- The paper proves that transformers trained with the Log-ICoT curriculum can internalize chain-of-thought reasoning while achieving sample-efficient learning on complex parity tasks.
- It introduces architectural innovations such as gated connections and level-restricted attention masks to overcome challenges like representation collapse and error compounding in multi-layer models.
- Empirical results on synthetic parity tasks confirm that the approach enables efficient one-pass inference with near-perfect accuracy by internalizing hierarchical computations.
Overview
The paper "Transformers Provably Learn to Internalize Chain-of-Thought" (2605.28600) presents a rigorous theoretical and empirical investigation into the internalization of chain-of-thought (CoT) reasoning within transformer models. The authors address the fundamental challenge of achieving sample-efficient, explicit reasoning in transformers without the computational overhead incurred by explicit generation of intermediate thinking steps at inference time. The paper introduces and theoretically analyzes the Log-ICoT curriculum, establishing that multi-layer transformers trained with this method can provably achieve the sample efficiency of explicit CoT while internalizing the reasoning process, enabling efficient inference.
Motivation and Context
Explicit CoT prompting facilitates transformer-based LLMs to solve complex reasoning tasks by decomposing problems into intermediate subtasks, enforceable via intermediate supervision. This improves sample efficiency, notably in parity learning tasks that are otherwise intractable for gradient-based methods without such supervision. However, explicit CoT incurs an Ω(k) sequential token generation cost at inference.
Implicit CoT (ICoT) addresses this efficiency bottleneck by training models to "internalize" intermediate reasoning steps into hidden representations through progressive removal of explicit thinking tokens during fine-tuning. While promising, the underlying learning mechanics and convergence properties for ICoT, especially in multi-layer architectures, were previously unproven theoretically.
Log-ICoT Curriculum and Training Paradigms
The Log-ICoT curriculum accelerates the internalization of reasoning steps by removing intermediate tokens in blocks corresponding to whole levels of the parity computation tree, rather than one token at a time. This reduces the number of training stages from linear (k−1) in standard ICoT to logarithmic (L=log2k):
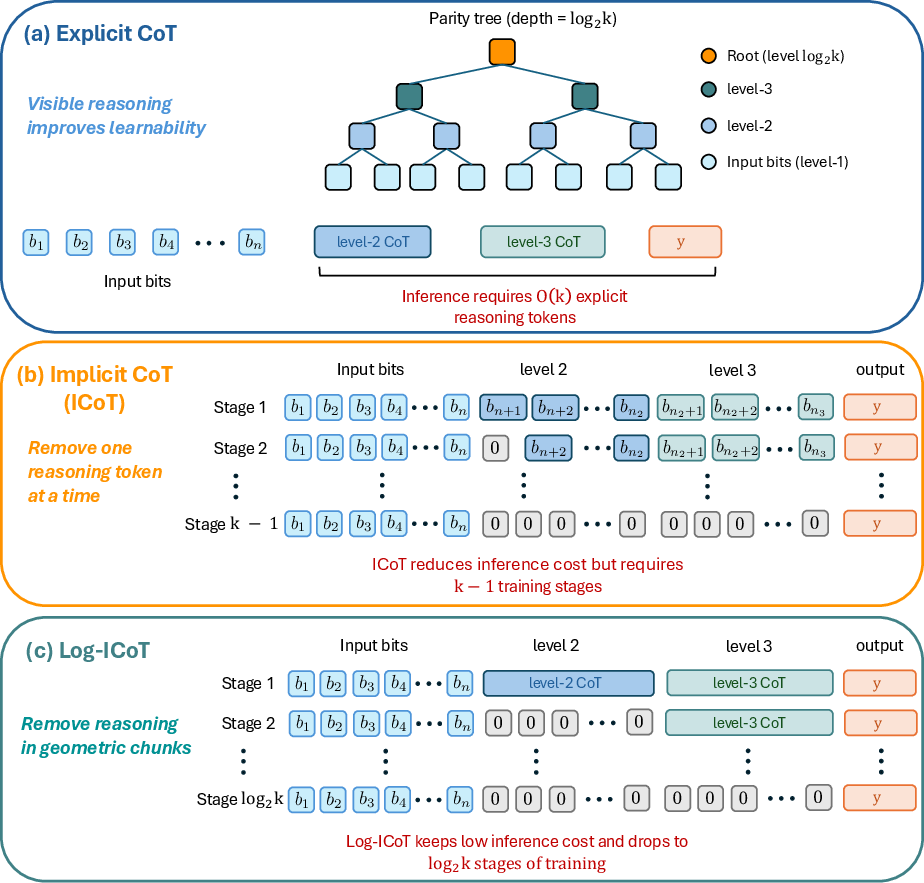
Figure 1: Training paradigm comparison on the k-parity task: (a) Explicit CoT supervises all parity nodes, (b) standard ICoT removes thinking tokens sequentially, (c) Log-ICoT removes them in geometric "chunks" by tree level, yielding logarithmic curriculum depth.
At each stage, the model is trained to predict only a subset of intermediate reasoning positions, with the remaining positions replaced by padding. This design supports the parallelization of hierarchical reasoning steps and enables the model to learn to compute the problem solution without explicit tokenized traces at inference—a single forward pass suffices.
Theoretical Results and Analysis
The main theoretical result is that an L-layer transformer, trained under the Log-ICoT curriculum with per-stage batch size B=Ω(n2+ϵ), learns the k-parity problem with polynomial sample complexity, matching that of explicit CoT, and internalizes all reasoning steps into hidden states. The final test error decays exponentially in n, guaranteeing high accuracy:
∥fθ^L(Dtest)T−ytest∥∞≤exp(−Ω(nϵ/16))
Overcoming Multi-layer Training Challenges
The analysis addresses two main challenges in multi-layer transformers:
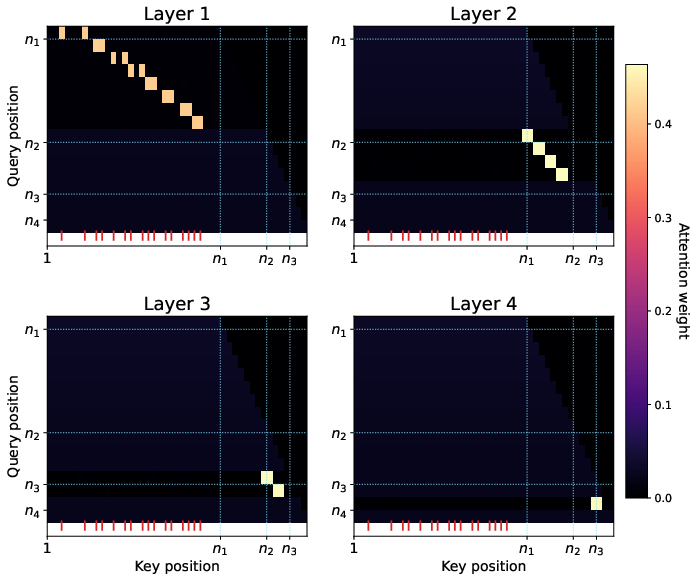
- Representation Collapse: Without careful design, higher layers suffer from loss of token-specific information due to uniform attention, leading to vanishing gradients. This is resolved using gated connections, which structurally constrain each transformer layer to operate only on its assigned tree level.
- Error Compounding: Accumulated errors across stages are controlled with a customized, level-restricted attention mask and integer quantization of attention weights, which "freezes" trained layers and limits error propagation.
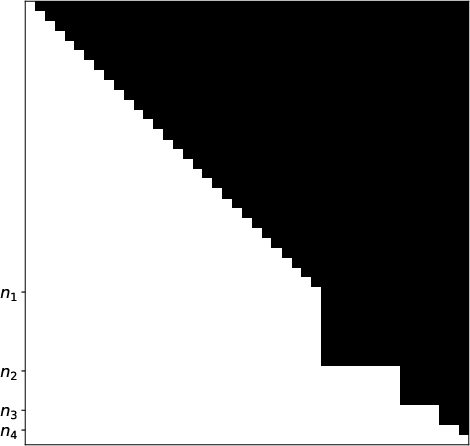
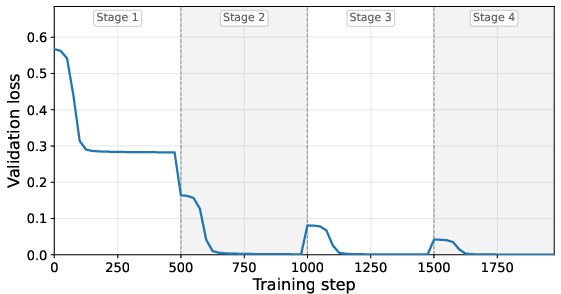
Figure 2: Left: Customized attention mask enforces strict level-wise dependency. Right: Validation loss evolution across curriculum stages; each stage's loss spike corresponds to the introduction of additional internalization requirements, followed by rapid convergence.
The curriculum's staged removal of explicit steps forces successive layers to learn computations corresponding to higher levels in the parity tree, which is validated theoretically via a convergence argument relying on concentration of measure and hierarchical gating.
Empirical Validation
Experiments are conducted on a synthetic parity task (n=30, k−10) with a 4-layer transformer. The key findings are:
Furthermore, the curriculum's geometric removal of steps is found to be essential for efficient and stable internalization, as opposed to the slower sequential step removal in standard ICoT.
Hierarchical Computation and Curriculum Progression
The hierarchical structure of the k−11-parity function naturally maps onto a binary tree, and the Log-ICoT curriculum mirrors this by removing reasoning steps in level-wise blocks. This results in parallel computation of all nodes at a given tree level—a process that is internalized within each corresponding transformer layer.
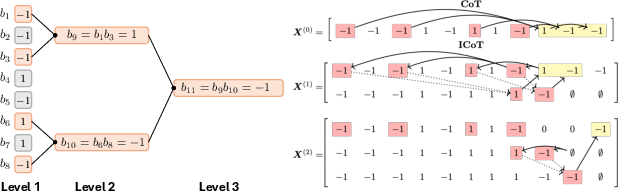
Figure 4: Left: Hierarchical decomposition of an k−12, k−13 parity task. Right: Comparison of standard CoT and ICoT training curricula; in ICoT, intermediate tokens are progressively replaced with padding and the model is forced to learn the required internal computation.
Implications and Future Directions
Theoretical advances in this work establish, for the first time, that transformers can learn to perform hierarchical reasoning without explicit intermediate token supervision at inference, as long as the right curriculum and architectural constraints are imposed. The results extend expressivity and learnability guarantees for parity learning from single-layer to multi-layer transformers.
Practically, this removes the linear inference-time cost of explicit CoT, rendering reasoning architectures more competitive for real-world deployment where low-latency is critical. The Log-ICoT approach could be adapted to other classes of hierarchical or compositional tasks where explicit reasoning traces are expensive or unavailable at test time.
Limitations include the reliance on a highly structured, synthetic testbed (parity functions), prescribed (non-learned) gating, and toy architectures. Extending these curriculums and analyses to more general reasoning domains, input-adaptive gating, and larger-scale models is a significant direction for future work. There is also rich potential for connection to self-distillation mechanisms and trajectory shortening observed in reinforcement learning and large-scale LLM training.
Conclusion
This paper rigorously demonstrates that multi-layer transformers can provably internalize chain-of-thought reasoning hierarchies, matching the sample efficiency of explicit intermediate supervision while eliminating inference overhead. The Log-ICoT curriculum achieves logarithmic curriculum depth and concurrent layer specialization, and the combination of architectural and algorithmic design guarantees stability and sample efficiency. These results advance the theoretical understanding of how modern transformer-based models can efficiently acquire and employ hierarchically structured reasoning without explicit trace generation at inference, and open avenues for practical improvements in efficient reasoning with deep neural architectures.