QuantumQA: Enhancing Scientific Reasoning via Physics-Consistent Dataset and Verification-Aware Reinforcement Learning
Abstract: LLMs show strong capabilities in general reasoning but typically lack reliability in scientific domains like quantum mechanics, which demand strict adherence to physical constraints. This limitation arises from the scarcity of verifiable training resources and the inadequacy of coarse feedback signals in standard alignment paradigms. To address the data challenge, we introduce QuantumQA, a large-scale dataset constructed via a task-adaptive strategy and a hybrid verification protocol that combines deterministic solvers with semantic auditing to guarantee scientific rigor. Building on this foundation, we propose the verification-aware reward model (VRM) tailored for Reinforcement Learning with Verifiable Rewards (RLVR), which employs an adaptive reward fusion (ARF) mechanism to dynamically integrate deterministic signals from a scientific execution suite (SES) with multidimensional semantic evaluations for precise supervision. Experimental results demonstrate that our method consistently outperforms baselines and general-purpose preference models. Notably, our optimized 8B model achieves performance competitive with proprietary models, validating that incorporating verifiable, rule-based feedback into the reinforcement learning loop offers a parameter-efficient alternative to pure scaling.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper tries to make AI much better at solving tough science problems—especially in quantum mechanics—without breaking the rules of physics. The authors do two main things:
- They build a new, carefully checked question–answer dataset called QuantumQA so the AI can learn from examples that are definitely correct.
- They design a new “teacher” for training called a verification‑aware reward model (VRM) that scores the AI’s answers using both strict tools (like calculators and physics checkers) and smart judgments (like a helpful tutor), then uses those scores to train the AI through reinforcement learning.
What questions the researchers asked
The team focused on a few simple questions:
- How can we give AI the right kind of practice so it learns to follow the rules of physics, not just sound smart?
- Can we build a dataset for quantum mechanics where answers are double‑checked so they don’t sneak in wrong steps?
- Can we design a training “judge” that not only prefers helpful writing but also verifies the math and physics behind the answer?
- Will this make smaller, open models as strong—or even stronger—than some big, commercial ones on science tasks?
How they did it (methods in everyday language)
Think of training an AI like coaching a student:
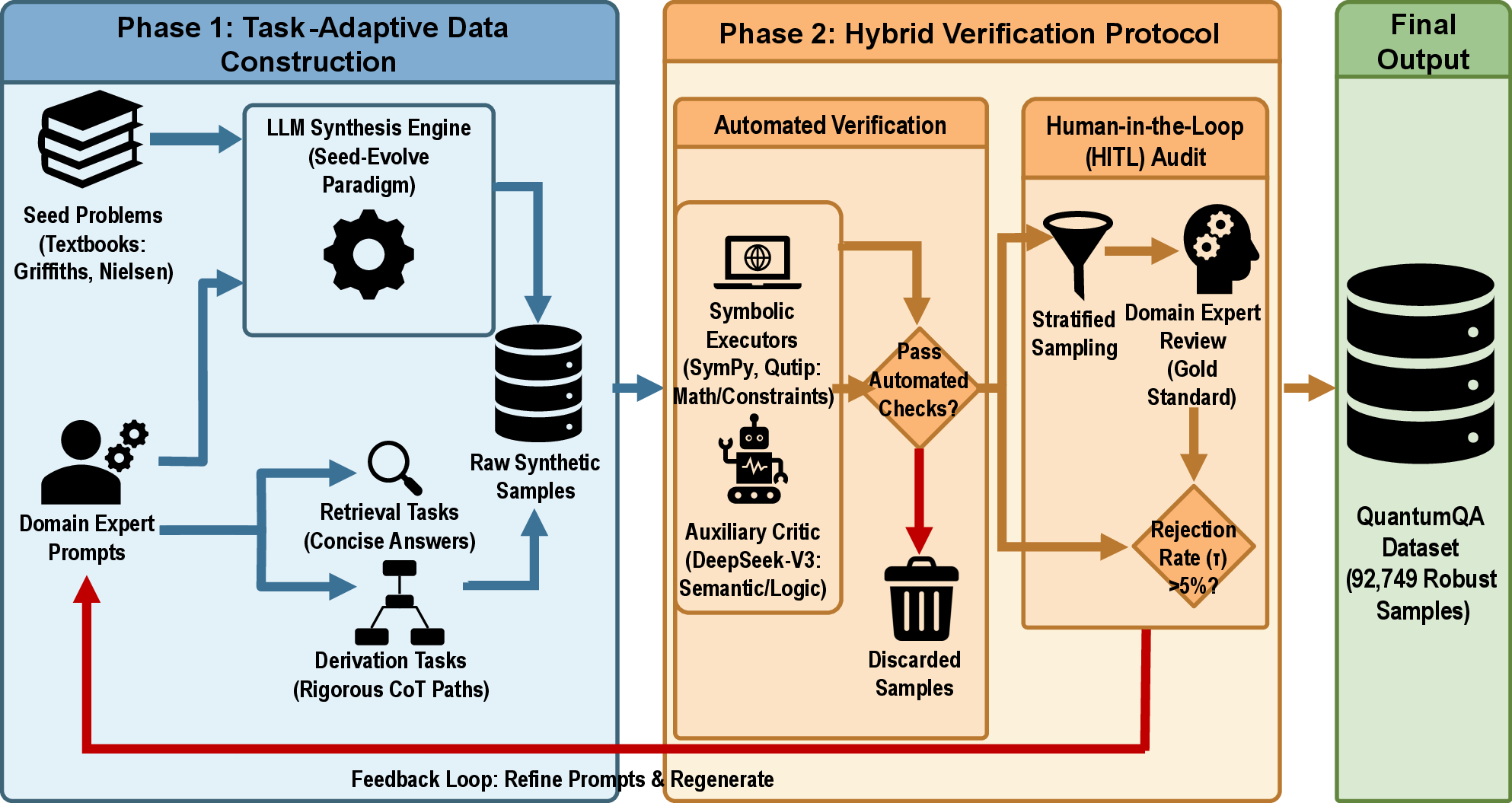
- Building the right workbook (QuantumQA)
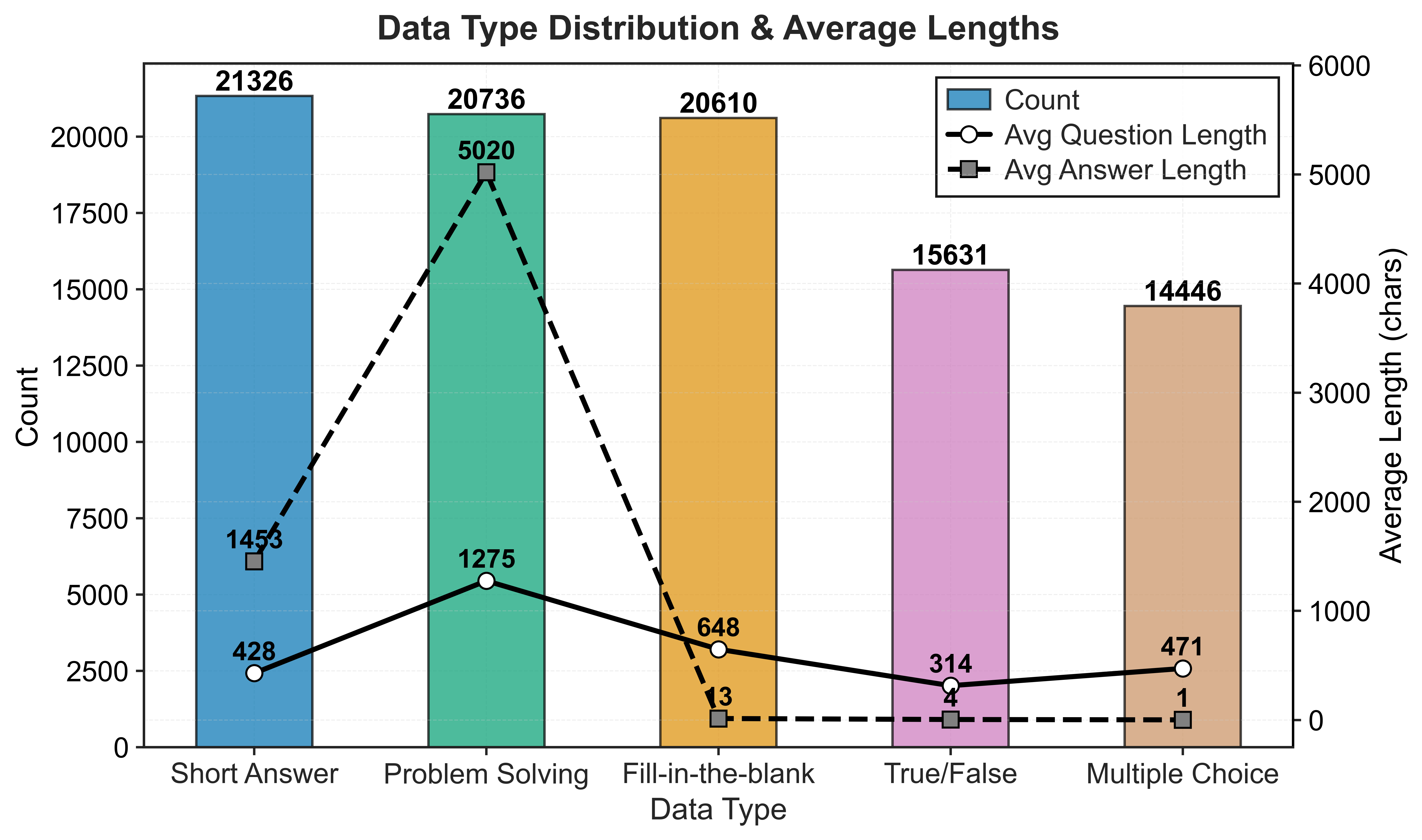
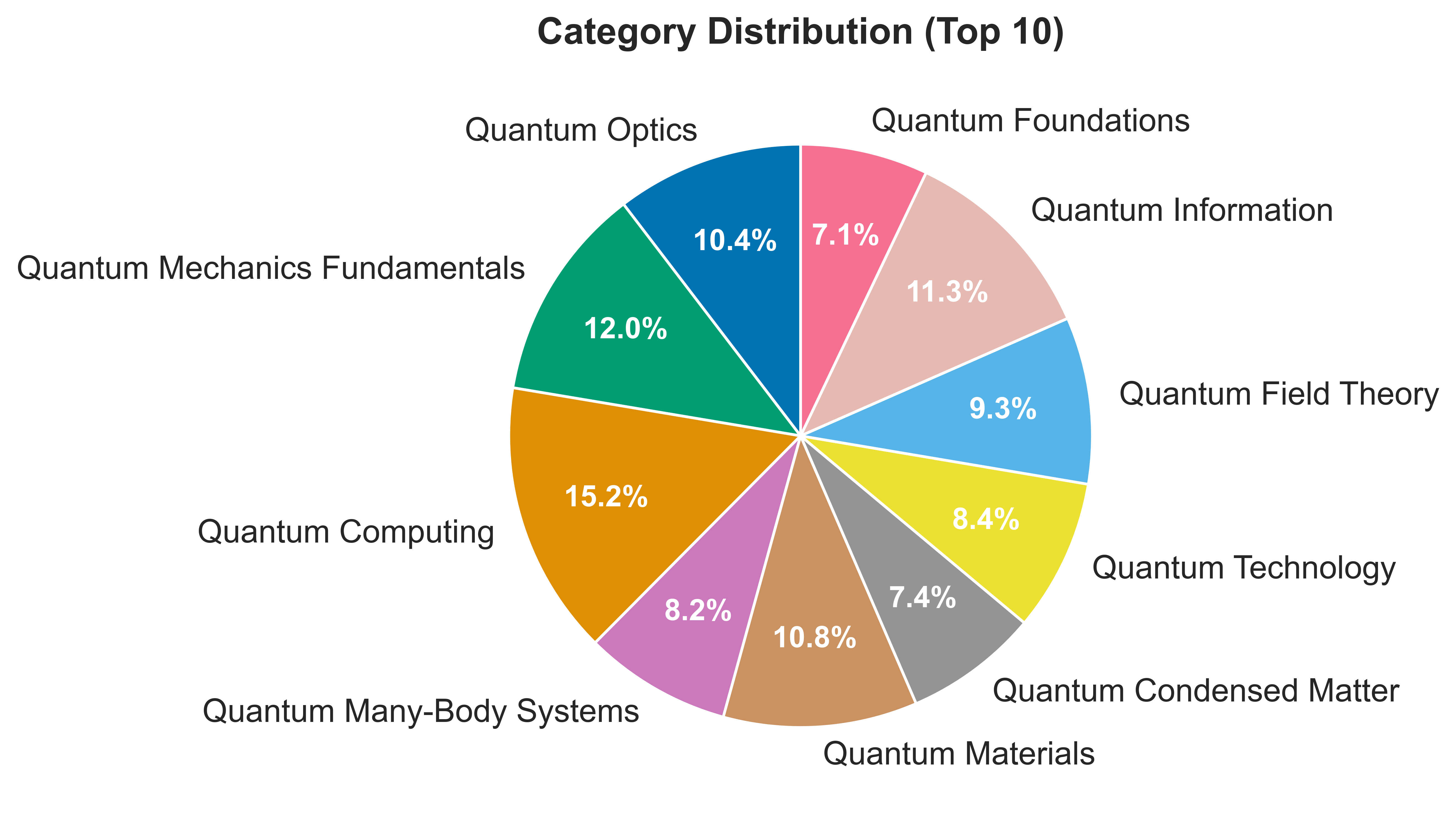
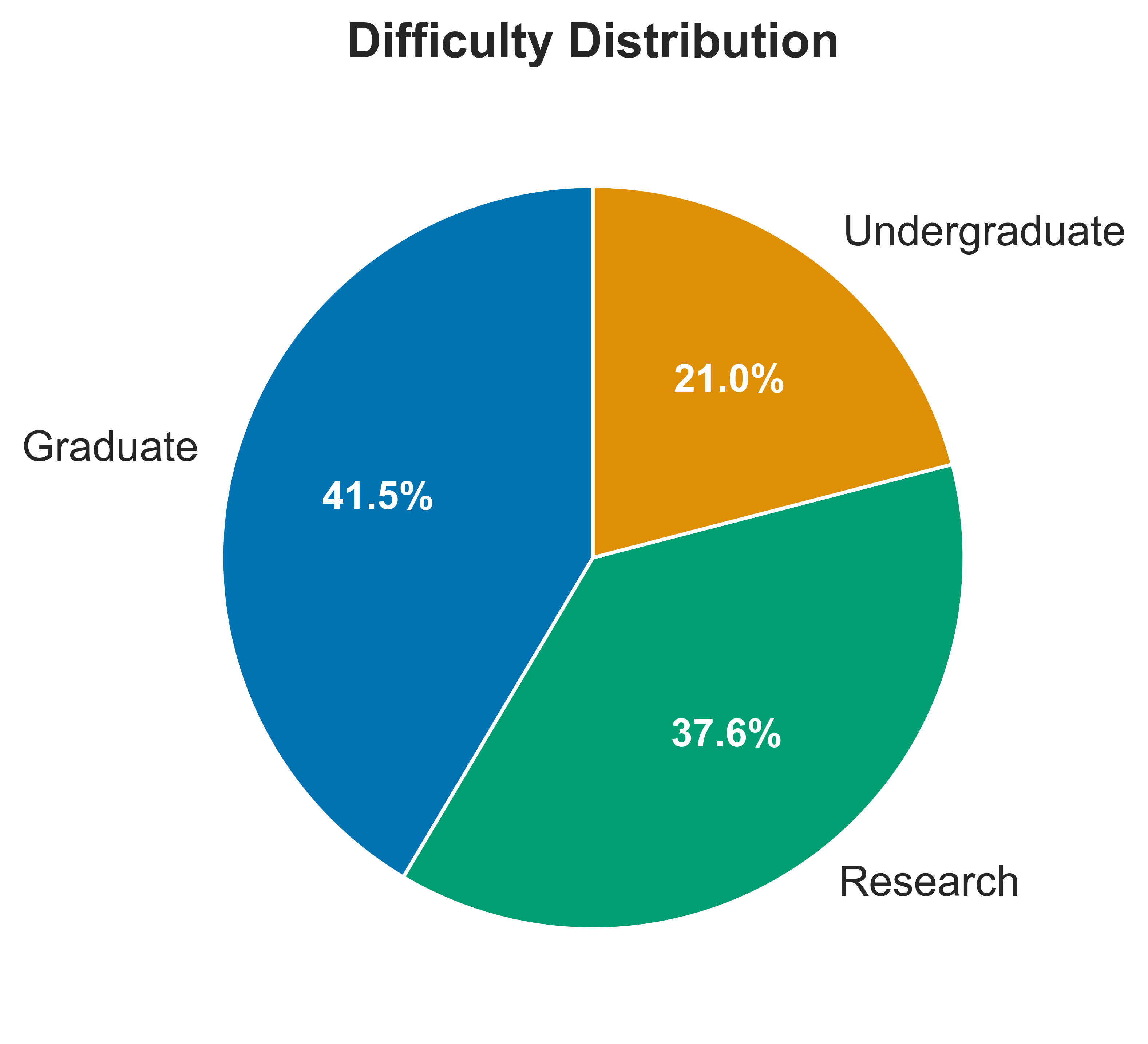
- The authors created a big set of 92,749 quantum questions with answers.
- For easy questions, they told the AI to keep answers short (to avoid rambling).
- For hard questions, they required “show your work” step‑by‑step solutions so later training can check the reasoning, not just the final answer.
- They then verified the answers in two ways:
- Using tools (the “Scientific Execution Suite,” or SES): calculators and symbolic solvers that can check equations and physics rules.
- Using smart reviewers (another AI + human experts): to judge if the explanation makes sense and follows instructions.
- If too many problems looked suspicious, humans reviewed and fixed them. This kept the dataset clean and trustworthy.
- Training with a fair and strict judge (VRM + RL)
- In reinforcement learning (RL), the AI tries answers; a “judge” gives points; the AI learns to earn more points.
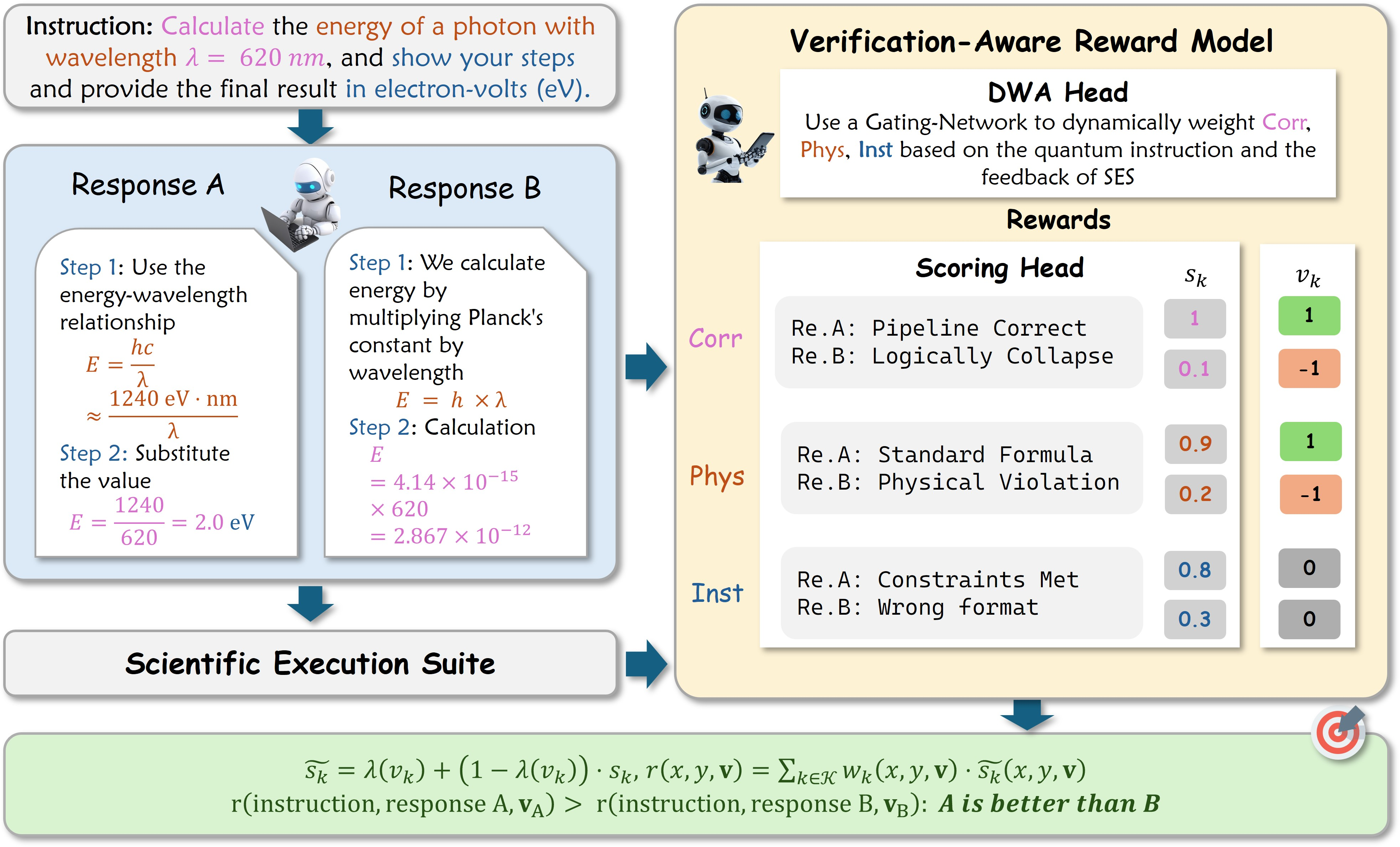
- Their judge is the Verification‑Aware Reward Model (VRM). It blends:
- Deterministic checks (like a calculator): “Is the math correct?” “Does this follow physics rules?”
- Semantic judgments (like a teacher): “Does this follow the instructions?” “Is the explanation clear?”
- The VRM looks at three things when scoring an answer:
- Mathematical correctness (Corr)
- Physical consistency (Phys)
- Instruction following (Inst)
- Adaptive Reward Fusion (ARF): The judge decides how much to trust each source. For example:
- If the calculator can check it, that result gets a lot of weight.
- If a tool can’t check a point, the judge leans more on the smart reviewer’s opinion.
- Before using the VRM to train the main model, they first taught the VRM itself using reliable “oracle” scorers, so it learned to be a strong, fair judge.
- Measuring success
- They tested models on QuantumQA and on other science benchmarks.
- Tasks included multiple‑choice, true/false, fill‑in‑the‑blank, short answers, and longer problem solving (with steps).
- For open‑ended answers, a separate judge scored correctness and reasoning quality on a 0–1 scale.
What they found (main results and why they matter)
Here are the main takeaways, explained simply:
- Better than standard training: Models trained with their verification‑aware RL (VRM + RL) were more accurate than models trained only on examples (supervised fine‑tuning).
- Strong gains on multi‑step problems: On tough, step‑by‑step physics problems, their method raised accuracy by about 6–7 percentage points compared to standard training with the same base model.
- Smaller models can punch above their weight: Their optimized 8‑billion‑parameter model performed similarly to or even better than some big commercial systems on certain measures. This means smart feedback can sometimes beat just making models bigger.
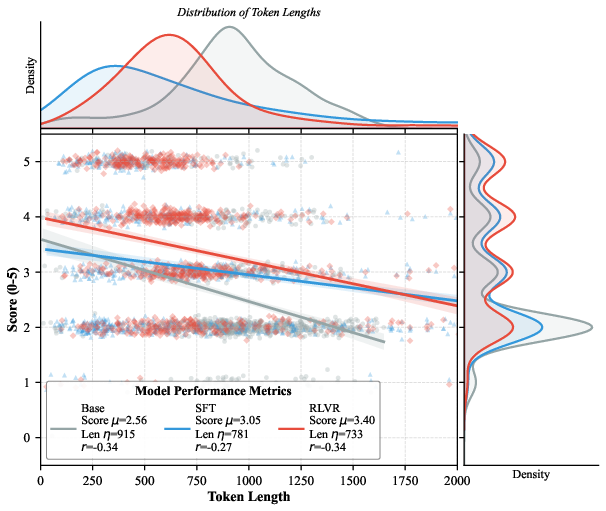
- Less rambling, more precision: Their method reduced “verbosity bias”—the tendency to write long answers without adding real correctness. The trained models got more problems right while using fewer words.
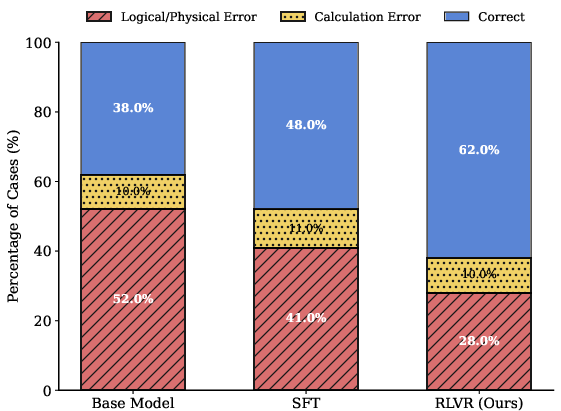
- Fewer physics rule breaks: Human checks showed fewer logical and physical mistakes after training with VRM.
- Works beyond one dataset: The improvements carried over to other science tests, not just the new dataset. That’s a sign of real learning, not just memorization.
- Each piece matters: When they removed parts of their system (like the math checker, the physics checks, or the adaptive weighting), performance dropped. This shows the pieces really do help.
Why it matters: In science, sounding confident isn’t enough; the steps must obey the rules. This work shows how to train AI to respect those rules.
What this could mean (impact and future use)
- More trustworthy science helpers: AI that follows math and physics rules can help students, teachers, and researchers with fewer errors.
- Efficient training: Instead of just building huge models, adding smart, verifiable feedback can make smaller models very capable—saving time and money.
- A blueprint for other fields: Although this paper focuses on quantum mechanics, the same idea—mixing strict tools with wise judging—could help in chemistry, classical physics, engineering, and beyond.
- Better step‑by‑step reasoning: Because the training checks the process, not just the final answer, it encourages clear, correct explanations.
Limits to keep in mind
- Mostly text and equations: The current dataset doesn’t include diagrams like quantum circuits.
- Focused on quantum mechanics: More work is needed to adapt the tool suite to other sciences.
- Not perfect judges: Tools and AI judges can still miss things, so human verification remains important for high‑stakes use.
Quick recap (the takeaway)
The authors built QuantumQA, a large, carefully verified set of quantum problems, and a smart judge (VRM) that mixes rule‑based checks with thoughtful scoring. Training with this judge made AI models more accurate, less wordy, and more faithful to physics—often rivaling bigger, commercial systems. It’s a practical path toward safer, more reliable scientific reasoning in AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, organized to make follow-up research actionable.
Dataset construction and coverage
- Limited domain scope: the dataset focuses on quantum mechanics only; no evidence of transfer to other scientific domains (e.g., classical mechanics, electromagnetism, chemistry, biology, astronomy) or to interdisciplinary tasks.
- Missing multimodal content: the dataset excludes diagrams, circuit schematics, state vectors on Bloch spheres, and lab-style plots; no protocols for verifying diagrammatic or visual reasoning.
- Lack of process-level traces: current data captures post-hoc derivations rather than exploratory, stepwise Long-CoT trajectories; no pipeline for collecting and validating intermediate steps with ground truth.
- Unclear task-typing automation: the “task-adaptive” policy depends on classifying tasks as retrieval-heavy vs. complex; no description or evaluation of the classifier, misclassification rate, or its impact on data quality.
- Verification coverage not quantified: the proportion of examples where SES verification is applicable vs. unavailable (v=0) is not reported; no breakdown by topic or task type.
- Solver limits and failure modes uncharacterized: no systematic analysis of SES failure cases (symbolic solver timeouts, numeric instability, operator ordering subtleties, gauge choices, unit handling).
- Numeric tolerance/approximation policies unspecified: no criteria for acceptable numeric error (e.g., tolerances) or handling near-equivalent symbolic expressions.
- Data de-duplication and contamination checks underreported: no audit of overlap with model pretraining corpora, textbook sources, or external benchmarks; risk of inflating apparent generalization.
- Data quality and bias auditing incomplete: while HITL filtering is used, there is no quantitative error taxonomy of residual issues (spurious assumptions, ambiguous notation, unit mistakes, frame dependence).
- Release details unclear: precise dataset license, SES code/tooling, and judge prompts/schemas are not confirmed as publicly available to ensure reproducibility.
Verification and SES design
- Coarse verification signals: trinary indicators (1, 0, −1) may be too coarse; no fine-grained metrics (e.g., partial equivalence, unit-consistency checks, step-local correctness).
- Limited physics checkers: “Physical consistency” is not operationalized beyond general checks; no explicit tooling for units, Hermiticity, commutation relations, positivity/trace constraints of density matrices, or measurement postulates across contexts.
- Open quantum systems and approximations: verification for Lindblad dynamics, noise models, perturbative expansions, and approximations (RWA, weak coupling) is not described.
- End-to-end tool reliability unmeasured: no estimates of SES false positives/negatives, inter-tool agreement, robustness to adversarial formatting, or version sensitivity (e.g., SymPy/Qutip versions).
- No per-step verifiers: verification is applied at the final-solution level; stepwise PRM-style checks remain unimplemented for scientific derivations.
Reward model (VRM) and training
- Calibration of fusion hyperparameters unspecified: the choice and sensitivity of λ(−1) (penalization for failed verification) is not reported; no robustness analysis to λ-schedule or weight decay.
- Ground-truth weights (w*) generation opaque: how oracle “dimension importance weights” are produced, validated, and de-biased is unclear; no inter-oracle agreement statistics.
- Lack of pairwise/ranking objectives: VRM uses L2 regression; no comparison with ranking-based or margin-based objectives commonly used for reward modeling.
- No analysis of reward misspecification: failure modes where semantic scorers overrule correct SES signals (or vice versa) are not cataloged; no adversarial probes for reward hacking beyond verbosity.
- Limited RL algorithm coverage: tested on PPO/GRPO only; no evaluation with DPO, RLAIF, VPO, or offline RL to decouple exploration vs. reward quality effects.
- Credit assignment granularity: rewards are response-level; no investigation of token- or step-level credit assignment to reduce variance and stabilize learning.
- Stability and compute costs underreported: training curves, variance across seeds, KL-control tuning, and compute/memory budgets for VRM and RLVR are not provided.
Evaluation methodology
- LLM-as-judge dependence: unified metric ACC_U relies on Qwen3-Max; although some human validation is mentioned, the exact correlation statistics, confidence intervals, and disagreement analyses are not reported.
- Family bias risk: using a Qwen-family judge while evaluating Qwen-based policies risks implicit bias; no cross-judge triangulation (e.g., Claude/GPT/LLama judges) or model-agnostic scoring audits.
- Human evaluation is small-scale: 400 instances for general comparison and 100 for error analysis may be underpowered; no power analysis or stratified sampling disclosure.
- Limited OOD stress tests: generalization is shown on quantum subsets of SuperGPQA and Physics; no tests on unrelated STEM domains, noisy/real-world lab data, or adversarial prompts.
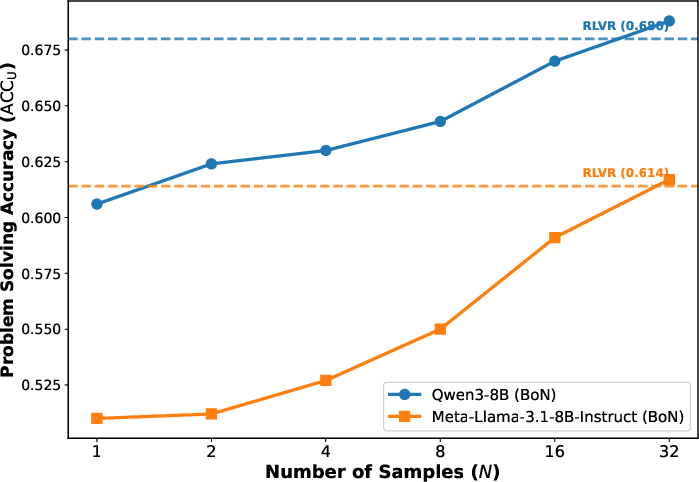
- Best-of-N compute fairness: BoN evaluation gains are shown but without equalized compute comparisons against baselines or alternative rerankers; no latency/throughput trade-off analysis.
- Safety/helpfulness trade-offs: no metrics on helpfulness, refusal behavior, or hallucination under safety prompts; potential interactions between correctness rewards and helpfulness/synergy remain untested.
Scope and applicability
- Inference-time tool use not explored: SES is used for training rewards, not as a tool the model can call during inference; the benefit/cost of tool-augmented inference remains unquantified.
- From theory to practice gap: tasks are primarily symbolic/theoretical; no linkage to experimental design, hardware constraints, or numerical simulation pipelines used in lab settings.
- No curriculum or scaling laws: absent analysis of performance as a function of dataset size, difficulty, verifier strictness, or RL steps; no curriculum schedule evaluation.
- Assumption tracking and explainability: no mechanisms to track assumptions, frames/units, or approximations in derivations; no interpretability study of VRM weights over dimensions/topics.
- Benchmark standardization: the new metric ACC_U and hybrid evaluation are not anchored to a community standard; comparability across papers remains uncertain.
- Transfer beyond quantum: while claimed to be domain-agnostic, no prototype SES/VRM deployments are demonstrated for other domains; tool substitution and coverage mapping are open engineering questions.
Concrete follow-up directions
- Build step-level scientific verifiers and PRMs for common quantum derivation patterns (operator identities, commutation, eigen-decompositions, unitary checks, trace/positivity).
- Extend SES to cover units, frames, noise models, and approximation regimes with quantitative tolerance settings and report verifier precision/recall on a labeled error corpus.
- Introduce multimodal quantum tasks with diagram parsing/generation and corresponding verifiers (circuit equivalence, gate counts, depth, measurement outcomes).
- Evaluate cross-judge robustness by triangulating ACC_U with multiple independent judges and human raters; release prompts, rubrics, and adjudication protocols.
- Quantify SES applicability rates, tool failures, and error taxonomies; report per-topic and per-task verifiability to guide data curation.
- Compare VRM regression with ranking-based reward learning; perform hyperparameter sensitivity (including λ(−1), ARF gating), ablations across seeds, and compute budgets.
- Test inference-time tool calling (planner-critic loops, Toolformer-style calls) versus pure policy learning; measure latency vs. accuracy trade-offs.
- Validate OOD generalization across non-quantum STEM domains and adversarial/noisy settings; include real lab data and numerical simulation tasks.
- Release full SES code, dataset versions, and evaluation scripts with version-locked dependencies to ensure reproducibility and cross-lab comparability.
Practical Applications
Overview
Based on the paper’s contributions—QuantumQA (a physics-consistent dataset), the Scientific Execution Suite (SES) for deterministic verification, and a Verification-aware Reward Model (VRM) with Adaptive Reward Fusion (ARF) for RL with verifiable rewards—below are practical applications organized by deployment horizon. Each item notes sectors, how it would be used, likely tools/workflows/products, and assumptions or dependencies that influence feasibility.
Immediate Applications
These can be piloted or deployed with today’s tools (SymPy/QuTiP, PPO/GRPO RL stacks, LLM-as-judge evaluators) once QuantumQA and the associated components are released.
- Physics-aware tutoring and auto-grading for quantum mechanics
- Sectors: education, academia
- What: AI tutor/TA that provides concise answers for simple tasks and step-by-step reasoning for complex problems, with automatic correctness and physical-consistency checks.
- Tools/products/workflows: LMS plug-ins that run SES (e.g., SymPy for algebra, QuTiP for QM operators), task-adaptive prompt templates, rubric-based LLM-as-judge scoring for open-ended answers.
- Assumptions/dependencies: Availability of QuantumQA and SES scripts; coverage is strongest for quantum mechanics; teacher oversight for edge cases; institutional data/governance approvals.
- Lab and research assistant for theory verification in quantum R&D
- Sectors: software (R&D tooling), quantum computing industry, academia
- What: Jupyter/IDE extension that flags algebraic mistakes, unphysical steps, and instruction-noncompliance in derivations, with inline SES checks and VRM-based scoring.
- Tools/products/workflows: SES-backed “linting” for derivations; VRM scorecards (Corr/Phys/Inst); integration with LaTeX/math notebooks and symbolic toolchains.
- Assumptions/dependencies: Researchers adopt SES-compatible notation; domain transfer beyond selected QM formalisms may need additional verifiers.
- Inference-time reranking for scientific Q&A (Best-of-N + VRM)
- Sectors: software, enterprise AI, education
- What: Boost reliability by sampling multiple candidate answers and using VRM (with SES signals) to select the best response.
- Tools/products/workflows: BoN sampling pipelines, VRM scorer microservice, SES status vector v_k logging for auditability.
- Assumptions/dependencies: Extra compute budget for sampling; stable SES execution; availability of the VRM weights or API.
- RLVR fine-tuning to upgrade in-house scientific assistants
- Sectors: software/AI platforms, quantum tech vendors, academia
- What: Use VRM-driven PPO/GRPO to align base LLMs for physics-constrained reasoning without scaling parameters.
- Tools/products/workflows: RL training loops (PPO/GRPO), reward logging (Corr/Phys/Inst), ARF for dynamic reward mixing; evaluation on QuantumQA test split.
- Assumptions/dependencies: Training compute; data licensing; engineering expertise to integrate SES and reward model in RL stacks.
- Scientific MLOps guardrails (physics-consistency gates)
- Sectors: enterprise AI, policy/compliance within R&D-heavy orgs
- What: Output filters that block or flag responses violating physical constraints before delivery to users.
- Tools/products/workflows: SES execution in the response pipeline; VRM thresholds for accept/reject; human escalation workflows; audit logs of v_k states.
- Assumptions/dependencies: Defined acceptance criteria per task; careful handling of SES “execution unavailable” states.
- Benchmarking and procurement evaluation for scientific LLMs
- Sectors: academia, industry benchmarking labs, policy
- What: Use QuantumQA test split and VRM/SES-based scoring to compare vendor models on physics-consistent reasoning.
- Tools/products/workflows: Leaderboards; standardized harness for Fill-in-the-Blank, T/F, MCQ, Problem Solving, and Short Answer; BoN vs. single-shot comparisons.
- Assumptions/dependencies: Neutral judging (avoid model self-judgment); dataset license clarity; reproducible SES runs.
- Physics-consistent prompt engineering patterns
- Sectors: software product teams, education technology
- What: Task-adaptive templates: concise answers for retrieval-heavy tasks, enforced CoT for complex derivations to reduce hallucination and verbosity bias.
- Tools/products/workflows: Prompt libraries; “format selectors” that switch modes by task type; integration with model routers.
- Assumptions/dependencies: Developers adopt and enforce templates; users accept concise vs. detailed responses based on task.
- Quantum SDK plugin for code and reasoning verification
- Sectors: software, quantum computing
- What: Qiskit/Cirq extensions that verify analytic steps (SES) alongside circuit code, flagging unphysical or mathematically inconsistent claims in comments/docs.
- Tools/products/workflows: CI checks for physics consistency; pre-commit hooks; VRM scoring in PR review.
- Assumptions/dependencies: Mapping between natural language justification and code artifacts; SES coverage for targeted tasks.
- Documentation/report linting for technical correctness
- Sectors: industry R&D, publishing, academia
- What: Document scanners that highlight physically inconsistent statements or derivations in papers, design notes, and tech docs.
- Tools/products/workflows: Batch SES checks; VRM score thresholds; redline suggestions; human-in-the-loop review panels.
- Assumptions/dependencies: Parsing fidelity from LaTeX/PDF to symbolic form; false positive management.
- Workforce upskilling content generation with verification
- Sectors: education, corporate L&D
- What: Generate verified question banks, solutions, and explanations for QM training programs with built-in SES checks to ensure correctness.
- Tools/products/workflows: Content generators that log v_k states; automated difficulty balancing; LLM-as-judge quality audits.
- Assumptions/dependencies: Coverage mainly in QM; instructors required to vet outliers.
Long-Term Applications
These require additional research, broader tool coverage, scaling to other domains, or validation in high-stakes settings.
- Domain-general verifiable reasoning (chemistry, materials, climate, control)
- Sectors: energy, pharma, materials, aerospace, robotics
- What: Extend VRM+SES to new domains with domain-specific solvers (e.g., RDKit/PSI4 for chemistry, ASE/LAMMPS for materials, OpenFOAM for CFD, control toolboxes for dynamics).
- Tools/products/workflows: SES adapters per domain; ARF tuned to new verifier reliabilities; domain-specific datasets akin to QuantumQA.
- Assumptions/dependencies: Availability/maturity of deterministic verifiers; domain expert involvement; new dataset construction with hybrid verification.
- Multimodal, physics-consistent reasoning (diagrams, plots, circuits)
- Sectors: education, R&D, software
- What: VLMs that read circuit diagrams, plots, and schematics and use verifiers to ensure consistency between text, equations, and visuals.
- Tools/products/workflows: Diagram parsers; symbolic extraction from figures; multimodal SES; VRM heads trained on mixed signals.
- Assumptions/dependencies: Reliable diagram-to-symbolic pipelines; curated multimodal datasets; higher compute/training costs.
- Autonomous experiment planning and analysis agents
- Sectors: lab automation, robotics, quantum/physics research
- What: Agents that design and analyze experiments while enforcing physical constraints and verifying analytic steps pre- and post-run.
- Tools/products/workflows: Integration with lab control software; SES/VRM gating for hypotheses and analyses; human supervisor dashboards.
- Assumptions/dependencies: Safety and reliability standards; robust coverage of domain-specific verifiers; institutional approval.
- Safety-critical engineering copilot with verifiable constraints
- Sectors: aerospace, energy, automotive
- What: Design assistants that verify equations, boundary conditions, and physical feasibility within CAD/CAE/CFD toolchains.
- Tools/products/workflows: Plug-ins for engineering suites; co-simulation with verifiers; traceable v_k logs for certification.
- Assumptions/dependencies: Rigorous validation; certification pathways; high-coverage verifiers for governing physics.
- Medical physics assistants (radiotherapy, MRI/CT physics)
- Sectors: healthcare
- What: Planning and QA support that checks dose calculations and imaging parameters against physics constraints before clinician approval.
- Tools/products/workflows: Domain-specific SES (e.g., dose calculation verifiers); VRM thresholds; clinical audit trails.
- Assumptions/dependencies: Regulatory clearance; extensive clinical validation; integration with hospital IT and privacy constraints.
- Regulatory and standards frameworks for “verifiable scientific AI”
- Sectors: policy, regtech, procurement
- What: Guidelines requiring verifiable, rule-based feedback (SES/VRM) for AI systems used in scientific analysis, procurement scorecards using QuantumQA-like benchmarks.
- Tools/products/workflows: Compliance checklists; certification tests using SES; standardized reporting of v_k distributions and failure modes.
- Assumptions/dependencies: Cross-institutional consensus; neutral third-party infrastructure; adaptability to multiple domains.
- Foundation-model training curricula with verifiable rewards
- Sectors: AI platforms, hyperscalers
- What: Incorporate VRM/ARF signals in pretraining/finetuning to reduce reliance on scale for scientific reliability.
- Tools/products/workflows: Large-scale RLVR pipelines; synthetic self-play with tool-use; distillation from BoN + VRM signals.
- Assumptions/dependencies: Training compute; stable tool-based evaluation at scale; careful mitigation of reward hacking.
- Cross-domain reasoning agents with dynamic verifier routing
- Sectors: software, enterprise AI
- What: ARF-gated agents that route subproblems to appropriate verifiers (math, physics, chemistry, regulatory rules) and fuse signals to guide generation.
- Tools/products/workflows: Tool-routing policies; multi-verifier SES; learned reliability weights per task type; failover mechanisms.
- Assumptions/dependencies: Tool coverage; orchestration latencies; robust fallback when tooling is unavailable.
- Quantum algorithm/circuit synthesis with physical constraints
- Sectors: quantum computing
- What: Automated algorithm/circuit design that enforces gate-level constraints, resource limits, and physical implementability via SES checks.
- Tools/products/workflows: Integration with transpilers/compilers; VRM-guided search; reward-aware pruning of invalid designs.
- Assumptions/dependencies: High-fidelity simulators; verifiers for hardware constraints; cost models for noise/latency.
- Large-scale, HITL-verified dataset ecosystems for STEM
- Sectors: academia, industry consortia
- What: Community-driven pipelines to create verifiable, process-supervised datasets across STEM with hybrid (tool + judge + human) validation.
- Tools/products/workflows: Open SES registries; shared judge models; expert-review marketplaces; quality thresholds with dynamic rejection rates.
- Assumptions/dependencies: Funding and governance; expert availability; licensing of tools and content.
Notes on Feasibility and Dependencies
- Tooling availability and maturity: SES depends on deterministic solvers (e.g., SymPy, QuTiP). Porting to other domains hinges on high-quality, callable verifiers (e.g., RDKit, ASE, OpenFOAM).
- Data readiness: Immediate deployments assume QuantumQA release and clear licensing. Long-term extensions require new, domain-specific QuantumQA-like datasets and HITL pipelines.
- Evaluation reliability: LLM-as-judge signals should be validated against human experts to reduce self-preference bias; consider cross-judge ensembles for robustness.
- Compute and latency: RLVR training and BoN reranking introduce compute overhead; operational systems must balance reliability gains with cost and latency constraints.
- Safety and governance: High-stakes uses (healthcare, aerospace) require rigorous validation, auditability (logging v_k), and compliance frameworks before deployment.
- User experience: Task-adaptive formatting (concise vs. CoT) must be communicated to users; guardrails should escalate gracefully when verifiers are unavailable or inconclusive.
Glossary
- Adaptive Reward Fusion (ARF): A mechanism that blends deterministic verification signals with semantic scores, weighting them based on verifiability to produce a stable reward. "adaptive reward fusion (ARF) mechanism"
- Best-of- (BoN) sampling: An inference-time strategy where multiple responses are generated and the best is chosen using a verifier. "Best-of- (BoN) sampling"
- Causal head: The output head used for autoregressive language modeling in transformer-based models. "the standard causal head is replaced by two specialized output modules."
- Chain-of-Thought (CoT) derivations: Step-by-step reasoning traces included in model outputs to enhance and verify reasoning. "Chain-of-Thought (CoT) derivations"
- Deterministic solvers: Formal tools (e.g., symbolic math engines) that provide unambiguous, checkable results for verification. "deterministic solvers"
- Dynamic rejection threshold (): A criterion in human auditing that triggers iterative refinement when error rates exceed a set threshold. "dynamic rejection threshold ()"
- Dynamic Weight Allocation (DWA) head: A gating network that assigns reliability weights to different evaluation dimensions based on execution signals. "Dynamic Weight Allocation (DWA) head"
- GeLU activations: Gaussian Error Linear Unit activation functions used in neural network MLPs. "GeLU activations"
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm variant that optimizes policies using group-relative baselines. "Group Relative Policy Optimization (GRPO)"
- Human-in-the-Loop (HITL) review process: A quality-control loop where humans audit and refine automatically generated or verified data. "Human-in-the-Loop (HITL) review process"
- Institutional Review Board (IRB): An ethics committee that reviews and approves research involving human participants. "Institutional Review Board (IRB)"
- Length-bias: A tendency in some RL-aligned models to prefer overly long outputs, which can distort evaluation. "length-bias"
- LLM-as-a-Judge framework: Using a LLM to evaluate responses along defined dimensions (e.g., correctness, consistency). "LLM-as-a-Judge framework"
- Long Chain-of-Thought (Long-CoT) paradigms: Methods that elicit and evaluate extended reasoning chains in model outputs. "Long Chain-of-Thought (Long-CoT) paradigms"
- Mathematical Correctness (Corr): A scoring dimension that evaluates the mathematical validity of a solution. "Mathematical Correctness (Corr)"
- Oracle-as-a-Judge: An evaluation setup where high-quality judge models provide supervisory signals for training or validation. "``Oracle-as-a-Judge'' pipeline"
- Oracle-Guided Pretraining: A pretraining phase where a reward model is trained to mimic oracle-provided scores and weights. "Oracle-Guided Pretraining"
- Out-of-distribution (OOD) generalization: The ability of a model to perform well on data that differs from the training distribution. "out-of-distribution (OOD) generalization"
- Pearson correlation coefficient: A statistic measuring linear correlation between two variables. "Pearson correlation coefficient"
- Personally identifiable information (PII): Data that can identify an individual and must be removed to protect privacy. "personally identifiable information (PII)"
- Physical Consistency (Phys): A scoring dimension assessing adherence to physical laws and constraints. "Physical Consistency (Phys)"
- Process Reward Models (PRMs): Reward models that evaluate and score intermediate reasoning steps, not just final answers. "Process Reward Models (PRMs)"
- Proximal Policy Optimization (PPO): A widely used policy gradient algorithm for reinforcement learning with stability constraints. "Proximal Policy Optimization (PPO)"
- Reliability-Weighted Aggregation: The aggregation step that combines fused dimension scores using learned reliability weights to produce a scalar reward. "Reliability-Weighted Aggregation."
- Reinforcement Learning from Human Feedback (RLHF): RL alignment using human preference or ranking signals to guide policy learning. "Reinforcement Learning from Human Feedback (RLHF)"
- Reinforcement Learning with Verifiable Rewards (RLVR): RL that leverages tool-verified signals and semantic judgments to shape rewards. "Reinforcement Learning with Verifiable Rewards (RLVR)"
- Reward hacking: Exploiting flaws in the reward function to achieve high scores without solving the intended task. "To rule out reward hacking, specifically verbosity bias"
- Reward over-optimization: Overfitting to a reward model that leads to degraded true performance or violations of constraints. "reward over-optimization"
- Reward sparsity: A challenge in RL where informative reward signals are infrequent, making learning unstable or slow. "reward sparsity"
- Scientific execution suite (SES): A deterministic toolkit of verification scripts and solvers used to check mathematical and physical constraints. "scientific execution suite (SES)"
- Seed-Evolve paradigm: A data-synthesis approach that grows a dataset from initial seed problems through iterative expansion. "Seed-Evolve paradigm"
- Semantic auditing: Using model-based or human-based semantic checks to assess the quality and correctness beyond formal execution. "semantic auditing"
- Skywork RM: A general-purpose reward model used as a baseline for scalar-reward RL. "Skywork RM"
- Skywork-Reward: The specific reward model from Skywork used to guide PPO in baseline comparisons. "Skywork-Reward"
- Step-wise verification: Verifying each intermediate step in a reasoning chain to provide dense supervision. "step-wise verification"
- Symbolic solvers: Tools (e.g., SymPy) that manipulate mathematical expressions symbolically for exact verification. "symbolic solvers"
- Trinary verification indicators: Three-valued signals indicating pass, fail, or unavailable states for each verification dimension. "trinary verification indicators"
- Verbosity bias: A bias where longer outputs are favored or mistaken for better quality. "verbosity bias"
- Verification-aware reward model (VRM): The proposed reward model that fuses solver-based verification with semantic evaluation to guide RL. "verification-aware reward model (VRM)"
Collections
Sign up for free to add this paper to one or more collections.