- The paper demonstrates how chain-of-thought enables Transformer forward passes to implement iterative batch TD learning for effective policy evaluation.
- It establishes geometric convergence rates under known dynamics and finite-sample guarantees with Markovian sampling.
- The analysis proves that in-context TD parameters become global minimizers under reinforcement pretraining, aligning theoretical principles with empirical outcomes.
Convergence and Emergence of In-Context Reinforcement Learning with Chain of Thought
Introduction and Context
The paper "Convergence and Emergence of In-Context Reinforcement Learning with Chain of Thought" (2605.07123) provides the first formal theoretical analysis of how autoregressive Chain-of-Thought (CoT) computation amplifies In-Context Reinforcement Learning (ICRL) in Transformers under reinforcement pretraining. ICRL refers to an agent's ability to adapt to new tasks solely by conditioning on context, without parameter updates at inference. While previous empirical findings had shown that CoT-style iterative reasoning significantly boosts this adaptation, rigorous theoretical explanations—especially in reinforcement-pretrained settings—were lacking. This work bridges that gap, focusing on the policy evaluation problem with linear function approximation and Transformers with linear self-attention.
Chain-of-Thought Generation as In-Context Temporal Difference Learning
The fundamental insight is that CoT generation in a linear Transformer layer, under suitable parameterization and structured prompting, can exactly implement iterated batch Temporal Difference (TD) learning updates. The forward pass, extended over the steps of CoT generation (rather than Transformer depth), recursively updates a candidate value function parameter according to the TD update formula, with each CoT step corresponding to another iteration of batch TD over the fixed context trajectory.
Concretely, by structuring the input prompt to encode states, actions, rewards, and the current iterate, and by imposing a block-sparse parameterization on the linear attention weights, the Transformer output on the final token realizes:
wk+1=wk+nαj=0∑n−1δk,jxj
with δk,j the sample TD error at the kth iterate, matching classical batch TD learning.
Theorem 1 in the paper rigorously proves the equivalence of the CoT-driven Transformer forward computation and the recursive TD update, for arbitrary k, given a fixed trajectory. This establishes that, under this setting, the Transformer forward pass is effectively a white-box implementation of TD learning, with each CoT step increasing the computation depth for in-context policy evaluation.
Convergence Analysis: Known and Unknown Dynamics
Geometric Convergence in the Population Setting
When the environment dynamics are known (i.e., the transition matrix is available and can be used in constructing the prompt), the TD recursion induced by the Transformer converges geometrically fast to the population TD fixed point in terms of Mean Squared Projected Bellman Error (MSPBE). Specifically, after k CoT steps, the error contracts exponentially in k:
L(wk)≤C(1−ημ)kL(w0)
where μ is the smallest eigenvalue of the (symmetrized) feature covariance under the stationary measure, and η the step size. Importantly, only O(log(1/ε)) CoT steps are required to achieve error δk,j0, for fixed step size.
Finite-Sample Convergence with Markovian Sampling
In the realistic case where dynamics are unknown and the agent conditions on a single finite Markovian trajectory (the standard ICRL setting), the paper quantifies both statistical and computational effects. Using advanced mixing and block-coupling arguments, it derives non-asymptotic bounds for the error after δk,j1 CoT steps:
δk,j2
where δk,j3 is a statistical floor determined by context length δk,j4 and feature dimension δk,j5, and δk,j6 are explicit constants depending on mixing, feature geometry, and step size. The error contracts geometrically in δk,j7 until it saturates at the finite-sample limit δk,j8, implying that additional CoT steps beyond this point yield no further reduction due to sample complexity constraints.
Reinforcement Pretraining and Emergence
The constructed parameterization that enables in-context TD in the Transformer is shown not only to be sufficient but also necessary in a strong optimization sense. Through analyzing pretraining with an empirical update-norm loss over a dataset of trajectories, the paper proves that the in-context TD parameters are global minimizers of the reinforcement pretraining objective. This establishes, for the first time, that such white-box algorithmic forward passes are actually favored under standard RL pretraining losses, supporting empirical findings that in-context algorithmic behavior emerges naturally during training.
Empirical Validation: Boyan’s Chain
Experiments in the canonical Boyan’s chain environment empirically confirm the theoretical predictions. The learned Transformer parameter matrices δk,j9 exhibit clear block patterns matching the analytical construction, and the in-context learning curves align with the predicted element-wise progress of TD learning.
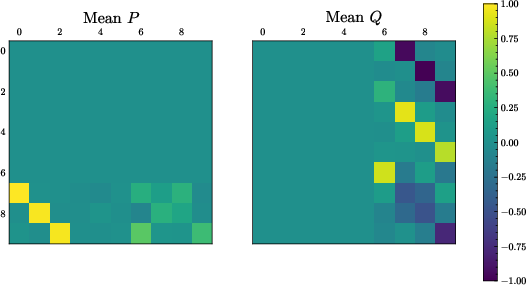
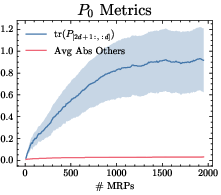
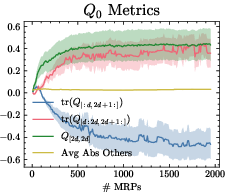
Figure 1: Block-sparse structure in learned Transformer parameters k0, with element-wise progress tracking the in-context TD update during CoT generation.
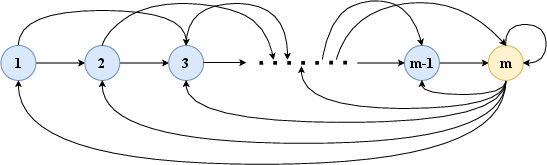
Figure 2: Boyan's chain topology, showing the structure of transitions in the experimental environment.
Implications and Future Directions
This paper makes the explicit claim that a linear attention Transformer of one layer, when equipped with autoregressive chain-of-thought prompting, implements batch TD learning in-context for policy evaluation. This goes further than prior works, which typically analyzed depth-unrolled computations or relied on supervised imitation of the underlying algorithm. By addressing the reinforcement-pretraining setting, the results indicate that ICRL with iterative reasoning has both an emergent algorithmic basis and log-computational depth amplification vis-à-vis CoT.
The provided finite-sample guarantees under single-trajectory Markovian context directly inform the design and evaluation of ICRL agents, highlighting both geometric improvement regimes and statistical precision floors. The global minimizer result for the pretraining loss aligns empirical algorithmic emergence with principled optimization theory. Theoretical tools established here—mixing-based concentration, structured prompt design, and iterative loss contraction—can potentially be leveraged for deeper investigations into more general in-context algorithms, nonlinear attention, and settings with partial observability, control, or exploration.
Conclusion
The paper rigorously establishes how Chain-of-Thought generation in a linear Transformer can amplify in-context TD learning under reinforcement pretraining, providing the first non-asymptotic convergence results for the policy evaluation task in this setting, and demonstrating the emergence of white-box algorithmic structure in trained parameter matrices. These insights clarify the computational role of iterative reasoning in ICRL and open the door to further exploration of in-context algorithm design, scaling, and theoretical guarantees in broader and more complex settings.