- The paper shows that VLMs excel in semantic tagging and instance grouping, while VGMs outperform in geometry-centric tasks.
- It employs a unified probing framework—semantic tagging, instance grouping, and 3D geometry prediction—to ensure fair evaluation across models.
- A simple fusion of VLM and VGM representations enhances both semantic and geometric performance, underscoring the complementarity of these paradigms.
Empirical Evaluation of VLMs and VGMs for Spatial Intelligence: A Probing-Based Perspective
Introduction
Spatial intelligence in visual systems entails the capacity to extract and utilize both semantic object information and geometric structure from visual observations. The emergence of large Vision-LLMs (VLMs), pretrained with language-visual correspondences, and Video Generation Models (VGMs), trained with frame prediction and generation objectives, has driven widespread adoption of these architectures as foundation backbones in embodied AI, robotics, scene understanding, and autonomous driving. However, existing evaluations of these paradigms conflate perception, action, and downstream fine-tuning. This work presents a rigorous, controlled comparison of frozen VLM and VGM visual representations, using lightweight probes across the axes of semantic tagging, instance grouping, and 3D geometry prediction, to disentangle the spatial information already resident in each paradigm (2605.28132).
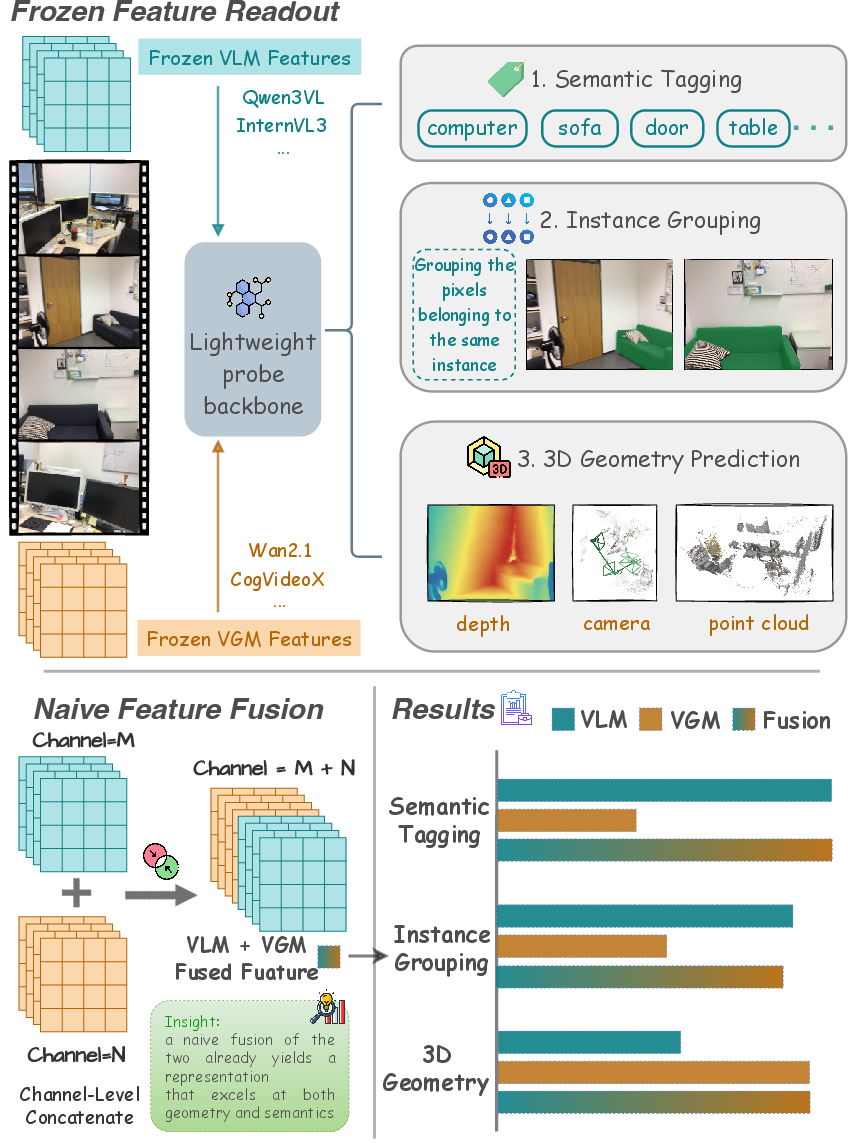
Figure 1: Probing study shows VLMs excel at semantics and instances, VGMs at geometry, and simple feature fusion combines both strengths, highlighting complementarity.
Methodology
The probing framework consists of three main tasks: (A) semantic tagging—video-level object category recognition; (B) instance grouping—multi-view consistent object instance segmentation; and (C) 3D geometry—dense 3D structure and camera pose prediction. For each, the foundation model is frozen, temporally aligned video features are extracted (76-frame context, 20-frame bank), and a shared lightweight backbone—featuring alternating intra-frame and inter-frame transformer layers—is trained with task-specific heads. All probe architectures, training protocols, and temporal sampling are strictly unified to ensure comparability.
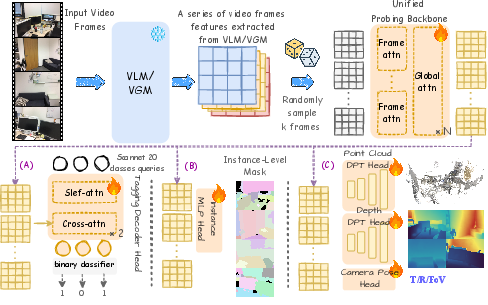
Figure 2: Schematic of the probing setup, with unified backbone and decoupled readout heads for semantic/tagging, instance grouping, geometry.
Main Results
Semantic Tagging
VLMs consistently yield superior results in semantic tagging, with macro average precision (mAP) improved from 69.89 (VGMs) to 92.08 (VLMs) and mid-frequency class performance (APmid) elevated in similar fashion. Critically, VLMs also retain high Mid Ratio (0.948 vs. 0.838), indicating effective recognition across rare categories—not just dominant ones. Qwen3-VL and InternVL3 checkpoints demonstrate extremely robust semantic transfer, confirming that language alignment fosters robust, fine-grained categorical representations.
Instance Grouping
VLMs again dominate in instance grouping, improving T-mIoU from 13.24 to 22.66 and T-SR from 4.35 to 11.23. This indicates VLM features encode not just object identities but also the partitioning necessary for object permanence and tracking across perspectives. While the best-performing VGMs (WAN2.1-T2V-14B) show that generative training imbues some grouping bias, VLMs’ object-centricity confers more distinctive instance embeddings and cross-view consistency.
3D Geometry
In contrast, VGMs are clearly superior in geometry-centric tasks. They achieve lower point-map error, lower depth AbsRel, and higher AUC@30 for camera pose accuracy, confirming that generative video pretraining imparts useful priors for scene geometry and spatial consistency. Even the most 3D-aware VLMs lag behind state-of-the-art VGMs in geometric fidelity.
Qualitative Analysis
Qualitative evaluations reinforce the numerical findings. In semantic tagging, VLMs robustly recall all relevant objects—even in cluttered scenarios—while VGMs frequently omit critical categories.

Figure 3: VLMs recall all relevant objects during semantic tagging despite challenging composition; VGMs miss salient categories.
Instance grouping visualization reveals that VLMs separate semantic entities even with occlusion and complex boundaries, whereas VGMs tend to merge objects into coarse aggregates.

Figure 4: VLM features enable clear, multi-view instance grouping; VGMs show reduced object separability.
Regarding geometry, VGM-based probes reconstruct sharper depths and crisper spatial layouts than their VLM-based counterparts, which tend to blur inter-object boundaries and lose local spatial accuracy.
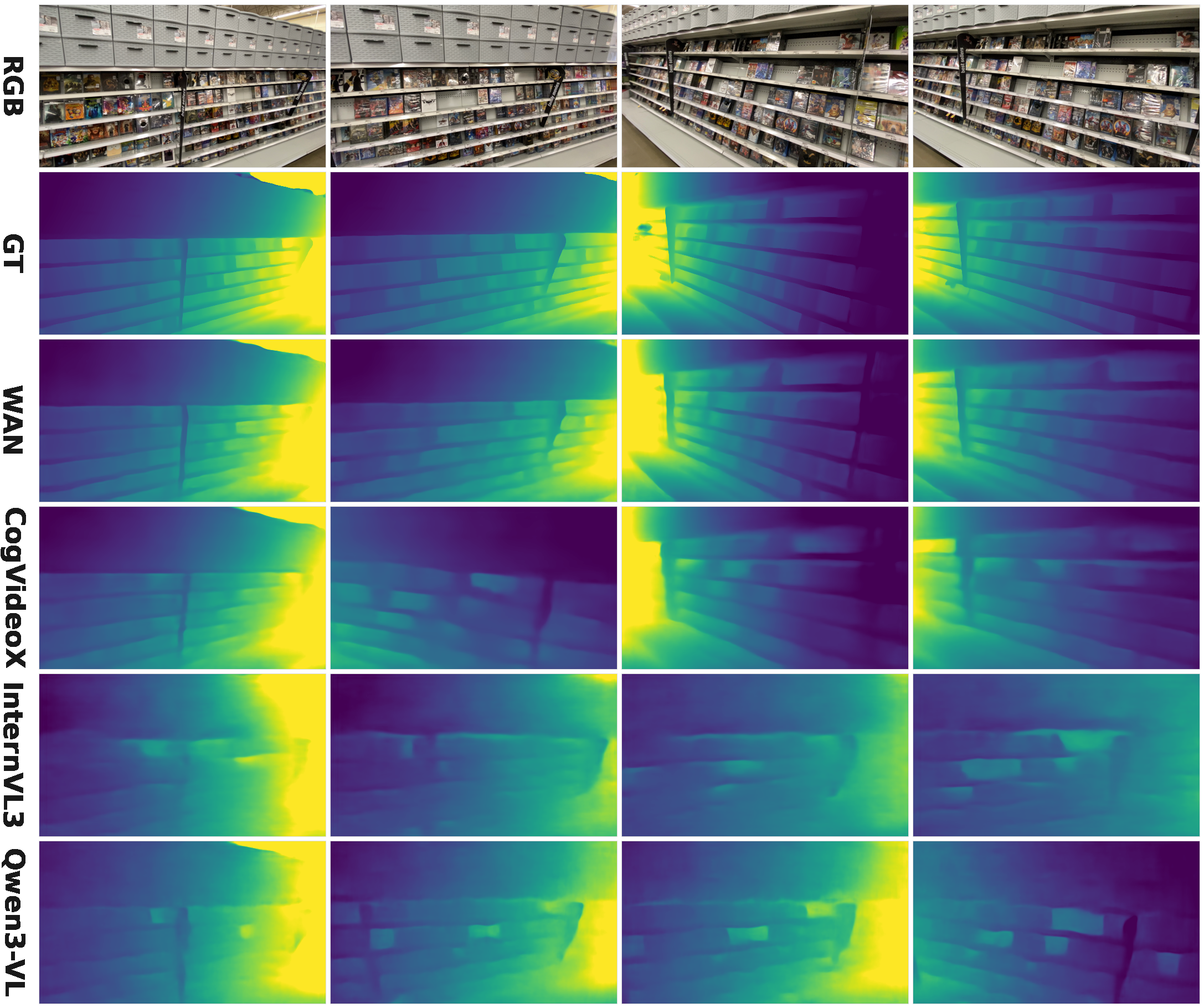
Figure 5: VGM features recover precise depth and fine structure, while VLMs yield smoother, less articulate geometry.
Point-cloud reconstructions highlight that VGM-based models preserve coherent scene structure, in contrast to the noisier, more fragmented reconstructions from VLMs.

Figure 6: VGM-backed probes generate structured, interpretable 3D point clouds; VLMs lack spatial consistency.
Feature Fusion and Complementarity
A simple concatenation and normalization of VLM and VGM frozen features enables probes to jointly exploit the semantic robustness of VLMs and geometric prowess of VGMs. The fusion approach preserves or improves on the best individual scores for both semantic and geometry axes, underscoring the genuinely complementary nature of these pretraining paradigms. This result strongly suggests that the dominant limitations of each family can be overcome through principled representational integration.
Ablation
Probe-depth ablation experiments, varying backbone capacity, confirm that the probe is not independently learning the tasks; instead, the latent model rankings by spatial information content remain stable, demonstrating that results reflect information embedded in the frozen features rather than probe overfitting.
Implications and Future Directions
The study substantiates that spatial intelligence is multifaceted: VLMs, optimized for semantic alignment, distribute semantic and object-centric signals broadly, whereas VGMs, trained with predictive and generative video objectives, embed rich geometric structure. This differentiation underscores the inadequacy of single-metric evaluation and advocates for multi-axis probing as standard practice for foundation backbone assessment.
Practically, these results motivate the design of new spatial-understanding backbones—potentially for robotics, AR, and embodied systems—that explicitly fuse language-aligned semantic abstraction with generation-induced geometric priors. From a theoretical perspective, the tangible advantage of feature-level fusion hints at uncharted architectural innovations for joint representation learning, including more sophisticated modalities of integration (e.g., cross-modal attention, shared latent spaces).
The limitations of current probes—reliance on annotated indoor datasets, untested in more dynamic or outdoor environments, evaluation of only three spatial axes—suggest ample space for both extension (to physical reasoning, affordance, and long-horizon planning) and for probing robustness to broader visual contexts.
Conclusion
This work provides a rigorous, multi-axis probing framework for frozen VLM and VGM representations in spatial intelligence contexts. The findings reveal a division of strengths: VLMs encode superior semantic and instance information, while VGMs provide better geometric detail. Crucially, simple fusion of their features yields a step increase in both axes, strongly supporting their complementarity. These results set a new methodological baseline for evaluating, integrating, and applying foundation models in spatially-aware AI systems. Future development should prioritize cross-paradigm fusion for holistic perception in embodied, interactive, and generative environments.