backends.
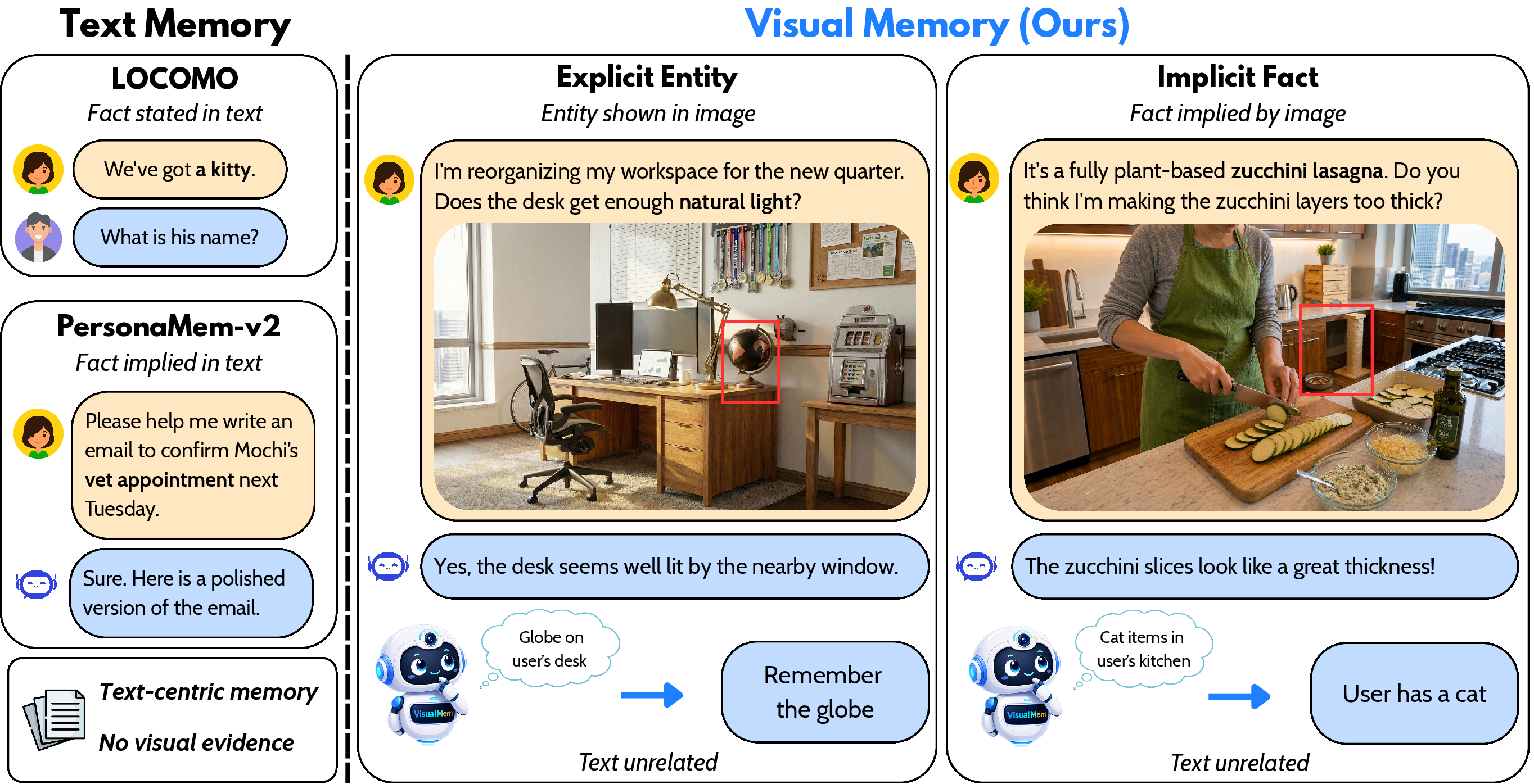
Figure 1: Prior benchmarks focus on text or facts implied by text, while VisualMem introduces explicit entity and implicit fact retrieval grounded in visual context.
Benchmark Construction and Properties
The VisualMem benchmark is synthetically constructed to enable precise, controlled evaluation of personalized visual memory across long-horizon, multimodal user histories. The process incorporates four phases:
- Structured Persona Context: Synthetic personas sampled from PersonaHub are enriched with detailed user profiles, persistent social graphs, and user-owned assets with distinctive visual properties.
- Event Sequence Generation: Temporally coherent events spanning diverse personal and social domains are generated, with causal links for temporal consistency.
- Multimodal Conversation Synthesis: Events are rendered into conversational sessions of three types—explicit entity, implicit fact, and distractor—each paired with image captions corresponding to persistent memory challenges.
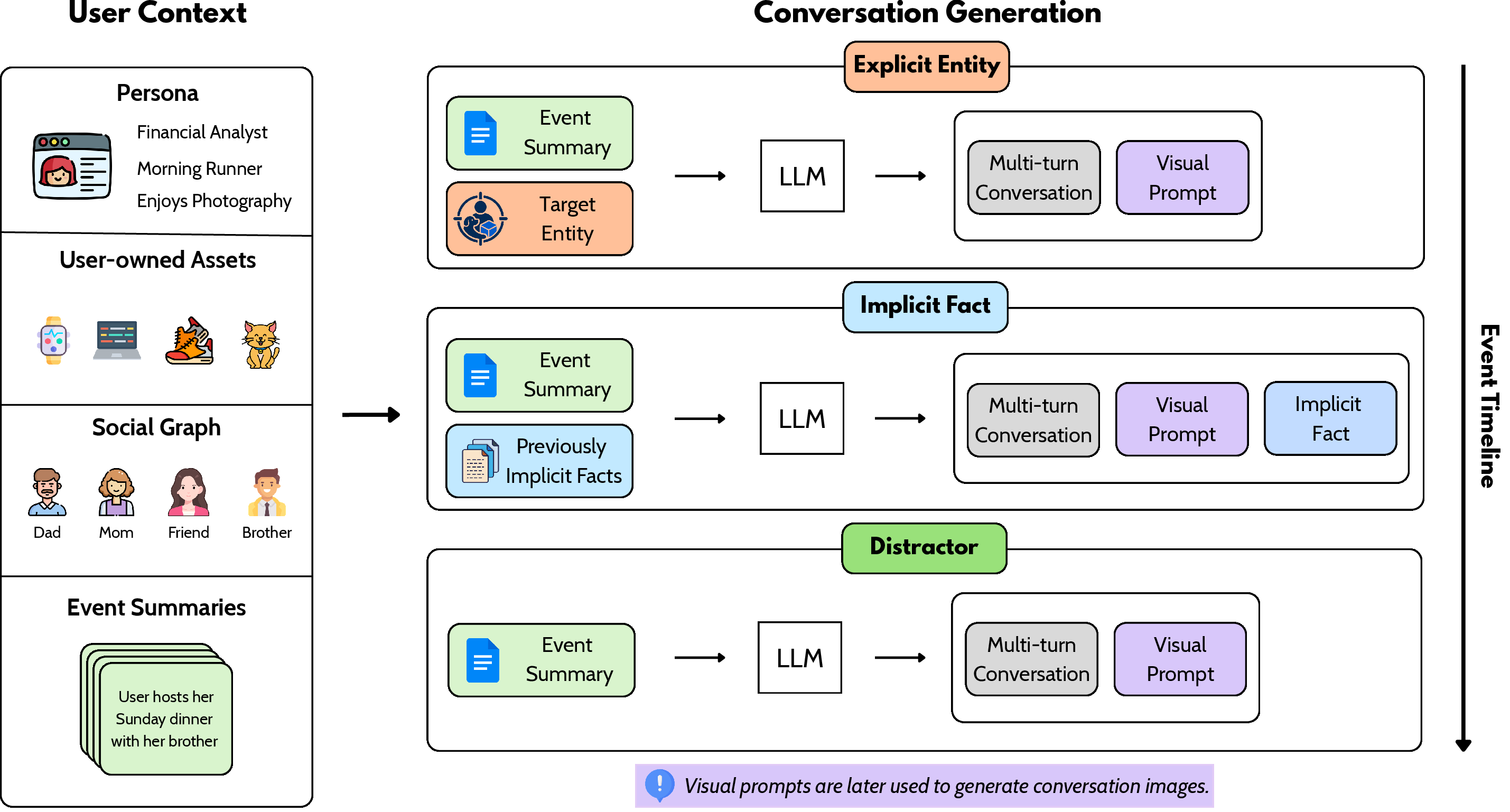
Figure 2: Multimodal conversation generation leverages persona-centric context to produce explicit entity, implicit fact, and distractor sequences.
To ensure global consistency and realistic visual identity, image synthesis employs reference conditioning for personalities and locations.
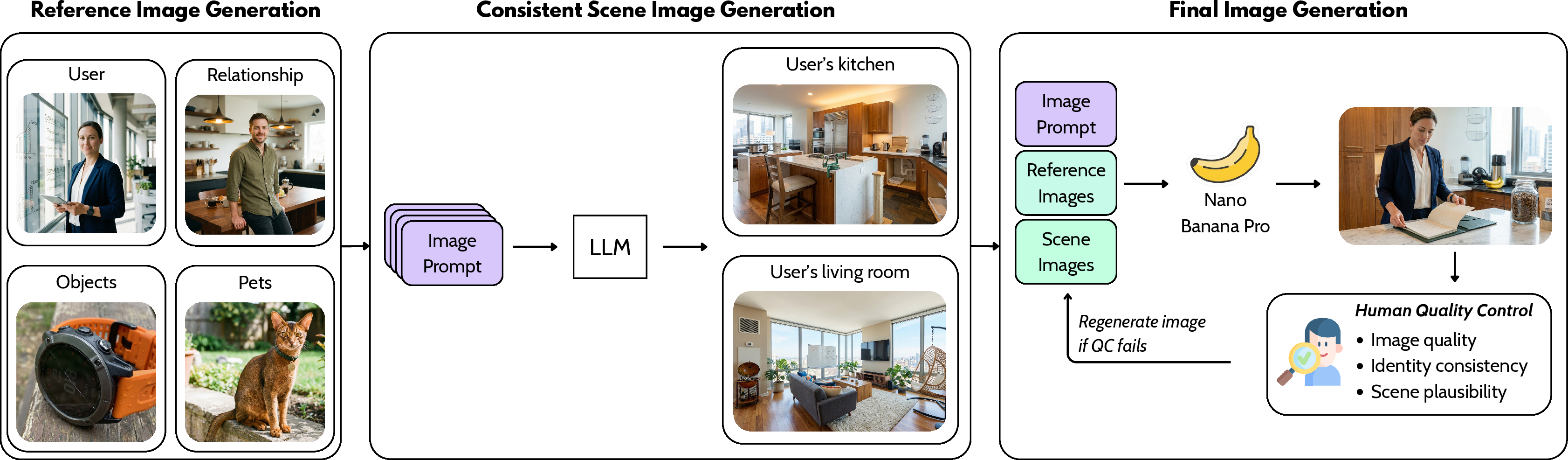
Figure 3: Image generation pipeline aligns reference entities and scene-level descriptors for coherent visual context across dialogue.
The resulting dataset contains 10 personas, >1700 events, ~700 evaluation questions, and >1700 images. Questions target either the identity of recurring visual entities (explicit memory) or personal facts inferable only via visual (or combined visual-text) evidence (implicit memory). Distractors and ambiguous ownership scenarios ensure high diagnosticity and robustness to spurious context associations.

Figure 4: Distribution of event modes and question types within the benchmark enables balanced evaluation.
The VisualMem Architecture
Standard memory systems reduce all image turns to text, erasing disambiguating visual evidence critical for personal long-term memory. VisualMem discards this paradigm, proposing a modular architecture that separates text and image memory processing and introduces structured, revisitable visual memory.
- Context-Guided Interpretation: At ingestion, each image is analyzed in conjunction with conversational context, enabling disambiguation of ownership, entity identity, and relevance. Explicit reasoning about personal linkage avoids erroneous premature extraction.
- Deferred Commitment: If evidence is insufficient, images are placed in a latent state, revisited when further context provides adequate resolution. This design is essential in realistic settings where visual facts are rarely isolated or immediately clear.
- Structured Extraction and Storage: Once disambiguation succeeds, information is extracted on three axes: relationships (social graph, ownership), entities (recurring people, assets), and facts (persistent user-specific attributes). Visual references are stored for future matching and retrieval; structured verbalized facts are also injected into the text memory backend.
- Query-Time Routing and Retrieval: At inference, VisualMem routes queries to the most relevant memory module, enabling entity-centric visual retrieval, fact-centric textual retrieval, or hybrid response construction.
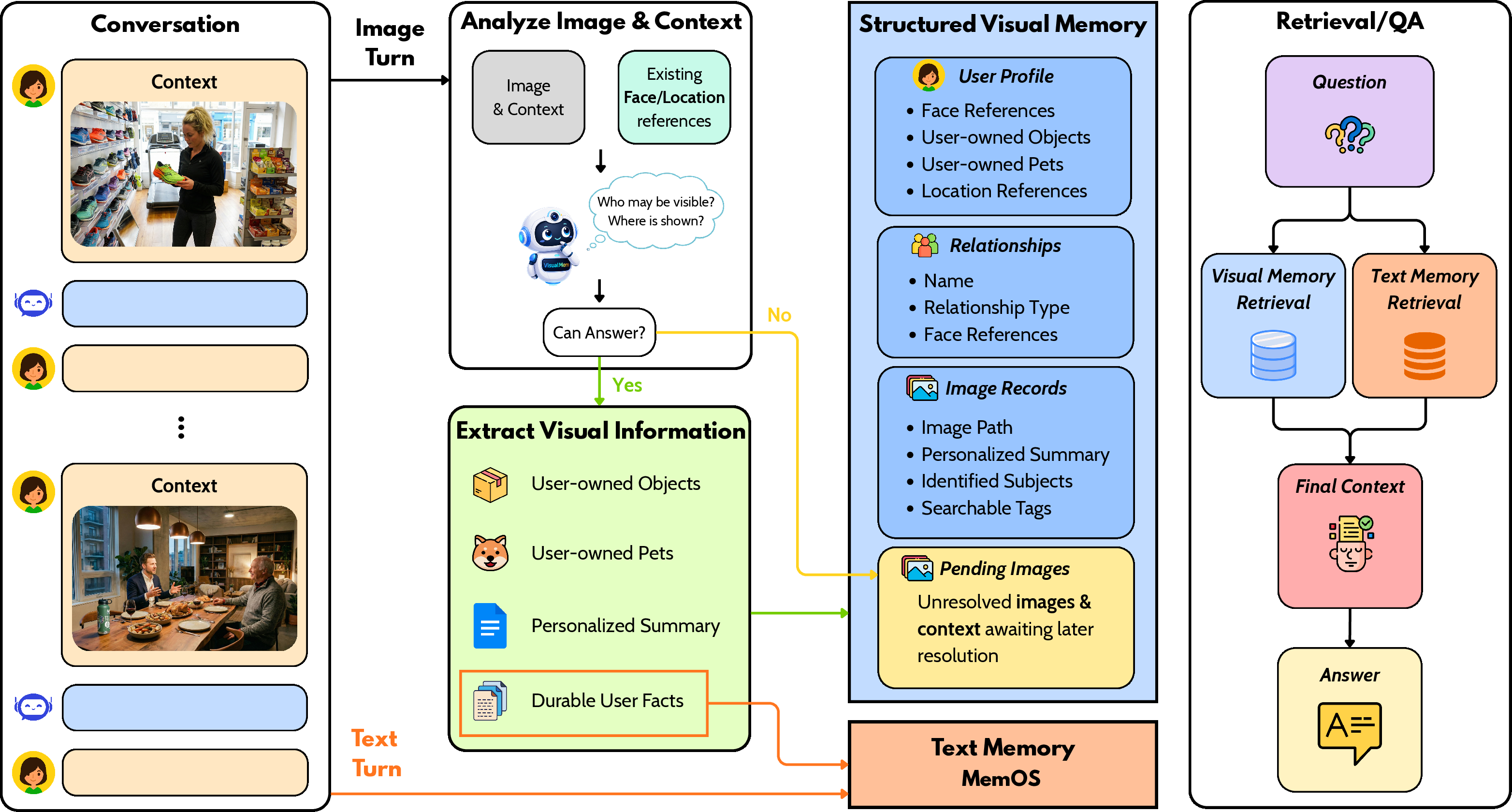
Figure 5: VisualMem processes multimodal context, incrementally accumulates structured visual memory, and enables hybrid retrieval for question answering.
Empirical Evaluation
Visual Memory Benchmark Results
VisualMem is benchmarked against full-history context, oracle access (gold supporting evidence), RAG systems (Self-RAG, HippoRAG2), and competitive memory-based methods (MemOS, Mem0, LightMem, SimpleMem).
- Reference settings: Full Context and Oracle demonstrate that gold evidence retrieval is non-trivial; naive models provided the full history cannot match Oracle.
- Practical systems: Standard text-oriented memory approaches (MemOS, SimpleMem, LightMem) yield low accuracies on explicit entity and implicit fact tasks, confirming significant information loss from caption-based image processing.
- VisualMem: Achieves overall accuracy of 84.1% (MemOS: 56.0%, best prior), with pronounced gains on Target Person (95.0%) and Target Asset (91.1%) categories. Performance also increases by substantial margins on implicit fact (visual-only and multimodal) settings, confirming that context-aware, structured visual memory is critical for these question types.
Text-Centric Benchmarks
On LOCOMO and PersonaMem (standard text-memory tasks), VisualMem remains competitive with MemOS, indicating no degradation of text-centric memory retention—a critical requirement for safe integration of structured visual modules into existing agent architectures.
Ablation Study
Ablations confirm that:
- Visual memory provides the largest performance boost on identity/ownership tasks, while combined visual+text memory offers best aggregate performance, especially for multimodal implicit facts.
- The deferred commitment mechanism is essential: bypassing it leads to increased error rates due to premature or spurious extractions.
- Wider conversational context windows further improve memory quality, especially in semantic-linking and fact inference tasks.
Implications and Future Research Directions
By demonstrating that visually grounded user-specific information is frequently irrecoverable from text-only representations, the paper raises critical concerns for both memory-benchmark design and downstream methods for AI personalization and user modeling. VisualMem establishes that meaningful long-term personalized memory for AI assistants requires more than surface-level captioning of visual inputs; it demands structured, context-aware, and persistently revisitable visual memory modules.
More broadly, this research exposes key open directions for AI system design:
- Data Collection and Privacy: The use of synthetic data sidesteps user privacy risks and annotation obstacles but limits ecological validity. Real-world deployment will require federated and privacy-preserving extensions.
- Robustness to Distribution Shift: Current benchmarks do not probe robustness across domains, data modalities, or under adversarial context drift.
- Dynamic Fact Evolution: Memory systems must handle dynamic, contradictory, or time-evolving visual facts without false permanence or catastrophic forgetting.
- Reasoning under Ambiguity: The deferred commitment strategy is a promising direction for managing uncertainty and ambiguity in human–AI interaction loops.
- Agentic Control: Users may require fine-grained visibility and control over what visual memories are retained, surfaced, or forgotten.
Conclusion
The VisualMem framework and benchmark provide compelling evidence that long-term personalized memory in AI assistants cannot be achieved by treating image data as auxiliary or reductively textual. Structured visual memory, tightly integrated and interoperable with text-centric memory backends, is necessary for capturing recurring user-specific facts, navigating implicit visual inference, and ensuring robust, personalized agent capabilities over extended interaction horizons. This work sets a clear direction for advancing the study of personalized multimodal memory and establishes a new baseline for future research in agentic AI memory integration.