- The paper introduces Predictive Representation Learning (PRL) as a distinct paradigm, shifting focus from traditional alignment and reconstruction methods.
- It provides a detailed taxonomy and empirical comparison, showing that PRL enhances occlusion robustness and achieves competitive benchmarks.
- The study highlights PRL's scalability across modalities and outlines future challenges in theory and application for more complex domains.
From Alignment to Prediction: A Study of Self-Supervised Learning and Predictive Representation Learning
Introduction
This paper analyzes the evolution of self-supervised learning (SSL), moving beyond prevalent alignment and reconstruction methods towards Predictive Representation Learning (PRL). The work formalizes PRL as an independent paradigm, primarily instantiated by Joint Embedding Predictive Architectures (JEPA). The study provides a taxonomy of SSL methods, comparative empirical evaluations of alignment, reconstruction, and predictive approaches, and an articulation of the theoretical and practical implications of predictive learning in representation space.
Taxonomy and Architectural Comparison in SSL
The paper proposes a categorical reorganization of SSL based on learning objectives:
- Alignment-based SSL: Includes contrastive (e.g., SimCLR, MoCo) and non-contrastive (e.g., BYOL, SimSiam) methods. These maximize invariance across augmentations with or without explicit negatives. Architectural asymmetry or gradient blocking (non-contrastive) and negative samples (contrastive) are central for collapse prevention.
- Reconstruction-based SSL: Encompasses classical autoencoders and methods like MAE. Here, the model reconstructs corrupted/masked input signals, leading to high similarity in latent space but often overfitting to low-level details.
- Predictive Representation Learning (PRL): This new category, exemplified by JEPA, shifts the objective to latent-space prediction of unobserved data components, decoupling supervision from direct input recovery and negative sampling.
This tripartite taxonomy is visualized and systematically compared across core dimensions including loss formulation, collapse avoidance, representational focus, and operational space.
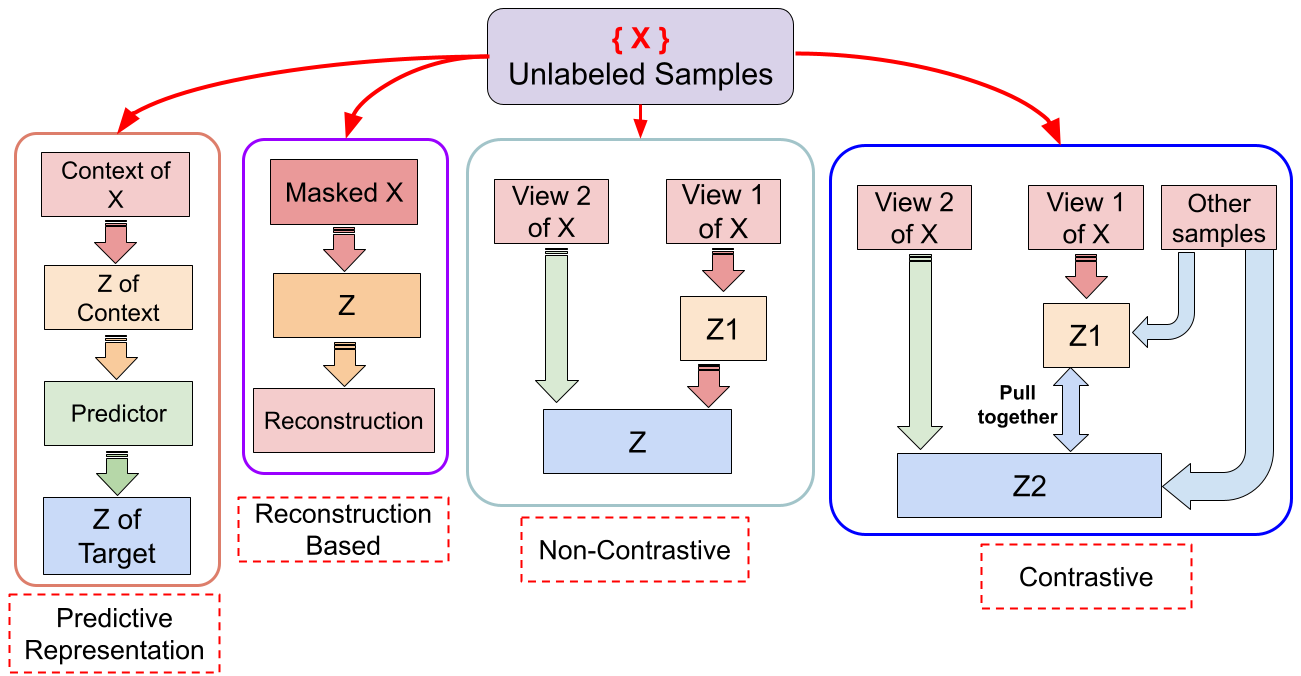
Figure 1: Architectural comparison of contrastive, non-contrastive, reconstruction-based, and predictive representation learning architectures.
PRL generalizes self-supervised objectives to prediction in the representation space. For an input sample x∼D partitioned into observed context c(x) and unobserved target t(x), a context encoder fθ and a target encoder fθˉ (momentum-based) produce embeddings zc and zt respectively. A predictor network gϕ outputs z^t=gϕ(zc), minimizing ∥z^t−sg(zt)∥22. Unlike alignment or reconstruction, the supervision signal drives the model to anticipate missing information in latent space, not explicitly tied to input recovery or negative pairs.
Key properties of PRL are:
- Supervision in representation space via latent prediction.
- Directional objectives that enforce context-to-target structure.
- Collapse avoidance via architectural design (asymmetry, predictor networks, stop gradients).
- High suitability for partial observability, abstraction, and scalability across domains (vision, video, language, graphs).
Empirical Comparison: Alignment, Reconstruction, and Predictive Objectives
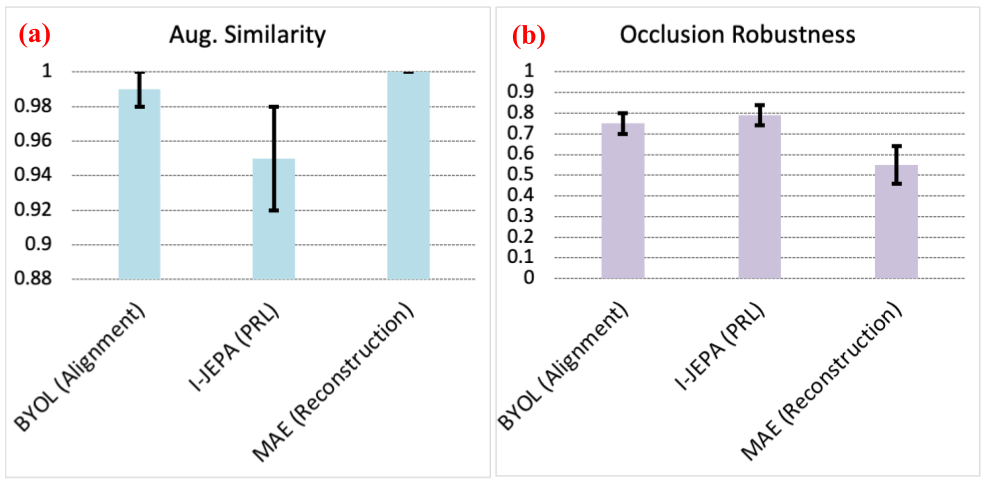
The authors implement BYOL (alignment), MAE (reconstruction), and I-JEPA (predictive) for controlled comparison:
The results highlight a trade-off: reconstruction and alignment maximize similarity but generalize poorly under occlusion, while predictive objectives improve robustness by capturing structural dependencies beyond the observed signal.
Generality and Benchmark Results of JEPA Variants
JEPA and its variants demonstrate competitive or state-of-the-art performance across multiple domains:
- Vision (I-JEPA): ImageNet linear probe Top-1, 72.8%.
- Video (V-JEPA): Matches VideoMAE on Kinetics-400.
- Vision-language (VL-JEPA): Enhanced cross-modal retrieval.
- Graph data (graph-JEPA): SOTA/competitive node classification.
These results establish JEPA-style predictive architectures as domain-general learners, scaling across modalities without resorting to explicit alignment or reconstruction.
A Novel Taxonomy and Conceptual Framework
A new taxonomy organizes SSL methods by the underlying nature of supervision and learning objective:
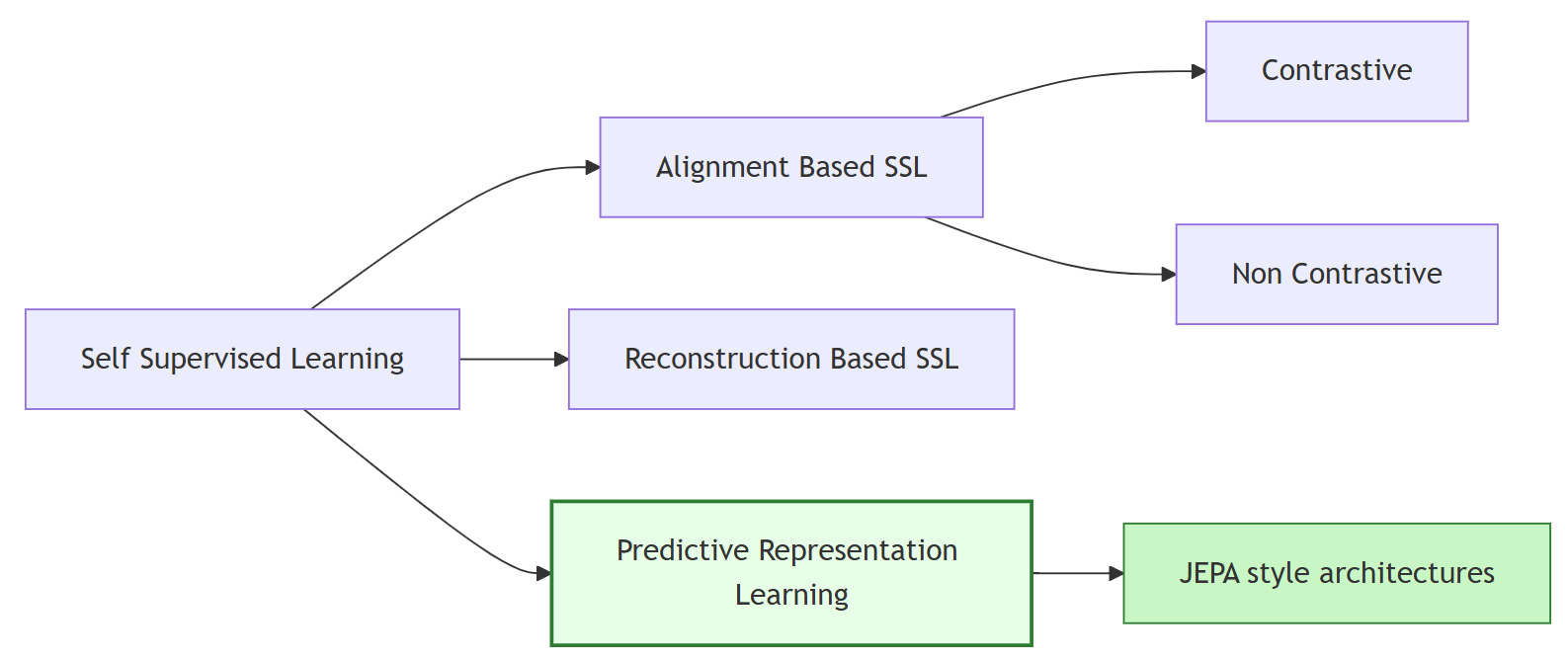
Figure 3: New taxonomy for SSL categorization distinguishing alignment, reconstruction, and predictive representation learning approaches.
This organization clarifies fundamental differences. Alignment and reconstruction operate under full or partially observed data, using loss signals (instance invariance, recovery error) tied to observed information. PRL, on the other hand, operationalizes supervision around the predictive structure, focusing on learning dependencies that generalize to unobserved contexts.
Collapse Avoidance Mechanisms
Each SSL family uses distinct collapse prevention:
- Contrastive: Explicit negatives (InfoNCE).
- Non-Contrastive: Predictor asymmetry, stop-gradient.
- Reconstruction: Pixel-level fidelity.
- Predictive/PRL (JEPA style): Directional prediction of diverse targets from context, inducing a partitioned, informative latent space even without negatives or explicit reconstruction losses.
Theoretical and Practical Implications
PRL provides several benefits over alignment and reconstruction:
- Enforces abstraction and structural representation beyond input similarity.
- Naturally supports modeling under partial observability, critical for generalization in real-world, multimodal, or sequential domains.
- Avoids bias toward low-level details, addressing a central weakness of reconstruction approaches.
- Yields robustness, evidenced by empirical comparisons, facilitating transferability.
However, challenges remain. Theoretical analysis of why and when directional predictive objectives stabilize is still lacking. Scaling PRL to long temporal horizons, cross-modal prediction, and embodied/interactively learned representations are critical future directions.
Conclusion
This paper reframes the landscape of self-supervised learning with the formal introduction of Predictive Representation Learning as a distinct paradigm. Through taxonomy, architectural and empirical analysis, PRL (particularly in the form of JEPA) is demonstrated to fundamentally differ from and often outperform alignment-based and reconstruction-based SSL in robustness and domain generality. While predictive objectives enable scalable, abstract, and world-model-capable representations, open challenges persist—particularly around theory, benchmarking, and application to embodied agents. The broader adoption and continued theoretical investigation of PRL are likely to impact future developments in foundation models and autonomous machine intelligence.
Reference: "From Alignment to Prediction: A Study of Self-Supervised Learning and Predictive Representation Learning" (2604.13518)