- The paper introduces GDCR, a graph-based reward method that assigns per-step credit using entity proximity, enhancing fine-grained control in agentic search.
- It integrates Step Advantage Policy Optimization (SAPO) to merge process rewards with outcome-based signals, eliminating the need for costly tree-sampling techniques.
- Empirical results on multiple search benchmarks show SAPO outperforms traditional methods with up to 20% lower training cost and more efficient progress tracking.
Step-Level Credit Assignment via Graph Modeling for Agentic Search
Introduction
This work addresses the challenge of fine-grained credit assignment in agentic search tasks executed by LLMs. Traditional RL paradigms in agentic search typically rely on trajectory-level outcomes: the reward signal is determined solely by the correctness of the final answer and uniformly allocated to all steps in a sequence. However, complex information-seeking and multi-turn search require nuanced credit assignment, as the contributions of individual retrieval and citation actions differ drastically. Existing step-level credit allocation methods often employ costly tree-sampling strategies, which are computationally prohibitive for long-horizon search. The paper introduces a graph-modeling approach to process-level RL: by considering search as traversal within a latent task graph subsumed by world knowledge, it becomes possible to score actions according to their progress toward the answer node in this underlying graph.
Graph-Based Step-Level Reward: Graph-Distance Contribution Reward (GDCR)
The core methodological innovation is the Graph-Distance Contribution Reward (GDCR), which quantifies the agent's per-step progress in information-seeking tasks by leveraging an explicit, training-time Entity-Relation (ER) graph constructed for each question-answer instance. GDCR assigns credit at the step level through two components: (1) newly-retrieved entities discovered by the agent at each action, and (2) newly-cited entities that appear explicitly in the agent’s generated thoughts for the first time. Both are scored on their shortest-path graph distance to the answer node in the task ER graph, with a decaying contribution function emphasizing entities close to the answer.
The process operates as follows. At each agent interaction step:
- The set of previously retrieved and cited entities is maintained.
- For the current step, newly-cited entities are identified from the generated thought, and newly-retrieved entities from the search environment.
- Each entity is given a contribution score of k−d where d is its shortest path to the answer node, and k is a decay constant (empirically set to 2).
This approach grounds per-step reward in meaningful knowledge-graph progress rather than arbitrary tree expansions.
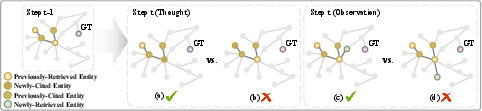
Figure 1: GDCR computation at step t highlights the scoring for newly-cited and newly-retrieved entities based on their proximity to the target answer node.
Policy Optimization: Step Advantage Policy Optimization (SAPO)
SAPO operationalizes GDCR by combining step-level process rewards with classical trajectory-level outcome objectives in a unified RL training pipeline. For each generated trajectory, a normalized, clipped GDCR signal is computed for each step and added (weighted by hyperparameter λ) to the group-normalized outcome advantage that anchors optimization to final-answer correctness. This mixed-advantage approach retains objective-driven training while enabling the RL signal to reinforce crucial intermediate retrieval/citation steps and suppress irrelevant behaviors. Policy optimization is performed with a GRPO-style clipped surrogate objective.
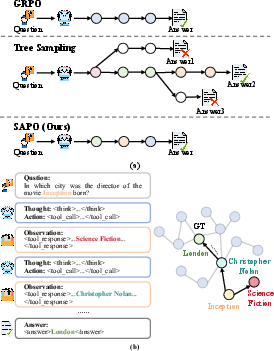
Figure 2: (a) SAPO distinguishes step-level contributions, unlike GRPO, and avoids expensive tree-policy optimizations. (b) Intuitive prior: progress on the latent task graph via meaningful entity retrieval should be credited more.
Experimental Evaluation
Extensive empirical evaluation is conducted on four challenging search-agent benchmarks (BrowseComp, BrowseComp-ZH, xbench-DS, GAIA), comparing SAPO to SFT, trajectory-level GRPO, and tree-sampling ARPO. The following findings are notable:
- SAPO consistently improves over SFT and GRPO across all model sizes and datasets. At both the 8B and 30B scale, SAPO yields the best open-source results among models tested under identical environmental constraints.
- Compared to ARPO, which incorporates stepwise credit via sampling, SAPO achieves higher or comparable accuracy under the same rollout budget with significantly reduced (≈20% lower) training cost due to its non-sampling structure.
- Ablation studies confirm both GDCR components (newly-retrieved and newly-cited rewards) are essential for optimal performance; removing either impairs effectiveness.
- The policy remains robust under moderate noise in the ER graph (random node deletion/injection or answer perturbation).
- Analysis reveals that trajectories generated by SAPO-trained agents exhibit steeper and more consistent progress toward the answer node, as measured by shortest-path distance, and higher rates of explicit citation of critical retrieved entities.
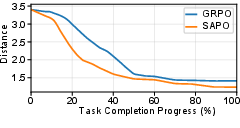
Figure 3: SAPO models drive a faster reduction in average graph distance to the answer, illustrating more efficient knowledge navigation than GRPO-trained models.
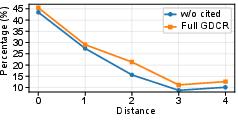
Figure 4: Adding newly-cited rewards increases the explicit use of key evidence entities, particularly those nearer the answer.
Theoretical and Practical Implications
By formulating credit assignment over graph structure, this approach shifts RL for agentic search from expensive sampling-based ablations toward resource-efficient, semantically grounded optimization. The explicit use of an ER graph makes the process reward both interpretable and scalable to complex, multi-step query reasoning.
In practice, GDCR and SAPO enable significant gains in the efficiency and reliability of training knowledge-intensive agentic systems on long-horizon benchmarks, providing performance improvements with minimal overhead. Theoretically, this work demonstrates the utility of structured knowledge priors—specifically, graph-theoretic progress functions—in guiding LLM-based search agents with sparse, delayed outcomes.
This paradigm suggests future directions:
- Extending graph-based reward assignment to open-ended or multi-answer settings via soft endpoint scoring.
- Integrating graph-construction into the agent’s loop for partially observed or dynamic environments.
- Adapting GDCR for tasks with ambiguous or multiple plausible answers by leveraging uncertainty-aware or distributional credit assignment.
Conclusion
This paper advances RL for agentic search by introducing GDCR, a structural, graph-based step-level reward, and SAPO, a hybrid advantage framework that seamlessly integrates process and outcome signals. The proposed method achieves strong empirical results on deep agentic benchmarks, efficiently assigns per-step credit without tree sampling, and systematically improves both the retrieval and integration of relevant information through entity-centric graph progress. The work sets a foundation for future research in agentic credit assignment leveraging explicit knowledge structure for highly scalable and effective search-agent optimization.

