Barriers to Universal Reasoning With Transformers (And How to Overcome Them)
Abstract: Chain-of-Thought (CoT) has been shown to empirically improve Transformers' performance, and theoretically increase their expressivity to Turing completeness. However, whether Transformers can learn to generalize to CoT traces longer than those seen during training is understudied. We use recent theoretical frameworks for Transformer length generalization and find that -- under standard positional encodings and a finite alphabet -- Transformers with CoT cannot solve problems beyond $TC0$, i.e. the expressivity benefits do not hold under the stricter requirement of length-generalizable learnability. However, if we allow the vocabulary to grow with problem size, we attain a length-generalizable simulation of Turing machines where the CoT trace length is linear in the simulated runtime up to a constant. Our construction overcomes two core obstacles to reliable length generalization: repeated copying and last-occurrence retrieval. We assign each tape position a unique signpost token, and log only value changes to enable recovery of the current tape symbol through counts circumventing both barriers. Further, we empirically show that the use of such signpost tokens and value change encodings provide actionable guidance to improve length generalization on hard problems.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Barriers to Universal Reasoning With Transformers (And How to Overcome Them)”
1. What is this paper about?
This paper studies how Transformer models (the kind of AI behind many chatbots) “think out loud” using Chain-of-Thought (CoT) and whether they can learn to solve longer, harder problems than the ones they were trained on. The authors show that just adding CoT isn’t enough to guarantee good performance on longer problems. Then, they propose a new way to format inputs and the model’s “thinking steps” that makes Transformers much better at handling longer tasks.
2. What questions did the researchers ask?
The paper focuses on three simple questions:
- Does “thinking out loud” (CoT) help Transformers reliably solve much longer problems than they’ve seen during training?
- If not, what exactly blocks them from generalizing to longer lengths?
- Can we design a better input and CoT format so Transformers learn rules that work on longer problems, and can we prove this?
3. How did they study it? (Methods explained simply)
Think of a Transformer as a very fast text robot. Chain-of-Thought (CoT) is like asking the robot to show all the steps it takes before giving a final answer, similar to showing your work in math class.
The researchers looked at “length generalization,” which means: if you train the robot on short problems, can it still solve much longer ones correctly? They used two theory tools to reason about this:
- C-RASP: Imagine a simple set of local rules the robot can follow, like “look at nearby tokens,” “count,” or “compare small patterns.” If a task fits into these local rules, it’s more likely the robot can learn it in a way that scales to longer inputs.
- C*-RASP (pronounced “C-star-RASP”): This extends the rule set to allow using an unlimited supply of special labels when needed. It’s like giving the robot as many sticky notes with unique numbers as it wants.
They also talk about “positional encodings,” which is how the robot knows the order of tokens (like page numbers or line numbers). And they discuss “finite alphabet” vs. “infinite alphabet”:
- Finite alphabet: The robot can only use a fixed set of tokens (like a small dictionary).
- Infinite alphabet: The robot is allowed to use new numbered labels as problems get bigger (like having endless numbered sticky notes).
Two big obstacles the robot faces when problems get longer:
- Repeated copying: It’s hard to reliably copy the same thing many times in different places as inputs grow.
- Last-occurrence retrieval: It’s hard to find the most recent change to a value when there are many changes scattered around.
To beat these obstacles, the authors propose:
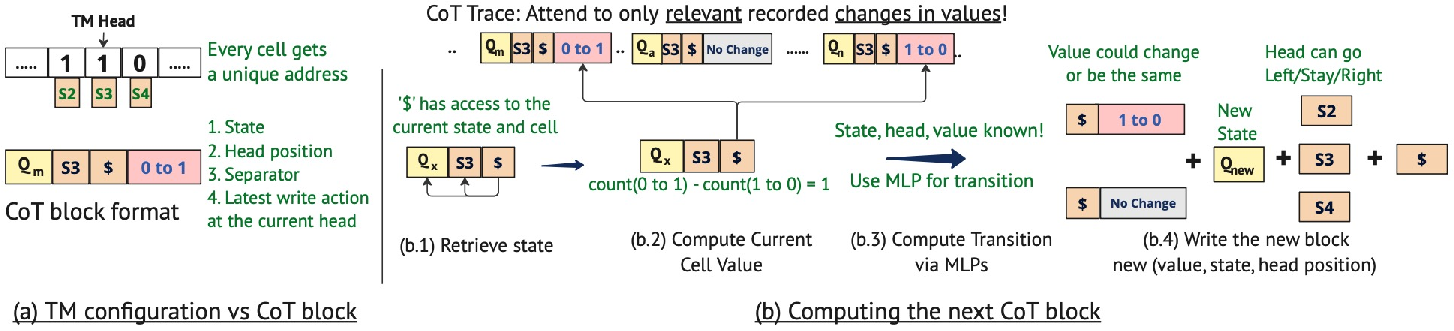
- Signpost tokens: Give every position a unique label (like house numbers on a street). This makes it easy to point to exactly the right place, no matter how long the street gets.
- Value-change logging: Instead of writing the entire state over and over, only record when a value actually changes (like keeping a simple change log: “cell A: 0 → 1”). Then, to recover the current value, just look at the most recent change for that cell.
They prove (using the C*-RASP rules) that if you give the model these signposts and value-change logs, it can simulate any step-by-step algorithm (like a Turing machine), and the number of CoT steps grows in a nice, predictable way with problem size.
They also run experiments:
- Training small Transformers from scratch on tasks like parity (is the count of 1s even?), evaluating logical formulas, and tracking permutations (S5).
- Prompting existing LLMs with examples that include signposts or value-change comments, to see if performance improves without retraining.
4. What did they find and why it matters?
Here are the main results:
- Under a fixed vocabulary and standard positional encodings, CoT alone does not guarantee strong length generalization. In simple terms, even if the model “shows its work,” it can still fail badly on longer problems. The authors show a formal barrier: tasks that are too complex won’t become learnable at longer lengths just because you add CoT.
- With a growing vocabulary (the “infinite alphabet”) and the right formatting—unique signpost tokens and value-change logging—the model can learn local rules that scale. In fact, they prove the model can simulate any step-by-step algorithm (Turing machine) with CoT traces whose length grows roughly in proportion to the time the algorithm takes. This is a strong guarantee.
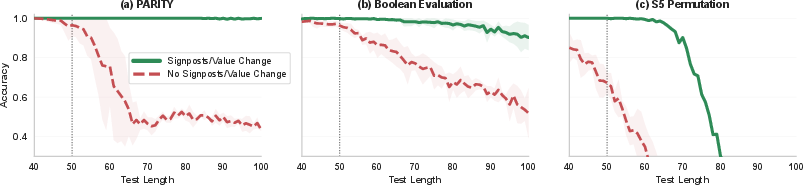
- Experiments confirm the theory. On parity, Boolean formula evaluation, and permutation tracking:
- Value-change formatting makes parity generalize reliably to much longer inputs.
- Signpost tokens greatly improve generalization on the harder tasks (Boolean and S5), compared to standard CoT formatting.
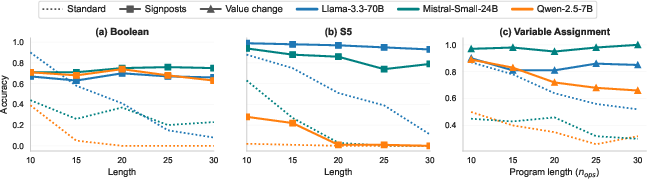
- Prompting real LLMs with signpost-like markers or code comments that log value changes improves performance out-of-the-box, especially as inputs get longer. This suggests better CoT and input design can help even without retraining.
Why this matters: It shows that “how you format the model’s thoughts” is crucial. Not all CoT is equal—some formats the model can learn in a way that scales; others break down.
5. Why does this matter? (Impact)
This work gives practical and theoretical guidance on making Transformers better at reasoning:
- Don’t rely on CoT alone. If you want your model to handle longer tasks, structure the input and the CoT with unique labels (signposts) and record only changes (value-change logs).
- These ideas can guide how we write prompts, create training data, or even design new curricula for models. For example, adding index hints (numbers or markers) and explicit change logs can make models more reliable on longer problems.
- In the big picture, the paper explains why models often struggle when problems get longer and offers a concrete fix that works in theory and practice. This can lead to better reasoning abilities in future AI systems, more robust tools for planning and logic, and improved performance on complex, multi-step tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to enable concrete follow-up work:
- Dependence on idealized learning models
- Bridge from -RASP/-RASP’s idealized, translation-invariant/local learning assumptions to standard training pipelines (finite precision, SGD, regularizers) is not established; quantify when practical training recovers the same “limit transformer.”
- Provide sample-complexity and data-coverage guarantees (how many lengths and offset configurations are needed) to realize the theoretical generalization in practice.
- Scope of the barrier under finite alphabets
- Tightness: Is the “CoT-in-Pos ⇒ language in ” result tight? Characterize the largest class of tasks/formats over a fixed finite alphabet that are length-generalizable (necessary and sufficient conditions).
- Explore whether alternative CoT formats over a finite alphabet (e.g., richer delimiters, multi-pass traces, structured encodings) can enlarge the learnable class beyond current bounds.
- Practicality and scalability of infinite-alphabet constructions
- Tokenization constraints: Systematically study how to realize “signpost tokens” with subword tokenizers (BPE/Unigram) at scale and how segmentation variability affects generalization.
- Embedding-space extrapolation: Test whether models reliably handle unseen signpost IDs at longer lengths (embedding initialization, sharing, or learned functions of IDs).
- Compute/memory costs: Quantify inference/training overhead from signposts and value-change logging at 5–10× train lengths; assess trade-offs with context window limits.
- Robustness: Analyze tolerance to missing, duplicated, or corrupted signpost tokens and to noisy or imperfect value-change logs; propose error correction or redundancy schemes.
- Constants and efficiency of the TM simulation
- Make explicit and measure the constant in the CoT-length bound; study how depends on depth, heads, width, and attention patterns.
- Evaluate overhead for multi-tape machines and for tasks requiring frequent random access or long-range dependencies; compare with alternative encodings (e.g., balanced trees, skip-lists).
- Generality of the proposed formatting principles
- Beyond three synthetic tasks: Test signposts/value-change on broader settings (long-form math, program execution with control flow, multi-step logical proofs, planning, graph algorithms).
- Identify when value-change vs. full-state logging is preferable; provide criteria to choose formats by task structure (e.g., sparse vs. dense updates, commutativity).
- Develop task-agnostic guidelines or an automated pipeline to synthesize -RASP/-RASP-compliant CoT formats from high-level task specifications.
- Interaction with positional encodings and architectures
- The learning guarantees are framed for NoPE/APE (with a link from RoPE/ALiBi to Pos expressibility), but empirical validation under RoPE/ALiBi and other modern PEs is limited; test whether results hold with these and learned relative PEs.
- Examine whether architectural variants (e.g., recurrence, external memory, key–value compression, retrieval augmentation, pointer networks) mitigate copying/last-occurrence barriers without growing the alphabet.
- Determinism vs. stochasticity in CoT generation
- The formalism assumes a deterministic next-token map; real models are stochastic and trained with cross-entropy. Analyze how sampling, beam search, or temperature affect the reliability of long CoTs under the proposed formats.
- Investigate mechanisms for self-correction (verification, re-computation) when occasional token errors accumulate in value counts.
- Learning to create vs. consume signposts
- Current construction assumes externally provided signposts. Can models learn to generate and maintain consistent signposts autonomously (including re-synchronization after errors)?
- Study whether pretraining can induce “implicit signposting” or pointer-like internal representations that unlock similar generalization without explicit markers.
- Pretraining and data mixture design
- Evaluate whether injecting signpost/value-change patterns into pretraining corpora improves downstream length generalization; identify the fraction and diversity of such data needed.
- Measure side effects on instruction-following, style fidelity, and natural text generation when models are exposed to structured CoT formats during pretraining or finetuning.
- Robustness to distribution shifts beyond length
- Test sensitivity to shifts in symbol frequencies, operation orderings, variable renamings, and adversarial perturbations (e.g., extra distractor tokens) with and without signposts/value-change logs.
- Explore compositional OOD generalization: can the same formats handle new symbol sets, unseen operation primitives, or longer/nested structures?
- Formal and empirical coverage boundaries
- Identify tasks that still fail to generalize under naive CoT to refine the practical boundary between “expressible” and “learnably generalizable”; map failures to missing -RASP primitives.
- Provide lower bounds or impossibility results for specific CoT formats (finite alphabet) to delineate when reformatting alone cannot help.
- Extending beyond text-only settings
- Generalize signpost/value-change ideas to multimodal inputs (tables, graphs, images), where indices/signals might be spatial or structural rather than sequential.
- Adapt the framework to bidirectional encoders or encoder–decoder architectures and to non-autoregressive generation.
- Evaluation scale and reproducibility
- Current experiments use small GPT-2 models, short lengths (up to 2×), and limited tasks. Conduct large-scale studies with bigger models, longer contexts (5–10×), and ablations across depths/heads.
- Provide systematic ablations on the number of in-context examples, decoding strategies, and prompt length budgets for LLM prompting results.
- Safety and usability considerations
- Study human factors and downstream constraints: do verbose signpost/value-change traces harm readability, latency, or cost? Explore compressed or hierarchical signposting to balance interpretability and efficiency.
- Automating CoT format discovery
- Develop program synthesis or neuro-symbolic tools that search over CoT formats to find -RASP/-RASP-compatible solutions for new tasks, with formal verification of length generalization.
Practical Applications
Practical Applications of “Barriers to Universal Reasoning With Transformers (And How to Overcome Them)”
This paper establishes two main insights with direct practical relevance: (1) under standard positional encodings and a fixed finite alphabet, transformers with Chain-of-Thought (CoT) do not provably length-generalize on problems beyond low circuit classes; (2) introducing signpost tokens (unique position markers) and value-change (delta) logging enables length-generalizable reasoning up to Turing-complete simulations under an expanding alphabet, and yields empirical gains on hard tasks. Below are actionable applications grouped by deployment horizon.
Immediate Applications
The following can be adopted today via prompt design, data formatting, training recipes, and evaluation practices.
- Signpost-based prompt templates to stabilize long-horizon reasoning
- Use case: Insert explicit, unique index markers (e.g., “1:, 2:, …” or section IDs) across inputs and CoT steps to reference positions/entities reliably.
- Sectors:
- Software (code agents, test generation, static analysis)
- Education (math proofs, logic, tutoring)
- Finance (ledger tracing, audit queries)
- Legal/Support/Knowledge management (RAG pipelines with citation IDs)
- Tools/workflows:
- “Signpost Prompt Library” that injects numeric indices per step/entity
- RAG pipelines that attach and preserve unique doc/paragraph IDs in both retrieval and CoT
- Assumptions/dependencies:
- The model follows instructions and does not conflate signposts with task tokens
- Slight increase in token count and context budget
- Value-change (delta) logging to improve state tracking
- Use case: Ask models to log only state changes (e.g., “x: 3 → 7”), not full state snapshots, to recover current state by counting the latest value assignment.
- Sectors:
- Software/DevOps (debugging, code review, program analysis)
- Robotics/Planning (state updates per step instead of full states)
- Operations/Manufacturing (inventory changes)
- Healthcare (EHR event summaries, medication changes)
- Tools/workflows:
- “Delta Log Formatter” for prompts (automatic comment insertion for code)
- CI plug-ins that annotate diffs with variable/state deltas for LLM reviewers
- Assumptions/dependencies:
- Value-change annotations must be accurate and consistent
- Additional tokens may increase latency/cost
- Training small/medium task-specific transformers with signposts and offset tricks
- Use case: For in-house models, incorporate unique signpost tokens and random position/signpost offsets during training to promote length generalization.
- Sectors:
- Software tooling startups, automation, robotics
- Tools/workflows:
- Tokenizer augmentation for signpost families
- Training scripts that randomize absolute positions and signpost offsets (as in the paper’s recipe)
- Assumptions/dependencies:
- Control over tokenizer and training data
- Sufficient compute for fine-tuning and synthetic data generation
- Length-generalization evaluation as a standard QA practice
- Use case: Establish evaluation suites that test performance beyond training lengths (e.g., parity, Boolean evaluation, S5) with and without signposts/deltas.
- Sectors:
- MLOps, AI governance, procurement, academia
- Tools/workflows:
- “Length Generalization Benchmarks” with configurable train/test length gaps
- Reporting templates documenting CoT format and positional encoding strategy
- Assumptions/dependencies:
- Budget for OOD testing and monitoring
- Clear acceptance thresholds per application domain
- Enterprise logging and data-design patterns for AI consumption
- Use case: Redesign logs as “event-sourced” streams with unique identifiers (signposts) and delta entries to ease AI analysis over long histories.
- Sectors:
- Finance (transaction/audit trails)
- Healthcare (EHR timelines)
- Cybersecurity (alert streams), Manufacturing (sensor events)
- Tools/workflows:
- ETL transforms that normalize events to [entity-ID, time, delta] tuples
- Data schemas that preserve stable, unique references end-to-end
- Assumptions/dependencies:
- Coordination with data engineering teams
- Backward-compatible schema evolution
- Structured planning outputs with step IDs and deltas
- Use case: Require planners and agents to produce plans with step indices and only the changes to world state per step.
- Sectors:
- Robotics, logistics, multi-step tools/agents
- Tools/workflows:
- Planner wrappers that enforce position-tagged and delta-only outputs
- Assumptions/dependencies:
- Integration with existing action schemas and simulators
- Validation of step consistency
- Education and tutoring content design
- Use case: Encourage students and LLM tutors to use indexed steps and delta notes (e.g., in algebraic manipulations or logic proofs) to scale reasoning to longer problems.
- Sectors:
- Education, EdTech
- Tools/workflows:
- Worksheets and LMS templates with signposted steps; grading rubrics that reward delta-based reasoning
- Assumptions/dependencies:
- Instructor adoption and training
- Alignment with curriculum standards
- Model selection and procurement criteria
- Use case: Require vendors to demonstrate performance under length-generalization tests and specify CoT formatting assumptions (e.g., with/without signposts).
- Sectors:
- Public sector procurement, regulated industries
- Tools/workflows:
- RFP language and audit checklists referencing length OOD benchmarks and CoT format constraints
- Assumptions/dependencies:
- Organizational readiness to evaluate and enforce criteria
- Availability of transparent evaluation results
Long-Term Applications
These opportunities require further research, scaling, or ecosystem changes to fully realize.
- Pretraining recipes that bake in signposts and delta-logged corpora
- Vision: Create pretraining mixtures containing signposted documents and datasets with explicit value-change annotations to improve length robustness out-of-the-box.
- Sectors: Foundation model labs, platform providers
- Dependencies:
- Curated corpora with high-quality identifiers and delta logs
- Validation that gains persist across broad tasks and token budgets
- Tokenizer and vocabulary design for “signpost families”
- Vision: Introduce dedicated token families and embeddings for position/entity signposts to support near-infinite indexing while minimizing collisions.
- Sectors: Model architecture and NLP tooling
- Dependencies:
- Compatibility with existing tokenization pipelines
- Backward compatibility for model upgrades
- Architecture modules with index-aware attention and matching primitives
- Vision: Embed RASP-like local matching and relative-index primitives directly into attention layers to natively support signpost/delta reasoning.
- Sectors: AI research, robotics, planning
- Dependencies:
- Stable training dynamics for new inductive biases
- Benchmarks to quantify benefits vs. standard attention
- TM-style CoT execution engines for reliable long reasoning
- Vision: Hybrid systems that offload long-horizon reasoning to a CoT executor implementing value-change logs and signpost addressing (meta-execution with verifiable traces).
- Sectors: High-stakes decision support (finance risk, compliance, safety-critical tooling)
- Dependencies:
- Latency/performance optimization
- Tooling for trace verification and human oversight
- Industry and regulatory standards for AI-friendly logging
- Vision: Standards (e.g., EHR/FHIR extensions, audit log schemas) mandating unique IDs and delta semantics to facilitate AI analysis and traceability.
- Sectors: Healthcare, finance, government
- Dependencies:
- Multi-stakeholder consensus and standard bodies’ adoption
- Privacy and compliance considerations
- Safety and reliability certifications emphasizing length generalization
- Vision: Certification frameworks that test and certify models’ length generalization under specified CoT formats and positional encoding regimes.
- Sectors: Regulatory, safety-critical industries
- Dependencies:
- Accepted test suites and pass/fail criteria
- Third-party evaluation capacity
- Auto-formatting middleware for CoT and inputs
- Vision: Middleware that rewrites user inputs and model outputs to add/remove signposts and compress traces into delta logs automatically, balancing performance and token cost.
- Sectors: Enterprise LLM platforms, MLOps
- Dependencies:
- Robust prompt/response transformation without semantic drift
- Monitoring for instruction adherence
- Curriculum learning and distillation from C*-RASP-generated traces
- Vision: Generate large-scale, theory-aligned traces (signposts + deltas) to distill into student models that generalize to much longer contexts.
- Sectors: Model training pipelines, education technology
- Dependencies:
- Scalable data generation and compute
- Demonstrated transfer to real-world tasks
- Benchmark suites and leaderboards for “format-aware” generalization
- Vision: Community benchmarks that compare naive vs. signpost/delta formats across algorithmic and real-world tasks, tracking length scaling laws.
- Sectors: Academia, open-source communities
- Dependencies:
- Broad adoption and reproducibility infrastructure
- Task diversity beyond synthetic problems
- Multi-agent and distributed protocols with unique IDs and delta updates
- Vision: Communication protocols for agent swarms or services using message IDs and state deltas to sustain long-horizon coordination and reduce error accumulation.
- Sectors: Distributed systems, autonomous robotics, supply-chain orchestration
- Dependencies:
- Protocol design and interoperability
- Fault tolerance and recovery strategies
Notes on Feasibility and Assumptions
- The strongest theoretical guarantees rely on an “expanding alphabet” (infinite signposts) and idealized learning models; practical deployments approximate this with numeric indices or token families and randomized offsets.
- Gains are sensitive to formatting. Signposts must be unique and consistently used; delta logs must be accurate. Poorly implemented formats can degrade performance.
- Token budget and latency trade-offs matter; signposts and deltas increase context length.
- Some tasks (e.g., complex permutation tracking) remain challenging and may require additional techniques or fine-tuning.
- For regulated settings, evaluation and documentation of CoT formats and length-generalization behavior should be part of risk management.
By integrating signpost tokens and value-change logging into prompts, data pipelines, training regimens, and evaluation standards, organizations can materially improve the robustness of LLM reasoning at longer horizons today while laying the groundwork for architectures and standards that deliver stronger guarantees in the future.
Glossary
- Absolute Positional Encodings (APE): A scheme that assigns each absolute position in a sequence a learned embedding to convey positional information to the model. "give length generalization guarantees for Transformers with No Positional Encodings (NoPE) and Absolute Positional Encodings (APE) respectively"
- AliBi: A positional encoding method that adds a linear bias to attention scores to encode relative positions without explicit embeddings. "RoPE/AliBi transformers can be expressed in "
- Annotate(w): A preprocessing function that interleaves each input token with a unique signpost symbol from an infinite alphabet to enable indexing. ""
- Autoregressive CoT generation: Producing the chain-of-thought and answers token by token, where each next token depends on the previously generated prefix. "We therefore introduce a corresponding autoregressive formalization of CoT"
- Boolean formula evaluation: The problem of computing the truth value of a propositional logic formula (with no variables to assign), known to be challenging for constant-depth circuits. "Boolean formula evaluation (evaluating the truth value of a propositional logic formula without variables)"
- C*-RASP: An extension of C-RASP that supports an unbounded alphabet and relational matching, enabling guaranteed length generalization in broader settings. "There is a CoT -RASP program computing it."
- C-RASP (Counting-RASP): A formal language for specifying algorithms that softmax transformers can implement, emphasizing counting and selection operations for length generalization analysis. "Counting-RASP introduced by \citet{yang2024counting} has become the standard formalism to study the abilties of decoder-only softmax transformers."
- Chain-of-Thought (CoT): Generating explicit intermediate reasoning steps before producing the final answer to improve performance and expressivity. "Chain-of-Thought (CoT) has been shown to empirically improve Transformers' performance"
- decoder-only transformer: A transformer architecture that predicts the next token using only leftward (causal) context. "We model a decoder-only transformer as a length-preserving map "
- idealized learning model: A theoretical framework for training where constraints like locality and translation invariance ensure convergence to length-generalizable solutions. "could be used to give length generalization guarantees for Transformers with No Positional Encodings (NoPE) and Absolute Positional Encodings (APE) respectively, under an idealized learning model."
- index hints: Explicit position markers introduced into inputs or CoT traces to facilitate copying and retrieval operations and improve generalization. "the idea of index hints \citep{nogueira2021investigating, bueno-etal-2022-induced, zhou2024algorithms, ebrahimi2024your} being used across the input and CoT to help in generalization"
- length generalization: The ability of a model to extend the learned algorithm from shorter training sequences to longer test sequences. "improve length generalization across tasks"
- local match predicate: A primitive that compares symbols from an unbounded alphabet based on relational equality, without memorizing their absolute identities. "Its key new primitive is a local match predicate, which allowed the program to compare symbols from relationally without memorizing their absolute identities."
- locality: A constraint that model interactions decay beyond a bounded neighborhood, promoting learnable, length-generalizable algorithms. "and locality (beyond a threshold such interactions should vanish)."
- next-token map: A deterministic function mapping any given prefix to the next token to be generated in an autoregressive process. "both transformers and CoT C-RASP programs induce a deterministic next-token map "
- No Positional Encodings (NoPE): A transformer setup that omits explicit positional information, relying on other mechanisms or invariances. "give length generalization guarantees for Transformers with No Positional Encodings (NoPE) and Absolute Positional Encodings (APE) respectively"
- Out-of-distribution (OOD): Inputs or conditions at test time that differ from those seen in training, such as longer sequences or different formats. "fragile in out-of-distribution settings"
- Pos: A C-RASP variant augmented with positional primitives (sometimes called periodic) used to reason about models with absolute/structured position signals. "its variant with some positional primitives {Pos}"
- RoPE (Rotary Positional Encodings): A positional encoding technique that applies rotations in embedding space to encode relative position information. "RoPE/AliBi transformers can be expressed in "
- S5 permutation-product problems: Tasks involving compositions of permutations from the symmetric group S5, used to test algorithmic tracking of object order. " permutation-product problems (tracking order of objects after a series of permutations)"
- semi-computable function: A function for which a Turing machine enumerates outputs when defined but may not halt on inputs where it is undefined. "Let be a semi-computable function computed by a Turing machine ."
- signpost tokens: Unique identifiers inserted alongside tokens (e.g., per tape cell) to enable precise addressing, copying, and retrieval. "We assign each tape position a unique signpost token"
- split alphabet: A representation that separates a finite symbol set from an unbounded one to enable scalable indexing and matching. "uses a split alphabet "
- translation invariance: A requirement that interactions depend on relative rather than absolute positions or identities, aiding generalization. "translation invariance (interactions between parameters should depend only on relative differences between positions and alphabets)"
- Turing completeness: The capacity of a system to simulate any Turing machine computation, implying maximal expressivity. "theoretically increase their expressivity to Turing completeness."
- unbounded alphabet: An infinite set of symbols available to models/programs for indexing or tagging, beyond a fixed vocabulary. "which acts as an unbounded alphabet"
- value-change encoding: A logging strategy that records only changes to values (e.g., tape cell updates) so current state can be reconstructed via counts. "The technical key is a value-change encoding of the TM run"
Collections
Sign up for free to add this paper to one or more collections.