- The paper’s main contribution is the identification of a ‘variance wedge’ where AI-induced mean time savings lead to longer workflow delays due to rework variability.
- It employs an M/G/1 queueing model with feedback mechanisms to derive precise conditions under which increased service-time variance offsets average processing gains.
- Empirical calibration and regime transitions highlight that optimal AI adoption depends on balancing mean task acceleration with the costs of increased rework and reviewer congestion.
Queueing-Theoretic Paradigm Shifts in AI-Assisted Workflows
Introduction: Revisiting AI Productivity Metrics
The paper "Queue & AI: When Faster Tasks Slow Down the Workflow" (2605.27202) interrogates dominant productivity metrics used to assess generative AI deployment in organizational workflows. Contrary to mean-based measurements—such as average tasks completed per worker-hour or mean handle time—this work posits that such metrics can significantly misrepresent AI's effects, especially when tasks accumulate and must compete for constrained human attention within a queueing structure. By formalizing the problem through classical queueing theory, specifically an M/G/1 framework with feedback for escaped errors, the authors provide analytical conditions where AI-induced mean savings in task completion paradoxically lead to increased workflow delay, a phenomenon they refer to as the "variance wedge".
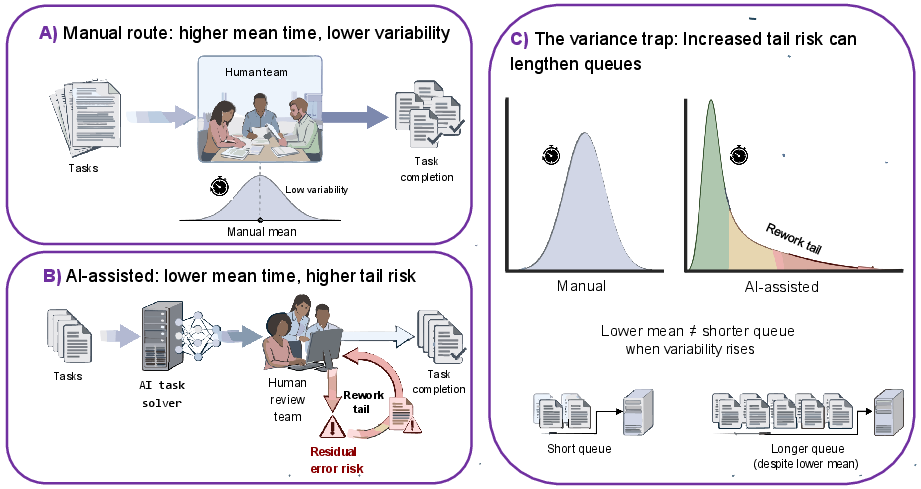
Figure 1: Schematic representation of manual and AI-assisted workflow routes demonstrating shift in service-time distribution due to AI-induced faster average completion but heavier tails from rework.
Model Construction: AI-Driven Service-Time Dynamics
The organization is modeled as a single-server queue where tasks are routed either to manual handling or AI-assisted processing. In the AI-assisted arm, the AI generates a draft rapidly, followed by human review, with the possibility of downstream rework if errors escape initial inspection. Service time for a task is therefore a random variable, exhibiting lower mean due to AI's acceleration but a pronounced right tail from rework events.
The authors derive closed-form expressions for steady-state mean waiting time (Wq) using the Pollaczek–Khinchine formula. Wq depends on mean (m(x;r)) and second moment (q(x;r)) of the mixed service-time distribution as well as system load. Crucially, increased variability from AI-induced rework can overwhelm mean savings, leading to longer queues despite faster task completion.
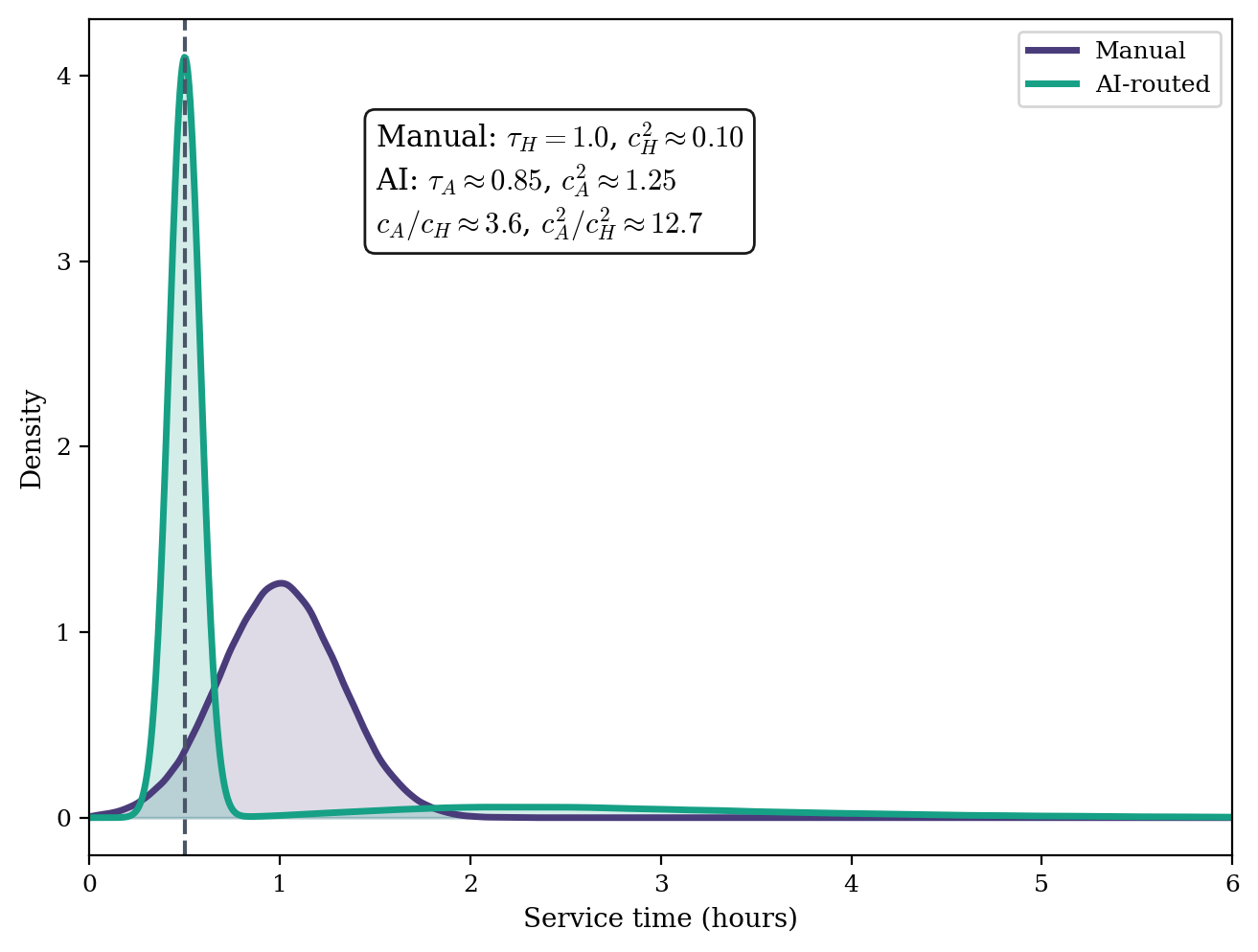
Figure 2: Empirically simulated distributions comparing manual and AI-routed handling service times; AI route exhibits spike-and-tail, indicating rapid completion counterbalanced by rare but costly downstream rework.
Analytical Results: Variance Wedge and Thresholds
Variance Wedge Condition
A formal comparison between pure manual and pure AI-routed workflows reveals that AI reduces waiting time only if the increase in service-time variability (cA2) does not exceed a derived threshold relative to mean savings. This threshold, the "AI variance budget", is large when AI significantly reduces average task time or the manual system is close to saturation.
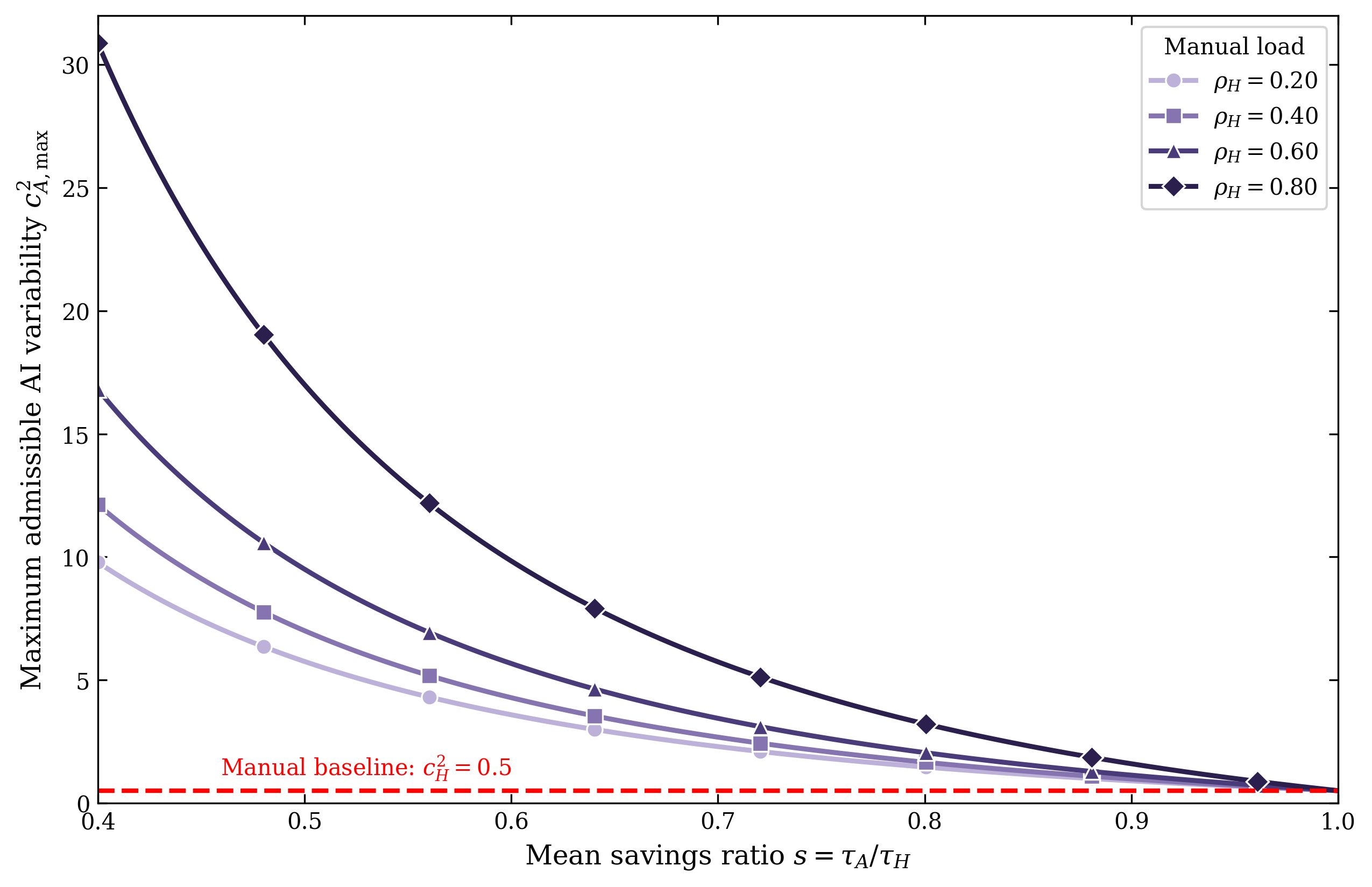
Figure 3: Maximum admissible AI-induced service-time variability as a function of mean-savings ratio, stratified by manual system utilization—reveals rapid shrinkage of tolerance to AI variability as mean savings decrease.
Empirical calibration in the paper demonstrates that with modest mean savings and high variability due to AI-driven rework, organizational queues can become substantially slower, even though individual tasks are completed faster on average.
Partial Adoption and Regime Transitions
The model supports monotonicity in the waiting-time objective with respect to AI adoption: either full manual or full AI routing is optimal, depending on whether the variability threshold is satisfied. A critical adoption fraction (xc) is precisely characterized for stabilizing previously overloaded manual queues; only sufficient adoption combined with genuine reduction in total human attention (including review and expected rework) can restore system stability.
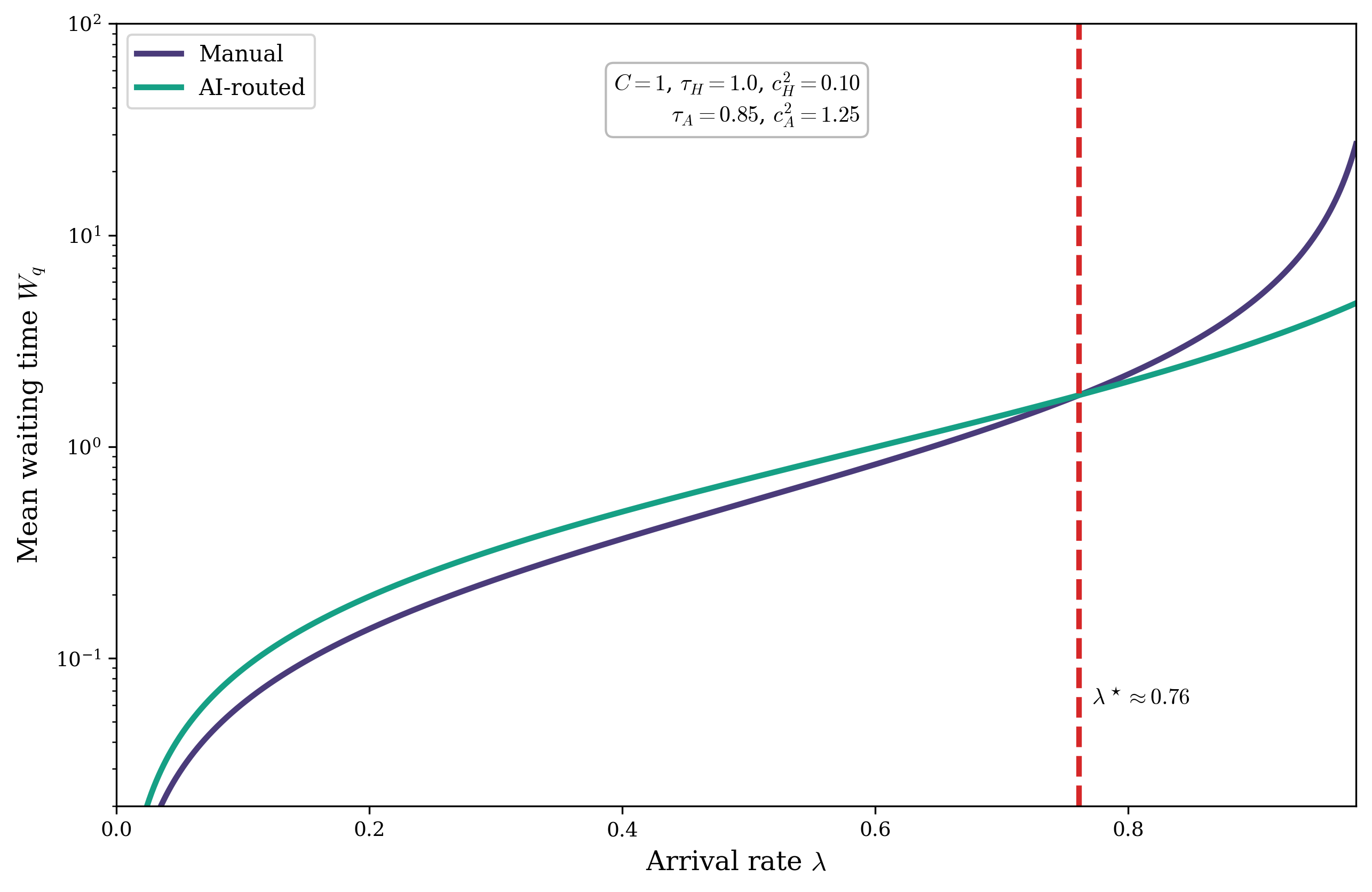
Figure 4: Mean waiting times for manual and AI-routed handling as function of arrival rate; crossover point demonstrates regime transition where AI routing only outperforms in highly congested environments.
Selective Verification and Congestion-Driven Review Thresholds
A salient implication concerns reviewer behavior under congestion: as load increases, the rational response is not to intensify scrutiny but to elevate the error-risk threshold for review, passing through more drafts unchecked and spending less effort even on drafts that warrant inspection. This endogenous under-verification is analytically derived via first-order optimality in a congestion-cost framework.
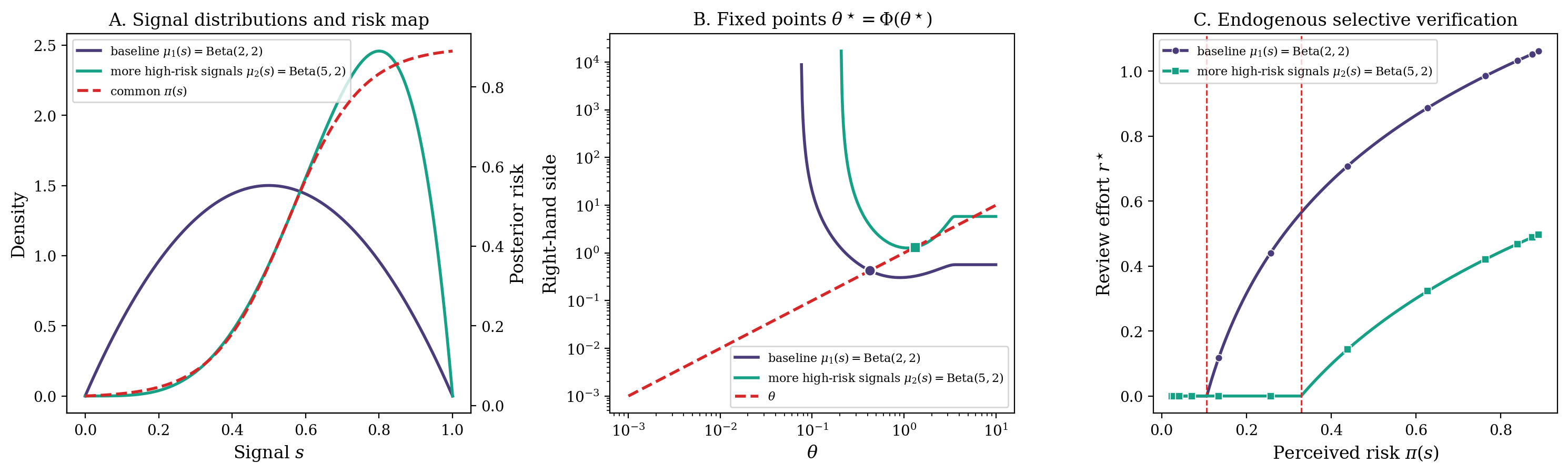
Figure 5: Congestion-driven verification equilibrium; higher prevalence of high-risk drafts elevates reviewer selectivity threshold, reducing overall review effort at fixed perceived risk.
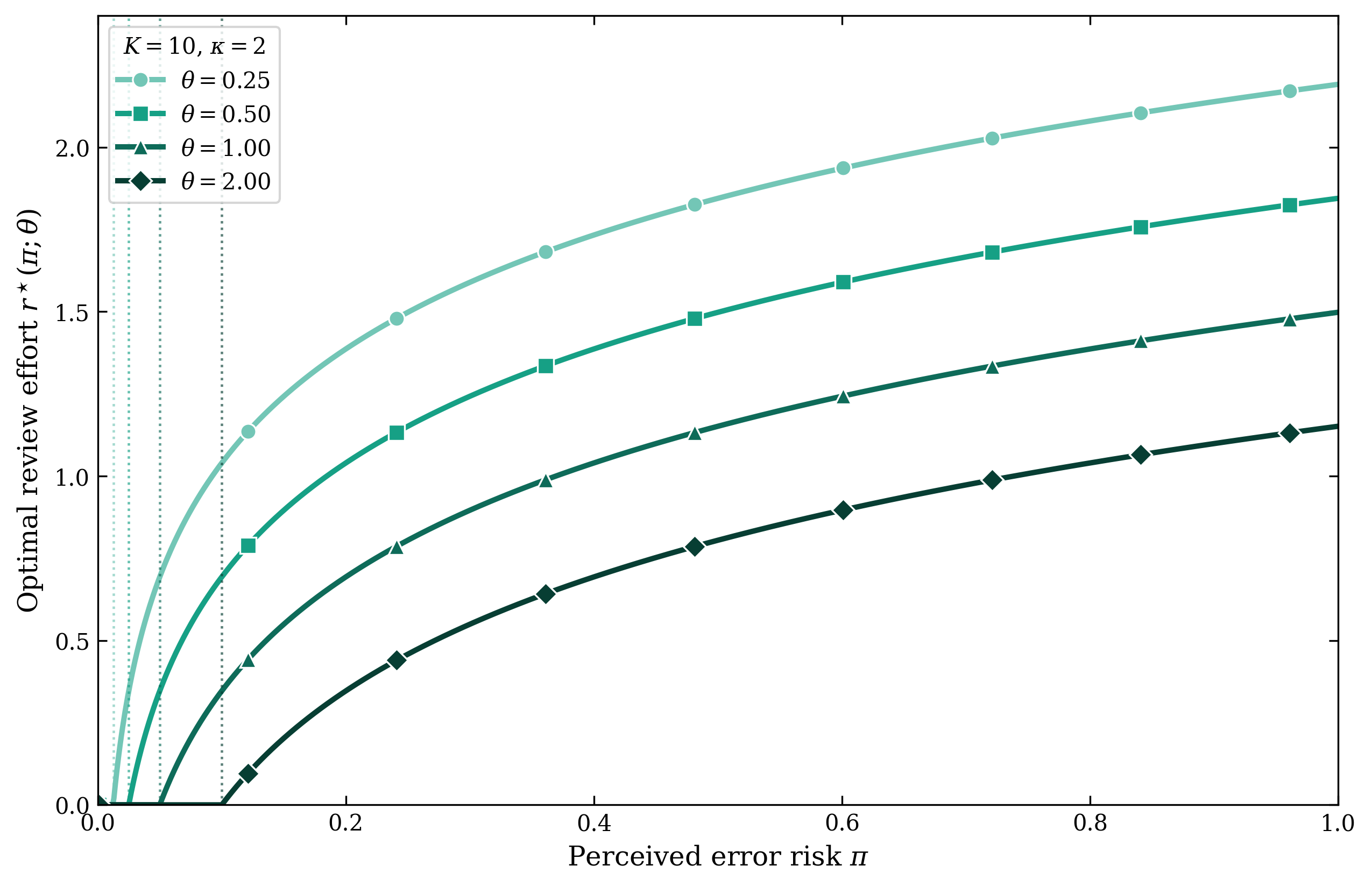
Figure 6: Review effort as function of perceived error risk; increasing reviewer time cost (congestion) shifts threshold right, diminishing review intensity across the risk spectrum.
This mechanism operationalizes theories on automation bias and complacency but grounds them in rational economic response to queue congestion, rather than cognitive limitations.
Practical and Theoretical Implications
The findings reveal that standard productivity metrics—focused on average task speed—may systematically overstate organizational benefits of AI deployment. Critical operational factors are the full distribution of service times, particularly the tails from escaped errors, and the dynamic feedback between review load and queue length. The variance wedge and selective verification regimes highlight the risk of deploying AI in environments lacking robust downstream audit and error measurement, especially when AI-induced mean savings are modest and reviewer capacity is scarce.
Theoretically, the paper's abstraction generalizes to any workflow technology that produces spike-and-tail distributions in service time, including non-AI forms such as process automation, outsourcing, or junior worker delegation.
Future research directions include:
- Modeling multi-layer human review with tiered queue constraints.
- Incorporating bursty arrivals and non-homogeneous task distributions.
- Analyzing adversarial error placements and randomized inspection policies.
- Examining queue dynamics with endogenous AI quality improvements and feedback learning.
- Extending empirical calibration to capture rare tail events and rework flows.
Conclusion
This work provides a rigorous queueing-theoretic framework for evaluating AI-assisted workflows, establishing conditions where faster mean task completion paradoxically increases organizational delays due to variability induced by rework. It reorients productivity measurement from mean-based statistics to system-level performance, emphasizing the importance of second moments and resource allocation. The recommendations for deployment testing are concrete: measure the total distribution of human-attention time (including downstream rework) and assess against precise variance wedge conditions. As generative AI continues to proliferate in operational contexts, these insights are critical for ensuring genuinely responsive, stable, and efficient organizational workflows.

