- The paper introduces PRISM, a one-step diffusion framework that rectifies degraded text image priors and reliably recovers high-level conditions.
- It employs a Flow-Matching Prior Rectification module to align low-quality inputs with privileged latent targets, significantly enhancing OCR accuracy.
- It leverages a Structure-guided Uncertainty-aware Residual Encoder to refine local stroke details, achieving state-of-the-art fidelity and rapid inference.
PRISM: Prior Rectification and Uncertainty-Aware Structure Modeling for Diffusion-Based Text Image Super-Resolution
Text image super-resolution (Text-SR) presents greater challenges than generic super-resolution due to the symbolic and fine-grained topological nature of text, where perceptual artifacts can critically impede character identity and readability. While prior works have incorporated stronger recognition and generative priors, these models remain brittle under severe degradations, particularly due to (1) unreliable priors extracted from low-quality inputs and (2) insufficient correspondence between global priors and local pixel-aligned stroke structures. The paper "PRISM: Prior Rectification and Uncertainty-Aware Structure Modeling for Diffusion-Based Text Image Super-Resolution" (2605.13027) addresses these two coupled ambiguities with a single-step restoration diffusion framework, targeting robustness and accuracy under severe conditions.
Methodological Innovations in PRISM
Overview of PRISM Architecture
PRISM decomposes the Text-SR process into two explicit subproblems: global prior rectification and local structure refinement. The architecture deploys two dedicated modules—a Flow-Matching Prior Rectification (FMPR) unit for robust text-aware condition recovery and a Structure-guided Uncertainty-aware Residual Encoder (SURE) for probabilistic local structure enhancement—within a one-step diffusion restoration procedure.
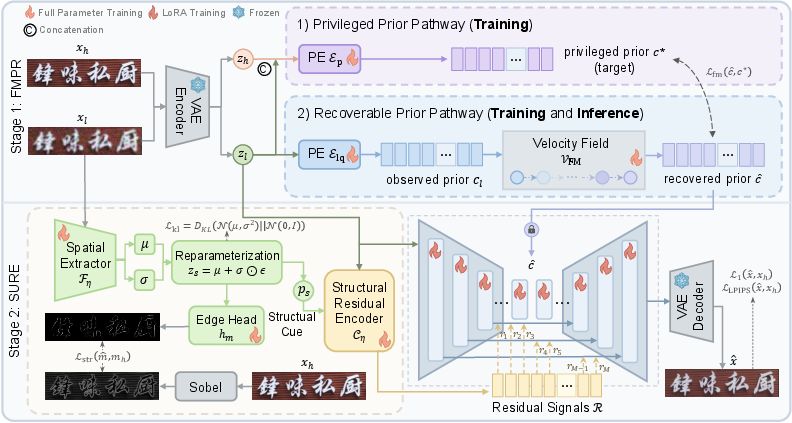
Figure 1: Overall structure of PRISM, which integrates FMPR for prior rectification and SURE for local structure refinement in a single-step diffusion restoration pipeline.
The restoration pipeline proceeds by mapping a degraded input image to a latent space with a VAE encoder, then utilizing FMPR to recover a reliable high-level prior and SURE to inject uncertainty-aware spatial cues, guiding a pre-trained diffusion UNet for final reconstruction.
Flow-Matching Prior Rectification (FMPR)
Rather than directly extracting priors from degraded images, FMPR leverages privileged access to paired high-quality/low-quality latents during training to define an informative target prior space. FMPR learns to transport the latent distribution of degraded inputs toward the privileged prior space using flow-matching generative modeling, parameterizing the transformation as a continuous velocity field integrated over multiple Euler steps.
This approach overcomes degeneracies of both direct regression (insufficient prior gap closure) and standard diffusion-based prior extraction (inefficient, overly stochastic generation paths) by enforcing a deterministic, monotonic trajectory in the embedding space, yielding superior reliability under severe degradation.
Quantitative Efficacy of FMPR
As demonstrated in controlled ablations, flow-matching prior recovery achieves the best trade-off between perceptual and recognition-oriented metrics compared to direct regression and diffusion-based baselines:
(Figure 2, left panel)
Figure 3: Ablation study of prior learning paradigms on RealCE-val, showing that flow-matching yields optimal fidelity and OCR accuracy for robust prior recovery.
Furthermore, the effect of iterative integration steps in FMPR (Euler steps) manifests a consistent improvement in fidelity, with diminishing returns past 16 steps as evidenced by the saturation trends:
(Figure 2, right panel)
Figure 2: Restoration performance improves with increased FMPR Euler steps, validating the necessity of multi-step prior rectification.
Structure-Guided Uncertainty-Aware Residual Encoder (SURE)
While global rectification addresses semantic plausibility, local stroke geometry and boundary placement remain ambiguous due to intrinsic information loss. SURE addresses this through a probabilistic structural cue pathway: a spatial extractor predicts the mean and variance of edge features from degraded inputs, with the variance representing epistemic uncertainty.
These uncertainty-aware cues are injected as residual controls into the frozen diffusion backbone, allowing the model to selectively trust sharp boundary evidence and suppress ambiguous signals, thus preventing overcommitment to unreliable edge predictions that can induce structural hallucinations.




Figure 5: SURE visualizes the input, LQ boundary map, predicted uncertainty, model’s boundary map, and ground truth, demonstrating effective uncertainty gating for local structure refinement.
Quantitative and qualitative ablations confirm that SURE, and particularly the explicit uncertainty modeling, produces measurable stability and accuracy improvements:
(Figure 4, right panel and table)
Figure 4: SURE ablation on RealCE-val demonstrates incremental gains in text fidelity as uncertainty modeling is introduced and the full model is used.
Empirical Evaluation
PRISM is evaluated on synthetic and real-world test sets—BTL-test and RealCE-val—constructed to reflect Chinese-English bilingual text lines with diverse degradation. Evaluation metrics span perceptual (LPIPS, FID), pixel-level (PSNR), and recognition (OCR accuracy, normalized edit distance) criteria.
Quantitative and Qualitative Results
PRISM achieves leading performance in LPIPS, FID, NED, and OCR accuracy under severe 4× super-resolution, substantially outperforming other diffusion- and non-diffusion-based baselines. It attains the highest accuracy (65.19%) and lowest FID (47.83) on the most challenging RealCE-val set, reflecting robust character-level and overall distributional restoration.







Figure 6: Qualitative comparison on BTL-test under 4× super-resolution demonstrates the superior structural fidelity and text readability of PRISM outputs.
Figure 7: Qualitative comparison on the RealCE-val dataset, where PRISM maintains stroke continuity and suppresses artifacts compared to other leading methods.
Efficiency and Practicality
A critical practical consideration for diffusion-based models is inference latency. PRISM’s single-step design delivers orders-of-magnitude faster inference (0.08s per image) than prior diffusion approaches (10-50s), enabling deployment in latency-sensitive applications.
Implications, Limitations, and Future Directions
PRISM’s architectural decoupling of prior rectification and uncertainty-aware refinement resolves fundamental bottlenecks in Text-SR. The framework is extensible to more general text-aware restoration settings, including full-document, multilingual, and scene-level scenarios. However, PRISM currently targets moderate-to-long text lines in Chinese and English, and does not address highly irregular layouts or other scripts.
Future research may generalize PRISM’s integration of flow-matching priors and probabilistic structure modeling to broader generative restoration tasks, exploit more expressive uncertainty quantification, and extend to multi-modal or fully self-supervised settings.
Conclusion
PRISM introduces a conceptually novel and technically effective approach to diffusion-based Text-SR by jointly modeling reliable high-level priors through flow matching and local structural uncertainty through probabilistic cues. Empirical evidence demonstrates consistent improvements over the state-of-the-art in both fidelity and efficiency, while architectural choices ensure practical usability. The implications of this work extend beyond Text-SR, informing the design of robust, structure-aware restoration models in vision and beyond.

