- The paper introduces ATLAS, an atomic-source tracing pipeline that accurately attributes over 99.7% of 1.45M instances across RLVR datasets.
- It employs canonicalization, temporal index matching, and semantic similarity retrieval to uncover dataset overlap, contamination, and benchmark leakage.
- Empirical results validate that provenance-aware curation and decontamination substantially improve model generalization and reliable evaluation.
RLVR Data Provenance: Atomic-source Lineage Tracing and Quality Benchmarks
Introduction
The paper "RLVR Datasets and Where to Find Them: Tracing Data Lineage for Better Training Data" (2605.26971) addresses the escalating complexity and opacity in RLVR dataset provenance, introducing ATLAS—an atomic-source tracing pipeline—to systematically unravel dataset lineage, attribute over 99.7% of 1.45M instances to 20 atomic sources, and quantify contamination and learnability for RLVR dataset selection. This work defines the RLVR data ecosystem, exposes pervasive dataset overlap and benchmarking leakage, and sets forth a principled framework for constructing and benchmarking verifiable RL training data.
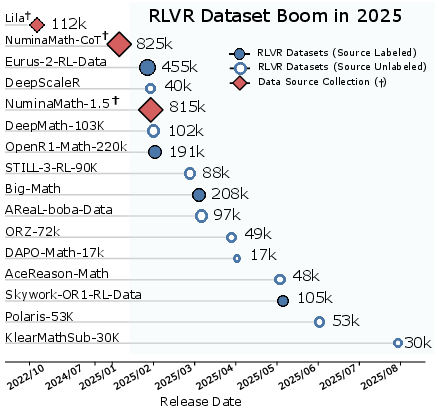
Figure 1: Timeline of RLVR dataset releases, highlighting the rapid expansion and the prevalence of "openly-closed" datasets with opaque provenance.
ATLAS Framework: Atomic-source Lineage Tracing
The ATLAS pipeline comprises three stages: canonicalization and temporal index matching, semantic similarity retrieval, and iterative source recovery. Canonicalization resolves schema heterogeneity—standardizing question-answer pairs and metadata for downstream matching. Temporal index matching employs SHA-1 hashes to efficiently track prompt identity and occurrence, while semantic matching leverages Sentence-BERT embeddings for high-sensitivity retrieval of paraphrased or transformed instances. Manual audits supplement automated matching to ensure robust attribution.
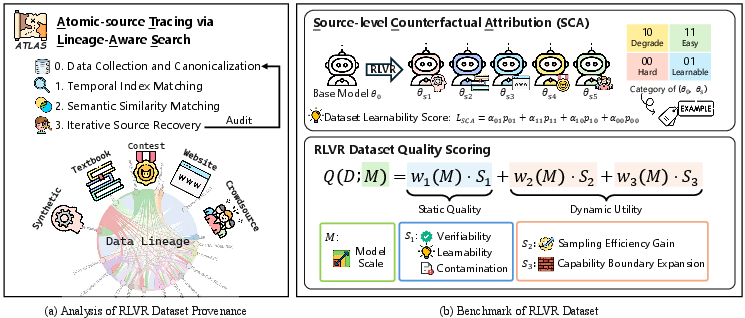
Figure 2: Overview of the ATLAS framework, encapsulating dataset provenance analysis and benchmarking.
ATLAS achieves near-complete attribution (<1% unknown instances), revealing that most RLVR datasets are downstream recompositions, frequently containing substantial overlaps originating from a small set of atomic sources. This exposes systemic issues in provenance collapse, recurring synthetic transformations, and the loss of data trust.
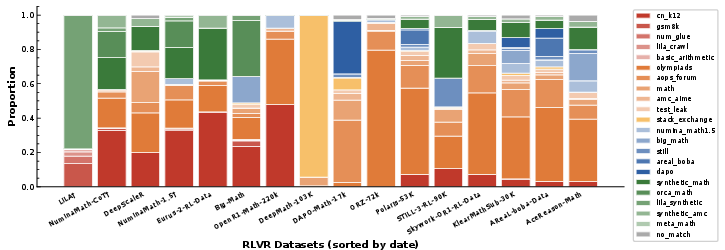
Figure 3: Atomic-source composition and relative proportions across RLVR datasets, identifying major source datasets and problem-type categories.
RLVR Dataset Landscape: Source Heterogeneity and Overlap
Atomic-source decomposition of RLVR datasets shows marked heterogeneity in problem types and source distributions, though many datasets reuse large portions of upstream collections such as NuminaMath-CoT and NuminaMath-1.5. Eurus-2-RL-Data notably transforms MCQ data into open-ended reasoning, boosting downstream utility and influencing other datasets.
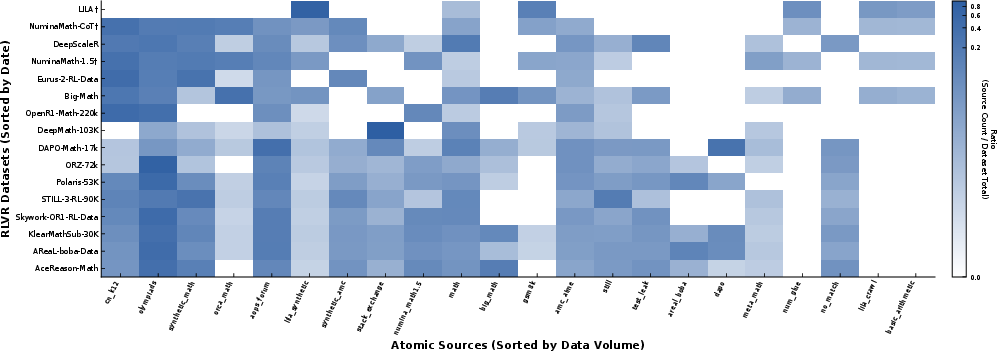
Figure 4: Atomic-source distributions across RLVR datasets, mapping the introduction of each source in the RLVR ecosystem.
Bokeh-style visualizations concisely capture compositional and overlap relationships, underscoring the need for provenance-aware data selection and cleaning.
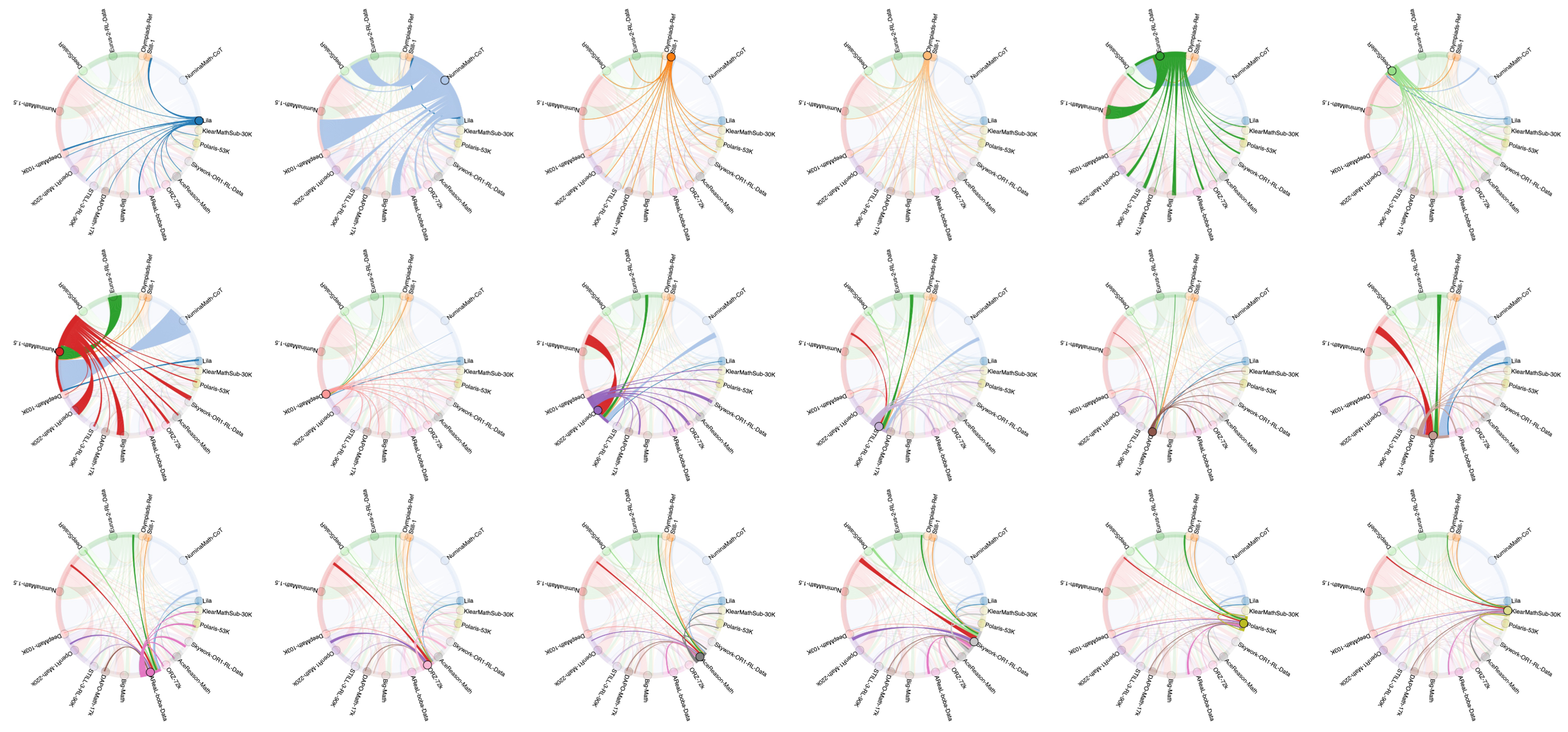
Figure 5: Compositional relationships and data overlaps among RLVR datasets.
Benchmark Contamination Analysis
Exhaustive pairwise similarity analyses between RLVR datasets and evaluation benchmarks reveal extensive benchmark leakage. Explicit inclusion (Omni-Math, HARP) and subtle format variations obscure contamination, with 36,148 leaked instances detected. Cases with superficial formatting changes but near-identical semantic content evade conventional rule-based filters.
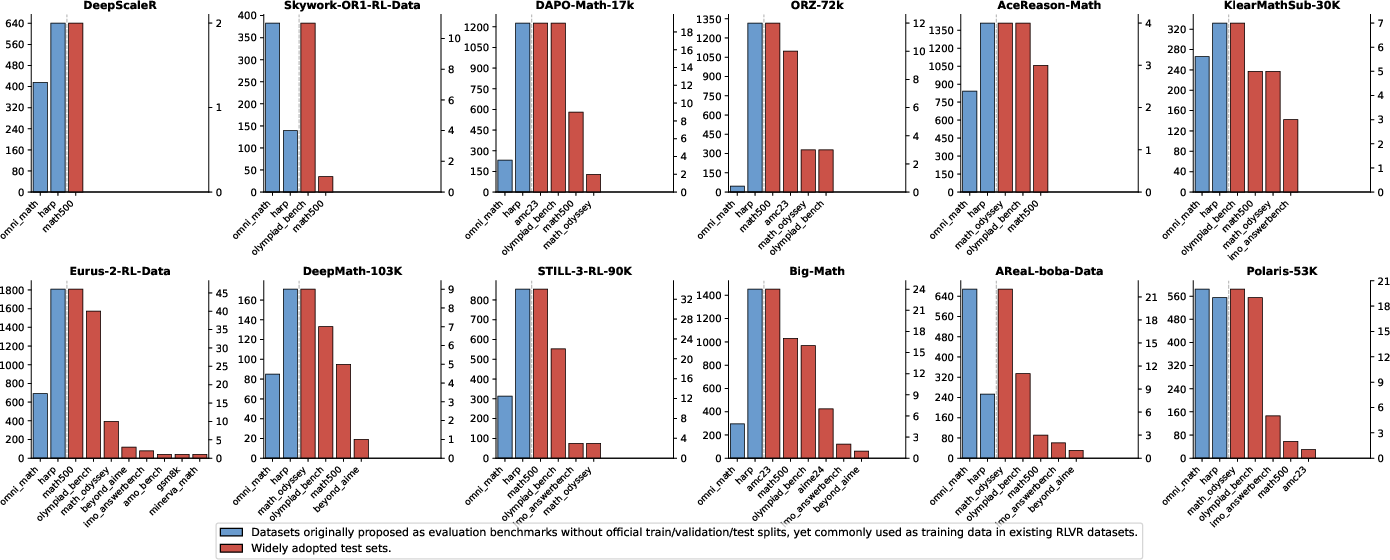
Figure 6: Leakage severity of RLVR datasets, quantified by semantic similarity to benchmark test sets.
High-confidence leakage (≥90% similarity) underestimates the true contamination extent, given lower-similarity matches (≈80%)—especially MCQ variants. This systemic contamination undermines fair model evaluation and signals the urgent necessity for rigorous data lineage and audit tools.
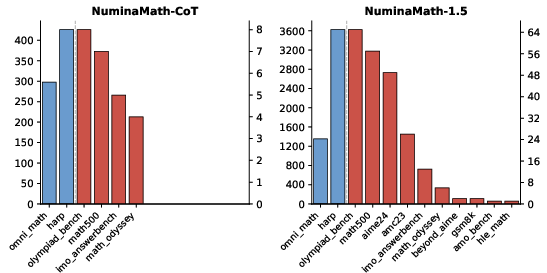
Figure 7: Benchmark leakage statistics for primary source datasets, measured via semantic overlap.
Source-level Counterfactual Attribution: SCA
The paper introduces Source-level Counterfactual Attribution (SCA), using atomic sources as minimally confounded intervention units. RL checkpoints are trained per-source and compared against base models, enabling instance-level learnability annotation and source utility estimation. Binary outcome categorization (00, 01, 10, 11) encodes solvability, learnability, degradation, and ease, supporting fine-grained analysis.
Dataset-level learnability is calculated:
LSCA=α01p01+α11p11+α10p10+α00p00
where p⋅ denotes category proportions and α⋅ are learnability weights.
Composite RLVR Dataset Quality Scoring
Three axes define dataset quality:
- S1: Static quality—verifiability, learnability (SCA), contamination robustness.
- S2: Sampling efficiency gain—Mean@N improvement, scale-adaptive.
- S3: Capability boundary expansion—Pass@N gain, scale-adaptive.
Composite quality score:
Q(D;M)=w1(M)S1+w2(M)S2+w3(M)S3
Scale-dependent coefficients prioritize empirical utility in larger models.
Empirical Results and Dataset Selection
Extensive RL experiments using Qwen3-1.7B-Base and Qwen3-8B-Base engines validate DAPO++—a decontaminated, curated dataset informed by ATLAS and SCA—as consistently yielding highest benchmark performance across scales. The composite Q score is strongly correlated with downstream performance (Spearman ≥0 and ≥1, respectively), confirming the efficacy of the benchmarking framework. Removal of contaminated or MCQ-heavy data improves model generalization and benchmark discrimination, challenging assumptions about the utility of leaked or synthetic data.
Ablation studies confirm verifiability and contamination as critical predictors of RLVR learning effectiveness: open-ended supervision outperforms MCQ, and systematic decontamination cleanses noise without degrading performance.
Implications and Future Directions
Practically, ATLAS and SCA lay a reproducible foundation for transparent RLVR data curation, benchmarking, and selection, mitigating contamination, and guiding domains ripe for exploration. Theoretically, the approach enables source-aware learning signal concentration, disentangling genuine reasoning gains from dataset artifacts or memorization effects.
The methodology anticipates increasing complexity in RLVR and LLM training corpora, and provides scalable audit tools for future large-scale provenance and contamination challenges. Further automation and integration with unified provenance standards are necessary for tracing older or deeply nested datasets.
Conclusion
This work demonstrates that atomic-level data lineage tracing, utility attribution, and principled benchmarking are indispensable for reliable RLVR data construction and fair LLM evaluation. The ATLAS pipeline and SCA framework enable transparent attribution, efficient contamination removal, and robust dataset ranking, setting new standards for reproducible and verifiable RLVR research.