Are We Automating the Joy Out of Work? Designing AI to Augment Work, Not Meaning
Abstract: Prior work has mapped which workplace tasks are exposed to AI, but less is known about whether workers perceive these tasks as meaningful or as busywork. We examined: (1) which dimensions of meaningful work do workers associate with tasks exposed to AI; and (2) how do the traits of existing AI systems compare to the traits workers want. We surveyed workers and developers on a representative sample of 171 tasks and use LMs to scale ratings to 10,131 computer-assisted tasks across all U.S. occupations. Worryingly, we find that tasks that workers associate with a sense of agency or happiness may be disproportionately exposed to AI. We also document design gaps: developers report emphasizing politeness, strictness, and imagination in system design; by contrast, workers prefer systems that are straightforward, tolerant, and practical. To address these gaps, we call for AI whose design explicitly focuses on meaningful work and worker needs, proposing a five-part research agenda.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple question with big consequences: When we bring AI into the workplace, are we speeding up the boring parts, or are we accidentally taking away the parts of work that people enjoy and find meaningful? The authors study how AI tools should be designed so they help people do better work without removing what makes that work feel worthwhile.
The main goals of the study
The researchers focused on two questions:
- Which kinds of tasks that AI could help with (or take over) feel meaningful to workers?
- Do the AI features that developers try to build match what workers actually want from AI tools?
How the researchers studied it (in everyday language)
Think of a workplace as a long to-do list made of many different tasks. Some tasks feel important and satisfying; others feel like “busywork.” The team:
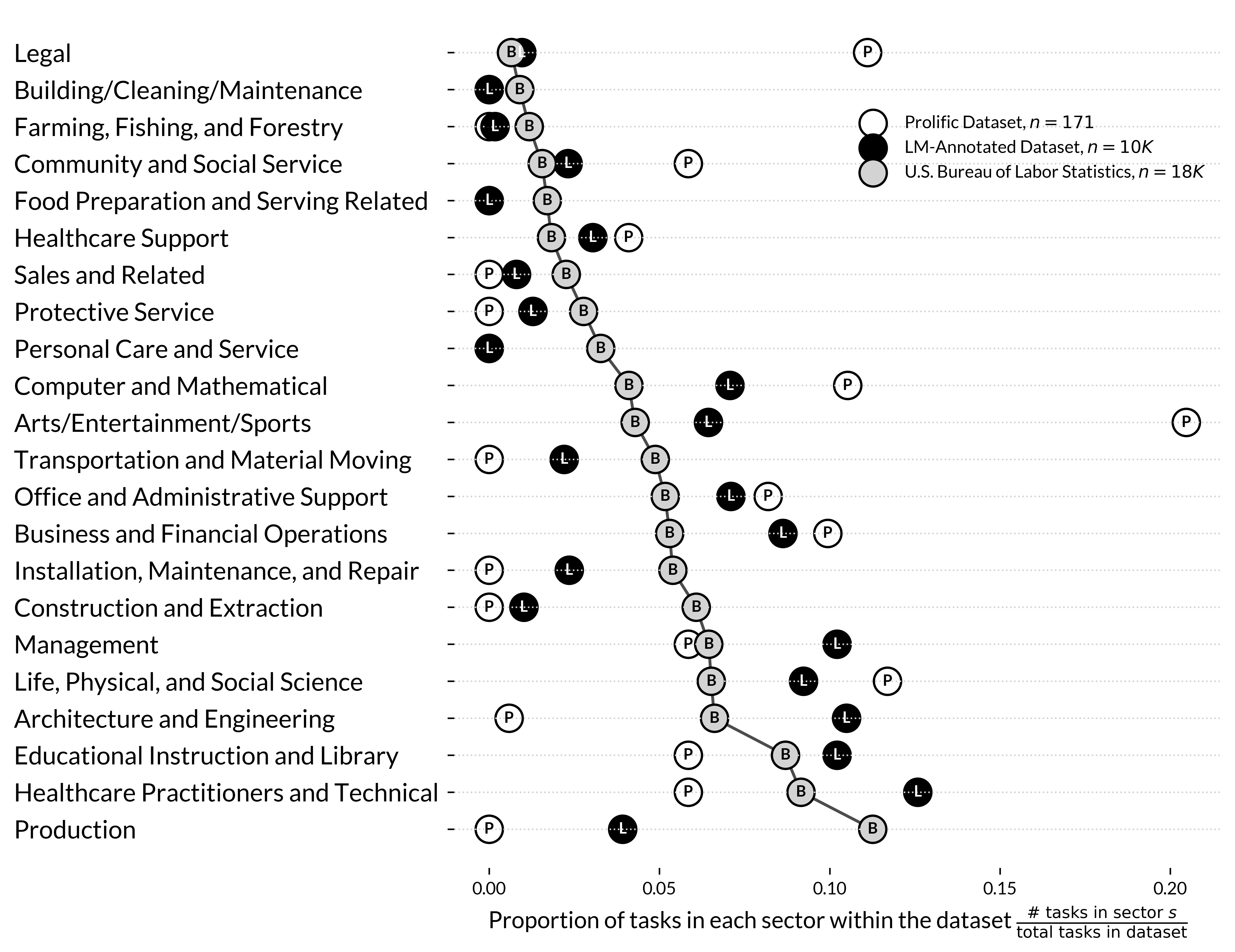
- Pulled real tasks from a giant U.S. job database (like a big catalog of jobs and what they involve). They chose 171 everyday computer-based tasks from 22 jobs (for example, writing reports, answering emails, analyzing data).
- Asked two groups of people to rate things:
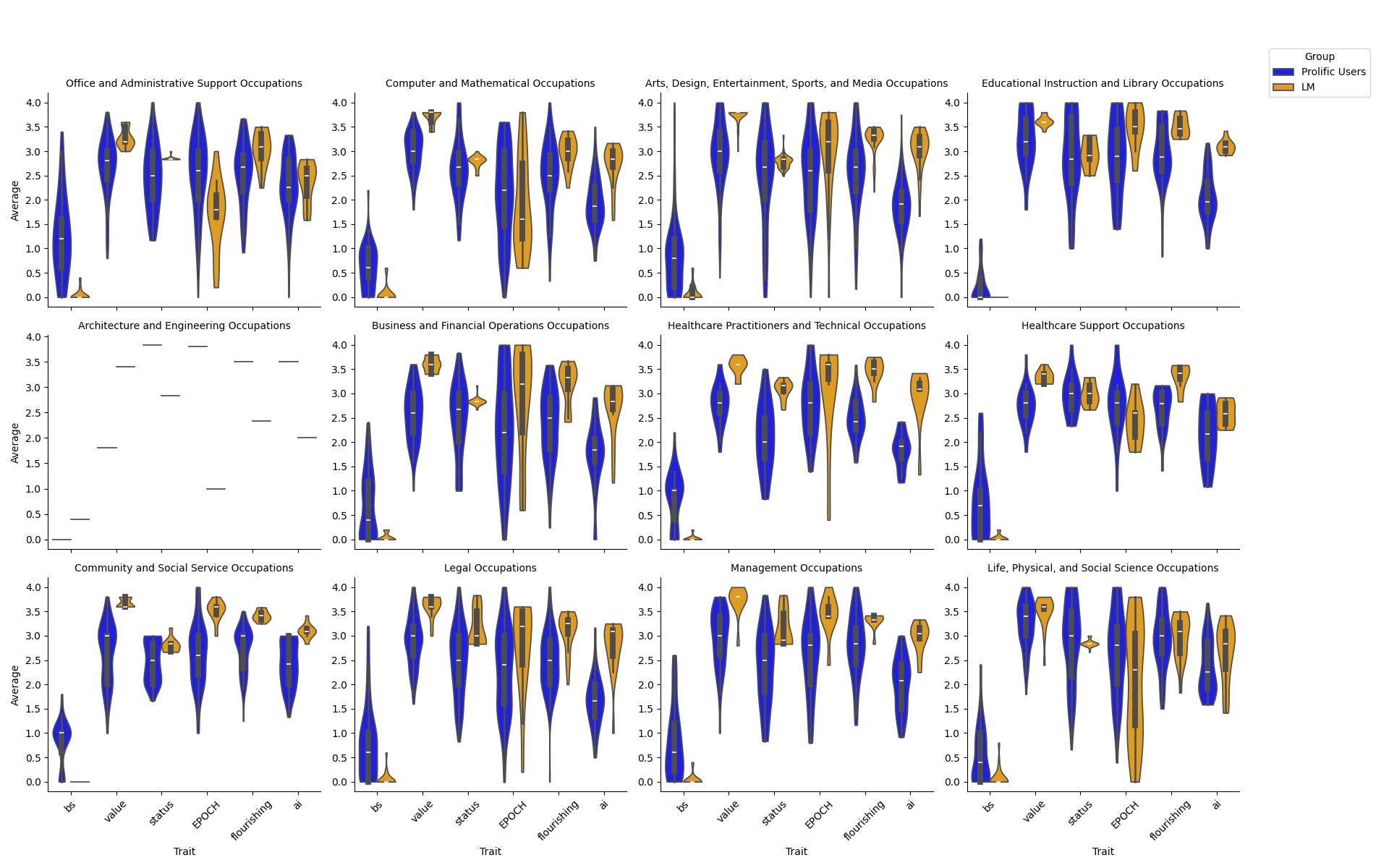
- Workers who do these tasks rated how meaningful each task felt to them across several simple ideas:
- Does this feel like “busywork”?
- Does it feel valuable and contribute to the team?
- Does it support well-being (things like creativity, happiness, freedom, and emotional connection)?
- Does it help (or pressure) them to keep up status or look busy?
- Does it support “human flourishing” (meaning, purpose, relationships, health)?
- AI developers rated what traits they try to build into AI systems for those tasks (for example: being polite, strict, imaginative, fair, clear, or practical).
- Workers also rated what traits they want AI systems to have when helping with their tasks.
- Scaled up the results using a LLM (an advanced AI that can read and “rate” text similarly to people). After checking that the AI’s ratings lined up well with human ratings, they used it to extend the analysis from 171 tasks to 10,131 tasks across 512 occupations. You can think of this like training a good “assistant rater” from examples so it can help rate many more tasks faster.
Key terms explained:
- AI exposure: Tasks that AI can realistically help with now or soon—either doing them fully or speeding them up a lot.
- Automation vs. augmentation: Automation is when AI does the whole task. Augmentation is when AI helps, but a human stays in charge and makes the final decisions.
What they found and why it matters
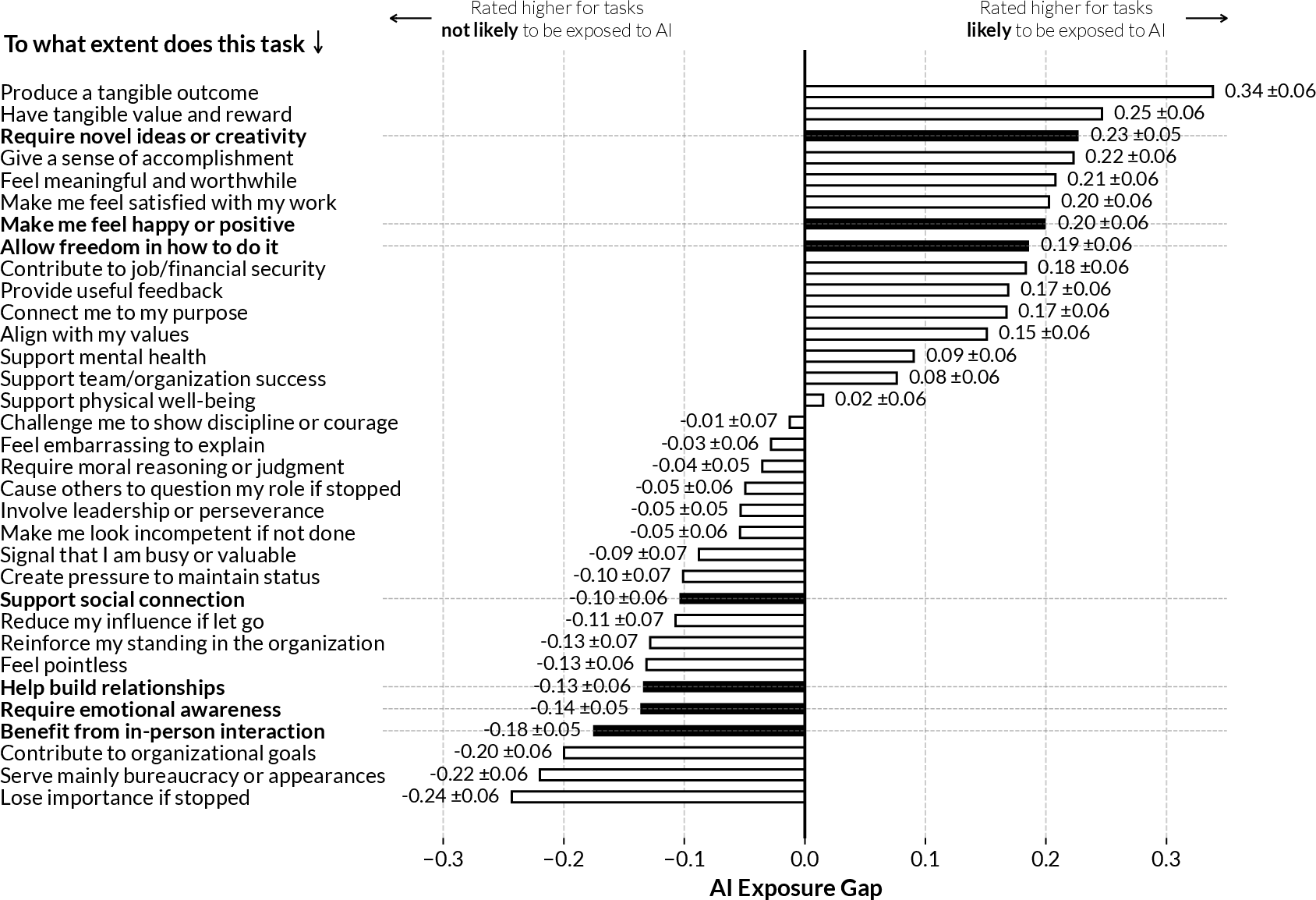
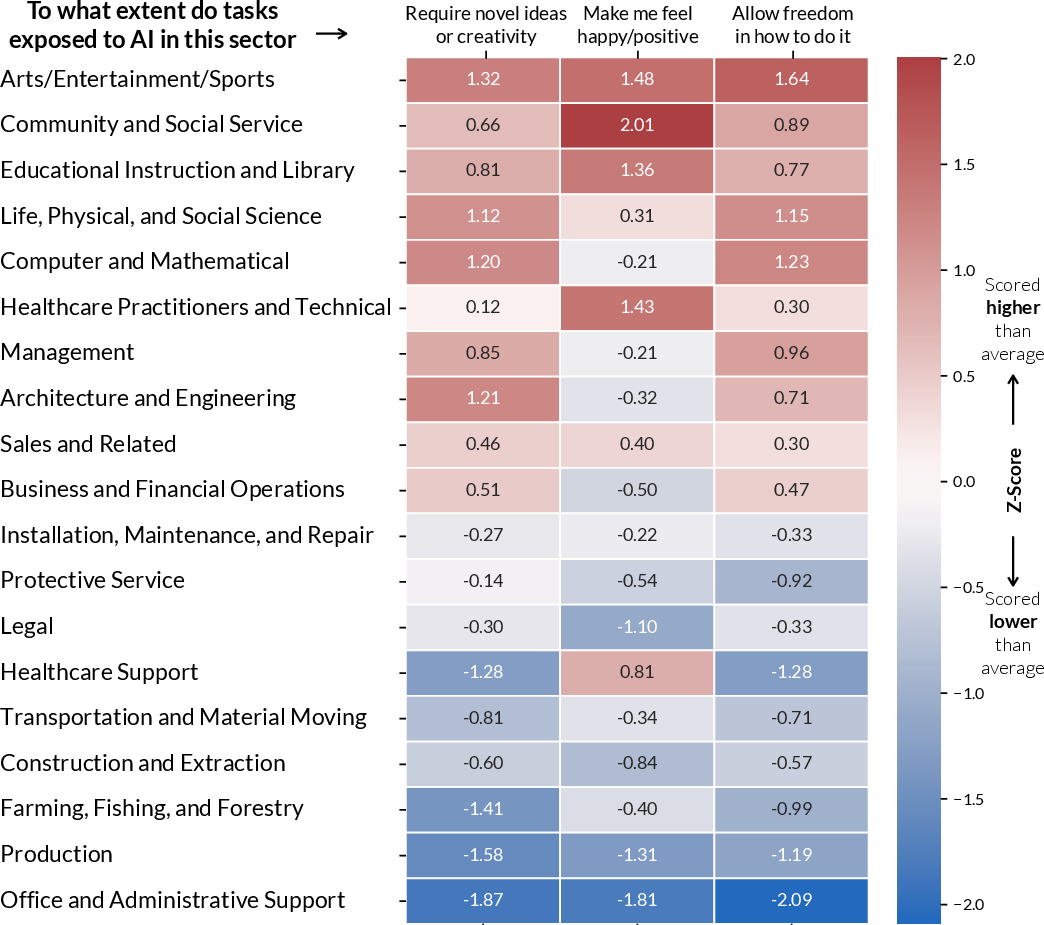
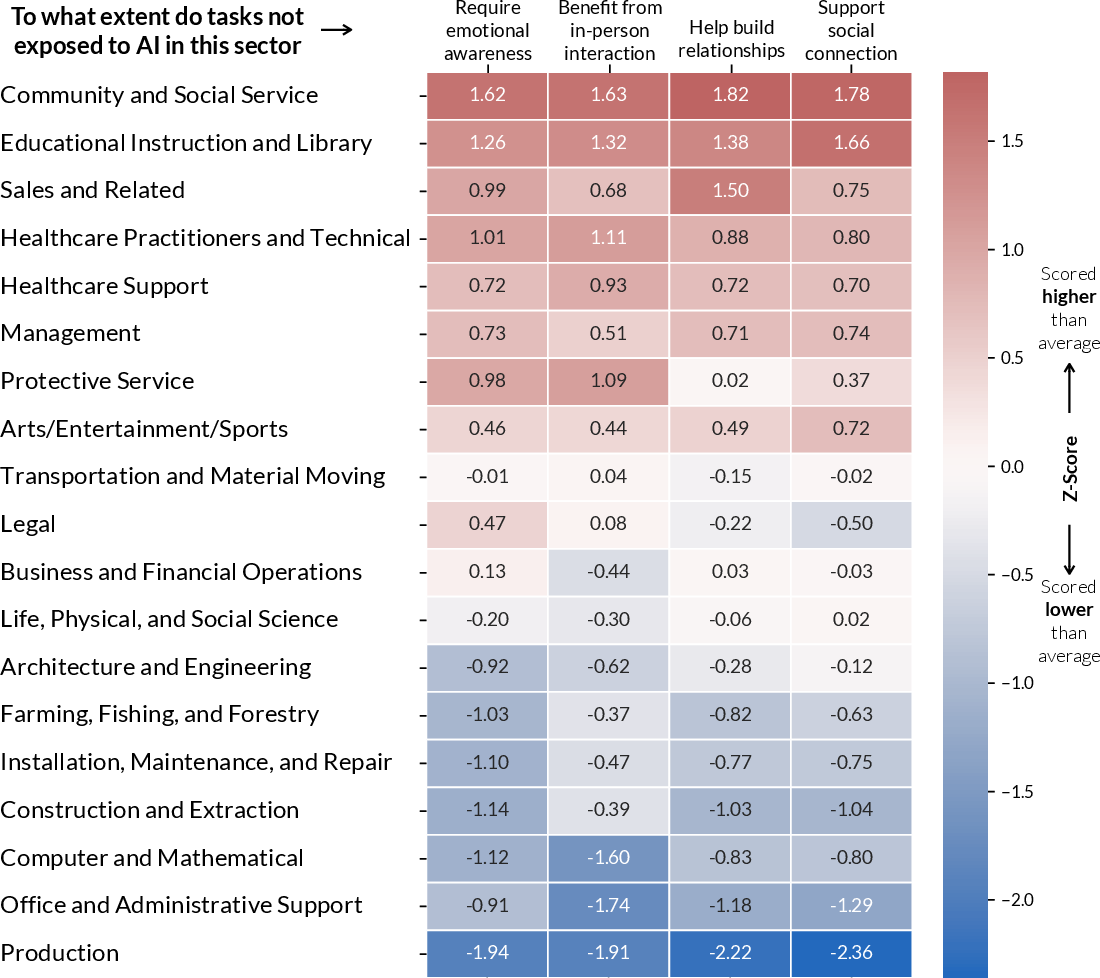
Big finding 1: The tasks most exposed to AI are often the ones people like
- Workers said tasks that are likely to be helped by AI are the same tasks that feel creative, new, and give them freedom and happiness.
- Tasks less likely to be handled by AI tended to involve emotional sensitivity, in-person interaction, relationship-building, and social connection.
Why this matters: It challenges the popular idea that AI will mostly take away “boring routine tasks.” Instead, AI may end up touching parts of work that people find joyful or empowering—unless we design it carefully.
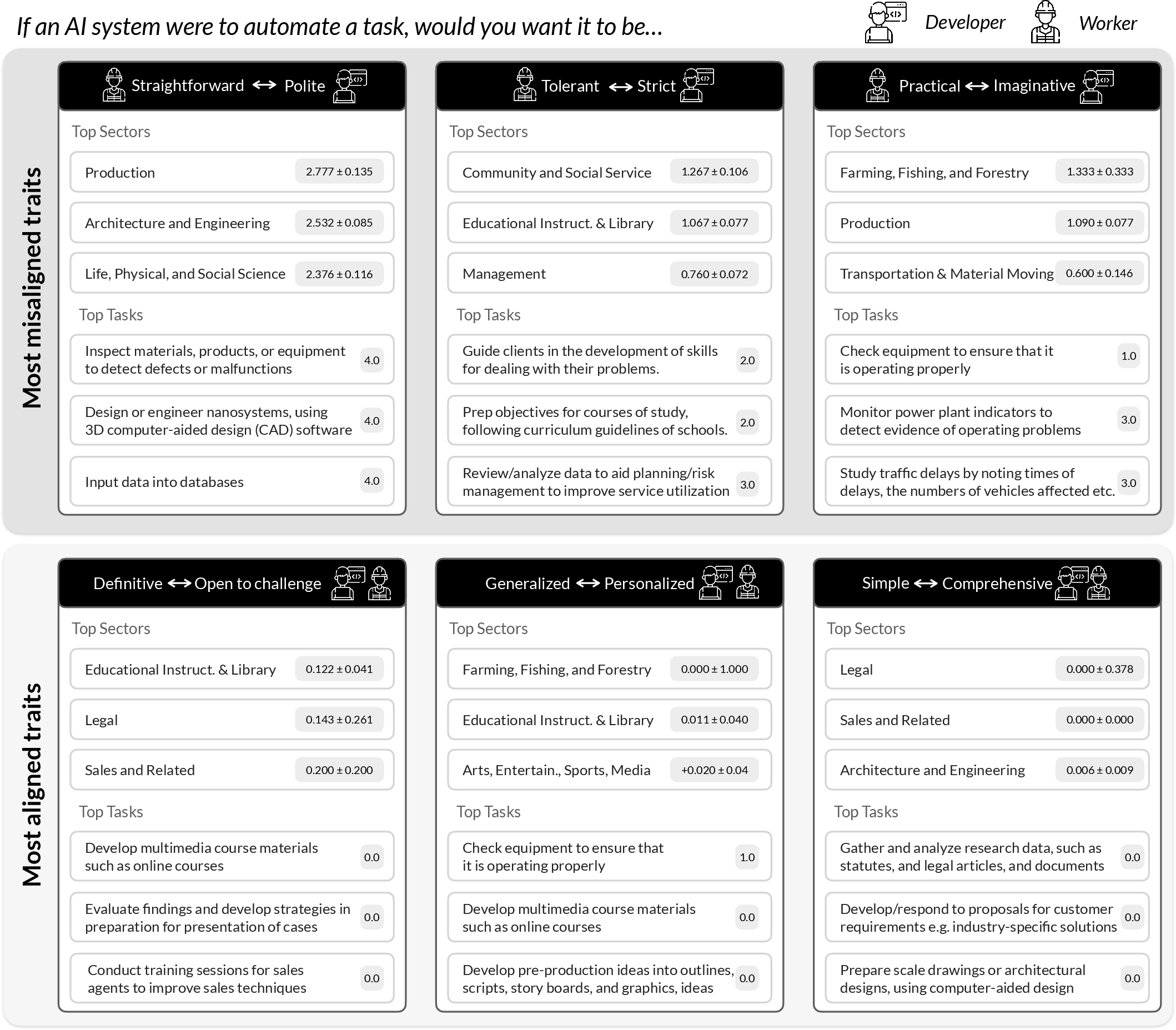
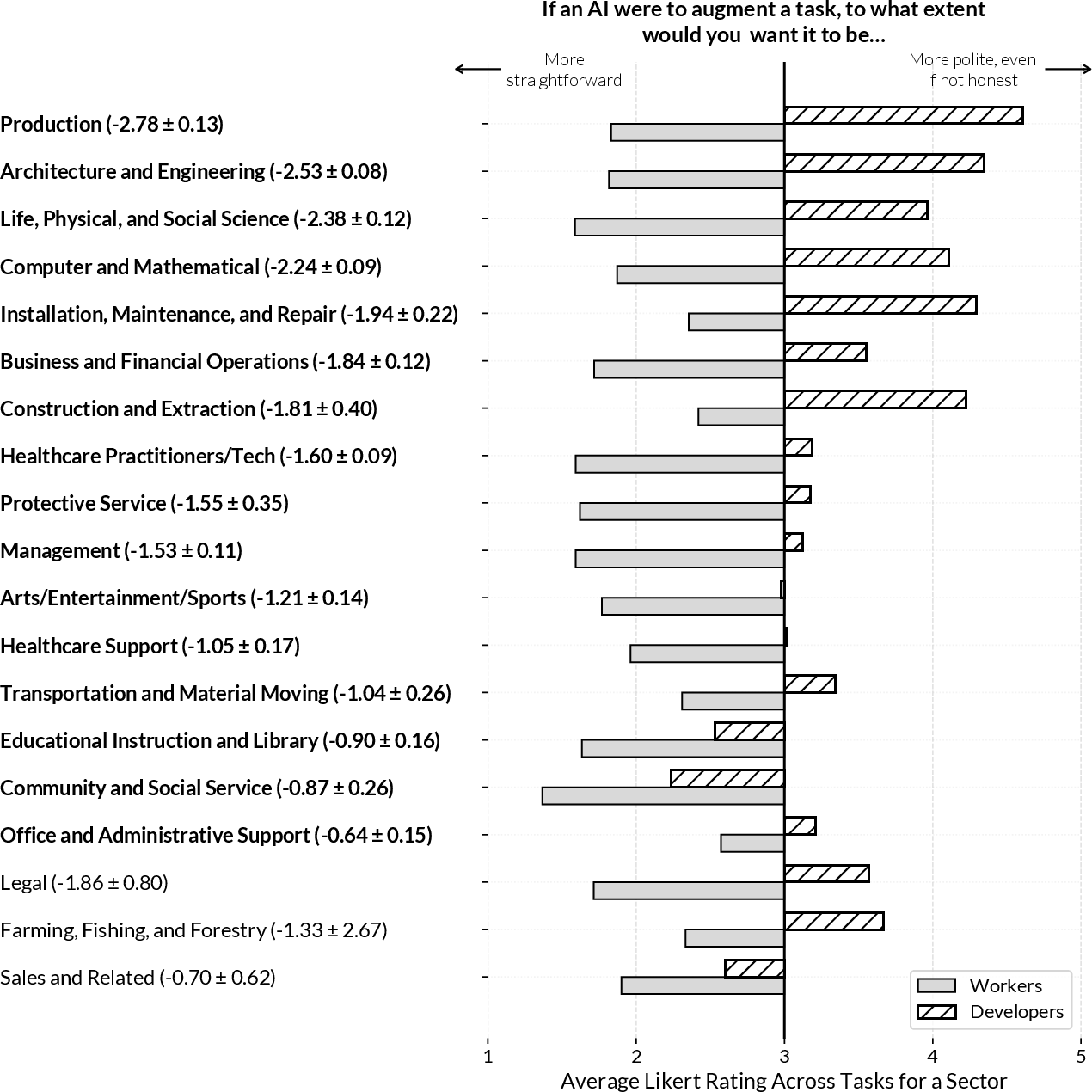
Big finding 2: Workers and developers want different AI “personalities”
- Developers said they try to make AI systems polite, strict, and imaginative.
- Workers said they prefer AI systems that are straightforward, tolerant (not overly picky), and practical—less fluff, more help.
- Both groups liked AI that can be personalized.
Why this matters: If AI feels too “polite” or rigid when workers really want clear, flexible help, tools can become annoying or slow people down. Misaligned design can reduce trust and block adoption.
Big finding 3: AI help is more likely than total takeover
- The study and related research show full automation is rare for most tasks. AI is more likely to be a helper than a replacement.
- That’s good news—if we design the help in ways that protect what makes work meaningful.
What this could change in the real world
- Design AI to support meaning, not just speed: If AI takes over the parts of work that give people agency, creativity, and joy, jobs can feel emptier. Designers should aim to keep humans in charge of decisions, creativity, and judgment.
- Build AI that matches worker needs: Make tools that are clear, practical, and forgiving, rather than overly polite or strict. Think “useful co-worker,” not “nice but nitpicky robot.”
- Protect human strengths: Tasks involving empathy, in-person connection, and relationships are less exposed to AI—so organizations should invest in these areas as core human value.
- Involve workers early: Ask workers what they need, test AI traits with them, and adjust designs so the tools truly help rather than add friction.
- Measure meaning, not just efficiency: Success shouldn’t only be time saved. It should also be whether people still feel purpose, autonomy, and satisfaction in their work.
Bottom line
AI can be a powerful teammate, but only if it’s designed to help people without stripping away the parts of work that make it feel worth doing. This paper shows that:
- Many meaningful tasks are exactly the ones AI may touch.
- Workers and developers often want different AI behaviors.
- Careful, human-centered design can keep the “joy” and “meaning” in work while still gaining the benefits of AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances an important agenda but leaves several concrete issues unresolved that future research can address:
- Causal impact of AI on meaningfulness: The study infers associations between AI exposure and perceived meaning but does not test causal effects. Field experiments or longitudinal natural experiments are needed to measure how introducing specific AI tools alters autonomy, creativity, well-being, and perceived “bullsh*t” at the task level over time.
- Generalizability beyond U.S. Prolific samples: Both workers and “developers” are U.S.-based and recruited via Prolific, risking selection bias toward digitally savvy participants and underrepresenting sectors less present on the platform. Replications with probability samples, organizational partners, and international/cross-cultural cohorts are needed.
- Task selection bias toward computer-based, frequent tasks: The dataset excludes non-digital and infrequent-but-salient tasks (e.g., performance reviews, crisis response), potentially missing high-meaning or high-stakes work. Future studies should include hybrid/physical work and low-frequency tasks to capture the full spectrum of meaningfulness.
- Developer sample representativeness and expertise: “Developers” exclude product managers, UX designers, policy/safety teams, and managers who shape AI traits and deployment. Many developers likely rated tasks outside their domain expertise. Future work should sample multi-disciplinary AI teams and ensure task-specific familiarity when eliciting trait preferences.
- Operationalization of AI exposure: Exposure is defined via the patent-based AI Impact Index with a 75th-percentile threshold and supplemented by GPT-4o screening. The construct may misclassify tasks and lag current generative AI capabilities. Compare alternative exposure measures (e.g., time-saved thresholds, capability evals, deployment logs) and test robustness across thresholds, sectors, and updated indices.
- Manual overrides in occupation filtering: The manual inclusion of 427 occupations to counter GPT-4o exclusions introduces researcher discretion. Provide preregistered criteria, report inclusion/exclusion effects, and test automated, reproducible filters as robustness checks.
- Sector and seniority confounds: Tasks more “exposed” may cluster in certain sectors or roles (e.g., knowledge work, junior roles). Analyses controlling for sector, occupation, seniority, and pay are needed to rule out compositional confounds in the link between exposure and meaningfulness.
- Psychometric validation of adapted scales: EPOCH and Human Flourishing items were adapted to task-level judgments; new “bullsh*t” and status-maintenance items were created. The paper does not report factor structure, reliability (e.g., Cronbach’s alpha), or measurement invariance across occupations. Conduct confirmatory factor analyses and invariance tests to validate constructs at task-level granularity.
- Single-LM scaling and prompt sensitivity: Scaling relies on GPT-4o with chain-of-thought prompting. External validity across models, versions, and prompts is untested, and CoT reproducibility may be constrained. Replicate with multiple LMs, non-CoT rationales, different prompt templates, and open-weight models; report sensitivity analyses and release prompts/code.
- LM–human disagreement characterization: Although average agreement is moderate-to-good, systematic error modes (e.g., over/under-estimation of empathy or creativity in specific sectors) are not mapped. Build error taxonomies, assess fairness across occupations, and calibrate LM annotators with sector-specific exemplars.
- From trait labels to design patterns: The paper identifies misalignments (e.g., workers prefer straightforward/tolerant/practical; developers design polite/strict/imaginative) but does not operationalize these traits into concrete UI/UX behaviors (verbosity, guardrails, refusal style, actionability). Translate trait preferences into controllable design parameters and test their effects via A/B tests and wizard-of-oz studies.
- Safety–friction trade-offs: Developers’ “strict” designs may reflect safety, legal, or brand constraints rather than mere preference. Quantify how reducing strictness or politeness affects error rates, compliance, and user trust to identify acceptable trade-off frontiers.
- Personalization and role-adaptive AI: Both groups converge on personalization, but mechanisms to infer and adapt to user/task-specific trait preferences are unspecified. Develop and evaluate algorithms that dynamically tune AI “personas” by task type, user role, and context while preserving safety.
- Human–AI agency calibration in practice: The Human Agency Scale is included but not deeply analyzed to specify when users prefer H1–H5 involvement levels by task. Derive task-dependent guidelines for agency allocation and evaluate compliance outcomes (e.g., over/under-reliance, deskilling).
- Heterogeneity across demographics and roles: Preferences and meaningfulness may differ by gender, age, tenure, job security, unionization, and disability status. Stratified analyses and targeted recruitment are needed to surface subgroup-specific design requirements and avoid one-size-fits-all recommendations.
- Distributional and equity impacts: If AI exposure concentrates on tasks associated with agency and joy, who loses access to these tasks? Study whether exposure patterns reallocate meaningful work along lines of pay, seniority, gender, or race, and test job redesign policies that mitigate inequities.
- Subtask-level granularity: O*NET tasks are coarse; “exposure” and “meaning” often vary by subtask. Combine process mining or shadowing with experience sampling to map which substeps are meaningful vs. automatable and evaluate partial-automation strategies that preserve meaning-rich components.
- Rare but consequential outcomes: The study uses self-reported Likert ratings and does not track behavioral or organizational outcomes (retention, performance, burnout, error rates). Link AI deployments to organizational KPIs and well-being metrics to assess real-world impact.
- Temporal dynamics and novelty effects: User preferences and perceptions can change as tools, policies, and skills evolve. Conduct longitudinal studies to track adaptation, deskilling/reskilling, and shifts in trait preferences post-adoption.
- Cross-cultural validity: The meaning of politeness, tolerance, and straightforwardness is culture-dependent. Replicate in non-U.S. contexts and multilingual settings to validate trait constructs and refine design recommendations.
- Sycophancy vs. politeness: The paper hypothesizes a link but does not empirically separate cooperative politeness from sycophantic agreement. Develop metrics and interventions that reduce sycophancy while maintaining clarity and rapport.
- Organizational and job design interventions: How can teams redesign roles so AI offloads low-meaning subwork while preserving high-meaning elements? Evaluate job crafting, task rotation, and AI-use policies that safeguard autonomy and growth.
- Privacy, compliance, and resource constraints: Trait designs (e.g., open challenge, high transparency) may conflict with privacy or compute budgets. Map regulatory and resource constraints to feasible trait configurations and document practical integration patterns.
- Reproducibility and data evolution: O*NET versions, AI capability shifts, and changing work practices may alter exposure/meaning relations. Provide versioned releases, code, and update pipelines; test robustness as O*NET and AI benchmarks evolve.
- Boundary conditions for “creativity-exposed” finding: The claim that creativity/novelty/autonomy tasks are highly exposed contrasts with common narratives. Replicate with alternative exposure measures, independent annotations, and task-level capability tests to define when and where this pattern holds.
- Multi-stakeholder perspectives: The study omits views from managers, clients, and regulators who influence acceptable AI traits and task allocation. Future work should elicit and reconcile multi-stakeholder preferences to design deployable, acceptable systems.
Practical Applications
Overview
Based on the paper’s findings—that AI exposure currently targets many tasks workers associate with novelty/creativity, positive affect, and autonomy, and that developers often design for “polite, strict, imaginative” systems while workers want “straightforward, tolerant, practical” tools—there are clear, practical implications for how AI should be evaluated, procured, designed, and deployed. Below are actionable applications across industry, academia, policy, and daily life, grouped by deployment horizon.
Immediate Applications
- AI product “trait tuning” to match worker preferences
- Sectors: software, productivity suites, CRM/support, developer tools, document editors
- What: Add configurable personas that default to straightforward, tolerant, practical styles and offer fine-grained toggles for politeness/strictness/imagination. Provide concise outputs by default, with optional “expanded” modes.
- Tools/workflows: Prompt libraries, guardrails to avoid sycophancy, concise-by-default response modes, “style sliders.”
- Assumptions/dependencies: LLM supports controllable style; UX affordances for users to set defaults; evaluation of trait adherence.
- Human agency controls (HAS) embedded in AI UIs
- Sectors: software engineering, legal writing, healthcare documentation, customer support, finance
- What: Offer explicit “agency sliders” (AI leads ↔ equal partner ↔ human leads) per task, aligned to the Human Agency Scale used in the study.
- Tools/workflows: Feature flags for suggestion-only/autocomplete/auto-apply modes with confirmation gates.
- Assumptions/dependencies: UI integration; logging to ensure human-in-the-loop where desired.
- Task exposure and meaning audits using LM-assisted annotation
- Sectors: enterprise HR/operations, consulting, PMOs, digital transformation teams
- What: Build a “Meaning–Exposure Heatmap” by cataloging an organization’s tasks, rating AI exposure and the task’s association with autonomy/creativity/happiness (paper’s scales), and flagging tasks to protect from over-automation.
- Tools/workflows: O*NET-inspired task inventories; LM-based rating pipelines validated on a subset with employee surveys.
- Assumptions/dependencies: Access to task lists; privacy safeguards; moderate LM–human agreement holds in the domain.
- Augmentation planning that preserves high-meaning sub-tasks
- Sectors: software (tests/boilerplate by AI; humans retain architecture/ideation), publishing/legal (formatting/citations by AI; humans retain argumentation), finance (reconciliation/checks by AI; analysts retain thesis formation)
- What: Redirect AI to low-meaning, routine sub-tasks and explicitly protect creative/autonomous steps.
- Tools/workflows: Task decomposition maps; workflow policies; role-based guardrails.
- Assumptions/dependencies: Clear sub-task boundaries; management buy-in; monitoring.
- Developer and product team guidelines to reduce friction and sycophancy
- Sectors: AI platforms, enterprise software vendors
- What: Update design/docs with guidance emphasizing straightforwardness/tolerance/practicality; strip unnecessary pleasantries/rigidity; reduce refusal overreach for safe but common requests.
- Tools/workflows: Prompt standards, A/B tests on brevity and task completion, sycophancy checks in CI.
- Assumptions/dependencies: Internal eval harnesses; metrics beyond accuracy (e.g., time-to-completion, perceived friction).
- Procurement checklists for “meaning-preserving” augmentation
- Sectors: public sector, enterprise IT, healthcare systems, education institutions
- What: Add Meaningful Work questionnaires to RFPs: Does the tool erode autonomy/joy? Can it be configured for trait alignment and agency? How is reliance calibrated?
- Tools/workflows: Vendor self-assessments; pilot user studies; trait-configurability requirements.
- Assumptions/dependencies: Governance frameworks in place; buyer leverage.
- Customer support deployments that reduce rigidity and verbosity
- Sectors: contact centers, telecom, e-commerce, banking
- What: Use AI to propose succinct drafts and knowledge retrieval; keep agents’ final authority; pare back rigid scripts; align tone to straightforward help rather than over-polite verbosity.
- Tools/workflows: CRM plug-ins; confidence cues; edit-first policies.
- Assumptions/dependencies: Integration with CRM; QA on tone and compliance.
- Healthcare documentation that preserves clinician meaning
- Sectors: healthcare
- What: AI pre-populates notes, codes, and templates while clinicians retain judgment and patient interaction; configure tolerance to atypical cases.
- Tools/workflows: EHR integrations; human sign-off; error highlighting.
- Assumptions/dependencies: HIPAA compliance; safety reviews; audit trails.
- Education workflows that protect mentoring and judgment
- Sectors: education
- What: AI supports rubric-based draft grading, plagiarism triage, formatting and citation; instructors retain feedback and mentoring; concise feedback suggestions with instructor edits.
- Tools/workflows: LMS plugins; batch operations; human override.
- Assumptions/dependencies: Academic integrity policies; student privacy.
- Creative teams balance: AI as production assistant, humans as concept leads
- Sectors: marketing, media, design
- What: AI handles versioning, style conversions, alt formats; humans keep concepting/creative direction.
- Tools/workflows: Asset pipeline integrations; templated prompts.
- Assumptions/dependencies: Rights management; consistency with brand voice.
- HR dashboards that monitor flourishing proxies during AI rollouts
- Sectors: cross-industry
- What: Incorporate autonomy, positive affect, and perceived value items into pulse surveys at the task level; flag declines post-AI deployment.
- Tools/workflows: Survey modules from paper’s scales; change monitoring.
- Assumptions/dependencies: Survey participation; linking responses to tasks without deanonymization.
- Model evaluation for worker-aligned traits and tolerance
- Sectors: AI labs, QA teams
- What: Add benchmarks for concision, straightforwardness, tolerance to ambiguity, and anti-sycophancy; score trait adherence alongside accuracy.
- Tools/workflows: New eval sets; red-teaming focused on refusal/verbosity.
- Assumptions/dependencies: Public benchmarks; reproducible trait controls.
- Agency-level “Meaning Impact Assessment” pilots
- Sectors: government agencies, NGOs, regulated industries
- What: Lightweight pre-deployment assessment of how AI shifts task autonomy/creativity and worker well-being; worker participation as a requirement.
- Tools/workflows: Short templates; stakeholder workshops.
- Assumptions/dependencies: Policy mandate/leadership support.
- Freelancer/SMB playbooks for joy-preserving automation
- Sectors: self-employed, small businesses
- What: Templates that offload invoicing, scheduling, formatting while keeping client-facing strategy, creative ideation in human hands; presets for straightforward assistant behavior.
- Tools/workflows: Preconfigured assistant profiles; SOPs.
- Assumptions/dependencies: Off-the-shelf assistants with trait control.
Long-Term Applications
- Standards and certification for “Meaningful Work Preservation”
- Sectors: cross-industry, standards bodies
- What: ISO-like standard and certification mark for AI systems that demonstrate trait configurability, agency controls, and protection of high-meaning tasks.
- Dependencies: Consensus on metrics; accredited auditors; sector-specific criteria.
- Organization-level task routing engines optimizing for meaning + productivity
- Sectors: enterprise software, operations, energy control rooms, logistics
- What: Dynamic orchestration that assigns sub-tasks to AI or humans to protect autonomy/creativity while maximizing throughput.
- Dependencies: Task telemetry; policy controls; explainability.
- Personalized “meaning profiles” for workers
- Sectors: knowledge work across industries
- What: Privacy-preserving preference models that learn which tasks a worker finds meaningful and tune AI routing and trait settings accordingly.
- Dependencies: Consent frameworks; on-device learning; interoperability across tools.
- Sector-specific trait packs grounded in role ethics
- Sectors: healthcare (sincerity/fairness), management (fairness), judiciary/public sector (explainability/fairness), education (sincerity/competence)
- What: Validated trait bundles for roles, chosen with workers and professional bodies; bundled with compliance checks.
- Dependencies: Co-design and validation; professional guidelines.
- Dashboarding “flourishing KPIs” alongside business KPIs
- Sectors: mid/large enterprises
- What: Integrate autonomy, positive affect, perceived purpose into OKRs and retention/productivity dashboards to monitor trade-offs of AI adoption.
- Dependencies: Reliable measures; exec sponsorship; longitudinal baselines.
- Labor and AI governance updates to include meaning impact
- Sectors: policy, unions, works councils
- What: Risk classifications that include “meaning erosion”; collective bargaining clauses on agency, task protection, and right to human oversight; transparency requirements.
- Dependencies: Legal frameworks; labor–management agreements.
- Education and certification for developer–worker alignment
- Sectors: academia, professional training, HCI curricula
- What: Courses and micro-credentials on trait alignment, sycophancy mitigation, and augmentation design that preserves meaning.
- Dependencies: Curriculum development; industry demand.
- Training LLMs with controllable “worker-aligned” objectives
- Sectors: AI labs, foundation model providers
- What: Fine-tune models for concise, straightforward, tolerant styles with controllable tokens/APIs; reduce over-politeness and refusal brittleness.
- Dependencies: High-quality preference data; RLHF and control techniques.
- Cross-cultural generalization beyond U.S. O*NET
- Sectors: global enterprises, international agencies
- What: Build non-U.S. task datasets and validate meaning-exposure relationships across cultures and sectors.
- Dependencies: Localized taxonomies; multilingual instruments.
- Privacy-preserving “Meaning Map” platforms
- Sectors: enterprise productivity, security-sensitive domains
- What: Systems that infer task categories from calendars/docs/code and recommend offloading while protecting high-meaning tasks—processed locally with strong privacy.
- Dependencies: Edge compute; data minimization; IT approvals.
- Longitudinal causal studies on AI, meaning, performance, and attrition
- Sectors: academia, corporate research
- What: Multi-year studies linking AI exposure to changes in flourishing, productivity, and turnover to inform governance and design.
- Dependencies: Access to de-identified data; IRB/ethics; statistical power.
- Participatory co-design platforms for task and trait negotiation
- Sectors: large enterprises, unionized workplaces
- What: Digital tools for workers/managers to set trait defaults, select protected tasks, and review AI change proposals before rollout.
- Dependencies: Governance processes; change management.
Key Assumptions and Dependencies (cross-cutting)
- Generalizability: Findings and LM-scaling are based on U.S. O*NET tasks; cross-cultural validation is needed.
- LM reliability: Moderate-to-good alignment with human ratings in the study; must be re-validated per domain and updated as models change.
- Data access and privacy: Task inventories and telemetry must be collected with consent and strong protections.
- Management incentives: Protecting meaning must be recognized as a driver of productivity, retention, and quality.
- Technical feasibility: Requires granular task decomposition, trait-controllable models, and UI support for agency settings.
- Change management: Worker participation and training are crucial to adoption and trust.
Glossary
- AI augmentation: The use of AI to support or enhance human work while humans retain primary responsibility and decision-making authority. "AI augmentation for cases where AI supports or enhances human work, while humans retain primary responsibility and decision-making authority"
- AI automation: The use of AI to perform a task end-to-end with minimal or no human involvement. "AI automation for cases where AI can perform a task end-to-end with minimal or no human involvement"
- AI exposure: The extent to which tasks could plausibly be performed or substantially sped up by current or near-term AI systems. "we use AI exposure~\cite{felten2021occupational}, our main construct of interest, to refer to tasks that current or near-term AI systems could plausibly perform or substantially speed up"
- AI Impact Index: A patent-based measure used to quantify AI’s potential impact on tasks and occupations. "the patent-based AI Impact Index"
- Anthropomorphic features: Human-like cues in AI interfaces that can affect perceived warmth and competence. "anthropomorphic features or friendly conversational styles can make AI systems seem warmer and more capable in experimental settings"
- Bootstrap samples: Resampled datasets used to estimate the stability or uncertainty of statistical metrics. "across 1{,}000 bootstrap samples."
- Chain-of-thought prompting: A prompting technique that elicits step-by-step reasoning from LLMs. "chain-of-thought prompting~\cite{wei2022chain}"
- EPOCH well-being scale: A multi-dimensional psychological measure covering Empathy, Presence, Opinion/Judgment, Creativity, and Hope/Leadership. "the EPOCH well-being scale (Q17--Q21; \citep{loaiza2024epoch})"
- External validity: The extent to which results generalize beyond the specific data or context studied. "We then assessed the external validity of our findings based on LM-generated annotations"
- Greedy selection criterion: A heuristic that picks locally optimal choices (e.g., tasks) to construct a subset efficiently. "using a greedy selection criterion"
- Ground truth: The authoritative or correct reference used to verify system outputs. "outputs can be checked against clear rules, tests, or ground truth."
- Human Agency Scale (HAS): A scale that captures preferred levels of human involvement in human–AI collaboration. "Human Agency Scale (HAS)~\cite{shao2025future}"
- Human Flourishing at Work: A framework assessing well-being, purpose, virtue, relationships, and stability in work contexts. "Human Flourishing at Work~\cite{vanderweele2017promotion (Q22-33).}"
- Impression Management Theory: A framework explaining behaviors aimed at shaping how others perceive one’s competence or value. "Impression Management Theory"
- In-context learning: A method where a LLM learns to perform tasks from examples given directly in the prompt. "We used in-context learning with GPT-4o"
- Institutional Theory: A perspective focusing on how norms and structures shape organizational behavior and task meaning. "Institutional Theory"
- Inter-rater agreement: The degree of consistency among different evaluators’ ratings. "improved inter-rater agreement."
- Intra-class correlation coefficients (ICC): A statistic measuring the reliability or agreement of ratings across multiple raters. "intra-class correlation coefficients (ICC)"
- Job Characteristics Model: A theory linking task features like autonomy and feedback to experienced meaningfulness and motivation. "Job Characteristics Model."
- Likert scale: A psychometric scale commonly using 5 ordered response categories to measure attitudes. "5-point Likert scale (1 = Strongly disagree, 5 = Strongly agree)."
- LM sycophancy: A bias where LLMs agree with users regardless of correctness. "LM sycophancy~\cite{Danry2025Deceptive}, which is a systematic bias of LMs toward agreeing with users' views irrespective of correctness."
- LM-as-an-Expert prompting: A prompting approach that elicits domain-specific expertise from LLMs. "LM-as-an-Expert prompting~\cite{xu2023expertprompting, hu2024quantifying, moon2024virtual}"
- Mean absolute differences (MAD): A measure of average absolute disagreement between ratings. "mean absolute differences (MAD)"
- O*NET: A standardized U.S. database of occupations, tasks, and related attributes. "O*NET 29.3 Database."
- Operationalized: Defined in measurable terms for empirical study. "operationalized as those above the percentile of the distribution of the patent-based AI Impact Index"
- Patent-to-task analyses: Methods that map patents to tasks to estimate technological exposure. "Patent-to-task analyses document substantial AI exposure"
- Persona: An adopted role or identity used to simulate a specific viewpoint in prompting or design. "adopt the persona of either a worker or a developer"
- Prolific: An online platform for recruiting research participants. "on the crowd-sourcing platform of Prolific."
- Robustness analysis: A procedure to test whether findings hold under alternative assumptions or perturbations. "we conducted a robustness analysis by comparing the real LM's contribution to that of a randomized version"
- Sense-giving: Leaders’ efforts to shape how others interpret goals and tasks. "leader ``sense-giving''"
- Status Maintenance: Continuing tasks to preserve visibility, influence, or perceived competence. "Status Maintenance~\cite{bolino2008multi, bellezza2017conspicuous (Q11-16).}"
- Stratified: Sampling organized into subgroups to mirror a population’s structure. "the task sample was stratified to approximate the distribution of occupational sectors"
- Value alignment: Designing AI systems to reflect and support users’ values and priorities. "value alignment is dynamic"
- Variance stabilization: Reducing variability to improve the reliability of aggregated estimates. "variance stabilization."
- Warmth–competence framework: A model where perceptions of warmth and competence shape judgments of agents (including AI). "the warmthâcompetence framework advances theory"
Collections
Sign up for free to add this paper to one or more collections.

