- The paper introduces the Pilot-Commit framework that decouples prompt evaluation and exploitation by allocating rollouts based on empirical reward variance.
- It achieves up to 4× improvement in rollout efficiency, reducing computation while enhancing the quality of policy updates.
- Empirical results across multiple LLM architectures validate its robustness and scalability in optimizing group-based RL post-training.
Rollout Allocation for Group-Based RL Post-Training: Pilot-Commit
Group-based reinforcement learning (RL) algorithms are the predominant approach for post-training LLMs to achieve complex alignment objectives. However, the primary bottleneck in this paradigm is the high computational cost of online rollout generation, particularly as inference is tightly coupled with the evolving policy. Traditional group-based methods such as GRPO and DAPO allocate rollout resources uniformly across prompts, irrespective of their reward-driven informativeness. The paper presents a rigorous analysis demonstrating that the strength of the policy gradient in GRPO is maximized for prompts exhibiting high within-group reward variance, which is generally associated with partially-solved or ambiguous prompts. The necessity to estimate prompt reward variance online, given the dynamic policy evolution, renders exhaustive evaluation prohibitively expensive.
Pilot-Commit Framework
The Pilot-Commit (PC) framework addresses this issue by decoupling prompt evaluation from exploitation through a two-stage rollout allocation scheme. In the pilot stage, a fraction of the rollout budget is spent to estimate empirical reward variance per prompt. The commit stage reallocates the remaining budget exclusively to the prompts identified as highly informative in the pilot stage, i.e., those exhibiting substantial reward variance. Prompts deemed near-solved or too-hard are either evicted or deferred, thereby optimizing computational expenditure:
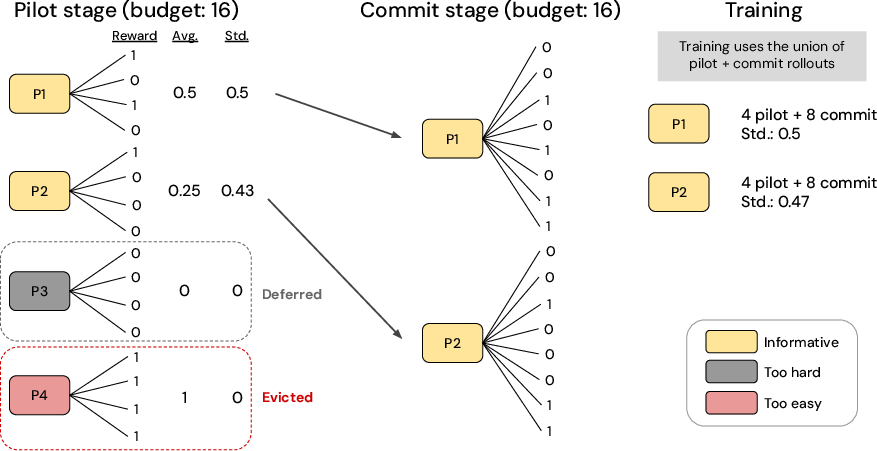
Figure 1: Pilot-Commit schematic illustrating pilot-based prompt selection and commit-stage budget concentration to maximize learning signal.
The framework is instantiated for verifiable binary rewards (math reasoning benchmarks), exploiting the closed-form mapping between success rate and reward variance, but is extensible to more general reward types.
Theoretical Analysis
A two-cluster approximation for group-wise GRPO gradients reveals an upper bound for the positive advantage mass, which is maximized at prompt success rate p=0.5, corresponding to maximal reward uncertainty. This supports the central claim that prompts in the high reward-variance regime contribute disproportionately to effective policy updates. As prompts transition from unsolved to solved during training, asymmetric filtering thresholds are applied: near-solved prompts are evicted, while borderline-hard prompts are deferred to subsequent epochs.
Empirical Results
Pilot-Commit is evaluated across multiple LLM architectures (Qwen2.5-Math-1.5B, Qwen3-4B, Qwen3-8B, Qwen3-14B) and math datasets (DeepMath-103K, Polaris-53K), using group sizes matched to baseline methods. PC consistently exhibits superior rollout efficiency: it reaches target baseline accuracy using up to 1.9× fewer rollouts than GRPO and 4.0× fewer than DAPO. The efficiency gains are most pronounced under ample group sizes, as redundant commit rollouts are avoided for uninformative prompts.
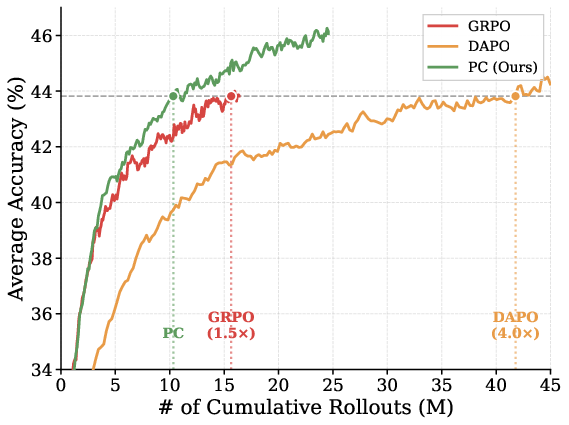
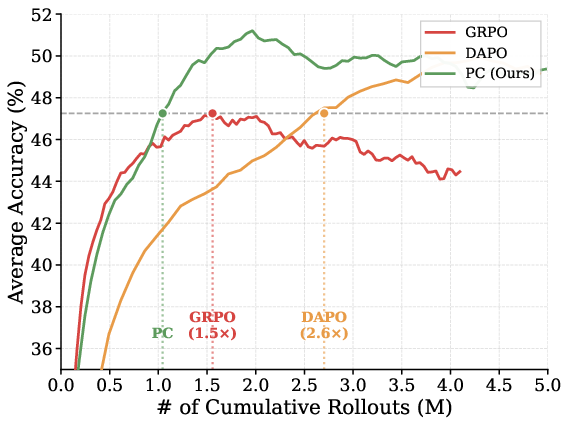
Figure 2: Average accuracy versus cumulative rollouts for Pilot-Commit, GRPO, and DAPO, showing significant rollout reduction for PC under multiple model scales.
Furthermore, PC maintains higher per-prompt reward variance and achieves elevated peak accuracy per step due to its targeted sampling. This points to enhanced gradient quality per update, not merely faster convergence. Per-step runtime measurements corroborate that rollout savings yield proportionate reductions in wall-clock training cost, even in parallelized inference setups.
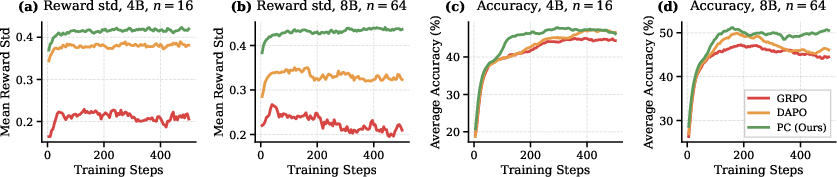
Figure 3: Quality metrics for each policy update: PC maintains elevated reward variance and rapid accuracy gains across training steps.
Tradeoff and Robustness Analysis
Pilot-Commit's two-stage allocation (pilot/commit split) was subjected to sweeps. Under constant sampling cost, varying the number of training rollouts per prompt did not impact final accuracy, confirming that the sampling budget is the critical driver of efficiency. Lightweight pilot allocations (e.g., (16,48)) yield optimal efficiency, although aggressive filtering increases risk of premature prompt eviction.
Hyperparameter ablations demonstrate robustness to filtering thresholds: performance is stable across a wide range of upper, lower, and eviction thresholds, with conservative settings preferred to minimize missed informative prompts.
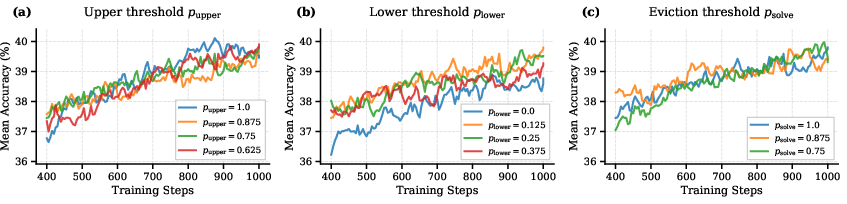
Figure 4: Hyperparameter ablation for PC confirms robustness to the upper, lower, and eviction thresholds, avoiding accuracy degradation.
Practical and Theoretical Implications
Pilot-Commit advances the practical efficiency of RL post-training for LLMs by reducing the sampling burden without compromising accuracy. The prioritization of prompts based on live reward variance maximizes the learning signal per rollout and circumvents redundant computation. The eviction strategy, replay buffer, and scheduling optimizations ensure that informative prompts are revisited efficiently and solved prompts are not repeatedly sampled.
This approach aligns with active learning and curriculum learning philosophies, but adapts selection to the dynamic policy via online estimation rather than predefined ordering or auxiliary difficulty models. Extensions to continuous or noisy reward signals, such as RLHF regimes with learned reward models, represent an evident path forward. Dynamically adapting pilot thresholds based on evolving prompt difficulty distributions could further enhance efficiency.
Conclusion
The Pilot-Commit framework for group-based RL post-training demonstrates substantial reductions in rollout cost while preserving or improving policy update quality and final accuracy. By concentrating computation on prompts possessing maximal reward-driven gradient signal, Pilot-Commit achieves up to 4× greater efficiency relative to prevailing baselines. Its practical implementation and robust empirical validation suggest broad applicability to large-scale RL post-training, paving the way for more scalable and resource-conscious training paradigms in LLM alignment and advanced reasoning tasks.