- The paper introduces PRISM, a unified transformer model that leverages spectrum prefix conditioning and cumulative-depth RoPE to predict material stacks and continuous thicknesses.
- It achieves superior spectral accuracy by reducing errors (MAE and EMD) compared to classical methods like simulated annealing through robust length generalization.
- The model bridges neural expressivity with physical fidelity using TMM-reranked beam search for real-time design of complex multilayer optical coatings.
PRISM: Position-encoded Regressive Inverse Spectral Model for Multilayer Thin-Film Design
Problem Setting and Motivations
The inverse design of multilayer thin-film optical coatings involves the recovery of stack specifications—discrete material choices and continuous layer thicknesses—that yield a desired spectral response. This is a mixed discrete-continuous optimization with a highly non-convex landscape and multiple degenerate solutions. Traditional methods such as simulated annealing, genetic algorithms, and needle optimization directly optimize per target, but incur substantial computational cost. Recent neural inverse design formulations offer amortized inference but have limited success in precision and generalization, particularly for variable-length stacks and continuous thicknesses.
Existing sequence-based neural architectures, especially decoder-only transformers, serialize stack design as sequence prediction. However, frameworks like OptoGPT require a joint material-thickness vocabulary that scales combinatorially and enforces discretization of thicknesses, while OptoFormer’s dual-decoder setup increases architectural complexity. PRISM introduces a unified model that overcomes these bottlenecks through innovative conditioning and positional encoding schemes.
Architectural Innovations
PRISM embodies two principal architectural advances:
Spectrum Prefix Conditioning
The target spectrum is projected via a linear layer to a single prefix token, which is prepended to the material token sequence. Unlike encoder-decoder transformers with cross-attention, this scheme leverages causal attention, keeping the spectrum visible throughout generation and simplifying conditioning.
Cumulative-Depth RoPE
Rotary Position Embeddings (RoPE) are adapted to encode cumulative physical depth (nm) rather than integer sequence indices. This aligns self-attention with the spatial separation and thin-film interference physics, enhancing inductive bias and enabling variable stack depths without retraining.
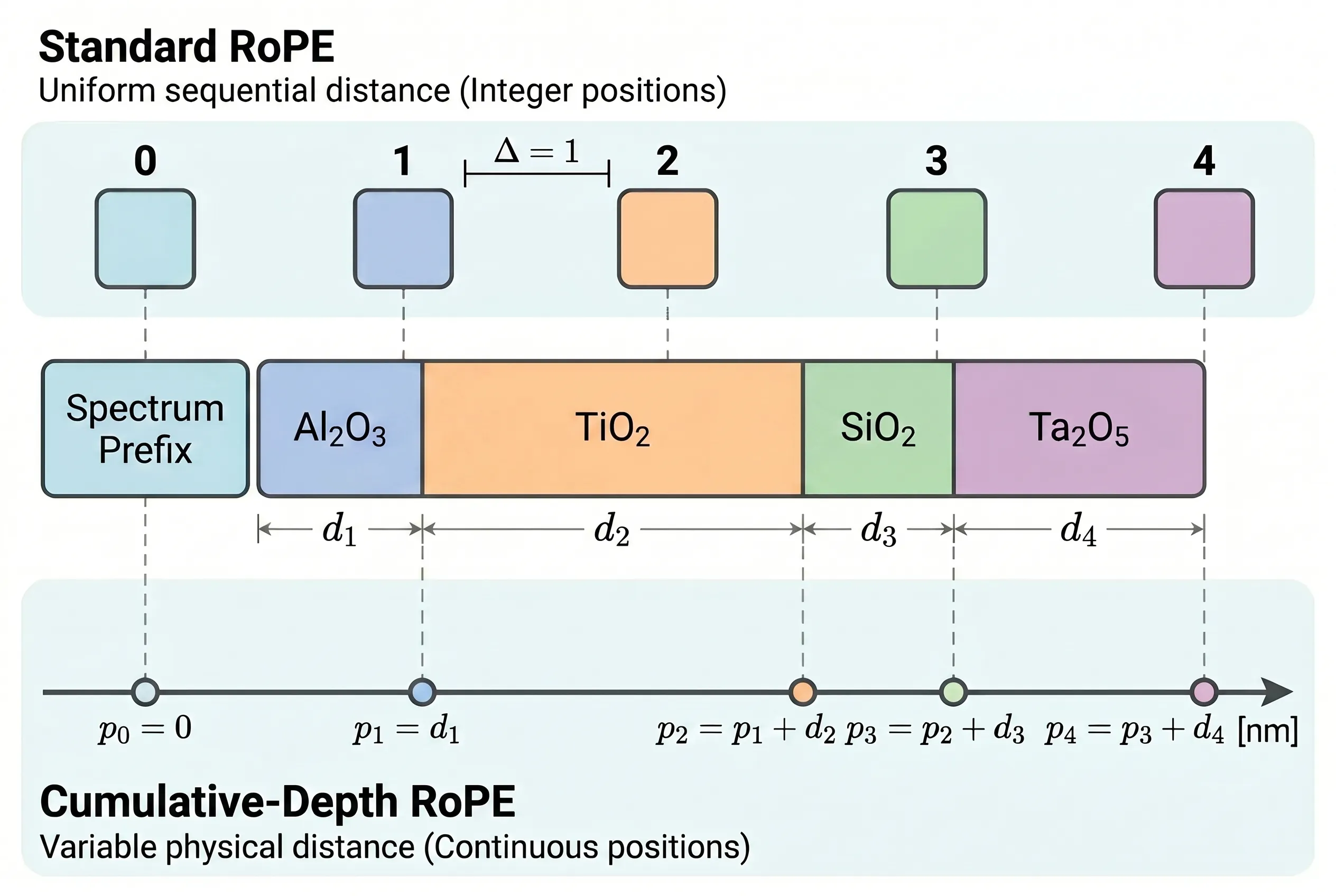
Figure 1: PRISM architecture and cumulative-depth RoPE. Spectrum prefix injects target embedding; cumulative-depth RoPE encodes spatial relationships; decoder predicts materials and thicknesses via dual heads.
The shared transformer backbone produces hidden states for each token, feeding two output heads: a categorical material head and a per-material thickness regression MLP. The latter allows differentiation of thickness predictions only for the chosen material per layer and directly supports beam search inference.
Training and Inference Regimes
PRISM is trained on datasets spanning variable stack lengths (1–20 layers), 17 distinct materials, and thickness ranges (10–500 nm), using TMM to simulate spectra. Losses are label-smoothed KL divergence for material prediction and log-space MSE for thickness regression, appropriately masked to non-padding positions. Two scaled variants are evaluated: PRISM-13M (256-dim backbone) and PRISM-44M (768-dim backbone).
At inference, the model supports both greedy generation and beam search. Crucially, candidate designs from beam search are re-simulated using TMM to obtain physically accurate spectra and are ranked by spectral error (MAE or EMD) relative to the target. This TMM-reranked strategy bridges neural and physical metrics, mitigating the mismatch between model confidence and spectral fidelity.
Empirical Evaluation
PRISM is benchmarked against simulated annealing, differentiable TMM, OptoGPT, tandem networks, and CVAE, using identical re-simulation protocols. The primary metrics are post-simulation MAE and spectral earth-mover’s distance (EMD), alongside R2.
In-Distribution Results
PRISM-44M achieves greedy MAE = 0.012 and R2=0.989 on the synthetic validation set, outperforming all methods including simulated annealing (MAE = 0.016), which has traditionally led benchmarks. PRISM-13M, with only 13M parameters, delivers performance superior to much larger transformer baselines.
Out-of-Distribution Generalization
PRISM shows minimal degradation in MAE when stacks of up to 2.5× longer than training are evaluated, indicating robust length generalization. Scaling model size effectively halves MAE across all sequence lengths.
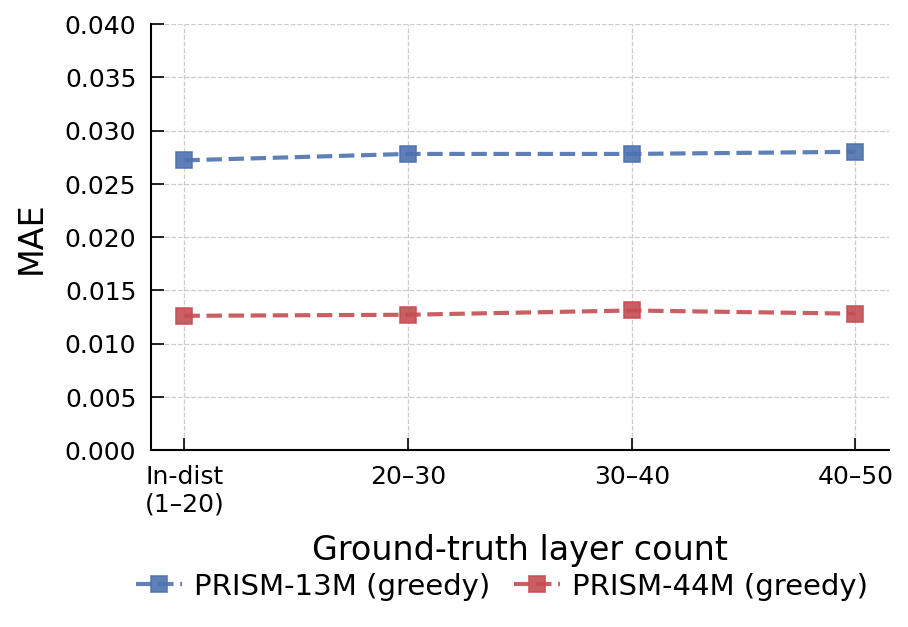
Figure 2: Out-of-distribution generalization performance for sequence lengths up to 2.5× longer than training.
Practical Targets
On a set of 84 practical optical filter spectra (e.g., dichroic, multi-bandpass, broadband HR mirrors), PRISM-44M TMM-reranked attains the lowest EMD (72.2) and high R2 (0.533), outperforming simulated annealing in shape-sensitive error despite a marginally higher pointwise MAE.
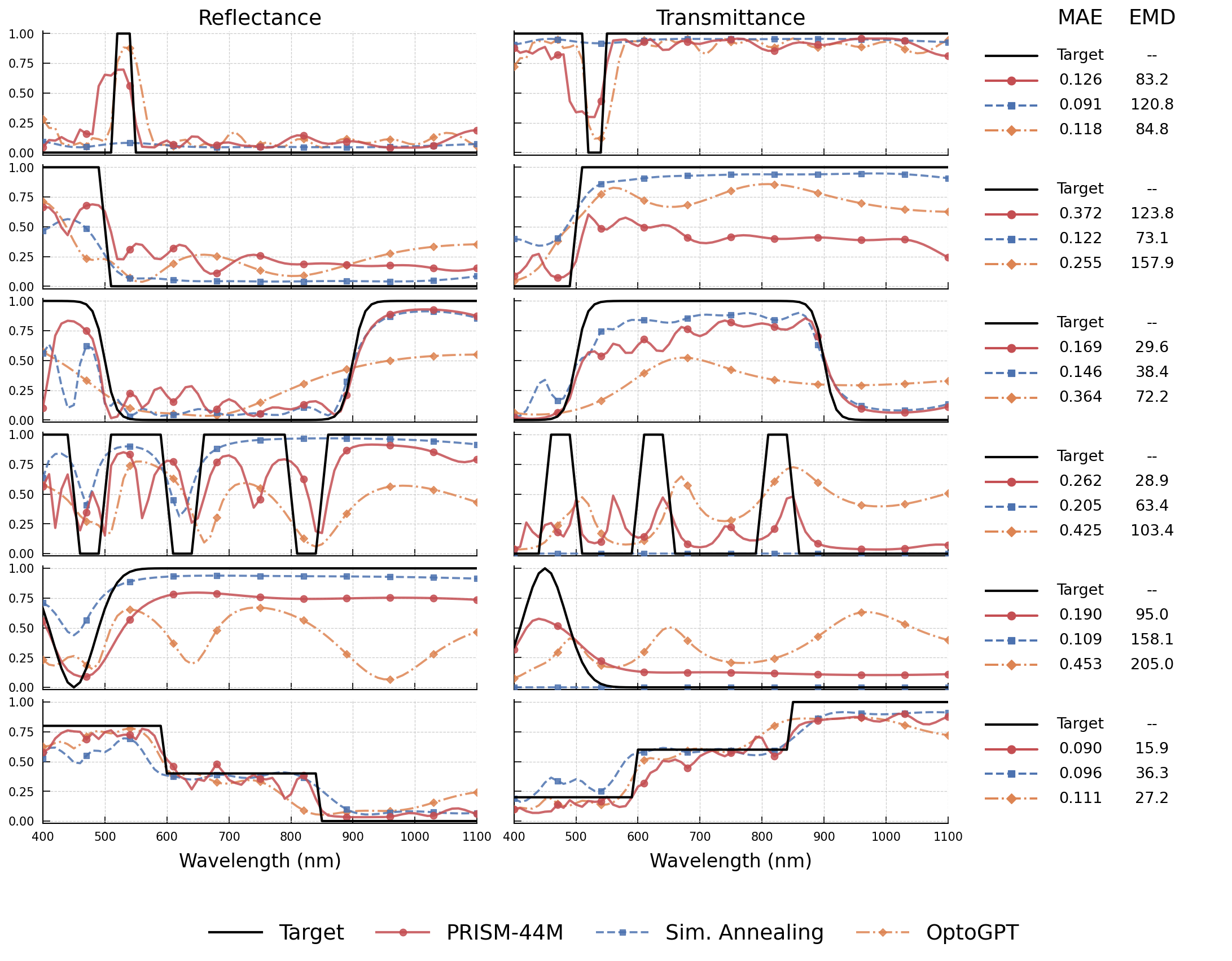
Figure 3: Qualitative comparison of predicted spectra across methods for practical targets; PRISM tracks target curve structure more closely than classical or other neural methods.
Qualitative inspection reveals that optimizer-driven methods favor average or smoothed structure, whereas PRISM’s decoder-based generation consistently reconstructs sharper edges and feature positions. This underscores the necessity of using EMD as a complementary evaluation metric, since MAE fails to credit structural alignment in non-trivial spectra.
Theoretical and Practical Implications
The architectural innovations in PRISM—prefix token conditioning and cumulative-depth RoPE—demonstrate the value of integrating domain-specific physical reasoning into sequence models. The cumulative-depth encoding aligns model attention with optical physics, providing an inductive bias that cannot be replicated using naive sequence indices. This approach generalizes naturally to stacks of unseen lengths and depths, and may be extendable to other layered inverse design domains (e.g., multilayer metasurfaces).
Practically, PRISM achieves inference speeds orders of magnitude faster than classical optimizers, rendering it suitable for real-time and high-throughput design applications. The TMM-reranked inference stratagem further bridges model expressivity with physical accuracy, providing robust candidate selection.
Limitations and Future Directions
PRISM’s current spectrum conditioning does not accommodate partial specifications (e.g., constraining only sub-ranges of wavelengths), nor does it handle angular dependence required by some practical filters. Future work may involve richer conditioning interfaces (e.g., masked targets, angle-of-incidence embeddings), band-specific optimization, or reinforcement learning approaches with TMM-based rewards to post-train for fidelity in practical regimes.
Conclusion
PRISM sets a new standard for neural inverse multilayer thin-film design by unifying discrete and continuous sequence prediction, introducing physics-aligned position encoding, and achieving superior quantitative and qualitative performance compared to both neural and classical baselines. The architectural strategies and empirical findings suggest promising pathways for the integration of domain knowledge into autoregressive architectures and broader applicability within layered photonic and nanostructure design domains.