Learn from your own latents and not from tokens: A sample-complexity theory
Abstract: Generative models, from diffusion models to LLMs, achieve remarkable performance but at a cost in training data orders of magnitude larger than what biological learners require. An alternative paradigm has emerged in which networks are trained to predict their \emph{own} latent representations of related views or masked regions, as in data2vec and JEPA -- an idea related to predictive-coding accounts of the cortex. Despite strong empirical results, the theoretical understanding of these methods remains limited. Central questions include: by how much does latent prediction actually improve data efficiency? Is there a benefit to stacking such methods into multi-scale hierarchies? We answer both using as data a tractable probabilistic context-free grammar that captures the compositional structure of natural language and images. Such a grammar generates strings of visible tokens by recursively applying production rules along a tree of hidden symbols of depth $L$. For such data, supervised or token-level SSL require a number of samples \emph{exponential} in $L$ to recover the latent tree; we prove that latent prediction achieves this with a number of samples \emph{constant} in $L$, up to logarithmic factors. We confirm this bound with (i) a hierarchical clustering algorithm, (ii) an end-to-end neural network whose predictor-clusterer modules predict their own latents at each level via gradient descent, and (iii) the first sample-complexity analysis of data2vec, which we show implicitly performs hierarchical latent prediction. This suggests that explicit stacking such as H-JEPA is largely redundant.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “Learn from your own latents and not from tokens: A sample-complexity theory”
1) What is this paper about?
This paper asks a simple question with a big impact: What’s the most efficient way for AI models to learn from data? The authors compare two ways:
- Predicting surface details (like the next word or pixel), which is what many popular models do today.
- Predicting the model’s own hidden ideas about the input (called “latents”), which are more abstract meanings or features.
They show, with theory and experiments, that learning by predicting your own hidden ideas can use far fewer examples than learning from raw tokens (like words or pixels).
2) What questions are the authors trying to answer?
In easy terms:
- How much fewer examples does “learning from your own latents” need compared to predicting tokens?
- If we build many layers that all do this (a tall stack), does that help a lot more, or is one layer already enough?
3) How did they study it? (Methods and key ideas in simple language)
To keep things clear and testable, the authors built a “toy world” where the rules are known and simple, but still capture the structure of real data like language and images.
- The toy world: Imagine creating sentences or pictures by following a recipe tree. At the top you have a big idea, which splits into smaller ideas, and those split further, until you get the final visible pieces (like words or pixels). This is called a hierarchy. The paper uses a simple, random version of this idea called the Random Hierarchy Model (RHM).
- Depth L: how many levels the idea-tree has (top to bottom).
- m: how many ways each symbol can expand (how many “synonymous” choices per parent idea).
- Tokens: the visible pieces (letters/words/pixels).
- Latents: the hidden ideas at each level of the tree.
- Sample complexity: how many training examples you need to learn well.
- Why predicting tokens can be wasteful: If you try to learn deep concepts by predicting surface tokens, the useful signal gets “watered down” as it has to travel through many levels of the tree. Each extra level makes the job a lot harder, like playing telephone through many people.
- Why predicting your own latents is efficient: If you instead predict ideas at the same level of the tree (latent-to-latent), the signal stays strong. It’s like comparing notes directly with your cousin in a family tree rather than shouting up and down the whole tree.
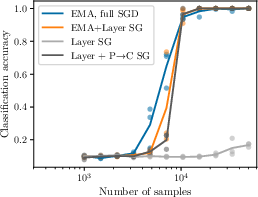
- What they tested: 1) A simple clustering algorithm (call it ILC): At each level, group together “tuples” (short chunks) that behave the same with their nearby neighbors (their “cousins” in the tree). This lets you reconstruct the hidden ideas level by level. 2) A neural network version (SLC): A stack of small modules. Each module learns to predict a cousin’s representation and then clusters the predictions into discrete codes (ideas). Trained end-to-end with gradient descent. 3) A popular method called data2vec: It trains a student network to match a teacher network’s hidden features at masked positions. The authors analyze it and argue that, in effect, data2vec is also doing this same “latent prediction” across levels.
- Key technical term translated:
- “Synonyms” here means different low-level choices that still represent the same higher-level idea (same parent in the tree). Learning means figuring out which different-looking pieces actually belong to the same concept.
4) What did they find, and why is it important?
Main findings:
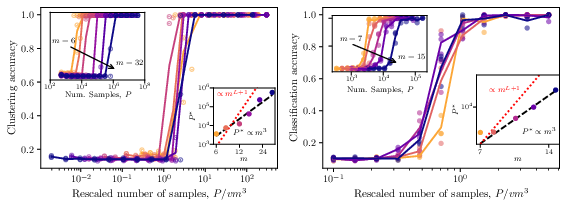
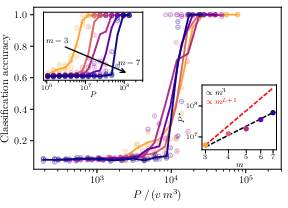
- Predicting tokens needs an enormous number of examples when the hierarchy is deep. In their model, it grows like mL+1 — this explodes as depth L increases.
- Learning from your own latents needs far fewer examples. They prove and confirm that it needs on the order of m3 examples, which does not grow with depth L. That’s a huge savings.
- Their simple clustering algorithm (ILC) and their neural stacked version (SLC) both achieve this m3 scaling.
- Data2vec, without explicitly stacking many levels, already behaves like a hierarchical latent predictor and also hits the m3 scaling. In other words, it “implicitly” builds a useful hierarchy inside, which helps explain its strong performance.
- Because data2vec already acts hierarchically, explicitly stacking many such modules (like in hierarchical JEPA) may bring only small gains.
Why this matters:
- It shows a clear, mathematical reason why predicting ideas (latents) can be vastly more data-efficient than predicting raw tokens.
- It helps explain why some self-supervised methods feel “smarter” with less data.
- It gives guidance for designing future AI training methods that learn faster and with fewer examples.
5) What could this change in the future? (Implications and impact)
- For AI research and engineering:
- Training by predicting your own latent representations could reduce how much data we need to reach strong performance, especially on tasks with deep structure (like language and vision).
- It suggests that mixing token-level and latent-level prediction, or emphasizing latent-level objectives, could improve data efficiency.
- Since data2vec already behaves like a hierarchical learner, we might focus on improving and simplifying such methods instead of building very deep stacks.
- For understanding brains:
- The idea connects to “predictive coding,” a neuroscience theory that the brain predicts its own future activity. This work strengthens the intuition that predicting internal representations can be very sample-efficient — something brains are great at.
- Limitations and next steps:
- The toy world (RHM) is simpler than real language or images: it uses a fixed tree and simple, non-recursive rules. Future work should test more realistic, flexible structures.
- It would be valuable to directly compare data2vec and next-token models on the same tasks and track how the number of training examples changes their performance.
In short: The paper shows that learning by predicting your own hidden representations can turn a hard, data-hungry problem into a much easier one. It provides both theory and experiments to back this up, and it helps explain why some modern methods work so well with less data.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of specific gaps and open questions the paper leaves unresolved. Each item is framed to be directly actionable for future research.
- Relaxation of RHM assumptions: Extend the theory beyond fixed-tree PCFGs to grammars with variable topology, ambiguity (non-injective rule maps), and recursion; quantify how sample complexity changes when the latent structure is not strictly tree-structured or context-free.
- Finite-v, finite-sensitivity analysis: The proofs rely on large-v limits and “balanced” and “separated” grammars. Provide non-asymptotic bounds with explicit constants; quantify how reconstruction degrades when tuple frequencies are imbalanced or parent context vectors are less than $1/m$ separated.
- Stability of clustering under realistic noise: Theoretical guarantees assume a “stable clustering module.” Derive rigorous success conditions for concrete algorithms (e.g., k-means, spectral clustering, contrastive codebooks) on the empirical context vectors under sampling noise and mis-specified cluster counts.
- Robustness to misspecification and spurious correlations: Characterize failure modes when correlations are contaminated (e.g., distributional drift, adversarial or random noise, partial observability); determine thresholds for synonym clustering under such perturbations.
- Exact dependence on branching factor and tree distance: Generalize the correlation attenuation law to arbitrary branching factor , masking strategies, and context geometries; confirm whether the exponent holds when cousin relationships or path lengths differ.
- Behavior near dense-rule regimes (): The sample complexity bound includes a factor $1/(1-f)$. Analyze edge cases where many tuples are grammatical (high ), including phase transitions in recoverability and the tightness of the bound.
- Adaptive discovery of hierarchy depth and vocabulary size: Develop methods that infer the number of levels and cluster cardinalities online, with guarantees on over/under-segmentation and corresponding sample complexity.
- Root-label recovery without supervision: The paper notes unsupervised recovery of non-root latents but not root labels. Design and analyze weakly supervised or self-supervised procedures to recover top-level partitions; quantify their sample complexity.
- Formal justification of data2vec assumptions (A1/A2): Provide theoretical or empirical evidence that teacher targets carry linear components of learned latents (A1) and that gradient descent systematically extracts any detectable correlation (A2) in realistic, non-synthetic settings.
- Sensitivity to data2vec hyperparameters: Quantify how EMA rate, the number of pooled layers , masking fraction, architecture depth/width, and pooling choices affect phase progression and the observed scaling.
- Offline vs online training regimes: Precisely characterize how dataset reuse (offline) vs fresh sampling (online) impacts the number of phases, per-phase thresholds, and overall sample complexity for data2vec-like methods.
- Controlled comparisons on real data: Execute head-to-head experiments (same architecture) between own-latent prediction (e.g., data2vec/JEPA) and token-level prediction (e.g., next-token modeling) across varying dataset sizes, to validate the predicted divergence in small- regimes and convergence at large .
- Conditions where explicit stacking helps: The paper suggests explicit hierarchies (e.g., H-JEPA) may be redundant. Construct datasets and synthetic models that break implicit hierarchy formation; identify regimes where stacking yields non-trivial gains and quantify them.
- Extension to continuous modalities (images/audio): Translate the cousin-tuple clustering mechanism to continuous inputs; define appropriate latent targets, context structures, and separation conditions; test if -like scaling persists in practice and theory.
- Non-uniform, heavy-tailed rule distributions: Natural language exhibits Zipf-like statistics. Analyze sample complexity under skewed rule frequencies; determine whether latent-supervised methods still beat token-level scaling when distributions are long-tailed.
- Compute–sample trade-offs and optimization dynamics: Quantify training time, compute, and optimization stability required to realize the sample-complexity gains; identify whether latent prediction shifts the optimal compute–data scaling compared to token-level objectives.
- Formal guarantees for SLC under local learning: Provide theoretical bounds showing the stacked predictor–clusterer architecture with stop-gradients (no end-to-end backprop) still achieves sample complexity; detail conditions on module interfaces and loss functions.
- Masking strategy optimization: Determine masking patterns and rates that maximize the strength of cousin-level correlations (and minimize token bottlenecks) in data2vec/JEPA; relate optimal strategies to grammar/statistical properties.
- Alternative target constructions: Investigate whether single-layer targets, different pooling schemes, or JEPA-style energy-based targets preserve the implicit hierarchical clustering and the scaling; formalize equivalences or differences.
- Measuring synonym clustering on real data: Define operational analogs of “synonyms” in natural corpora or images; build diagnostic interventions and metrics to detect internal clustering of equivalence classes during own-latent SSL.
- Integration with multimodal grounding: Test whether combining own-latent prediction with grounded or multimodal inputs further reduces sample complexity; develop theory connecting cross-modal correlations to improved latent reconstruction.
- Generalization beyond PCFG/RHM: Formulate a broader correlation-propagation theory that predicts when own-latent prediction will outperform token-level objectives in non-grammar generative processes (e.g., Markov, autoregressive, or hybrid hierarchical models).
Practical Applications
Immediate Applications
Below are actionable uses that can be piloted today based on the paper’s findings that “learn-from-your-own-latents” objectives (e.g., data2vec/JEPA-like) can recover hierarchical structure with roughly O(vm3) samples (independent of hierarchy depth L), outperforming token-level objectives that scale as O(vm{L+1}). Where relevant, we outline tools/workflows and note assumptions/dependencies.
- Data-efficient pretraining for domain-specific models (software, healthcare, finance, legal)
- Use case: Train language and vision encoders for specialized domains with limited unlabeled data (e.g., clinical notes, radiology images, financial filings, legal contracts).
- Tools/workflows:
- Swap or augment next-token/MLM/diffusion objectives with own-latent prediction (data2vec/JEPA). Use an EMA teacher and masked inputs (e.g., ~15% masking).
- Add a small labeled head for downstream tasks; rely on linear/MLP probes post-SSL for classification.
- Introduce diagnostics for hierarchical learning (e.g., synonym clustering scores; linear probe accuracy at internal layers).
- Assumptions/dependencies: Real data exhibits approximate hierarchical latent structure; EMA teacher stabilizes training; hyperparameters tuned to avoid collapse; modest labeled data still needed for final tasks.
- Data-constrained model development and rapid prototyping (software, MLOps/DevOps)
- Use case: Build encoders with fewer training samples in startups or teams with limited data budgets.
- Tools/workflows:
- Implement the Stacked Latent-Clustering (SLC) module or a JEPA/data2vec objective in existing transformer backbones.
- Monitor sample-efficiency via scaling sweeps; add stop-gradients between modules if using SLC to simplify training and enable local learning.
- Assumptions/dependencies: Off-the-shelf clustering-like components (contrastive codebooks) are stable; compute available for teacher-student setup.
- Label-efficient pipelines for niche verticals (healthcare, finance, cybersecurity)
- Use case: Pretrain with own-latent SSL on small unlabeled corpora; fine-tune on small labeled sets for diagnosis coding, fraud detection, or threat triage.
- Tools/workflows:
- Pretrain with data2vec-style objective; then train shallow classifiers on pooled final-layer features.
- Assumptions/dependencies: Downstream tasks align with learned representations; enough label signal to map latents to target labels.
- Edge and federated learning with small local datasets (mobile/IoT, robotics)
- Use case: On-device or federated pretraining where each client holds limited unlabeled data (sensor streams, logs).
- Tools/workflows:
- Replace token-level prediction with latent prediction to reduce per-client sample needs; plug teacher-student into federated averaging.
- Assumptions/dependencies: Communication/computation supports EMA teacher updates; privacy constraints allow exchanging model updates only.
- Vision/audio encoders with reduced data needs (computer vision, speech/audio)
- Use case: Domain-specific feature extractors for medical imaging, industrial inspection, or low-resource speech.
- Tools/workflows:
- Port data2vec or JEPA-like latent targets to images/spectrograms; measure representation quality via linear probes, few-shot tasks.
- Assumptions/dependencies: Hierarchical structure (e.g., parts→objects) is present; robust masking/target pooling choices.
- Scientific and academic benchmarking (academia, ML theory/practice)
- Use case: Evaluate SSL methods’ data efficiency and hierarchical recovery.
- Tools/workflows:
- Use the Random Hierarchy Model (RHM) as a controlled testbed; run scaling sweeps vs. sample size and measure clustering/probe metrics.
- Assumptions/dependencies: Transfer of insights from RHM to real datasets must be empirically validated.
- Training diagnostics and MLOps add-ons (software tooling)
- Use case: Detect when models begin to cluster “synonymous” patterns and ascend latent levels.
- Tools/workflows:
- Implement synonym-clustering scores and level-wise probes; add “phase-wise” teacher refresh schedules to encourage hierarchical progression.
- Assumptions/dependencies: Requires instrumentation for internal activations; approximate proxies for “synonyms” in real data.
- Privacy and compliance-friendly modeling (policy, compliance)
- Use case: Reduce data collection/storage by achieving target performance with fewer samples.
- Tools/workflows:
- Document data-minimization via latent-SSL pretraining; combine with differential privacy as needed.
- Assumptions/dependencies: Legal acceptance of reduced-data pipelines; validation on representative cohorts.
- Neuroscience-inspired modeling and cognitive experiments (academia, neuro-AI)
- Use case: Test predictive-coding/local-learning hypotheses with SLC-like local rules (stop-gradients).
- Tools/workflows:
- Train local-learning variants; compare human-like sample efficiency on cognitive benchmarks.
- Assumptions/dependencies: Tasks need measurable hierarchical structure; local rules provide sufficient stability without full backprop.
- Diffusion/modeling variants with latent prediction (vision, audio, time series)
- Use case: Improve sample efficiency for generative modeling by predicting latents instead of raw tokens/pixels.
- Tools/workflows:
- Hybrid objectives: combine diffusion or masked modeling losses with latent targets to accelerate early learning on small datasets.
- Assumptions/dependencies: Loss balancing and schedules tuned to avoid dominance of token-level losses.
Long-Term Applications
These rely on further empirical validation beyond RHM, robust engineering at scale, and broader adoption. They could shift training regimes, scaling laws, and sector practices.
- Redesign of foundation-model objectives to break current scaling laws (AI infrastructure, energy/sustainability)
- Impact: Reduce data and compute needs by moving from token-level to latent-level prediction at scale; lower carbon footprint.
- Potential products: Latent-SSL-pretrained foundation encoders for text, vision, multimodal; “latent-first” training suites.
- Dependencies: Confirmation that vm3-like scaling advantages persist on natural data; robust training stability; community benchmarks.
- Low-resource language and domain foundation models (education, culture, public-interest tech)
- Impact: Enable high-quality models for languages and domains with scarce data.
- Potential products: LLMs for endangered languages; specialized biomedical/financial encoders trained from small corpora.
- Dependencies: Suitable tokenization/segmentation; culturally appropriate evaluation; community data partnerships.
- Healthcare-grade models from limited data (healthcare, med-tech)
- Impact: Models for rare diseases or small hospitals that cannot collect massive datasets.
- Potential products: Latent-SSL-pretrained EHR encoders, medical imaging backbones, clinical note understanding systems.
- Dependencies: Strict validation and bias audits; regulatory approval; privacy-preserving training with EMA teacher setups.
- Robotics world models and planners with few trials (robotics, autonomy)
- Impact: Sample-efficient representation learning from onboard sensory streams; faster sim-to-real adaptation.
- Potential products: Latent-prediction world models, hierarchical planners learning from fewer interactions.
- Dependencies: Handling non-tree, recursive, and partially observed dynamics; stable on-policy/off-policy learning with latent objectives.
- Scientific discovery with hierarchical SSL (genomics, materials, climate)
- Impact: Learn structure in sequences, graphs, and fields with fewer samples.
- Potential products: Encoders for protein/DNA grammar, materials microstructure, multiscale climate fields.
- Dependencies: Extending theory beyond fixed-tree grammars to variable topology/recursions; robust clustering under noise/heterogeneity.
- Standardized benchmarks, metrics, and tooling for hierarchical latent recovery (academia, open-source software)
- Impact: Common ground to evaluate latent-SSL methods and measure “implicit hierarchy.”
- Potential products: Open libraries implementing SLC modules, synonym-clustering diagnostics, phase-wise schedules; RHM-like synthetic suites.
- Dependencies: Community consensus on metrics; alignment with practical tasks.
- Energy-efficient, on-device, and neuromorphic learning (hardware, edge AI)
- Impact: Local learning rules (stop-gradients, predictive coding) enabling efficient chips and on-device adaptation.
- Potential products: Hardware-accelerated predictor–clusterer modules; neuromorphic co-processors for latent prediction.
- Dependencies: Hardware/software co-design; stability of local rules at scale; task portability.
- Policy and governance shifts toward data minimization (policy, compliance)
- Impact: Encourage “less-is-enough” training paradigms, reducing data hoarding and privacy risk.
- Potential products: Best-practice guidelines for latent-SSL pipelines; regulatory frameworks recognizing reduced data needs.
- Dependencies: Strong, public empirical evidence on real-world gains; clear audit trails for training decisions.
- AutoML systems that adapt objectives by data regime (software, platform AI)
- Impact: Automatically switch between token-level and latent-level objectives as data grows; schedule teacher refresh phases.
- Potential products: AutoML controllers that monitor clustering/probe signals and adjust masking, EMA rates, and loss weights.
- Dependencies: Reliable real-time diagnostics; cost-aware decision policies; generalization across domains.
- Content moderation and safety models with less data (trust & safety)
- Impact: Train classifiers for harmful content or misinformation in low-data regimes and new languages.
- Potential products: Latent-SSL-pretrained moderation encoders that adapt quickly to emerging domains.
- Dependencies: Robustness to distribution shift; careful alignment and human-in-the-loop review.
Cross-cutting assumptions and dependencies
- Structural assumptions: Real-world data should exhibit sufficiently separable and balanced hierarchical latent structure; the RHM’s fixed-tree, unambiguous, non-recursive grammar is a simplification.
- Learning dynamics: The “correlation-learning” assumption—gradient descent extracts weak but detectable correlations—should hold; EMA teacher targets should carry linear components of learned latents.
- Stability: Prevent representation collapse (e.g., EMA teacher, contrastive codebooks); tune masking rates, pooling, and losses.
- Evaluation: Root-level labels (top of hierarchy) cannot be recovered purely unsupervised; small labeled sets or appropriate probes will often remain necessary.
- Engineering: Need scalable implementations of latent prediction, local learning variants (stop-gradients), clustering-like modules, and robust MLOps diagnostics.
- Generalization: Extending beyond fixed topology to variable trees, recursion, and richer compositionality remains an open research frontier and affects long-term feasibility.
Glossary
- Balanced RHM grammar: An RHM where grammatical tuples appear with roughly equal frequency at each level. "An RHM grammar is balanced if, for every level , every grammatical tuple occurs with probability of order $1/(vm)$."
- Bootstrap Your Own Latent (BYOL): A self-supervised method that learns representations by predicting its own embeddings without negative samples. "including BYOL~\citep{grillBootstrapYourOwn2020}, DINO ~\citep{caronEmergingPropertiesSelfsupervised2021}, data2vec~\citep{baevskiData2vecGeneralFramework2022} and JEPA"
- Branching factor: The number of children each node has in the latent tree. "The tree has depth , branching factor , and vocabularies , all of size ."
- CLAPP: A biologically inspired self-supervised method using local learning rules for predictive coding. "conceptually similar to contrastive predictive coding~\citep{oordRepresentationLearningContrastive2019a} and CLAPP~\citep{illingLocalPlasticityRules2021}, which both propose biologically plausible self-supervised objectives that predict in latent rather than raw-sensory space."
- Connected correlation: A correlation measure subtracting the product of marginals to isolate dependence. "One can consider the connected correlation:"
- Contrastive objective: A learning objective that pulls similar representations together and pushes dissimilar ones apart. "through a contrastive objective: prediction vectors with high similarity are pulled to the same code while dissimilar ones are pushed apart -- implementing in the neural setting."
- Contrastive predictive coding (CPC): A contrastive self-supervised framework predicting future latent representations. "conceptually similar to contrastive predictive coding~\citep{oordRepresentationLearningContrastive2019a}"
- Context vector: The conditional distributional embedding of a target given a tuple, used for clustering synonyms. "As before, the essential observation is that synonyms have the same context vector."
- Cousin tuple: A tuple sharing a grandparent with a given tuple at a specified level. "cousins are simply nodes sharing the same grandparent at level "
- Data2vec: A self-distillation method that predicts teacher latent representations from masked inputs. "data2vec~\citep{baevskiData2vecGeneralFramework2022} implicitly performs hierarchical latent prediction"
- DINO: A self-supervised method that learns visual features via self-distillation with no labels. "including BYOL~\citep{grillBootstrapYourOwn2020}, DINO ~\citep{caronEmergingPropertiesSelfsupervised2021}, data2vec~\citep{baevskiData2vecGeneralFramework2022} and JEPA"
- Diffusion models: Generative models that iteratively denoise data from noise to samples. "Diffusion models produce realistic images and video~\citep{ho2020denoising, rombach2022high, brocks2024video}"
- Energy-based methods: Models that define an energy function whose minima correspond to desired configurations, enabling learning via energy shaping. "they can be formulated as energy-based methods~\citep{lecun2022path}"
- Exponential moving average (EMA): A running average of parameters that emphasizes recent updates, used for teacher networks. "whose weights track an exponential moving average of the student's weights"
- H-JEPA: Hierarchical Joint-Embedding Predictive Architecture; an explicitly stacked variant of JEPA. "weakening the case for explicit stacking such as H-JEPA."
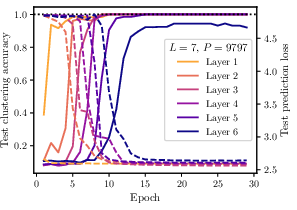
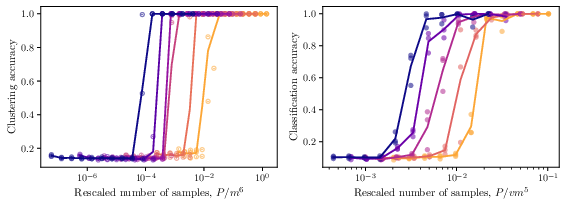
- Hierarchical clustering: Clustering that organizes data into nested groups across levels. "a hierarchical clustering algorithm recovers the full non-root latent tree"
- Iterative Latent Clustering (ILC): An algorithm that clusters tuples by their context vectors level-by-level to recover latents. "Iterative Latent Clustering (ILC) --- see \Cref{fig:ilc_schematic} for a graphical representation."
- JEPA: Joint-Embedding Predictive Architecture; a framework that predicts embeddings of future or masked content. "JEPA ~\citep{lecun2022path}"
- k-means: A clustering algorithm that partitions data into k clusters by minimizing within-cluster variance. "cluster them using -means."
- Latent prediction: Predicting abstract latent representations rather than raw tokens to improve data efficiency. "latent prediction achieves this with a number of samples constant in , up to logarithmic factors."
- Learn-from-your-latent SSL: A self-supervised paradigm where models predict their own latent representations at each level. "Learn-from-your-latent SSL"
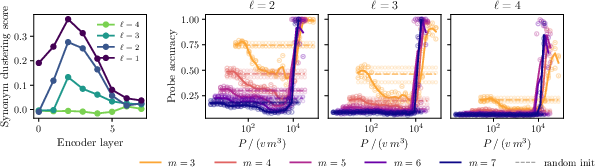
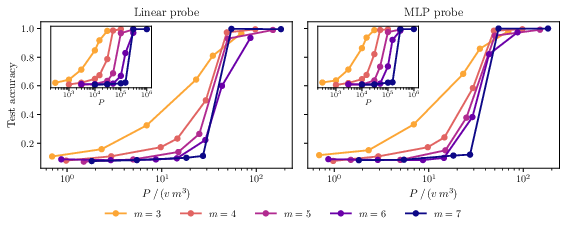
- Linear probe: A simple classifier (often linear) trained on frozen features to assess representational content. "accuracy of a linear probe trained to recover the top-level latent"
- Linearly decodable representation: A representation from which target variables can be recovered by a linear map. "becomes linearly decodable"
- Masked-language modelling (MLM): A self-supervised task predicting masked tokens in a sequence. "masked-language modelling and diffusion"
- Multi-scale hierarchy: A representation structure with multiple levels of abstraction. "a multi-scale hierarchy of learned representations"
- Neural scaling laws: Empirical relations describing how performance scales with model/data size. "relating neural scaling laws to the statistics of natural language"
- Nonparametric sample-complexity bounds: Bounds that do not assume a fixed finite parameterization, often scaling with input dimension. "yielding nonparametric sample-complexity bounds polynomial in the input dimension"
- Predictive coding: A neuroscience-inspired theory where systems predict their future activity and minimize prediction errors. "predictive coding posits that the cortex seeks to predict its own future activity~\citep{rao1999predictive,illingLocalPlasticityRules2021, millidge2022predictive}"
- Probabilistic context-free grammar (PCFG): A grammar with production rules assigned probabilities, generating hierarchical structures. "Probabilistic context-free grammars (PCFGs) are a natural candidate"
- Production rule: A grammar rule specifying how a parent symbol generates its child tuple. "through recursive production rules they generate data compositionally from a tree of latent variables"
- Random Hierarchy Model (RHM): A simplified PCFG on a fixed tree with random production rules, used for theoretical analysis. "The RHM \citep{cagnetta2024deep} is a probabilistic context-free grammar on a fixed regular tree."
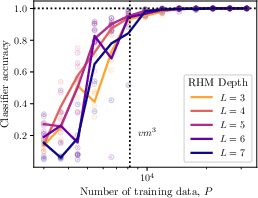
- Sample complexity: The number of samples needed to learn a task with desired accuracy. "The sample complexity to learn RHM data depends on training objective."
- Scaling collapse: A plot rescaling that collapses curves across conditions to reveal universal scaling. "the main plot is a {\it scaling collapse},"
- Self-supervised learning (SSL): Learning representations from unlabeled data by predicting parts of the input or its transformations. "Token-level SSL (MLM, diffusion)"
- Stacked Latent-Clustering (SLC): A differentiable, modular architecture that mirrors ILC with predictor and clusterer stacks. "The Stacked Latent-Clustering (SLC) network."
- Stop-gradient: A training technique preventing gradient flow through parts of a model to enforce locality. "inserting a stop-gradient at every module boundary"
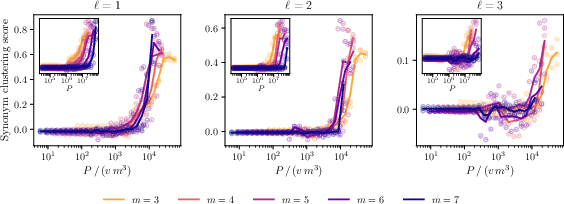
- Synonym (in grammars): Distinct grammatical tuples that share the same parent, treated as equivalent for learning. "Two grammatical tuples are called synonyms if they have the same parent."
- Synonym clustering score: A metric quantifying how closely the model maps synonymous tuples versus non-synonyms. "Synonym clustering score of the encoder at "
- Teacher-student: A self-distillation setup where a student predicts targets produced by a slowly updated teacher. "Data2vec learns in a teacher-student setting;"
- Token-level self-supervision (token-level SSL): Objectives that predict raw tokens (e.g., masked or future tokens) rather than latents. "Token-level SSL (MLM, diffusion)"
- Transformer: A neural architecture based on self-attention, effective for sequences and hierarchical inference. "transformers can approximately implement parsing-style inference on context-free grammars"
- Unambiguous grammar: A grammar where each grammatical tuple maps to a unique parent (no ambiguity). "the grammar is unambiguous: each grammatical tuple has a unique parent."
Collections
Sign up for free to add this paper to one or more collections.