- The paper presents the IBRO framework to optimize LLM reasoning by maximizing informative reasoning paths while filtering out irrelevant prompt details.
- It integrates IB regularization into RL post-training pipelines with minimal computational overhead, achieving improvements on mathematical reasoning benchmarks.
- Empirical results demonstrate a two-point avg@32 gain and stable entropy dynamics, underscoring the practical impact of IBRO on detailed, accurate reasoning.
Introduction
The paper presents a methodological shift in enhancing the reasoning capabilities of LLMs using the Information Bottleneck (IB) principle. Specifically, the study introduces IB-aware reasoning optimization (IBRO), a framework that maximizes the informativeness of reasoning paths concerning answers while minimizing reliance on irrelevant prompt-specific details. This approach is embedded within reinforcement learning (RL) paradigms to improve the efficacy of reasoning tasks in LLMs.
Methodology
The core contribution of the paper is the formulation of the IBRO framework, which leverages the IB principle to optimize LLM reasoning. The framework is mathematically represented as:
π(r∣q)minI(q;r)−βI(r;a)
where I(q;r) measures the information retained from the prompt and I(r;a) measures the informativeness of the reasoning path towards the answer. The surrogate objective derived for practical implementation involves token-level regularization that modulates entropy based on token importance. The novelty lies in integrating IB regularization seamlessly into existing RL post-training frameworks, requiring minimal computational overhead.
Practical Implementation
The implementation of the IBRO framework involves a one-line modification in existing RL-based post-training pipelines. By utilizing advantages available from RL frameworks, the IB regularization enhances reasoning without additional computational cost:
1
|
entropy_loss = compute_mean(entropy * advantage) |
This code snippet illustrates the practical integration of IB regularization into a policy gradient loss computation.
Empirical Results
The performance of IB regularization was assessed across multiple mathematical reasoning benchmarks using two RL algorithms: PPO and DAPO. The results indicated consistent improvements in reasoning accuracy, with the avg@32 metric showing a gain of approximately two points over baseline methods.
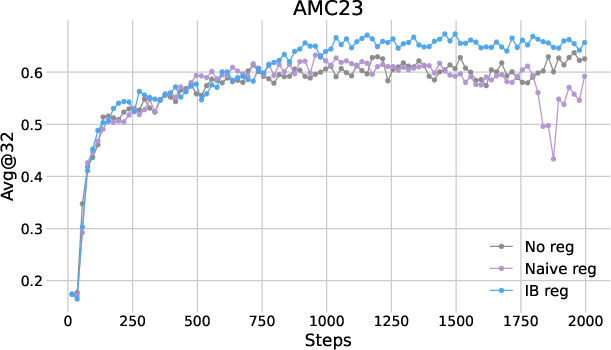
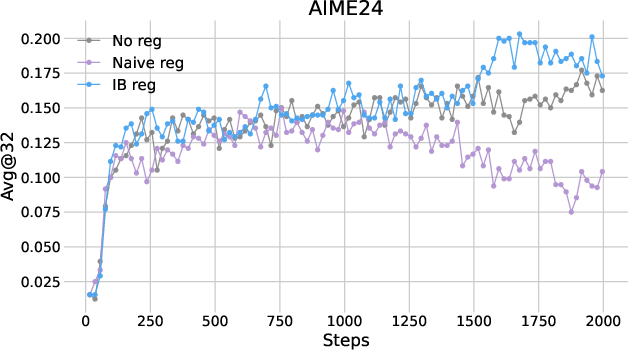
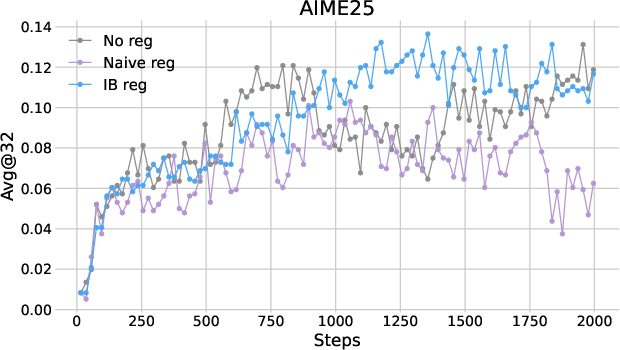
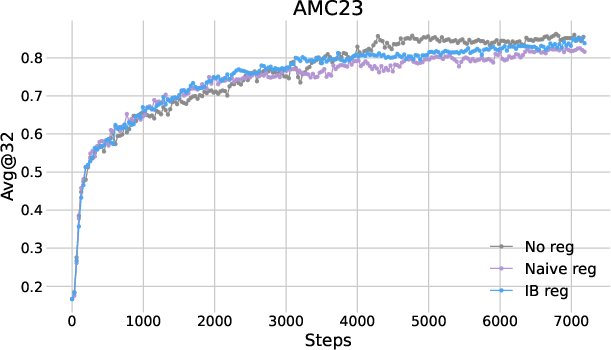
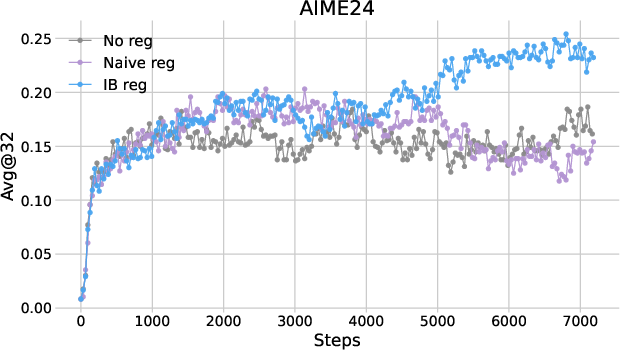
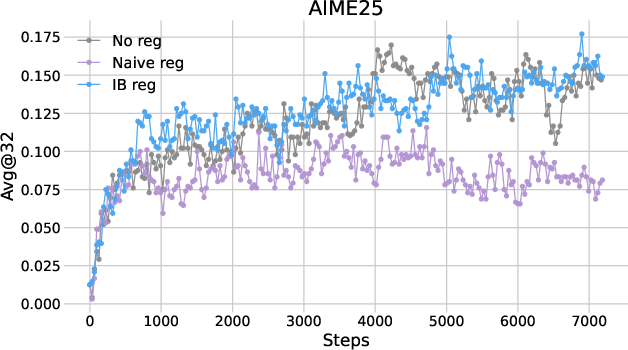
Figure 1: Plots of avg@32 as functions of training steps in (a) PPO and (b) DAPO.
Further analysis of entropy dynamics revealed that naive entropy regularization destabilized training by excessively elevating entropy levels, whereas IB regularization maintained stable entropy dynamics conducive to reasoning.
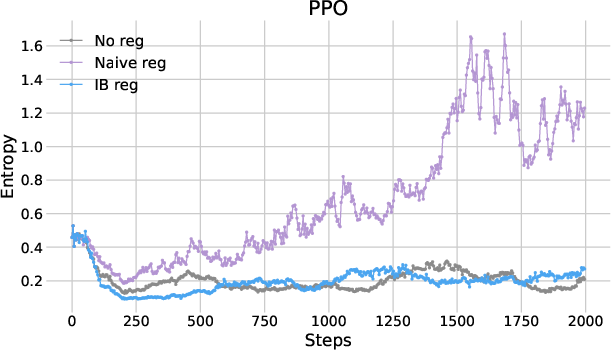
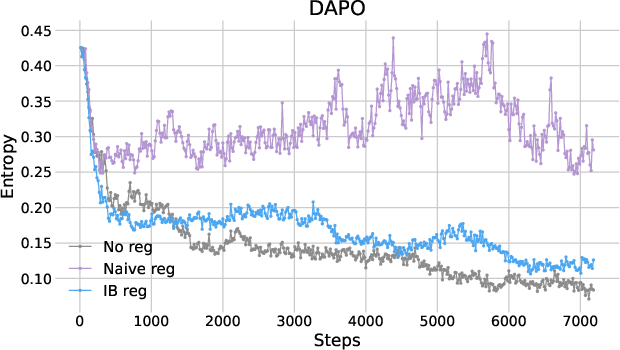
Figure 2: Plots of entropy as functions of training steps.
The study also examined response lengths as an indicator of reasoning depth, demonstrating that IB regularization maintains desirable response lengths conducive to detailed reasoning.
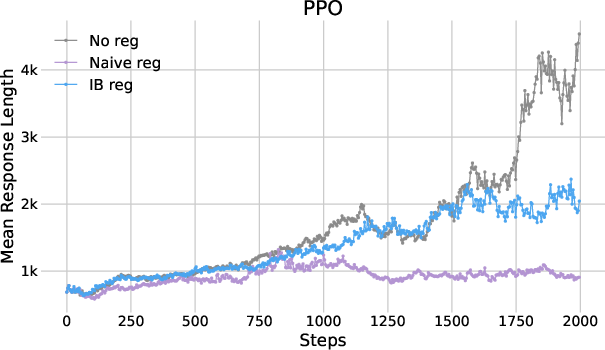
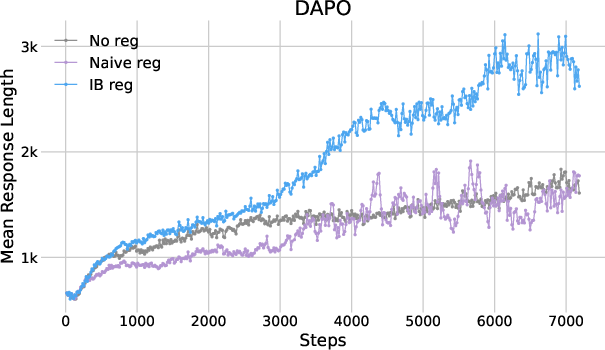
Figure 3: Plots of mean response length as functions of training steps.
Discussion
The proposed IB regularization effectively redistributes entropy during token generation, promoting focused exploration without increasing overall entropy excessively. This aspect renders it highly compatible with existing RL training regimes. However, the method's efficacy is contingent on careful tuning of the regularization strength, which may vary across different model configurations and tasks.
Conclusion
The integration of IBRO into LLM training demonstrates a significant advance in machine reasoning, providing a theoretically grounded method that enhances reasoning accuracy and stability. These findings stress the importance of information-theoretic approaches in optimizing LLM capabilities, suggesting potential avenues for further research in scalable learning methods for large models.