- The paper introduces RTMC, a critic-free method that leverages rollout trees for fine-grained, per-step credit assignment in agentic RL tasks.
- RTMC computes unbiased, per-token Q-values using Monte Carlo estimates and Bayesian prior smoothing, achieving a 5.4 pp pass@1 improvement over baselines.
- This approach bypasses the need for trained critics, providing efficient and robust credit assignment that supports complex, tool-interactive reinforcement learning.
RTMC: Step-Level Credit Assignment via Rollout Trees
Introduction and Motivation
This paper addresses the fundamental challenge of fine-grained credit assignment in agentic reinforcement learning (RL) for LLM agents operating in multi-step, tool-interacting environments. Traditional critic-free approaches such as GRPO assign trajectory-level advantages, which obscure the component-wise quality of agent actions. Critic-based methods require training learned value networks, introducing significant overhead and instability—especially in sparse reward or long-horizon domains typical of so-called agentic RL tasks.
The authors propose Rollout-Tree Monte Carlo (RTMC) advantage estimation, a critic-free method that overcomes these limitations by organizing group rollouts of the same underlying problem into a tree structure. This structure exploits the overlap of intermediate states among rollouts to construct per-step, state-action-based Q-values and advantages, without auxiliary models.
Methodology: Rollout-Tree Monte Carlo Advantage Estimation
RTMC operates by abstracting each agent-environment interaction step into compact state-action signatures. These signatures enable tractable matching and aggregation across multiple rollout trajectories. Given N group rollouts per problem, the method constructs a tree where nodes correspond to unique states (up to signature abstraction) and edges to actions. Each state-action pair receives an unbiased first-visit Monte Carlo estimate of its Q-value, per classic RL theory, with the advantage given by A(s,a)=Q(s,a)−V(s). For states visited by few rollouts, RTMC employs Bayesian prior smoothing, blending local per-node estimates with a group-level prior to ensure robust advantage signals.
Per-token policy optimization is achieved by broadcasting the computed per-step advantages over the corresponding action token segments in the trajectory, directly integrating with standard PPO-style objectives.
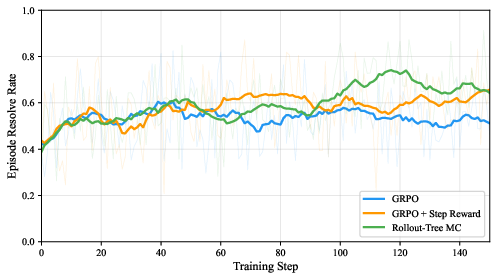
Figure 1: Training episode resolve rate on the R2E dataset, with clear separation between methods as credit assignment granularity increases.
State-Action Signature System
A major technical contribution is the design of domain-specific abstraction schemes that distill raw agentic experience into signatures capturing salient problem-solving context while abstracting incidental surface details. For software engineering environments, this involves categorizing tools by functional impact, hashing modified file contents, bucketing view actions by code location, and encoding states as per-file operation sets—enabling reliable cross-trajectory state matching.
Empirical Results
Extensive experiments are performed on the SWE-bench Verified benchmark, using Qwen3-Coder-30B-A3B-Instruct as the base model in an R2E-Gym simulated environment. Four methods are compared: pretrained baseline, trajectory-level GRPO, GRPO augmented with per-step intrinsic rewards, and the proposed RTMC.
Each refinement in credit assignment—from episode-level, to step-level rewards, to state-level tree-based advantages—yields consistent, monotonic improvements in the pass@1 metric on held-out evaluation:
- Baseline (no RL): 46.8%
- GRPO: 49.0% (+2.2 pp over baseline)
- GRPO + Step Reward: 50.4% (+3.6 pp)
- Rollout-Tree MC: 52.2% (+5.4 pp)
On-path analysis confirms that RTMC assigns non-uniform, context-sensitive advantages to tokens within a trajectory, highlighting both suboptimal actions within successful rollouts and high-quality actions within failures—capabilities that are strictly absent with previous methods.

Figure 2: Visualization of the rollout tree for datalad_final_05ea, showing branching histories and downstream outcomes.
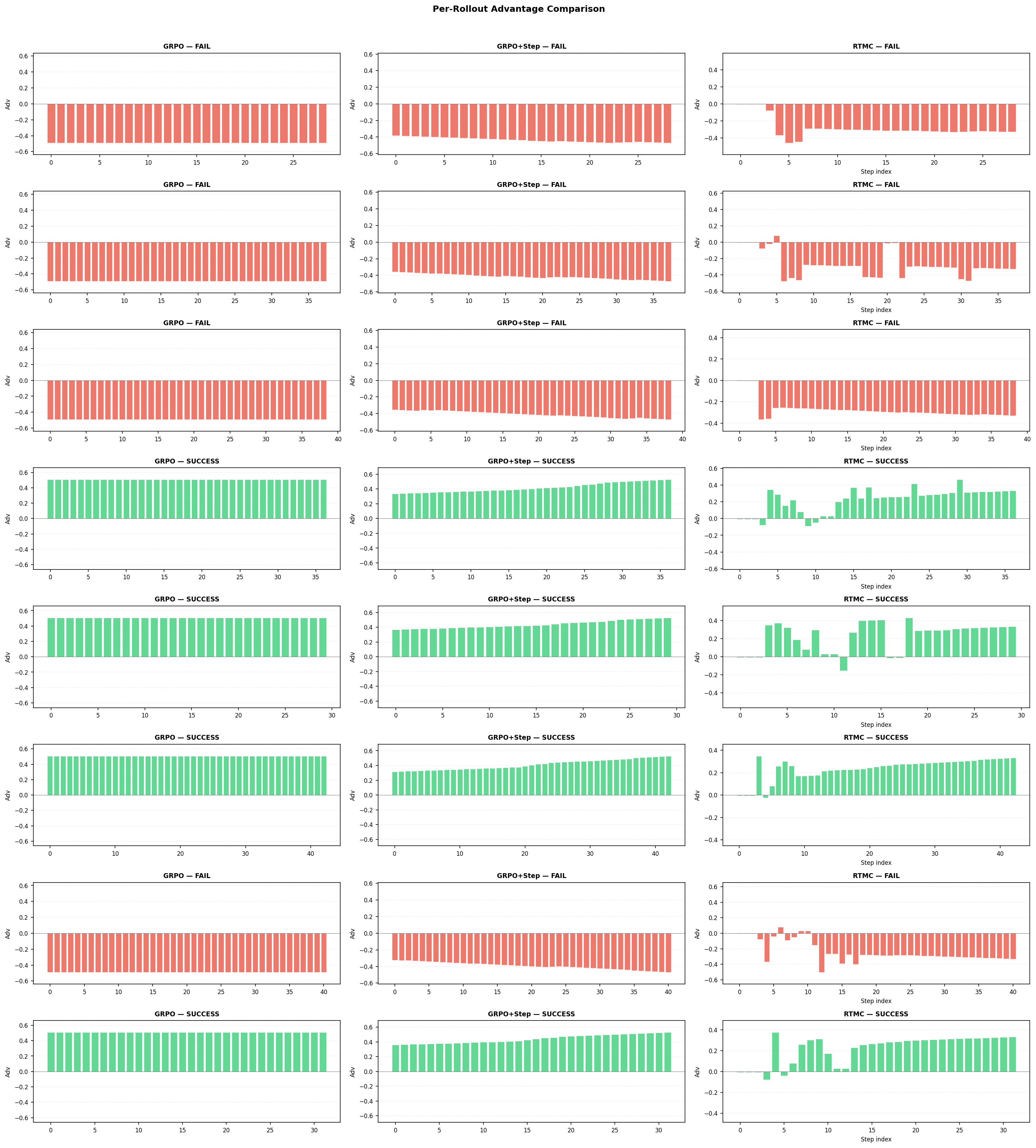
Figure 3: Step-level advantage curves for eight rollouts, indicating RTMC’s fine-grained assignment compared to coarse baselines.
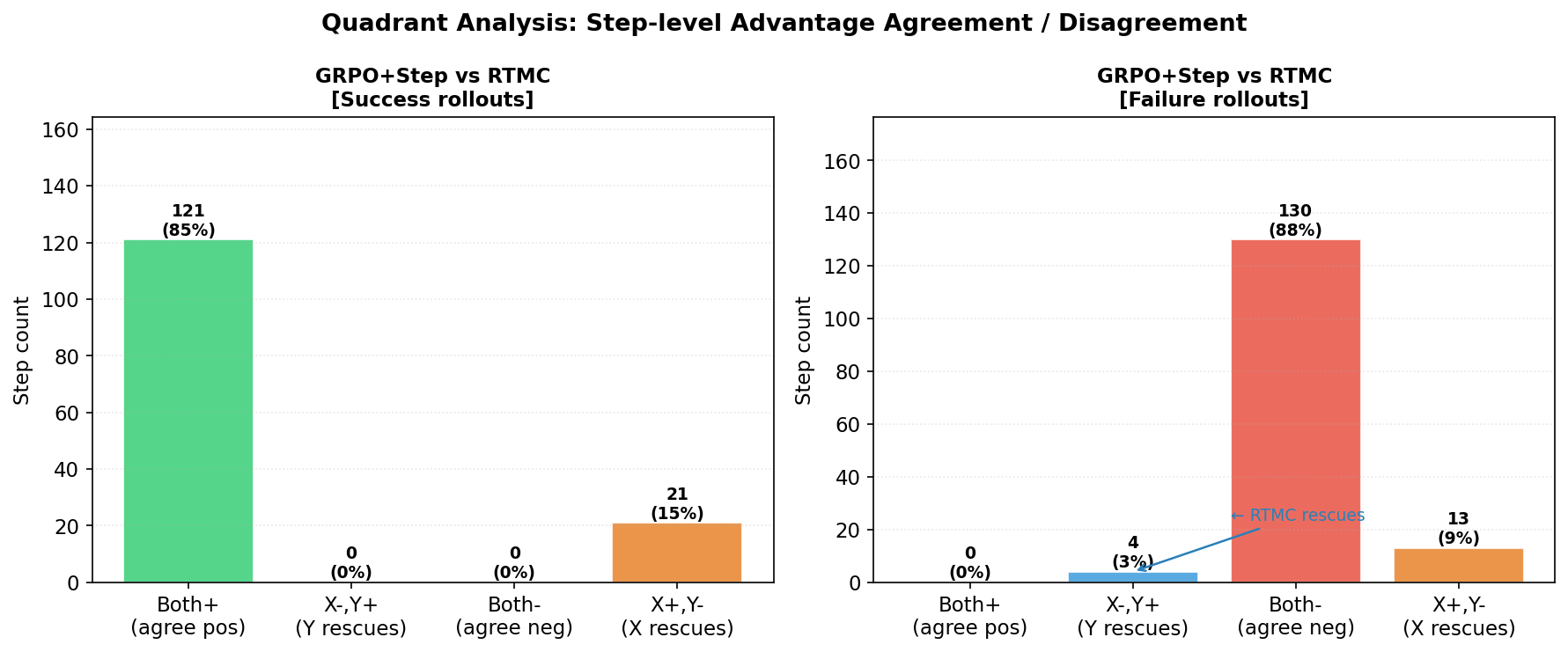
Figure 4: Quadrant analysis reveals the percentage of actions where RTMC’s advantages diverge from or correct GRPO+Step rewards.
An ablation demonstrates that the performance gain of RTMC relies heavily on prior-based value smoothing. Setting the prior weight nprior=0 drops pass@1 from 52.2% to 49.7%, confirming the value of this regularization when most tree nodes are sparsely visited.
Theoretical and Practical Implications
The results substantiate several important claims:
- RTMC outperforms both trajectory-level and step-reward baselines by leveraging group-level outcome statistics at each decision point, without training a critic network.
- RTMC’s lightweight computation (linear time over the batch, with no gradient or additional forward passes) makes it readily applicable in practical agentic RL pipelines based on PPO or group RL schemes.
- The approach is robust to reward sparsity, given that it requires only batch returns and can function without model-based value predictions.
- Signature quality is a bottleneck: Most tree nodes remain single-visit for moderate rollout budgets, placing an upper bound on RTMC’s realized gains until better state abstraction/logical grouping algorithms are deployed. The methodology is flexible with regard to learned, domain-agnostic embedding–based signatures, suggesting future extensibility beyond current hand-crafted schemes.
Limitations and Future Directions
While RTMC yields consistent and strictly additive improvements, the magnitude of those gains (3.2 pp over the best baseline) is limited by the sparsity of high-quality cross-rollout matches and the inherent limitations of rule-based abstraction. There is a trade-off between abstraction granularity and the coverage needed for meaningful cross-trajectory comparison—a problem exacerbated by the combinatorial action-state space of code editing and tool use.
Possible future directions include:
- Integration of learned or hybrid signature systems that more effectively cluster semantically equivalent states, amplifying the cross-rollout comparison signal.
- Exploration of methods to increase state visitation overlap without artificially constraining agent diversity.
- Application to broader agentic RL domains (scientific discovery, synthesis, real-world robotic control) where tool effect abstraction is even less amenable to rules.
- Analysis of training-induced performance regression along with methods to mitigate negative transfer on previously solved instances.
Conclusion
RTMC constitutes a robust, critic-free step-level credit assignment mechanism for multi-step, agentic RL in LLM-based agents. By leveraging the natural tree-structured overlap among group rollouts, and utilizing structured state-action signatures paired with an efficient MC estimator and prior smoothing, the method achieves measurable improvements in downstream agent performance, all without introducing learned critics or costly rollouts. Its primary limitation—dependence on the quality of signature abstraction—also points to fertile ground for integration of recent advances in learned state representation. Overall, RTMC advances the state of the art in sample-efficient, high-granularity advantage estimation for agentic LLM RL, with compelling implications for complex tool-using AI systems.